Downloaded 215 times













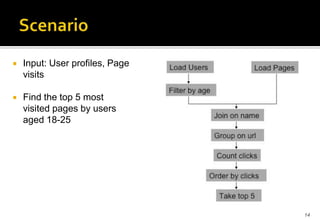














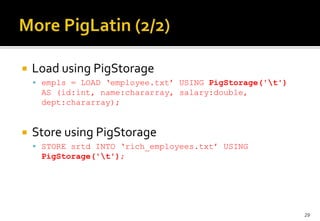







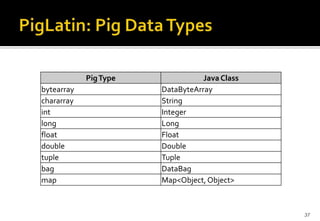

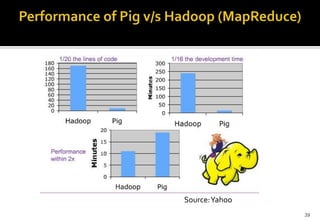



This document provides an overview of Apache Pig and Pig Latin for querying large datasets. It discusses why Pig was created due to limitations in SQL for big data, how Pig scripts are written in Pig Latin using a simple syntax, and how PigLatin scripts are compiled into MapReduce jobs and executed on Hadoop clusters. Advanced topics covered include user-defined functions in PigLatin for custom data processing and sharing functions through Piggy Bank.























![Interview questions on Apache spark [part 2]](https://cdn.slidesharecdn.com/ss_thumbnails/interviewquestionsonapachesparkpart2-150731093720-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




























































