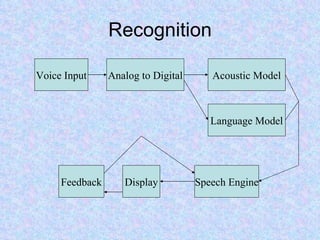
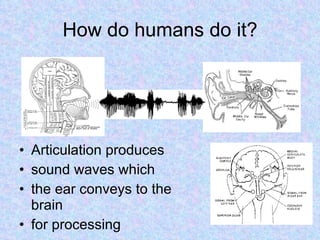
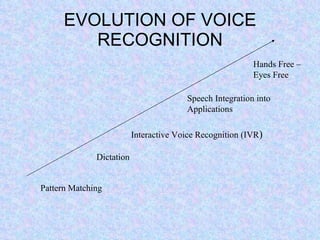
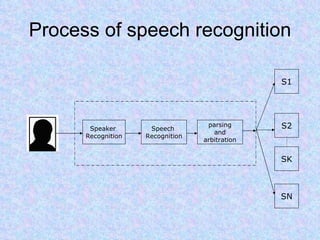
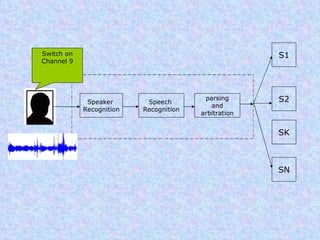
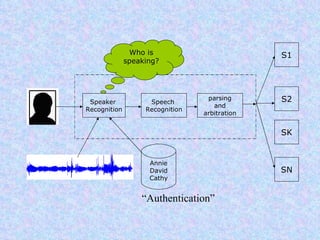
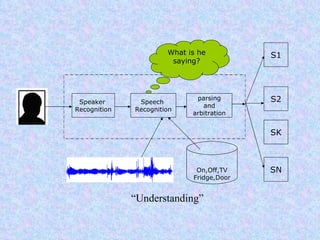
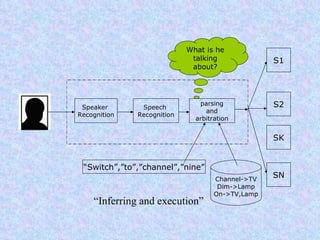
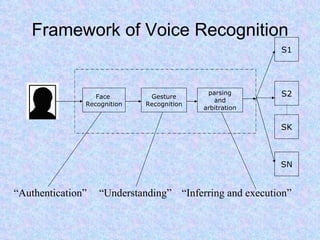
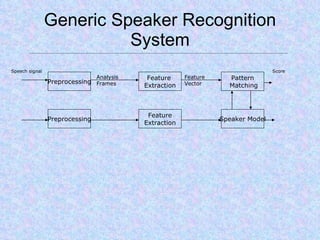
Speech recognition, also known as automatic speech recognition or computer speech recognition, allows computers to understand human voice. It has various applications such as dictation, system control/navigation, and commercial/industrial uses. The process involves converting analog audio of speech into digital format, then using acoustic and language models to analyze the speech and output text. There are two main types: speaker-dependent which requires training a model for each user, and speaker-independent which can recognize any voice without training. Accuracy is improving over time as technology advances.