



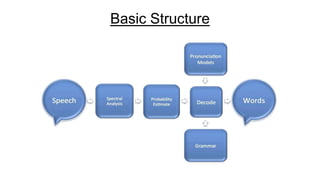






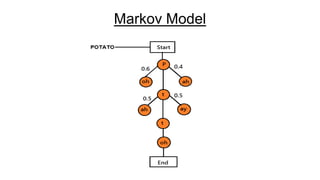

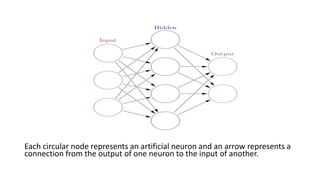

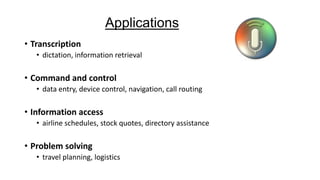







Speech recognition, also known as automatic speech recognition (ASR), involves converting acoustic signals into words for various applications such as voice commands and transcription. It relies on digital sampling, acoustic models, and statistical modeling systems, including hidden Markov models and neural networks, to process speech effectively. The technology faces challenges such as noise interference and dialect variations but is evolving towards achieving near-instantaneous language translation and potential speech understanding.





































































































