Downloaded 48 times








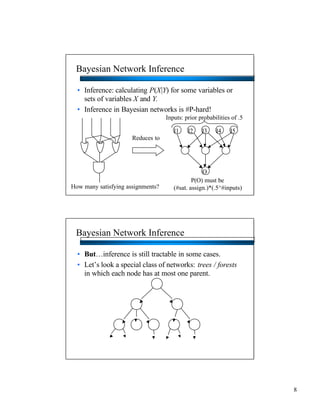

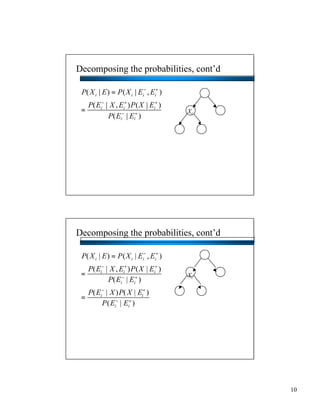





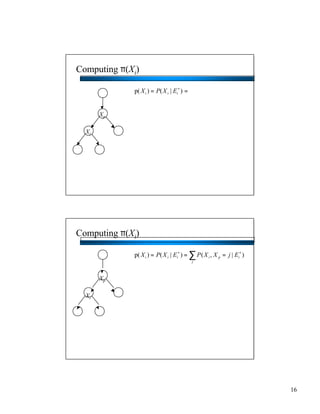
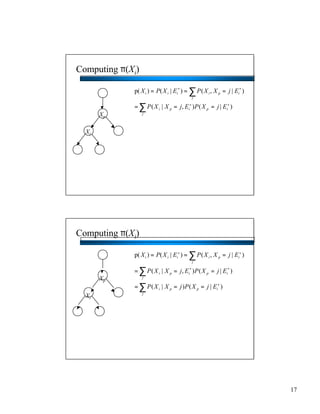


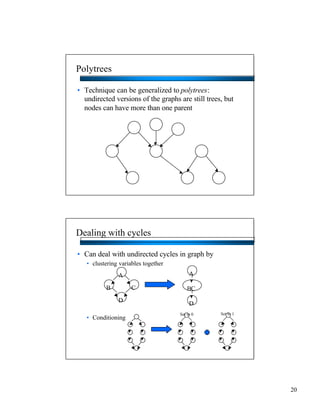

- Bayesian networks can model conditional independencies between variables based on the network structure. Each variable is conditionally independent of its non-descendants given its parents. - The d-separation algorithm allows determining if two variables are conditionally independent given some evidence by checking if all paths between them are "blocked". - For trees/forests where each node has at most one parent, inference can be done efficiently in linear time by decomposing probabilities and passing messages between nodes.
















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

