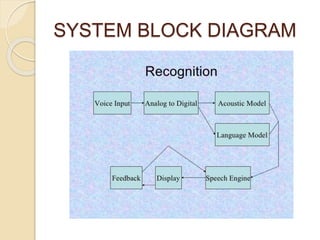
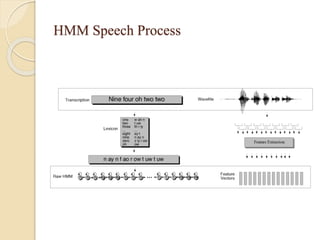
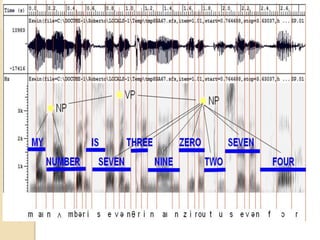
Our speech to text conversion project aims to help the nearly 20% of people worldwide with disabilities by allowing them to control their computer and share information using only their voice. The system uses acoustic and language models with a speech engine to recognize speech and convert it to text. It can perform operations like opening calculator and wordpad. Speech recognition has applications in areas like cars, healthcare, education and daily life. Accuracy depends on factors like vocabulary size, speaker dependence, and speech type (isolated, continuous). The system aims to improve accessibility while reducing costs.