Download as PDF, PPTX
























![PigLatin Data Types
● Scalar types
○ int, long, float, double, chararray, bytearray, boolean
(since Pig 0.10.0)
● Complex types
○ tuple - sequence of fields of any type
■ ('Poland', 2, 0.66)
○ bag - an unordered collection of tuples, possibly with
duplicates
■ {('Poland', 2), ('Greece'), (3.14)}
○ map - a set of key-value pairs. Keys must be a
chararray, values may be any type
■ ['Poland'#'Euro2012']](https://image.slidesharecdn.com/whug3-apachepig-adamkawa-120625124434-phpapp01/85/Introduction-To-Apache-Pig-at-WHUG-29-320.jpg)



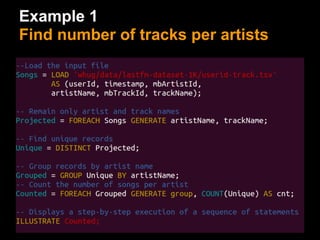




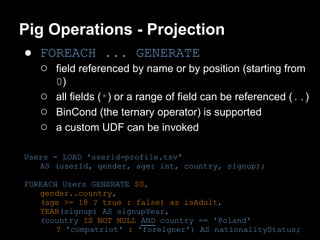





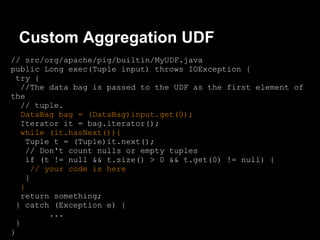







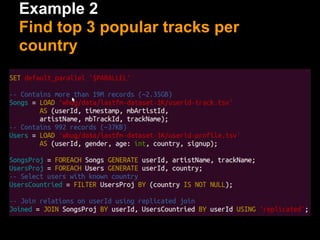

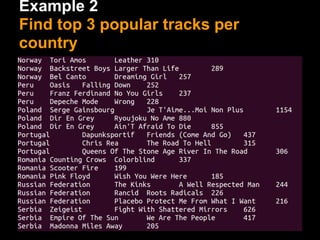
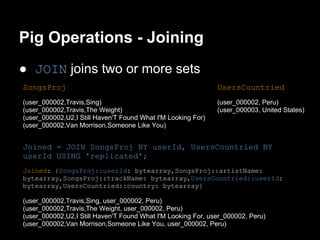





















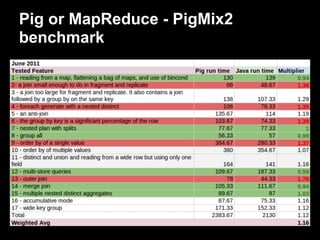





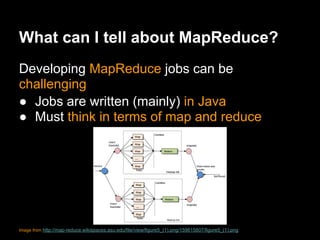
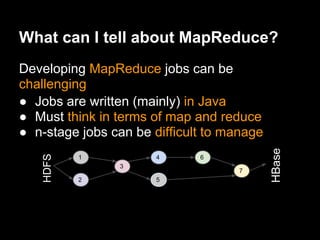
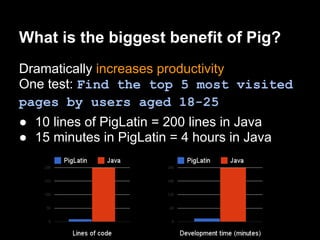
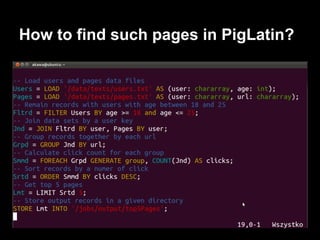
This document provides an introduction to Apache Pig including: - What Pig is and how it offers a high-level language called PigLatin for analyzing large datasets. - How PigLatin provides common data operations and types and is more natural for analysts than MapReduce. - Examples of how WordCount looks in PigLatin versus Java MapReduce. - How Pig works by parsing, optimizing, and executing PigLatin scripts as MapReduce jobs on Hadoop. - Considerations for developing, running, and optimizing PigLatin scripts.






















































































