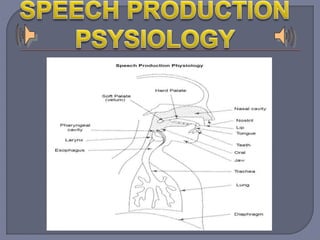
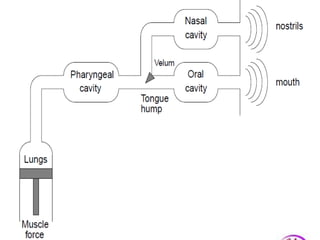
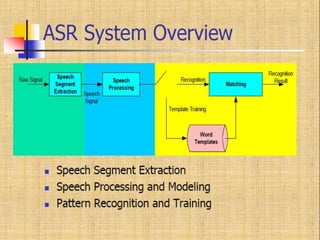
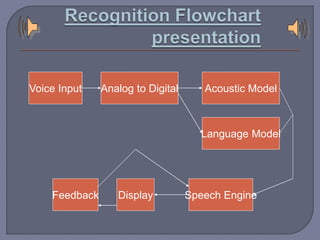
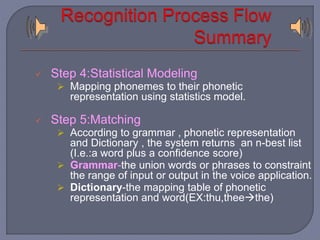
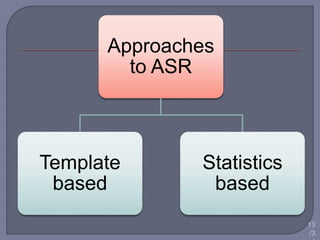
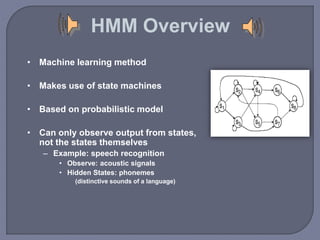
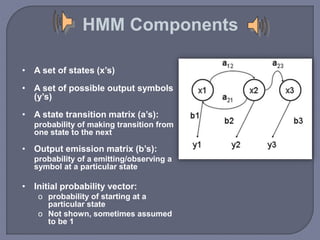
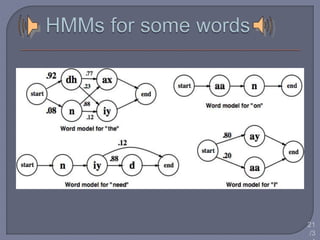
Speech recognition technology decodes acoustic signals into words and can be categorized into speaker independent, speaker dependent, and emerging speaker adaptive models. The process involves several steps, including user voice input, digitization, phonetic breakdown, and statistical modeling to match phonemes to their phonetic representations. Applications range from voice dialing and simple data entry to advanced uses in aircraft cockpits and serving the disabled, with challenges such as speaker variability and channel quality affecting accuracy.