Downloaded 214 times



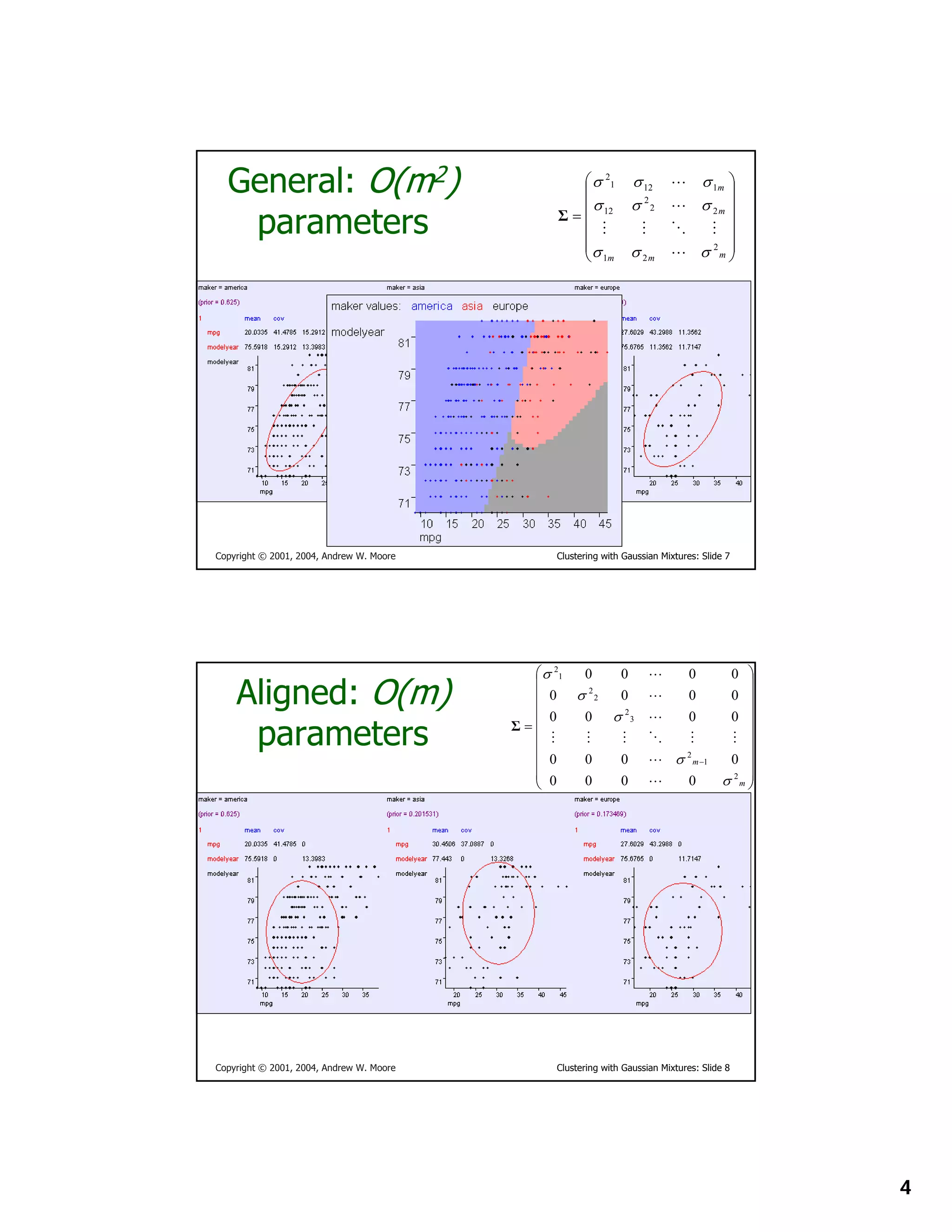


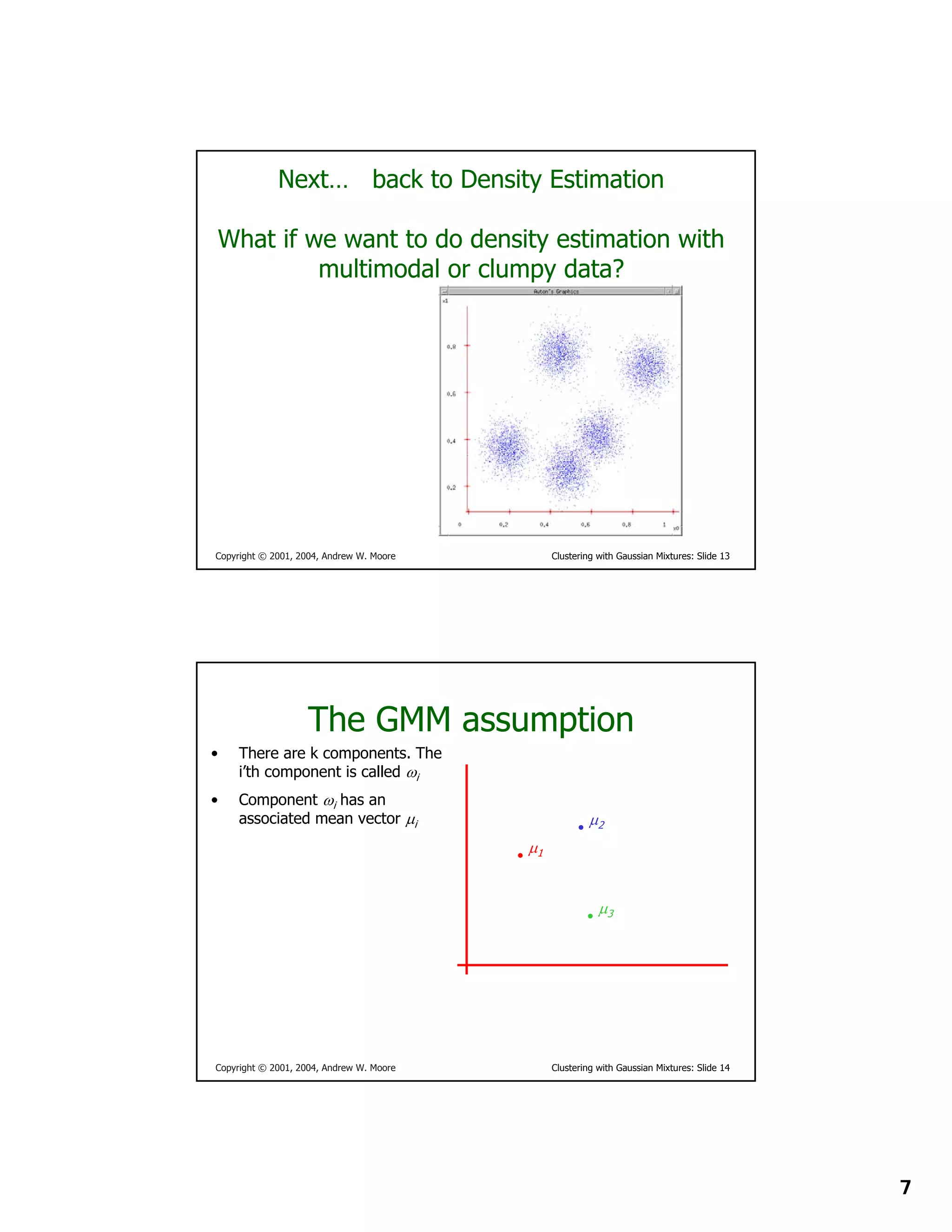




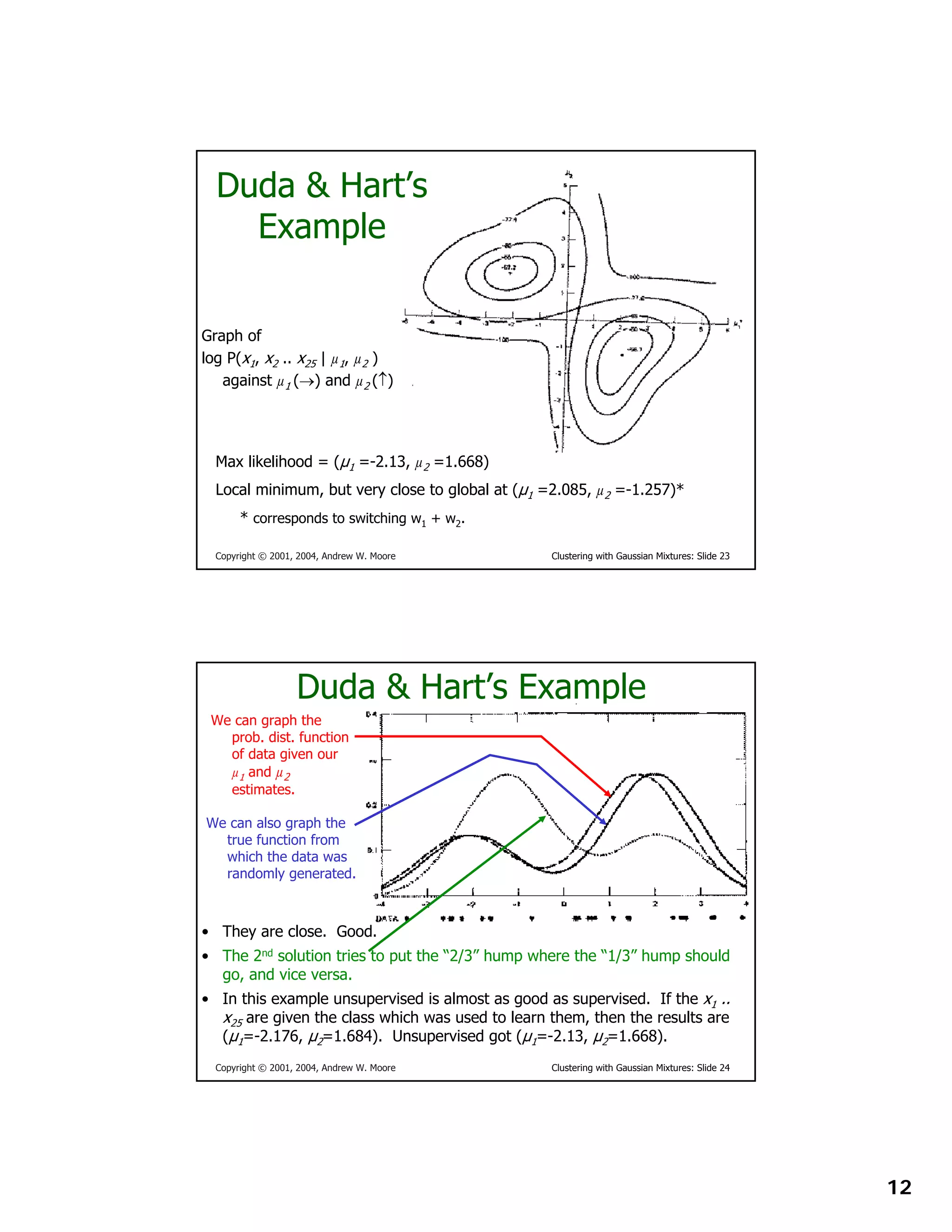

















This document provides instructions for other teachers to use and modify slides from a lecture on clustering with Gaussian mixtures given by Andrew W. Moore. It notes that the PowerPoint originals are available and encourages comments and corrections. Users are asked to include attribution if using a significant portion of the slides.



















![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)