Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PPTX, PDF
1,077 views
【DL輪読会】EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Pointsfor Monocular Object Pose Estimation
2022/7/22 Deep Learning JP http://deeplearning.jp/seminar-2/
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 18 times
1
/ 15
2
/ 15
3
/ 15
4
/ 15
Most read
5
/ 15
6
/ 15
Most read
7
/ 15
8
/ 15
9
/ 15
10
/ 15
11
/ 15
12
/ 15
13
/ 15
14
/ 15
Most read
15
/ 15
More Related Content
PDF
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monoc...
by
Kazuyuki Miyazawa
PPTX
[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...
by
Deep Learning JP
PPTX
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
PDF
Point net
by
Fujimoto Keisuke
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monoc...
by
Kazuyuki Miyazawa
[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...
by
Deep Learning JP
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
Point net
by
Fujimoto Keisuke
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
What's hot
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PDF
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
by
Deep Learning JP
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PDF
点群深層学習 Meta-study
by
Naoya Chiba
PPTX
SLAM勉強会(3) LSD-SLAM
by
Iwami Kazuya
PPTX
[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...
by
Deep Learning JP
PDF
30th コンピュータビジョン勉強会@関東 DynamicFusion
by
Hiroki Mizuno
PPTX
[DL輪読会]Graph R-CNN for Scene Graph Generation
by
Deep Learning JP
PPTX
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
PDF
[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...
by
Deep Learning JP
PPTX
CNN-SLAMざっくり
by
EndoYuuki
PDF
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
PDF
[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...
by
Deep Learning JP
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PPTX
[DL輪読会]PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
by
Deep Learning JP
PDF
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
Transformer メタサーベイ
by
cvpaper. challenge
Optimizer入門&最新動向
by
Motokawa Tetsuya
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
by
Deep Learning JP
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
点群深層学習 Meta-study
by
Naoya Chiba
SLAM勉強会(3) LSD-SLAM
by
Iwami Kazuya
[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...
by
Deep Learning JP
30th コンピュータビジョン勉強会@関東 DynamicFusion
by
Hiroki Mizuno
[DL輪読会]Graph R-CNN for Scene Graph Generation
by
Deep Learning JP
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...
by
Deep Learning JP
CNN-SLAMざっくり
by
EndoYuuki
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...
by
Deep Learning JP
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
[DL輪読会]PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
by
Deep Learning JP
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
Similar to 【DL輪読会】EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Pointsfor Monocular Object Pose Estimation
PPTX
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...
by
Deep Learning JP
PDF
【ECCV 2018】Implicit 3D Orientation Learning for 6D Object Detection from RGB ...
by
cvpaper. challenge
PDF
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
PPTX
[DL輪読会]3D Human Pose Estimation @ CVPR’19 / ICCV’19
by
Deep Learning JP
PDF
[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks
by
Deep Learning JP
PDF
PFI成果発表会2014発表資料 Where Do You Look?
by
Hokuto Kagaya
PDF
夏のトップカンファレンス論文読み会 / Realtime Multi-Person 2D Pose Estimation using Part Affin...
by
Shunsuke Ono
PDF
[DL輪読会]CVPR2019:Weakly-Supervised Discovery of Geometry-Aware Representation ...
by
Deep Learning JP
PDF
DeepPose: Human Pose Estimation via Deep Neural Networks
by
Shunta Saito
PDF
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
PDF
論文紹介:Deep Learning-Based Human Pose Estimation: A Survey
by
Toru Tamaki
PDF
Cvpr 2019 pvnet
by
Kenta Tanaka
PDF
【2015.07】(1/2)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PPTX
Triplet Loss 徹底解説
by
tancoro
PPTX
Eccv2018 report day2
by
Atsushi Hashimoto
PDF
cvpaper.challenge in CVPR2015 (PRMU2015年12月)
by
cvpaper. challenge
PPTX
[DL輪読会]End-to-End Object Detection with Transformers
by
Deep Learning JP
PPTX
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unk...
by
Kazuyuki Miyazawa
PPTX
My article s_endo
by
ShinEndo1
PDF
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...
by
Deep Learning JP
【ECCV 2018】Implicit 3D Orientation Learning for 6D Object Detection from RGB ...
by
cvpaper. challenge
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
[DL輪読会]3D Human Pose Estimation @ CVPR’19 / ICCV’19
by
Deep Learning JP
[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks
by
Deep Learning JP
PFI成果発表会2014発表資料 Where Do You Look?
by
Hokuto Kagaya
夏のトップカンファレンス論文読み会 / Realtime Multi-Person 2D Pose Estimation using Part Affin...
by
Shunsuke Ono
[DL輪読会]CVPR2019:Weakly-Supervised Discovery of Geometry-Aware Representation ...
by
Deep Learning JP
DeepPose: Human Pose Estimation via Deep Neural Networks
by
Shunta Saito
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
論文紹介:Deep Learning-Based Human Pose Estimation: A Survey
by
Toru Tamaki
Cvpr 2019 pvnet
by
Kenta Tanaka
【2015.07】(1/2)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
Triplet Loss 徹底解説
by
tancoro
Eccv2018 report day2
by
Atsushi Hashimoto
cvpaper.challenge in CVPR2015 (PRMU2015年12月)
by
cvpaper. challenge
[DL輪読会]End-to-End Object Detection with Transformers
by
Deep Learning JP
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unk...
by
Kazuyuki Miyazawa
My article s_endo
by
ShinEndo1
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Pointsfor Monocular Object Pose Estimation
1.
DEEP LEARNING JP [DL
Papers] “EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation” Presenter: Takahiro Maeda D1 (Toyota Technological Institute) http://deeplearning.jp/
2.
目次 1. 書誌情報 2. 概要 3.
研究背景 4. 提案手法 5. 実験結果 6. 考察・所感 2
3.
1. 書誌情報 紹介論文 タイトル: EPro-PnP:
Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation 出典: CVPR2022 Best Student Paper 著者: Hansheng Chen, …, Hao Li. 所属: 同済大学(中国),Alibaba 選書理由 CVPR2022のBest Student Paperに興味がある ※引用は最後にまとめてあります.特に明示が無い場合は,紹介論文,動画から引用 3
4.
2. 概要 • argminの学習不安定性を緩和する手法を提案 ①
物体姿勢推定は Perspective-n-Point (PnP) が比較的高精度 ② しかし,PnPはargmin処理により,微分不可・学習不安定 ③ 提案手法(EPro-PnP)では,argmin出力を確率分布とする ことで微分可能にし,End-to-End学習を可能にした. 4 Perspective-n-Point (PnP)問題 [1]
5.
3. 研究背景: Direct
Pose Prediction 5 2D画像 姿勢 𝑅, 𝒕 6次元姿勢推定[2] 3次元位置 3次元回転 3次元物体検出(車載系)[3] 平面上2次元位置 鉛直方向1次元回転 姿勢の例 良い点 • 単純 • 物体形状を必要としない 悪い点 • (PnPと比べ)解釈性が低い • 過学習,汎化性能悪い(見た目の変化に過敏) 損失関数
6.
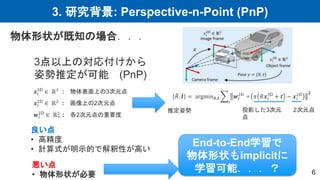
3. 研究背景: Perspective-n-Point
(PnP) 6 物体形状が既知の場合... 3点以上の対応付けから 姿勢推定が可能 (PnP) 𝒙𝑖 3D ∈ ℝ3 : 物体表面上の3次元点 𝒙𝑖 2D ∈ ℝ2 : 画像上の2次元点 𝒘𝑖 2D ∈ ℝ+ 2 : 各2次元点の重要度 𝑅, 𝒕 = argmin𝑅,𝒕 𝑖 𝒘𝑖 2D ∘ 𝜋 𝑅𝒙𝑖 3D + 𝒕 − 𝒙𝑖 2D 𝟐 推定姿勢 投影した3次元 点 良い点 • 高精度 • 計算式が明示的で解釈性が高い 悪い点 • 物体形状が必要 End-to-End学習で 物体形状もimplicitに 学習可能...? 2次元点
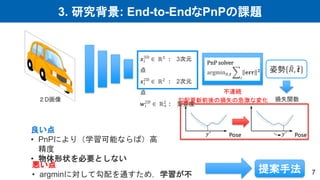
7.
3. 研究背景: End-to-EndなPnPの課題 7 良い点 •
PnPにより(学習可能ならば)高 精度 • 物体形状を必要としない 悪い点 • argminに対して勾配を通すため,学習が不 2D画像 損失関数 𝒙𝑖 3D ∈ ℝ3 : 3次元 点 𝒙𝑖 2D ∈ ℝ2 : 2次元 点 𝒘𝑖 2D ∈ ℝ+ 2 : 重要度 姿勢 𝑅, 𝒕 PnP solver argmin𝑅,𝒕 𝑖 𝐞𝐫𝐫 𝟐 不連続 勾配更新前後の損失の急激な変化 提案手法
8.
4. 提案手法: argminから確率分布への緩和 8 2D画像
損失関数 MSE 𝒙𝑖 3D ∈ ℝ3 𝒙𝑖 2D ∈ ℝ2 𝒘𝑖 2D ∈ ℝ+ 2 姿勢 𝑅, 𝒕 PnP solver argmin𝑅,𝒕 𝑖 𝐞𝐫𝐫 𝟐 不連続 従来法 提案手法 2D画像 EPro-PnP 連続 確率分布 𝒙𝑖 3D ∈ ℝ3 𝒙𝑖 2D ∈ ℝ2 𝒘𝑖 2D ∈ ℝ+ 2 GT分布[4] 損失関数 KL divergence Pose Softmax
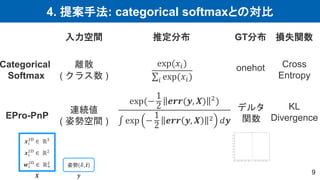
9.
4. 提案手法: categorical
softmaxとの対比 9 Categorical Softmax EPro-PnP 入力空間 推定分布 GT分布 損失関数 離散 ( クラス数 ) 連続値 ( 姿勢空間 ) exp(𝑥𝑖) 𝑖 exp(𝑥𝑖) exp(− 1 2 𝒆𝒓𝒓(𝒚, 𝑿) 2) exp − 1 2 𝒆𝒓𝒓 𝒚, 𝑿 2 𝑑𝒚 𝒙𝑖 3D ∈ ℝ3 𝒙𝑖 2D ∈ ℝ2 𝒘𝑖 2D ∈ ℝ+ 2 姿勢 𝑅, 𝒕 𝑿 𝒚 onehot デルタ 関数 Cross Entropy KL Divergence
10.
4. 提案手法: 損失関数 10 確率分布 GT分布[4] 損失関数 KL
divergence Pose 𝐿 = 𝐷KL 𝛿gt 𝒚 𝑝 𝒚 𝑿 = 𝛿gt 𝒚 log 𝛿gt 𝒚 𝑝 𝒚 𝑿 𝑑𝒚 = − 𝛿gt 𝒚 log 𝑝 𝒚 𝑿 𝑑𝒚 + const = −log 𝑝 𝒚gt 𝑿 + const = 1 2 𝒆𝒓𝒓 𝒚gt, 𝑿 2 + log exp − 1 2 𝒆𝒓𝒓 𝒚, 𝑿 2 𝑑𝒚 𝛿gt(𝒚) 𝑝(𝒚|𝑿) 確率密度関数におけるKLDの定義 𝑿に関わらない項を定数に デルタ関数の積分の定義 𝑝(𝒚|𝑿)の定義,const省略 GT姿勢の確率を最大化 他の姿勢の確率を最小化 確率分布
11.
4. 提案手法: 重点サンプリングによる積分値の近似 11 log
exp − 1 2 𝒆𝒓𝒓 𝒚, 𝑿 2 𝑑𝒚 = log 𝑓 𝒚 𝑑𝒚 = log 𝑓 𝒚 𝑞 𝒚 𝑞 𝒚 𝑑𝒚 = log 𝔼𝑞 𝑓 𝒚 𝑞 𝒚 ≈ log 𝑖 𝑓 𝒚 𝑞 𝒚 𝑓(𝒚)と置く 𝑞 𝒚 𝑞(𝒚) = 1を掛け合わせる. ただし,𝑞(𝒚)はサンプリング可な確率分 布 積分を期待値とする 𝑞(𝒚)からのサンプルによる期待値の近似 (重点サンプリング) 重点サンプリングの近似精度は𝑞(𝒚)の選択に依存 推定空間に合わせた分布を選択する必要がある. 姿勢推定: 3次元位置 t分布 1次元角度 von Mises distribution と一様分布の混 合 3次元角度 Angular Central Gaussian Distribution
12.
5. 実験結果: 6次元姿勢推定 12 6次元姿勢推定[2] CDPN:
PnPベースの6次元姿勢推定従来法
13.
5. 実験結果: 3次元物体検出 13 3次元物体検出(車載系)[3] 平面上2次元位置 鉛直方向1次元回転
14.
6. 所感・考察 • softmaxの連続空間verを提案 –
身近な場所にbest paperの種が落ちている • argminは古典的アルゴリズムで頻出するため,応用範囲が広い • 解法がシンプル • 性能も向上 • 流石best paper 14
15.
引用 [1] Perspective-n-Point問題 http://www.sanko-shoko.net/note.php?id=y15w [2]
EfficientPose https://github.com/ybkscht/EfficientPose [3] KITTI http://www.cvlibs.net/datasets/kitti/ [4] Dirac delta https://jp.mathworks.com/help/symbolic/sym.dirac.html 15
Editor's Notes
#2
という論文を紹介します.
#4
まず,書誌情報です. この論文はCVPR2022でBest Student Paperを受賞しており,Best Paperに興味があったため選びました.
#5
この論文は,機械学習モデル内のargmin処理が学習不安定であることを解決しました. 大まかな流れとして,この3段階に分けられます. 物体姿勢推定は右図に示すPerspective-n-Point PnPが高精度です. これは,古典的なCVアルゴリズムで,3次元空間の点と2次元画像上の点を対応付けることで,物体姿勢を求めます. しかし,このPnPはargmin処理のために機械学習モデル内で用いると学習が困難です. これに対して,提案手法ではargmin処理の出力を確率分布とすることで微分可能にし,End-to-End学習を可能にしました.
#6
研究背景について説明します. 深層学習が流行りだした後には,このように物体が写った画像から直接姿勢をregressionする手法が多く取られています. 姿勢の例としては,3次元位置と3次元回転や車載系では道路平面上の2次元位置と鉛直方向の回転などです. 良い点として,単純であり物体形状を必要としません. しかし,物体全体の情報から姿勢を推定するため,過学習しがちで汎化性能が悪いです.
#7
物体形状が既知の場合,右図のように物体表面上の点と画像平面上の点を3点以上対応付けることで, 物体姿勢を求めることが可能です. これがPerspective-n-Pointアルゴリズムです. 具体的には,画像上に投影した3次元点と2次元点の距離が最小になるようにargmin処理で姿勢を求めます. 良い点として,局所的な見た目によって姿勢推定を求めるため,見た目の変化にロバストで高精度です. また推定失敗した場合は,対応付けミスを調べることで解釈を行えます. しかし,大きな問題としてこのアルゴリズムは物体形状が必要です. 深層学習の時代では,End-to-Endで物体形状もimplicitに学習できないかと考えます.
#8
単純にPnPを深層学習器と組み合わせたものがこちらです. 画像情報から深層学習器によってPnPの入力となる3つを出力します. その後,PnP内でargminを行うことで姿勢を推定し,損失を計算します. このようにEnd-to-End学習することで物体形状も学習できることを期待します. しかし,argmin処理は不連続で微分不可なために,勾配更新前後で損失が急激に変化し学習が不安定です. よって,提案手法が必要です.
#9
End-to-End Probabilistic PnP (EPro-PnP)が提案されました. これは,argmin処理の出力をsoftmaxを用いて確率分布とすることで,連続で微分可能にし学習を安定化させています. 損失はGT分布とのKL divergenceです. 俯瞰してみるとかなり単純な手法だとわかっていただけると思います.
#10
このEpro-PnPは,classificationのSoftmaxとよく対比されます. softmaxは離散クラスにおいて用いられ,Epro-PnPは連続空間において用いられます. EPro-PnPの確率値は,よくご存じのsoftmaxを連続空間に拡張したものとなっています. softmaxのGT分布はonehotベクトルですが,Epro-PnPではディラックのデルタ関数が用いられます. このデルタ関数は,ある一点において確率密度が無限大となる関数で,onehotと酷似しています. 用いられる損失は,cross entropyとKL divergenceでほぼ同じものです. このようにEpro-PnPはsoftmaxを連続空間へ拡張している単純なものです.
#11
これから,KL損失を計算します. 式変形を重ねていくと,最終的にGT姿勢の確率を最大化する項と他の姿勢の確率を最小化する項にたどり着きます. これは,categorical softmaxを微分した場合にも類似した項が得られます. しかし,大きな問題点として連続空間全体に対する積分が計算できず,最適化できません.
#12
提案手法では,この積分値を重点サンプリングにより近似します. 重点サンプリングは,あるサンプリング可能な分布による期待値で積分値を近似します. この近似精度は分布qがどれだけ真の分布との類似性に依存します. よって提案手法では,3次元位置空間や角度空間での分布qも提案しています. 結局はすべてGaussian likeな分布です.
#13
このEPro-PnPを物体6次元姿勢推定に適用した例がこちらです. 既存ネットワークから,3次元位置と重要度を予測するブランチを生やして学習したところ, 精度が向上されています.
#14
また,車載系の3次元物体検出にも適用されていました. ここでも精度向上が確認されています.
#15
まとめです. 提案手法では,categorical softmaxの連続空間版を提案し,argmax処理の不連続性を解消しています. argmin処理は古典的なアルゴリズムで頻出するため,かなり応用範囲が広いのではないかと感じます. また,解法もシンプルで性能も向上しており,流石best paperだと思います.
Download
![DEEP LEARNING JP
[DL Papers]
“EPro-PnP: Generalized End-to-End Probabilistic
Perspective-n-Points for Monocular Object Pose Estimation”
Presenter: Takahiro Maeda D1
(Toyota Technological Institute)
http://deeplearning.jp/](https://image.slidesharecdn.com/20220722dlseminarsepro-pnp-220725010500-ac894d78/85/DL-EPro-PnP-Generalized-End-to-End-Probabilistic-Perspective-n-Pointsfor-Monocular-Object-Pose-Estimation-1-320.jpg)
![DEEP LEARNING JP
[DL Papers]
“EPro-PnP: Generalized End-to-End Probabilistic
Perspective-n-Points for Monocular Object Pose Estimation”
Presenter: Takahiro Maeda D1
(Toyota Technological Institute)
http://deeplearning.jp/](https://image.slidesharecdn.com/20220722dlseminarsepro-pnp-220725010500-ac894d78/75/DL-EPro-PnP-Generalized-End-to-End-Probabilistic-Perspective-n-Pointsfor-Monocular-Object-Pose-Estimation-1-2048.jpg)


![2. 概要
• argminの学習不安定性を緩和する手法を提案
① 物体姿勢推定は Perspective-n-Point (PnP) が比較的高精度
② しかし,PnPはargmin処理により,微分不可・学習不安定
③ 提案手法(EPro-PnP)では,argmin出力を確率分布とする
ことで微分可能にし,End-to-End学習を可能にした.
4
Perspective-n-Point (PnP)問題
[1]](https://image.slidesharecdn.com/20220722dlseminarsepro-pnp-220725010500-ac894d78/85/DL-EPro-PnP-Generalized-End-to-End-Probabilistic-Perspective-n-Pointsfor-Monocular-Object-Pose-Estimation-4-320.jpg)
![3. 研究背景: Direct Pose Prediction
5
2D画像
姿勢 𝑅, 𝒕
6次元姿勢推定[2]
3次元位置
3次元回転
3次元物体検出(車載系)[3]
平面上2次元位置
鉛直方向1次元回転
姿勢の例
良い点
• 単純
• 物体形状を必要としない
悪い点
• (PnPと比べ)解釈性が低い
• 過学習,汎化性能悪い(見た目の変化に過敏)
損失関数](https://image.slidesharecdn.com/20220722dlseminarsepro-pnp-220725010500-ac894d78/85/DL-EPro-PnP-Generalized-End-to-End-Probabilistic-Perspective-n-Pointsfor-Monocular-Object-Pose-Estimation-5-320.jpg)
![4. 提案手法: argminから確率分布への緩和
8
2D画像 損失関数
MSE
𝒙𝑖
3D
∈ ℝ3
𝒙𝑖
2D
∈ ℝ2
𝒘𝑖
2D
∈ ℝ+
2
姿勢 𝑅, 𝒕
PnP solver
argmin𝑅,𝒕
𝑖
𝐞𝐫𝐫 𝟐
不連続
従来法
提案手法
2D画像
EPro-PnP
連続 確率分布
𝒙𝑖
3D
∈ ℝ3
𝒙𝑖
2D
∈ ℝ2
𝒘𝑖
2D
∈ ℝ+
2
GT分布[4]
損失関数
KL divergence
Pose
Softmax](https://image.slidesharecdn.com/20220722dlseminarsepro-pnp-220725010500-ac894d78/85/DL-EPro-PnP-Generalized-End-to-End-Probabilistic-Perspective-n-Pointsfor-Monocular-Object-Pose-Estimation-8-320.jpg)
![4. 提案手法: 損失関数
10
確率分布
GT分布[4]
損失関数
KL divergence
Pose
𝐿 = 𝐷KL 𝛿gt 𝒚 𝑝 𝒚 𝑿
= 𝛿gt 𝒚 log
𝛿gt 𝒚
𝑝 𝒚 𝑿
𝑑𝒚
= − 𝛿gt 𝒚 log 𝑝 𝒚 𝑿 𝑑𝒚 + const
= −log 𝑝 𝒚gt 𝑿 + const
=
1
2
𝒆𝒓𝒓 𝒚gt, 𝑿
2
+ log exp −
1
2
𝒆𝒓𝒓 𝒚, 𝑿 2
𝑑𝒚
𝛿gt(𝒚)
𝑝(𝒚|𝑿)
確率密度関数におけるKLDの定義
𝑿に関わらない項を定数に
デルタ関数の積分の定義
𝑝(𝒚|𝑿)の定義,const省略
GT姿勢の確率を最大化 他の姿勢の確率を最小化
確率分布](https://image.slidesharecdn.com/20220722dlseminarsepro-pnp-220725010500-ac894d78/85/DL-EPro-PnP-Generalized-End-to-End-Probabilistic-Perspective-n-Pointsfor-Monocular-Object-Pose-Estimation-10-320.jpg)

![5. 実験結果: 6次元姿勢推定
12
6次元姿勢推定[2]
CDPN: PnPベースの6次元姿勢推定従来法](https://image.slidesharecdn.com/20220722dlseminarsepro-pnp-220725010500-ac894d78/85/DL-EPro-PnP-Generalized-End-to-End-Probabilistic-Perspective-n-Pointsfor-Monocular-Object-Pose-Estimation-12-320.jpg)
![5. 実験結果: 3次元物体検出
13
3次元物体検出(車載系)[3]
平面上2次元位置
鉛直方向1次元回転](https://image.slidesharecdn.com/20220722dlseminarsepro-pnp-220725010500-ac894d78/85/DL-EPro-PnP-Generalized-End-to-End-Probabilistic-Perspective-n-Pointsfor-Monocular-Object-Pose-Estimation-13-320.jpg)

![引用
[1] Perspective-n-Point問題 http://www.sanko-shoko.net/note.php?id=y15w
[2] EfficientPose https://github.com/ybkscht/EfficientPose
[3] KITTI http://www.cvlibs.net/datasets/kitti/
[4] Dirac delta https://jp.mathworks.com/help/symbolic/sym.dirac.html
15](https://image.slidesharecdn.com/20220722dlseminarsepro-pnp-220725010500-ac894d78/85/DL-EPro-PnP-Generalized-End-to-End-Probabilistic-Perspective-n-Pointsfor-Monocular-Object-Pose-Estimation-15-320.jpg)


![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/pvrcnn-200311050009-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]3D Human Pose Estimation @ CVPR’19 / ICCV’19](https://cdn.slidesharecdn.com/ss_thumbnails/190816dlseminar3dhpe-190816032821-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/20170821onodeepposepresentation-170928100207-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]CVPR2019:Weakly-Supervised Discovery of Geometry-Aware Representation ...](https://cdn.slidesharecdn.com/ss_thumbnails/weaklysuperviseddiscoveryofgeometryawarerepresentationfor3dhumanposeestimation-190722094452-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)






















