Downloaded 73 times

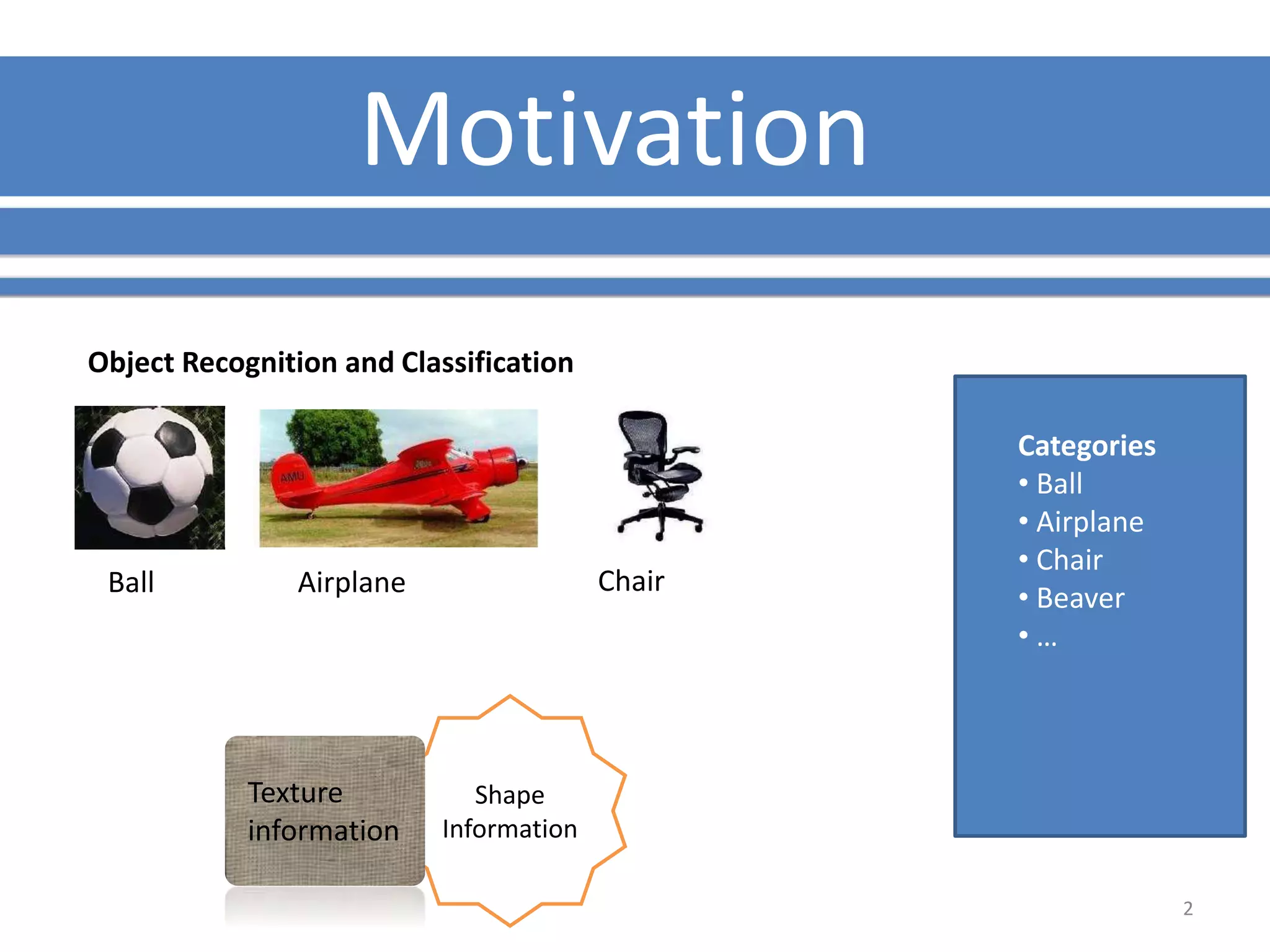


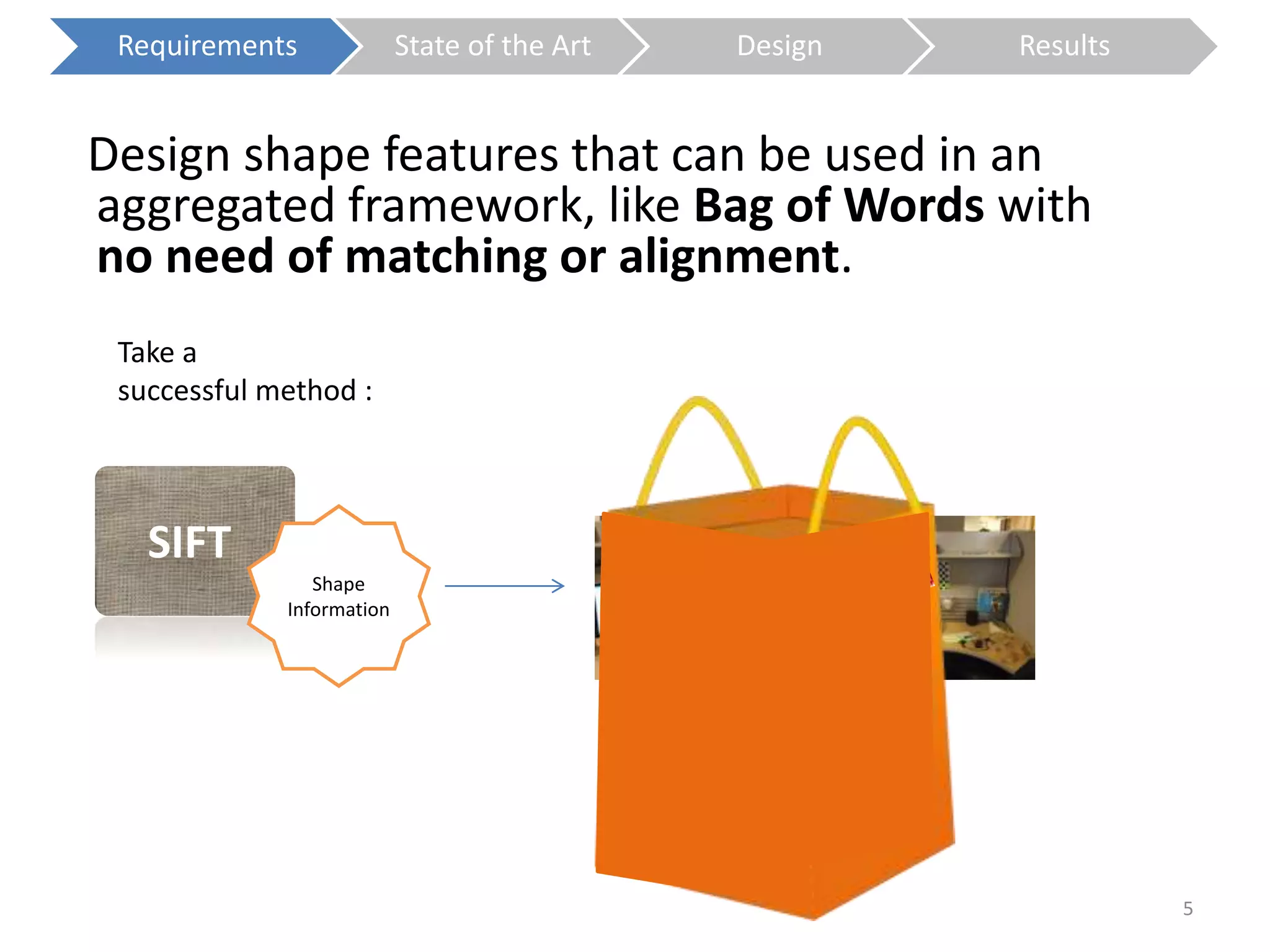
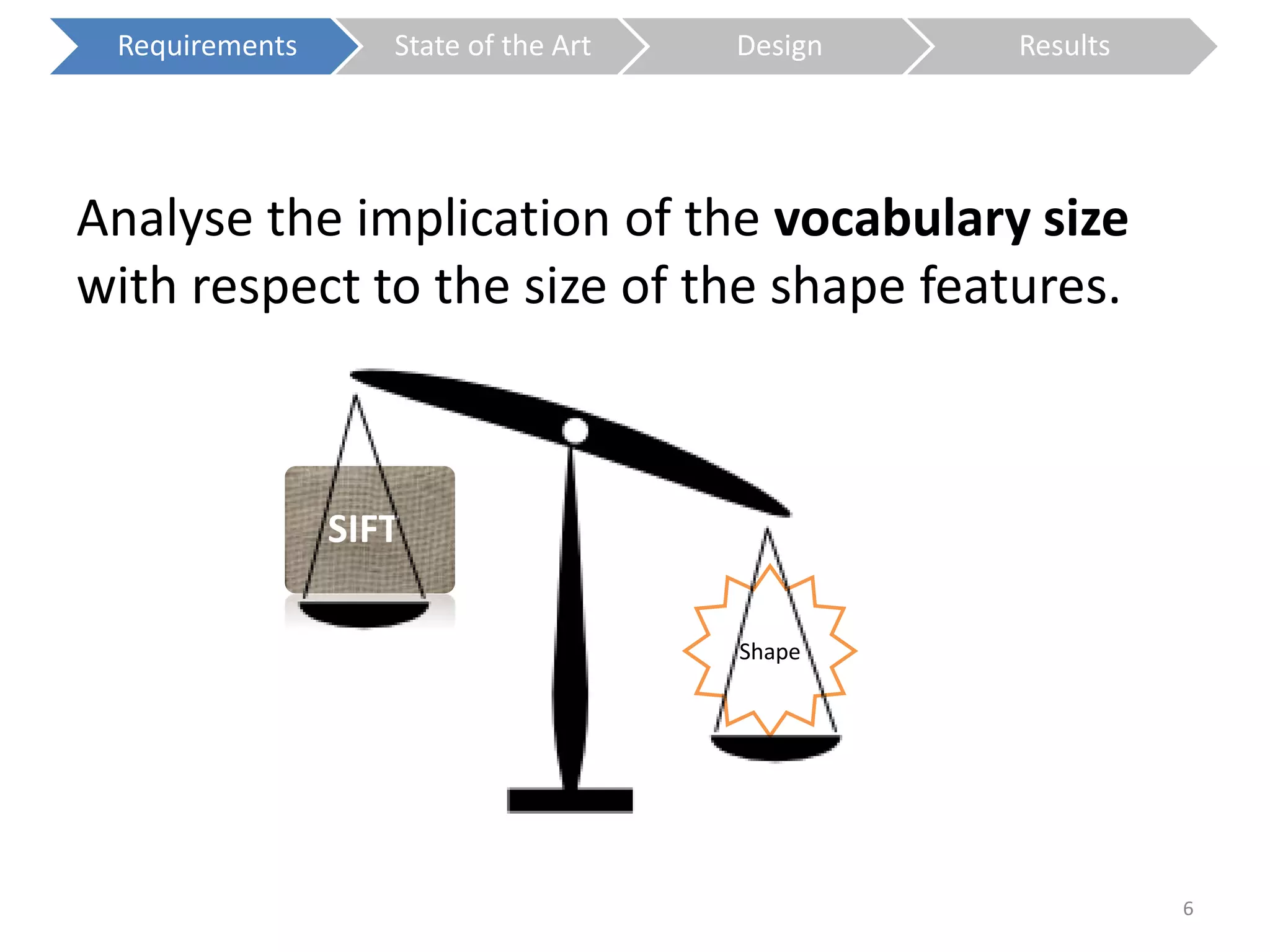




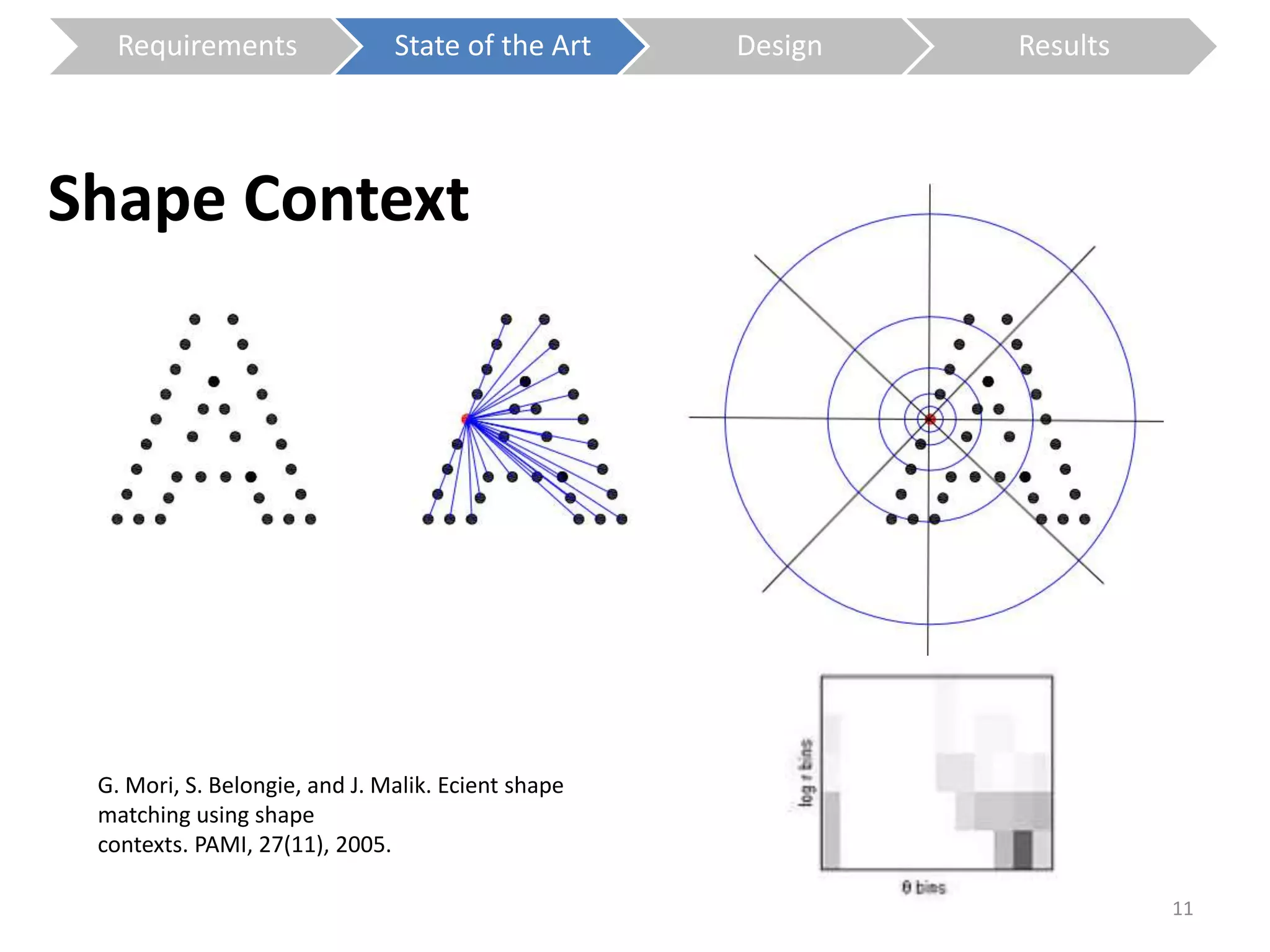
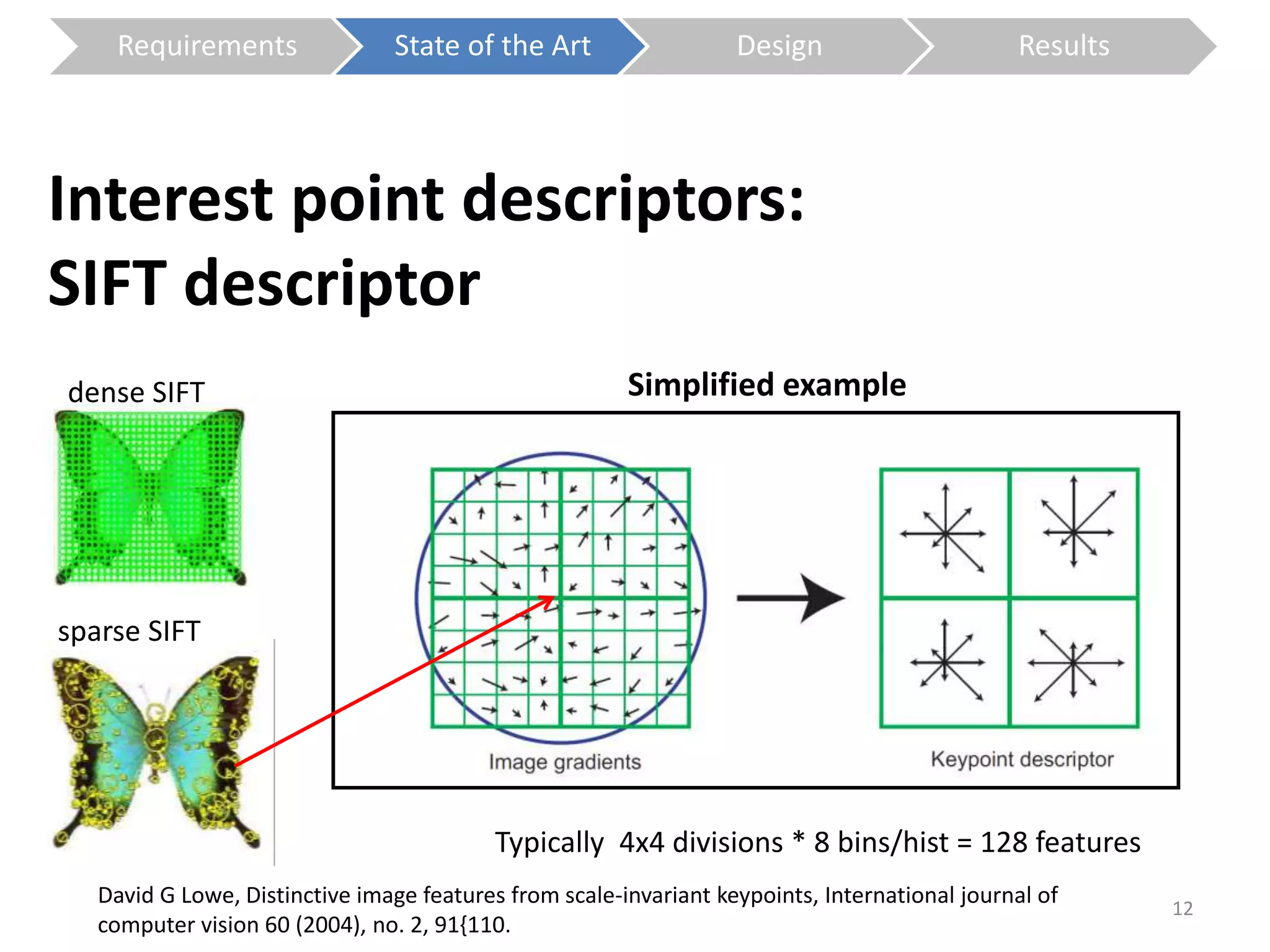

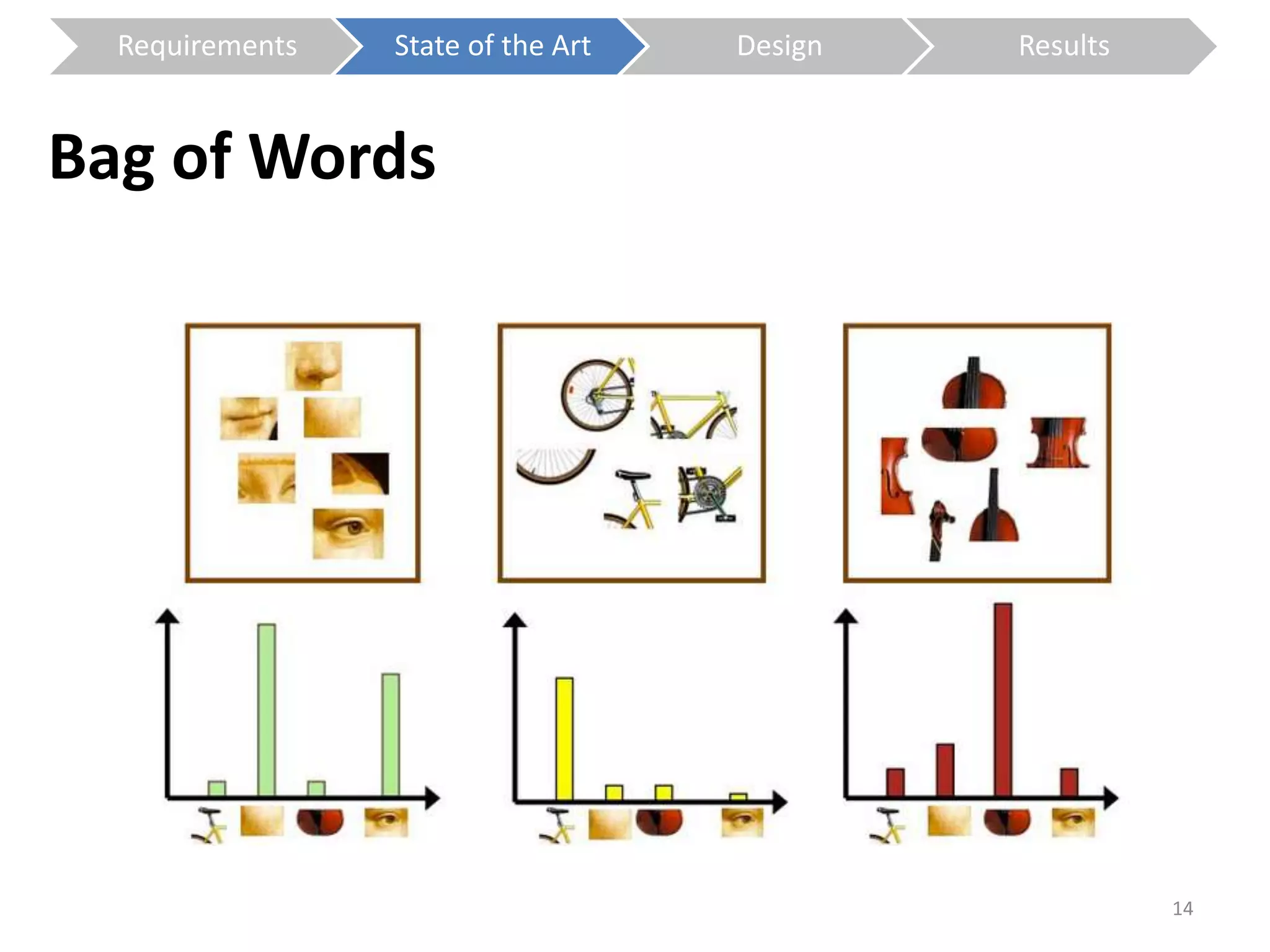
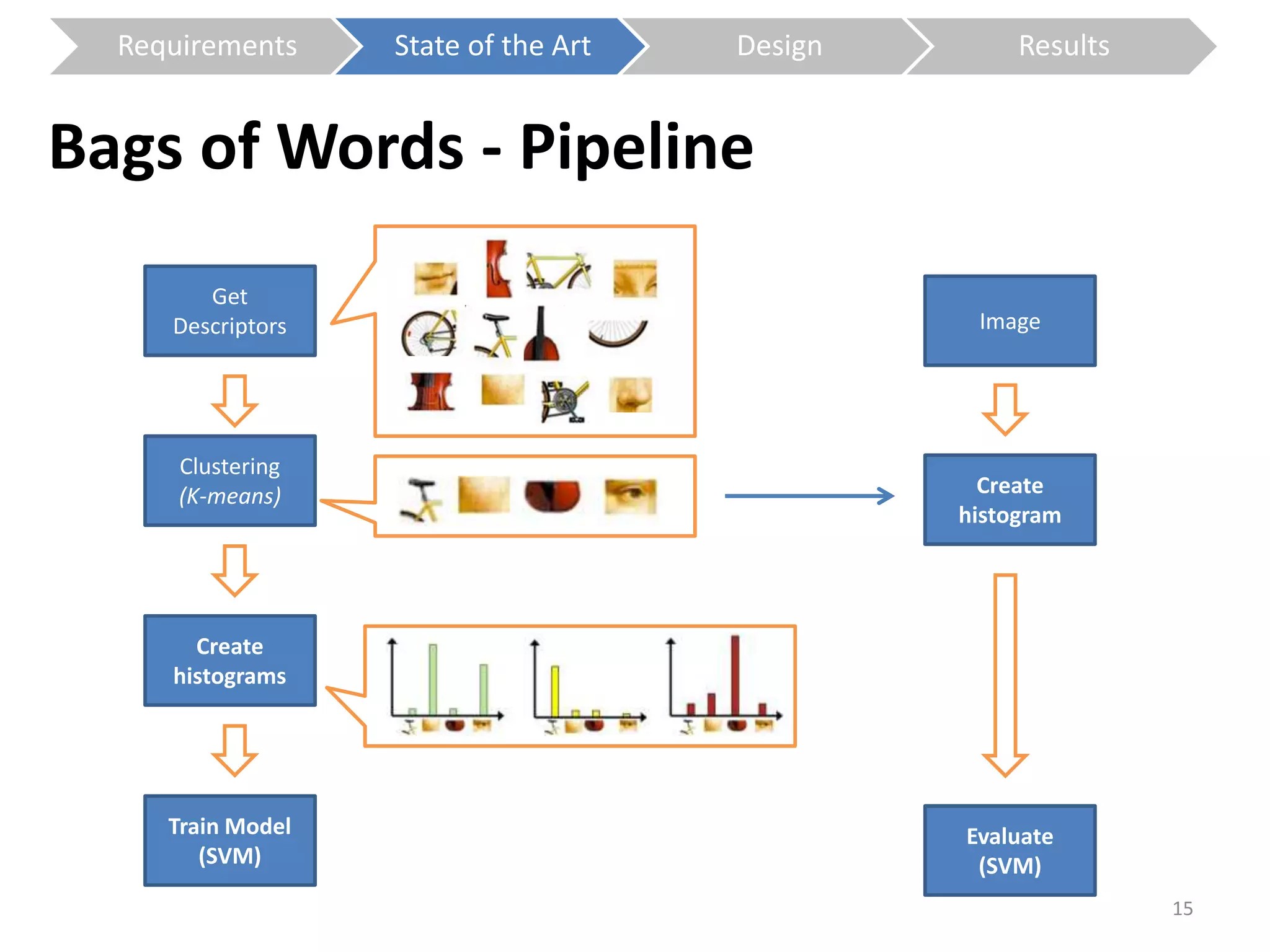

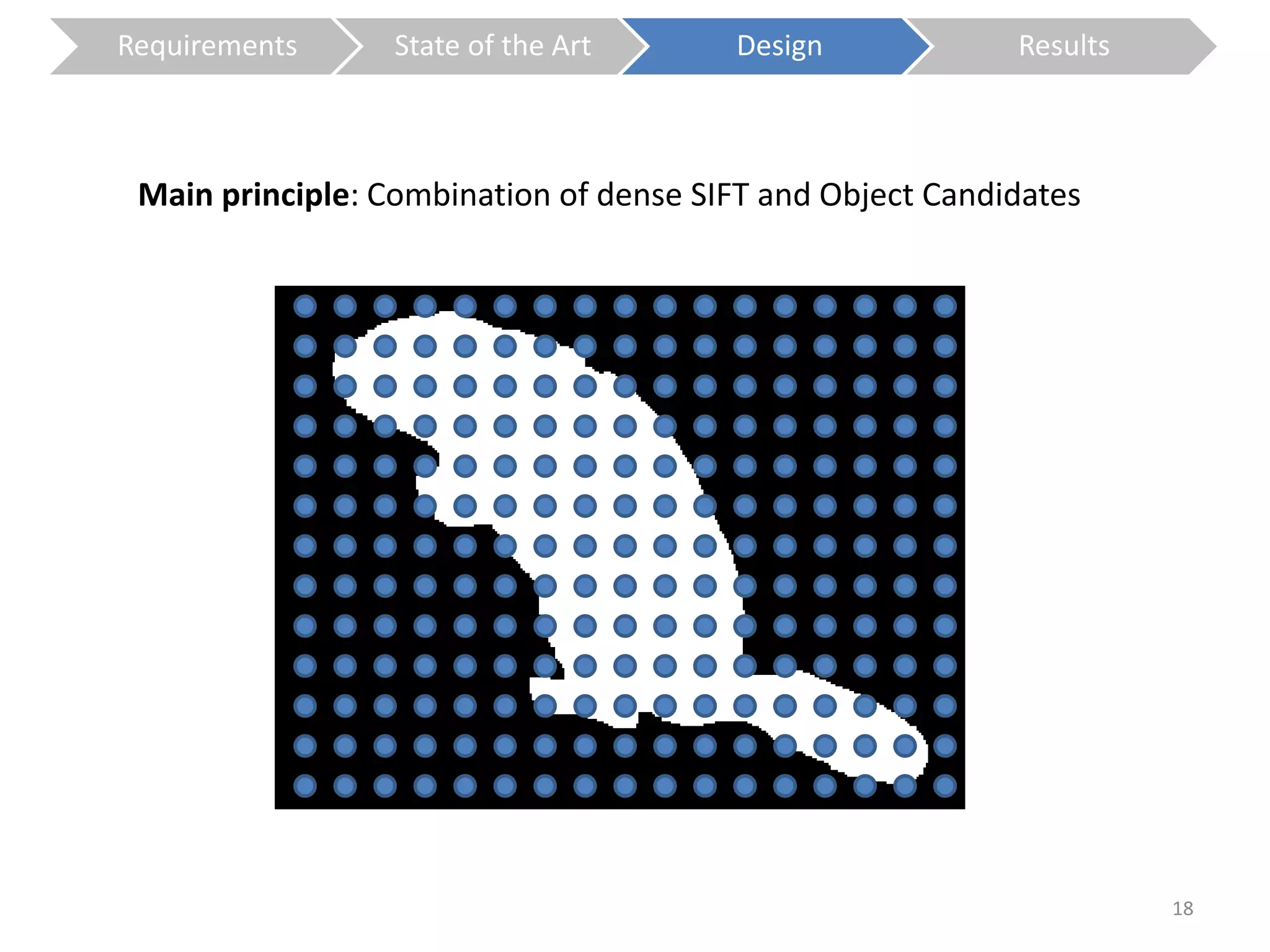
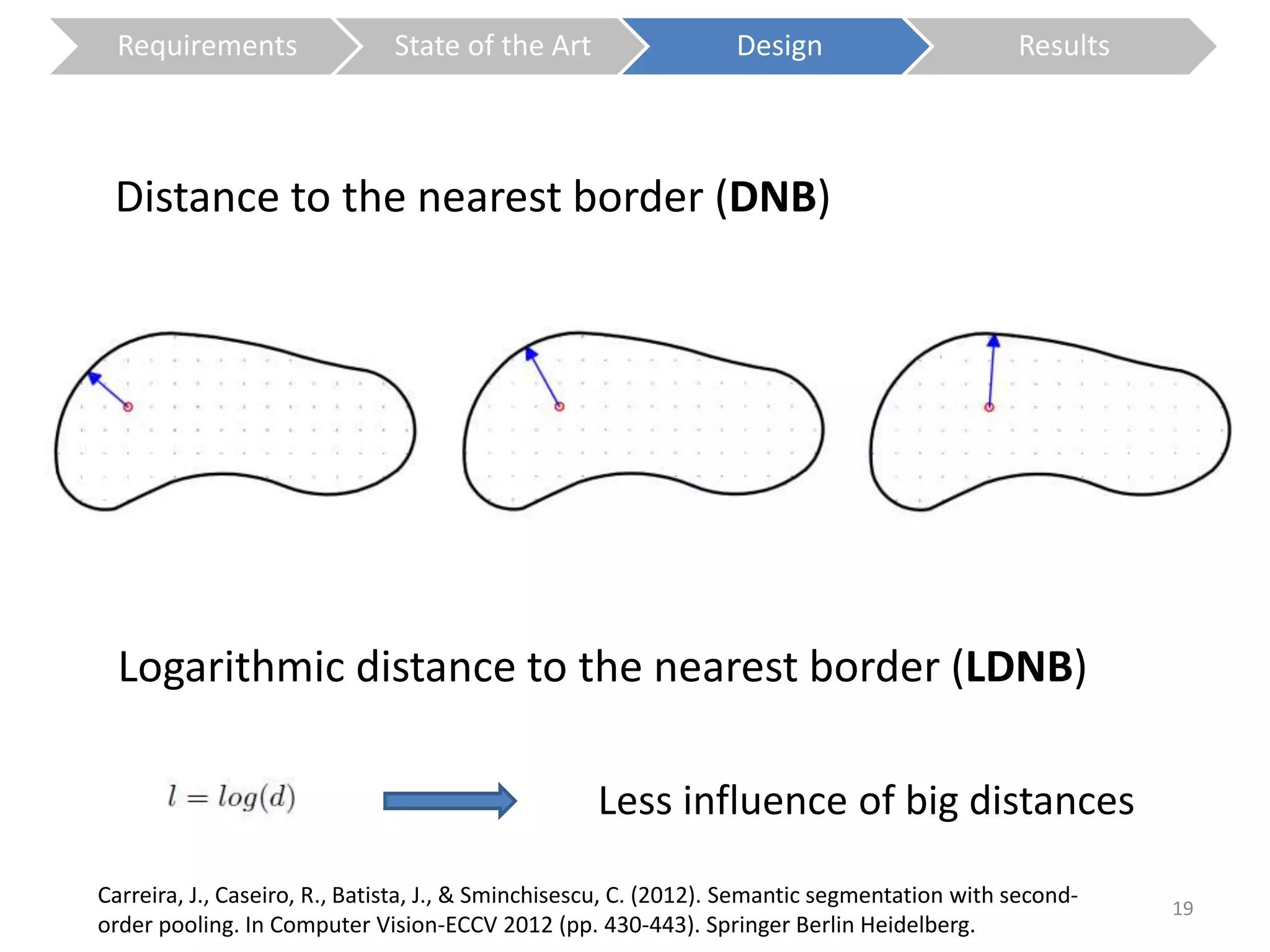
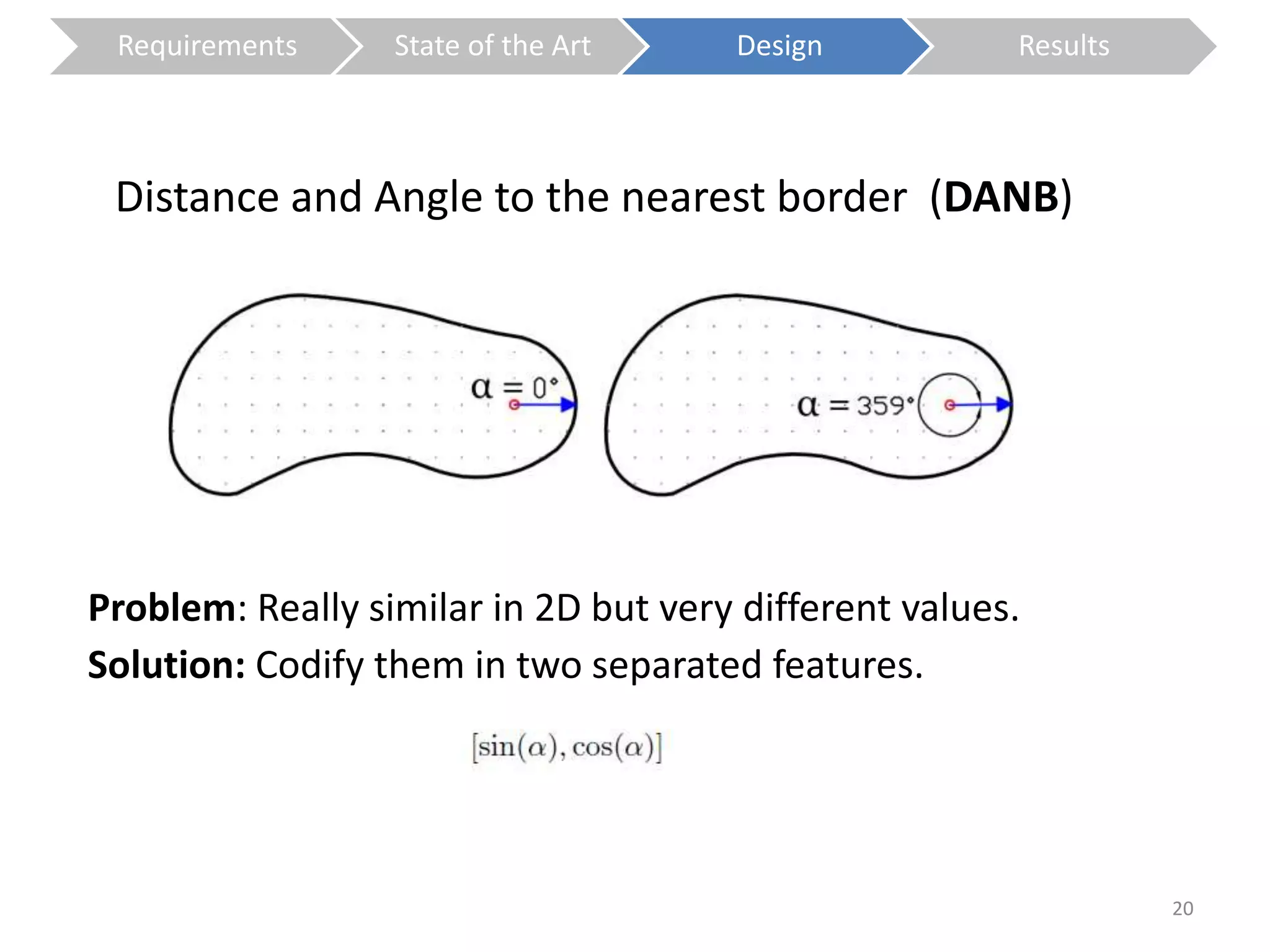
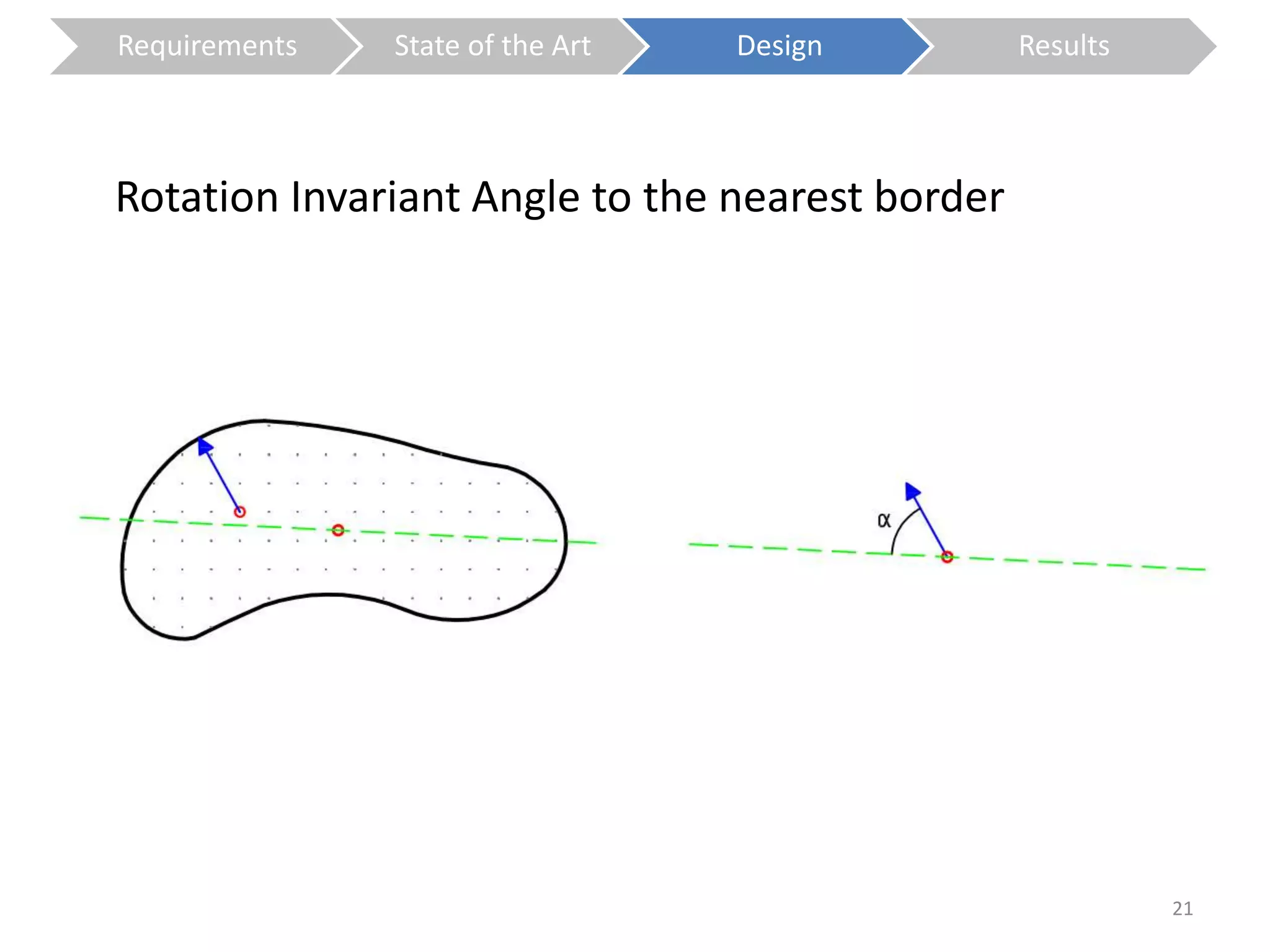
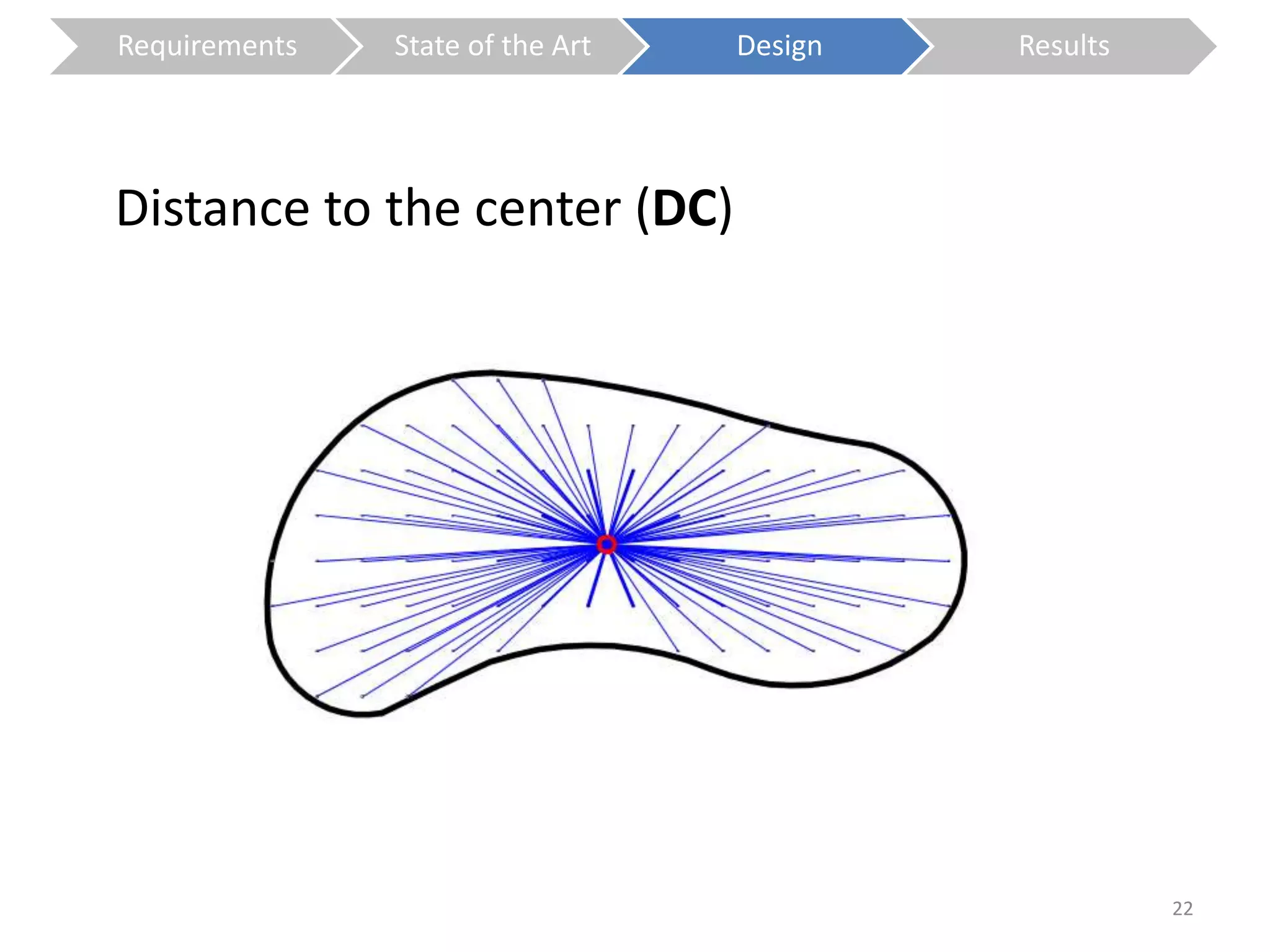
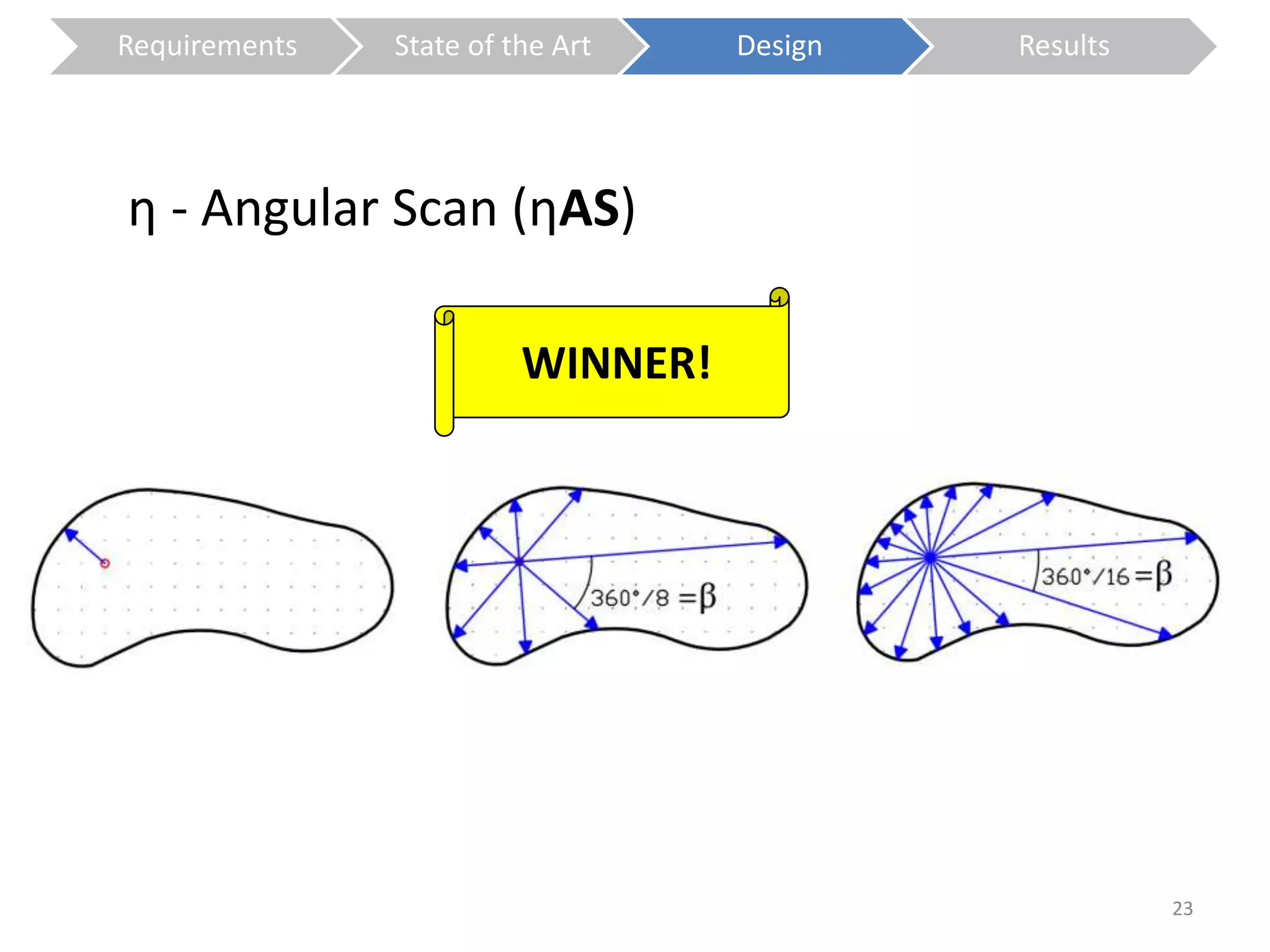
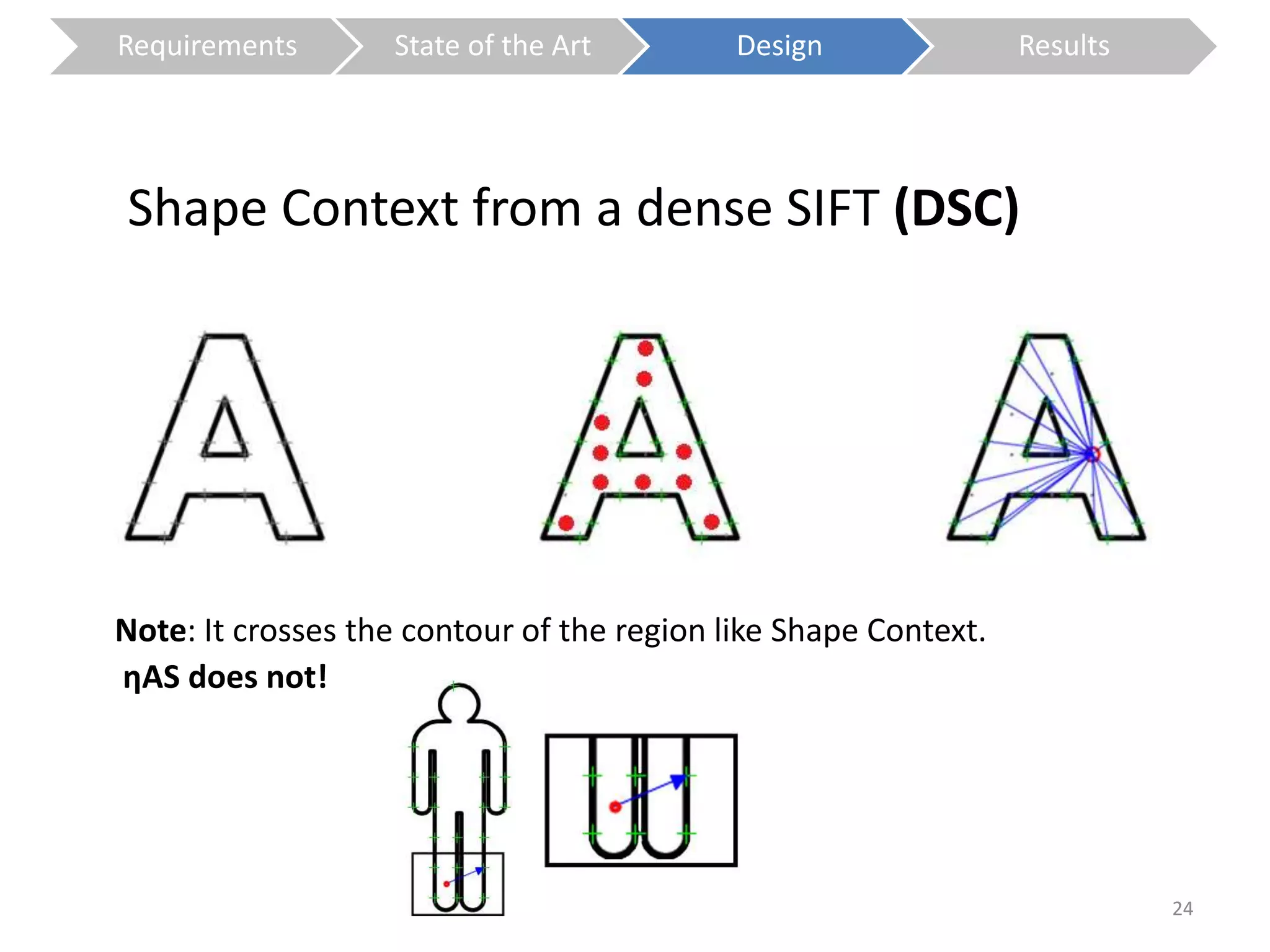
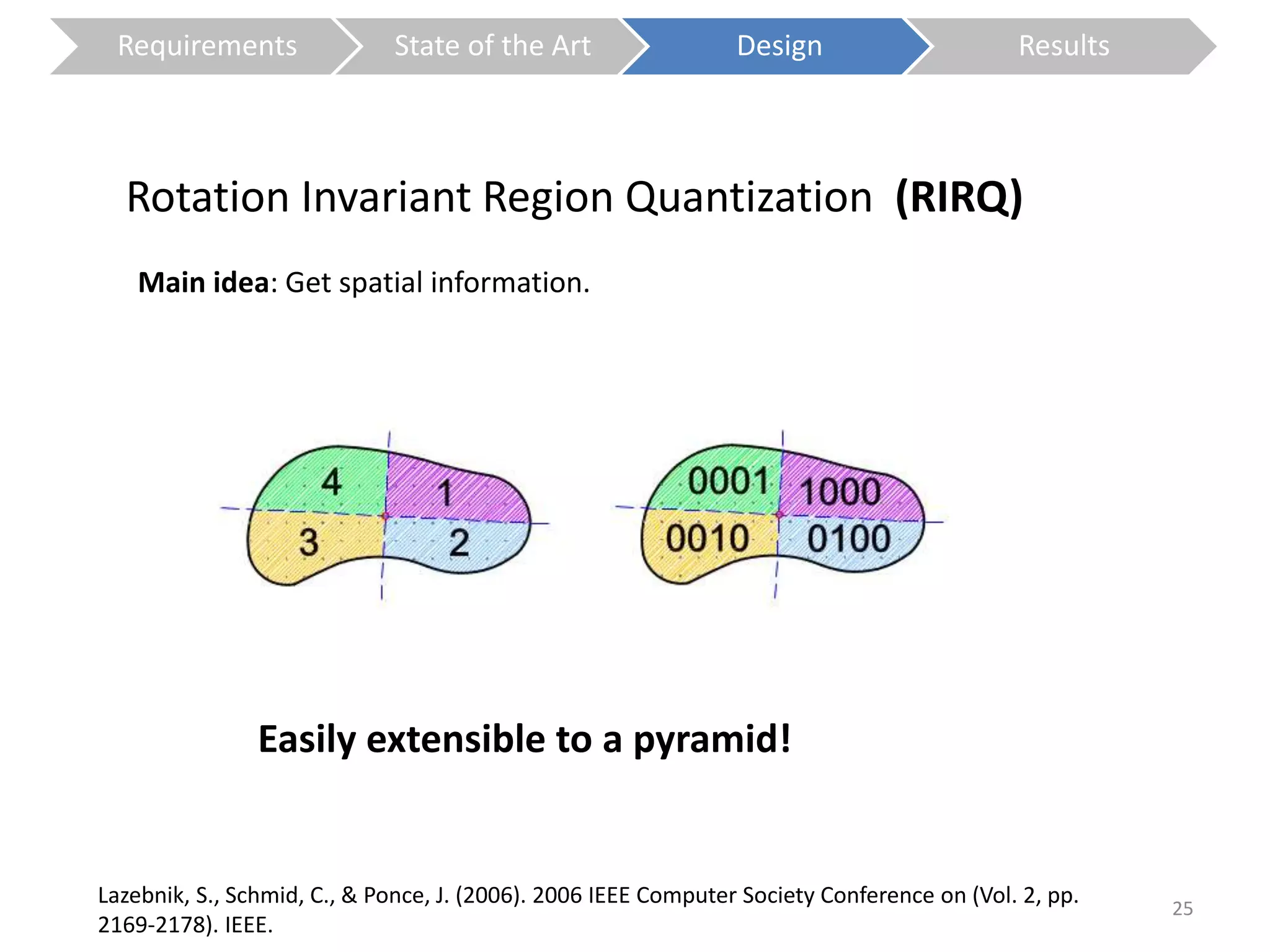
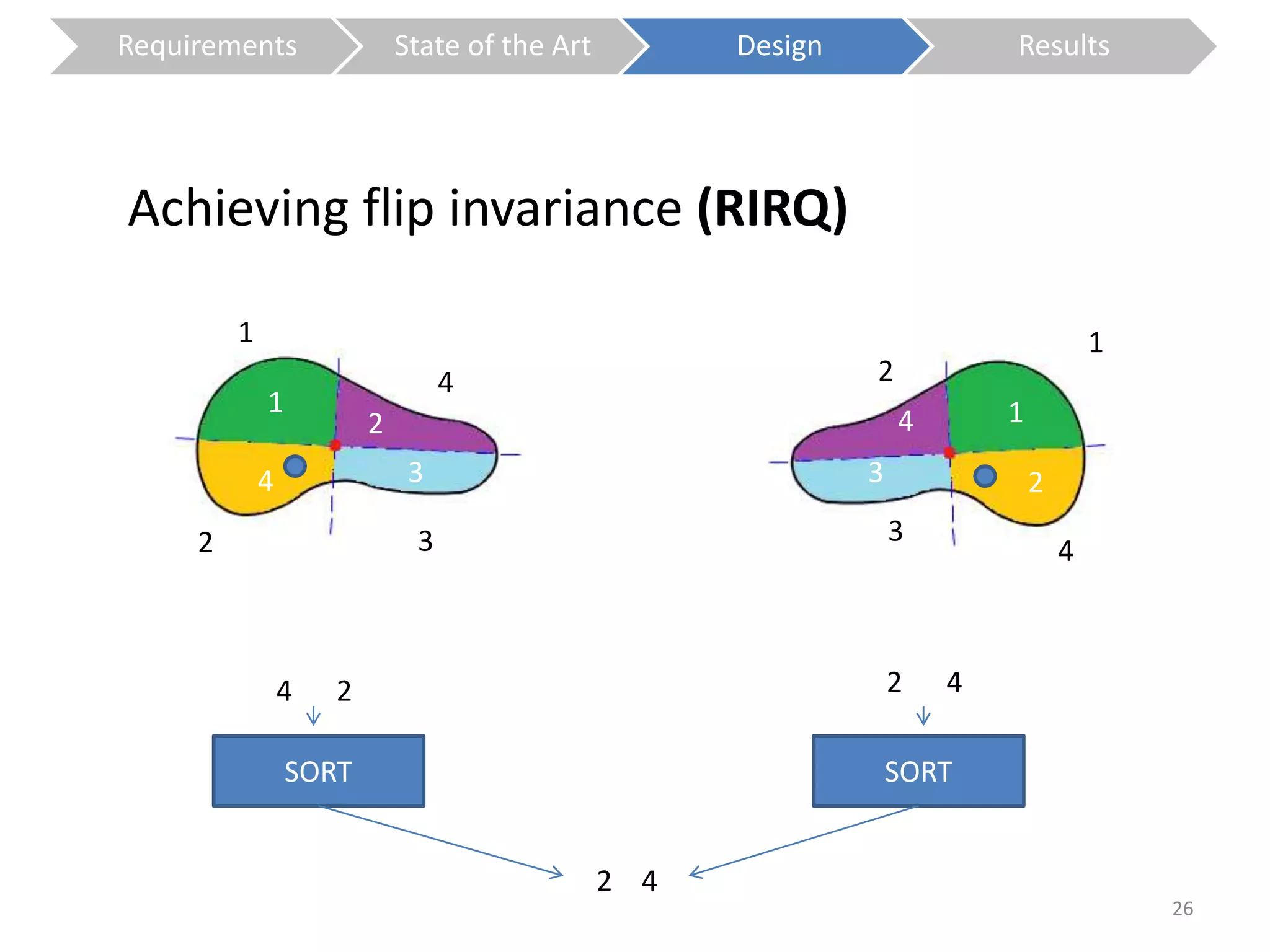
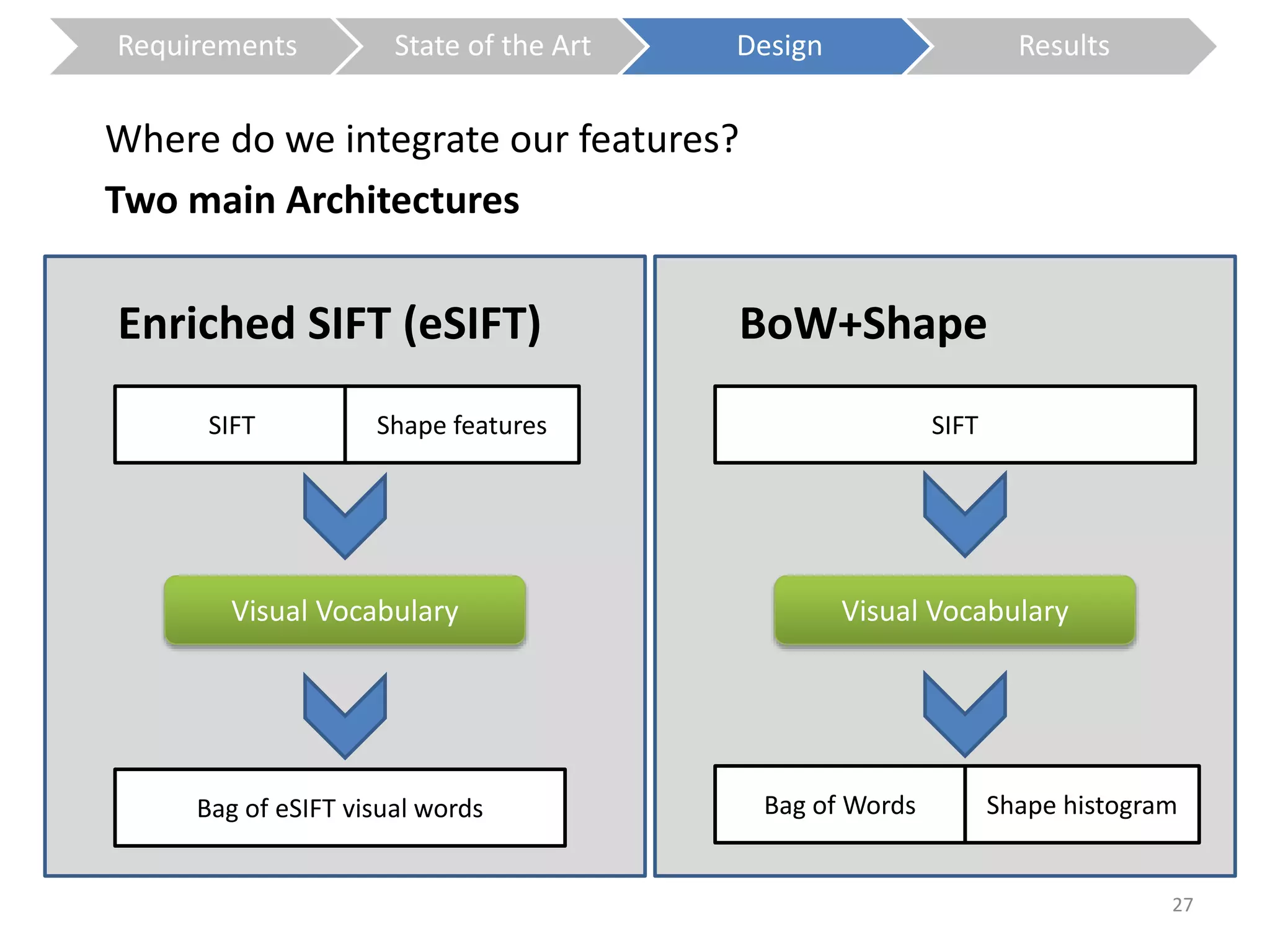
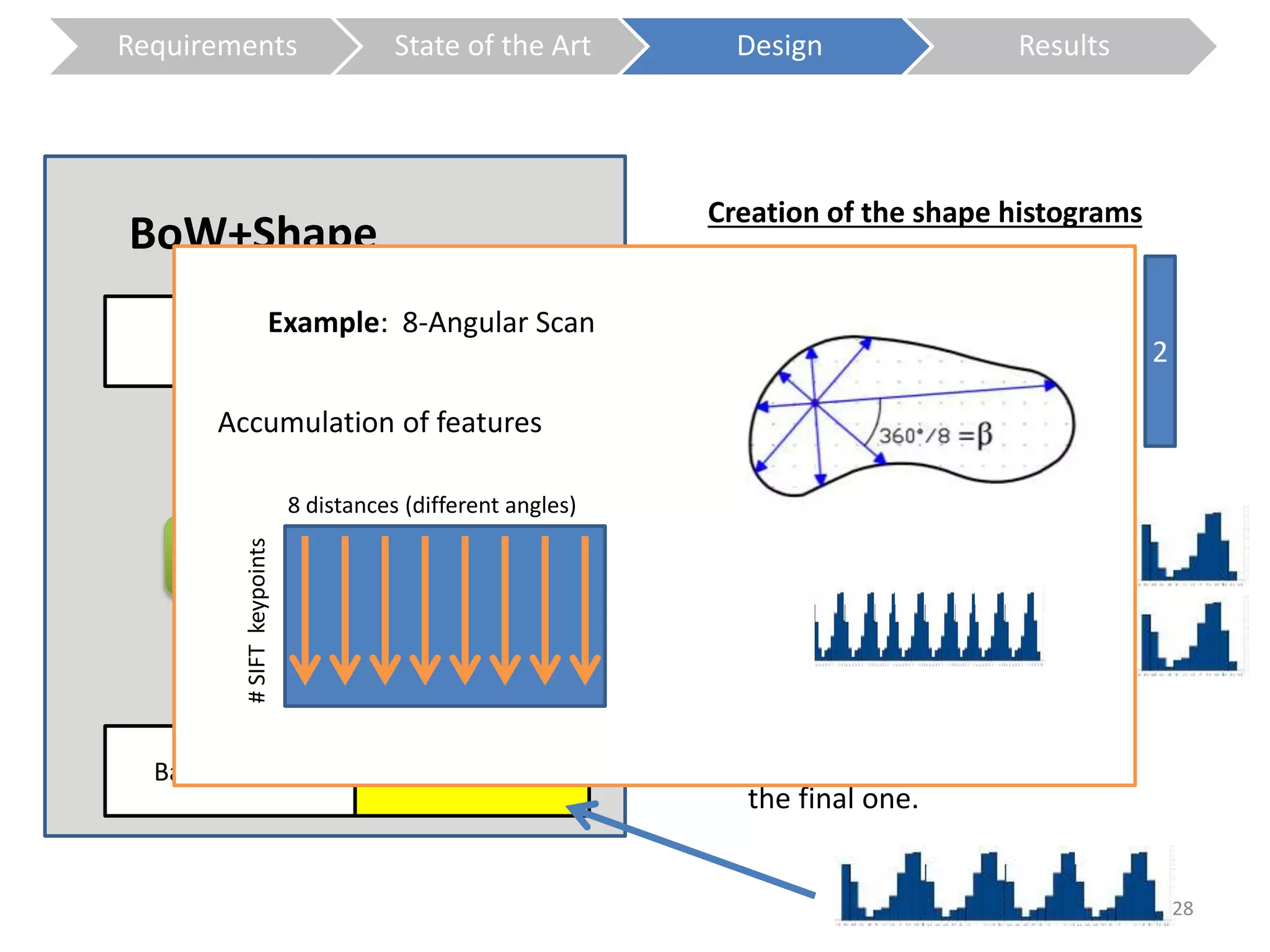




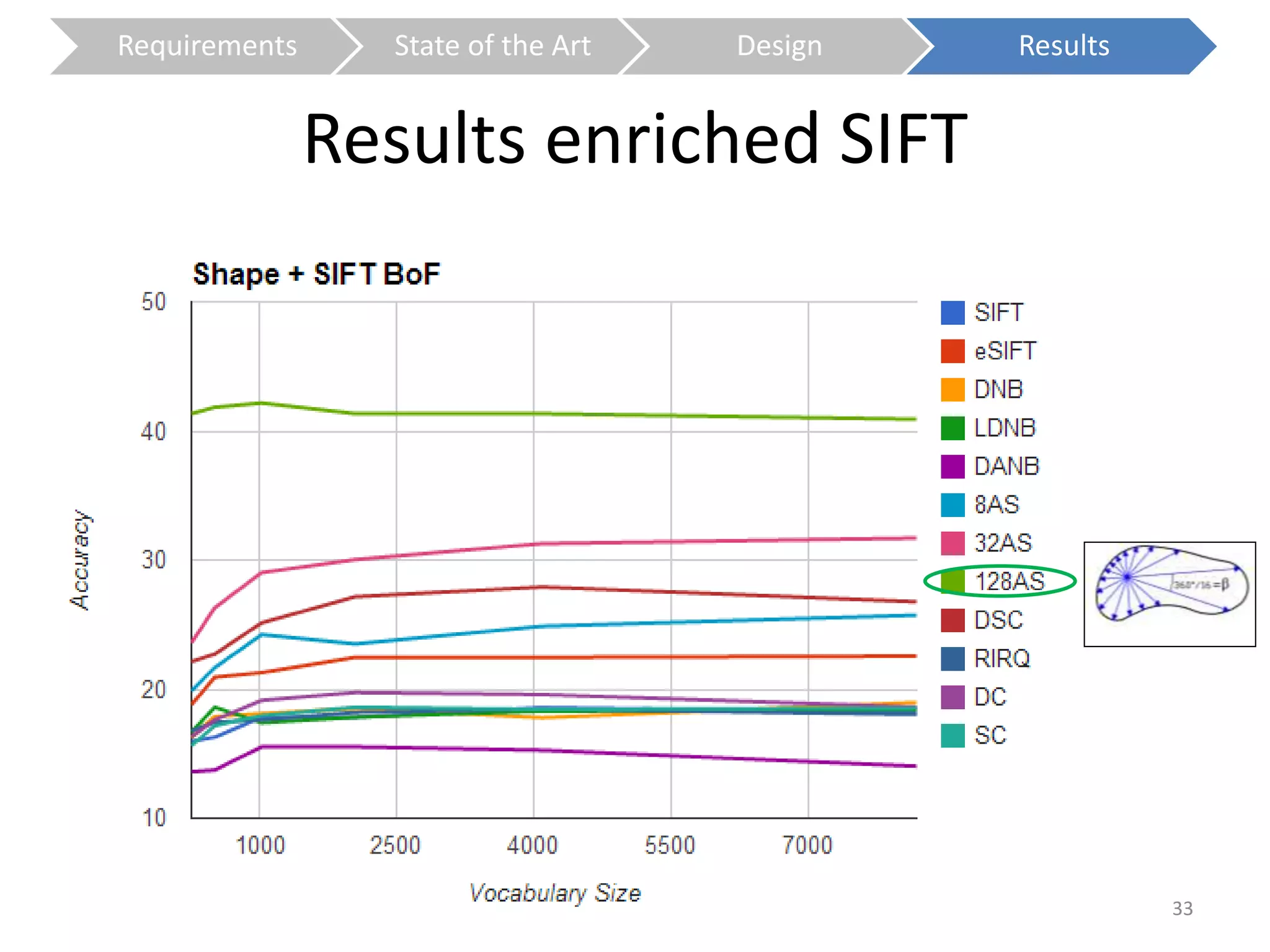
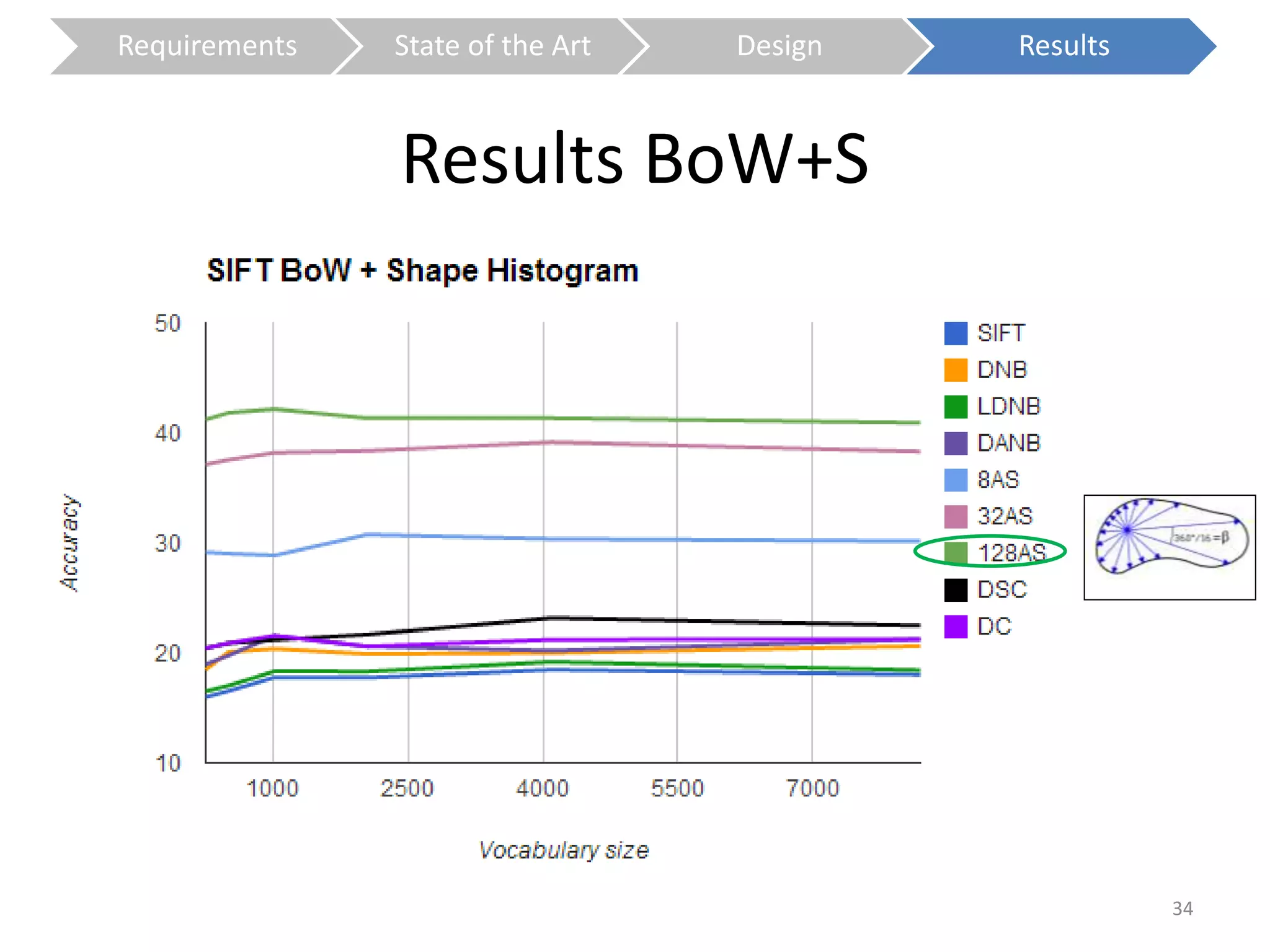
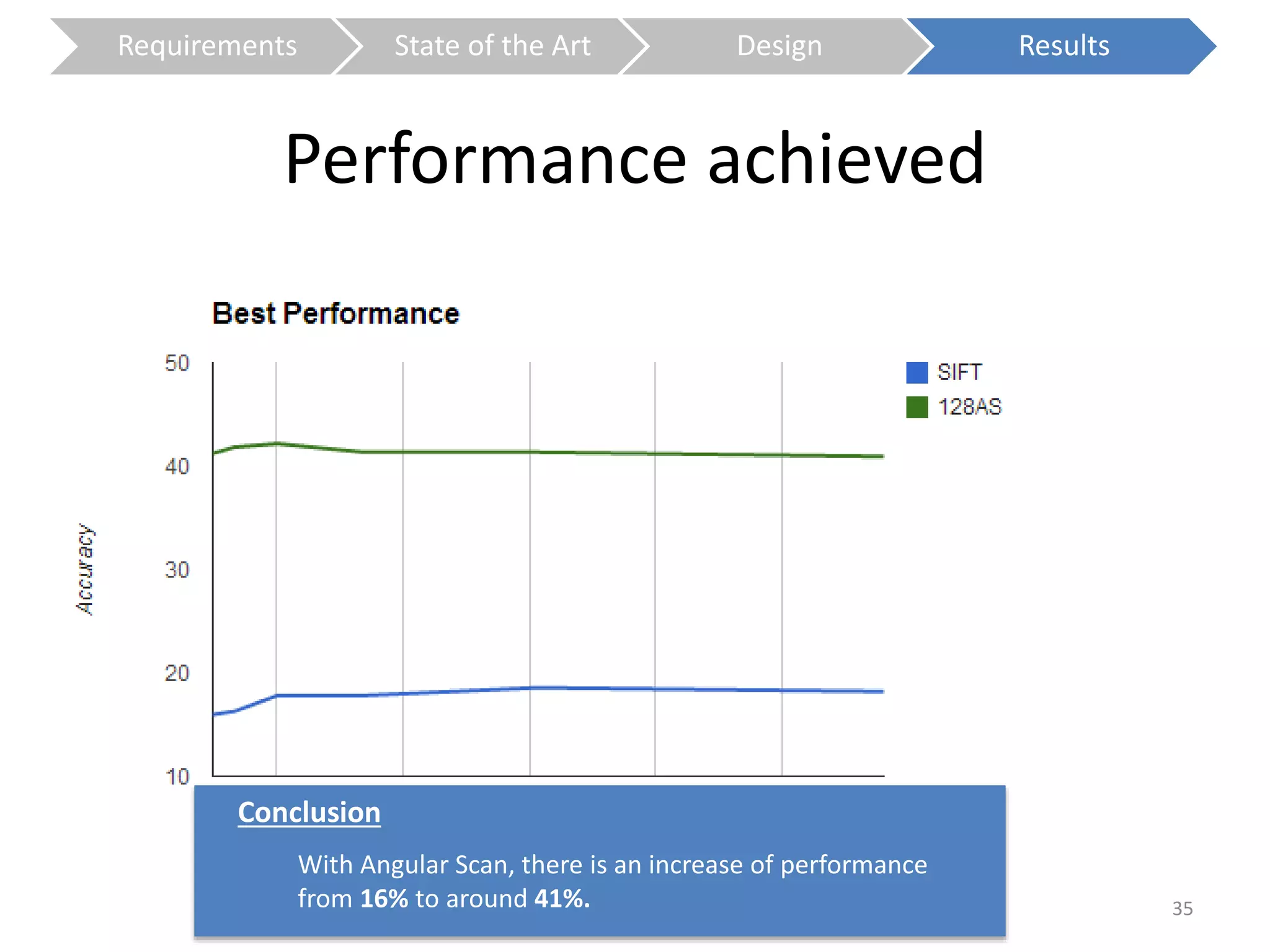
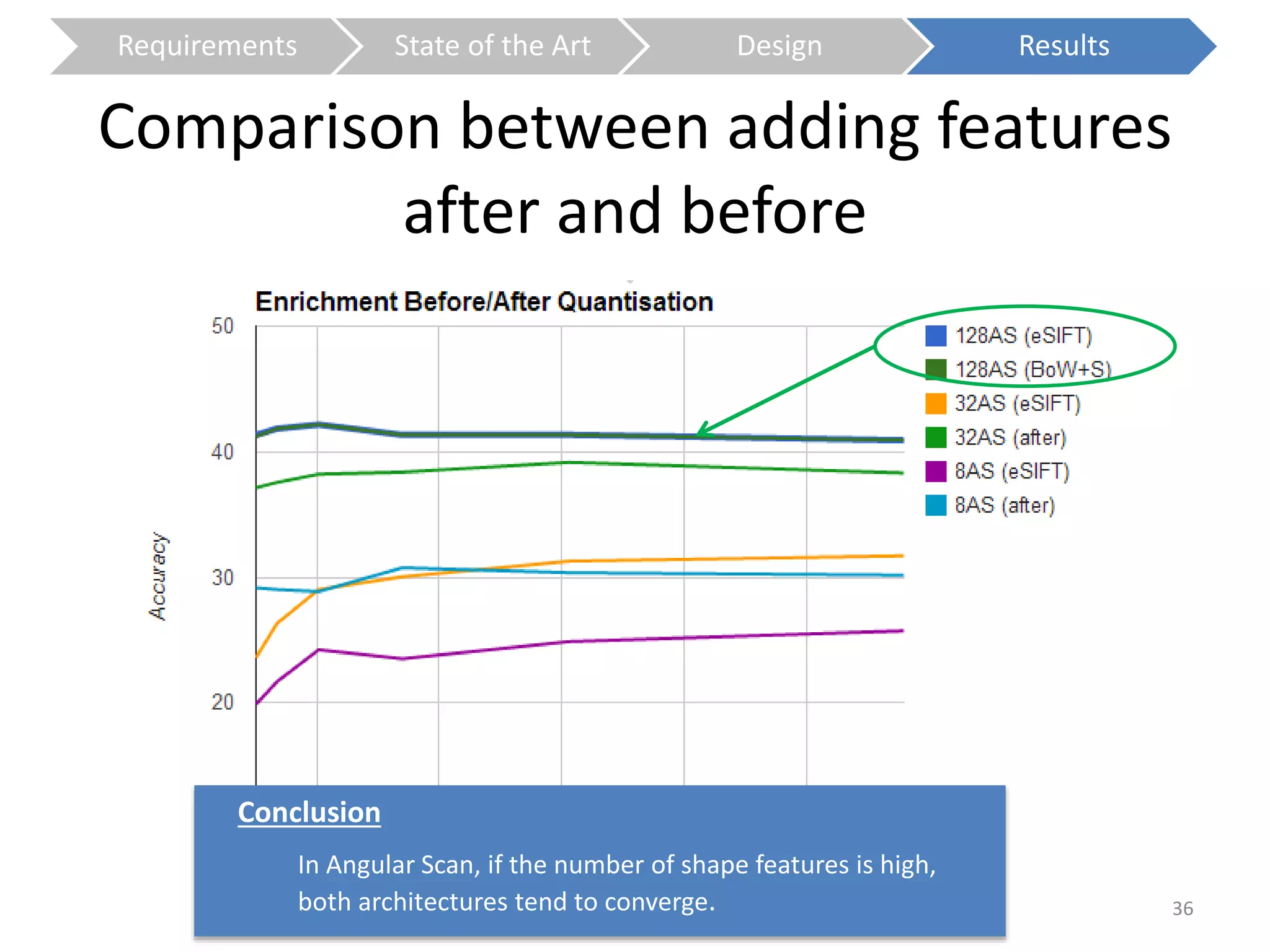
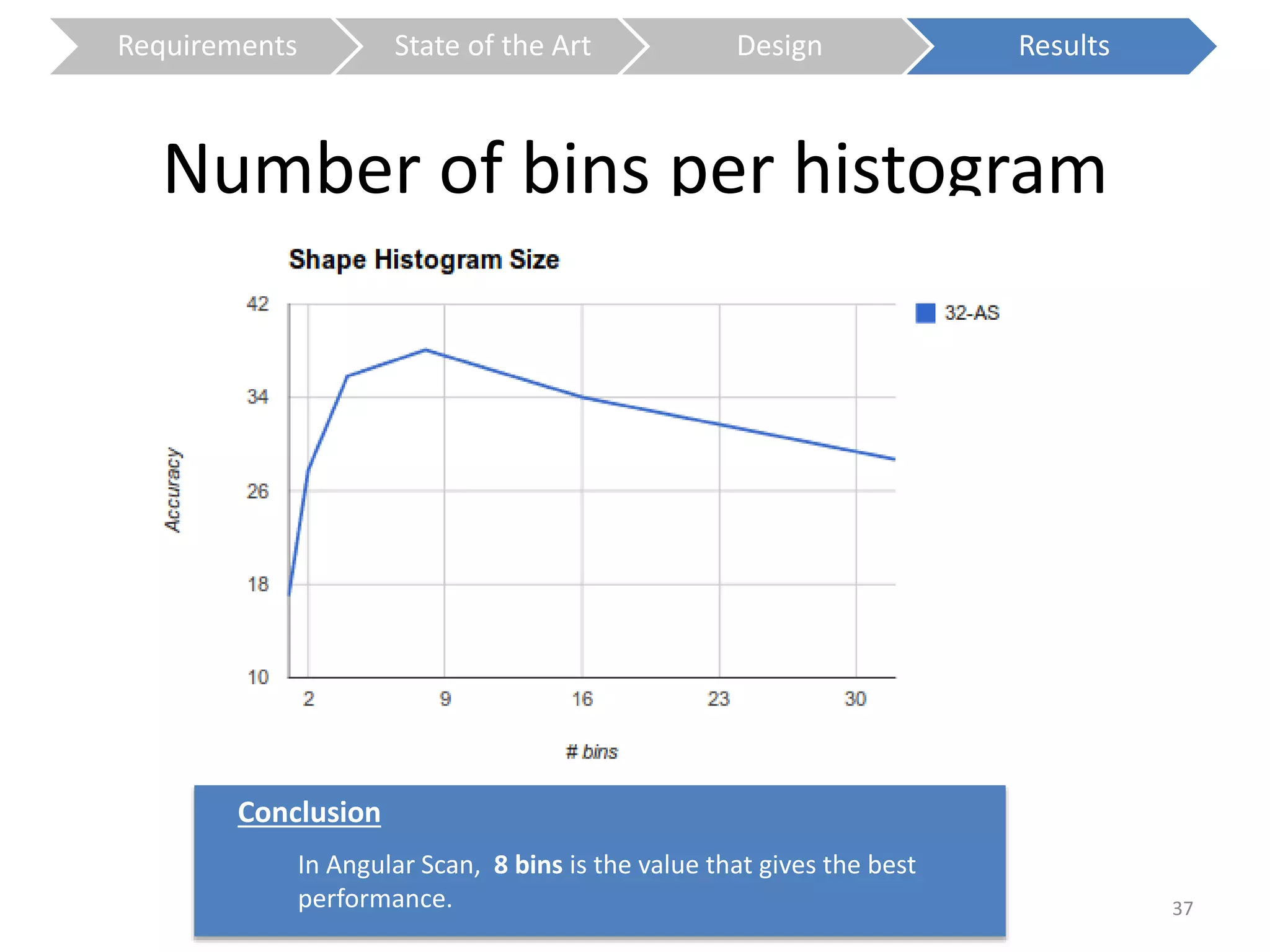
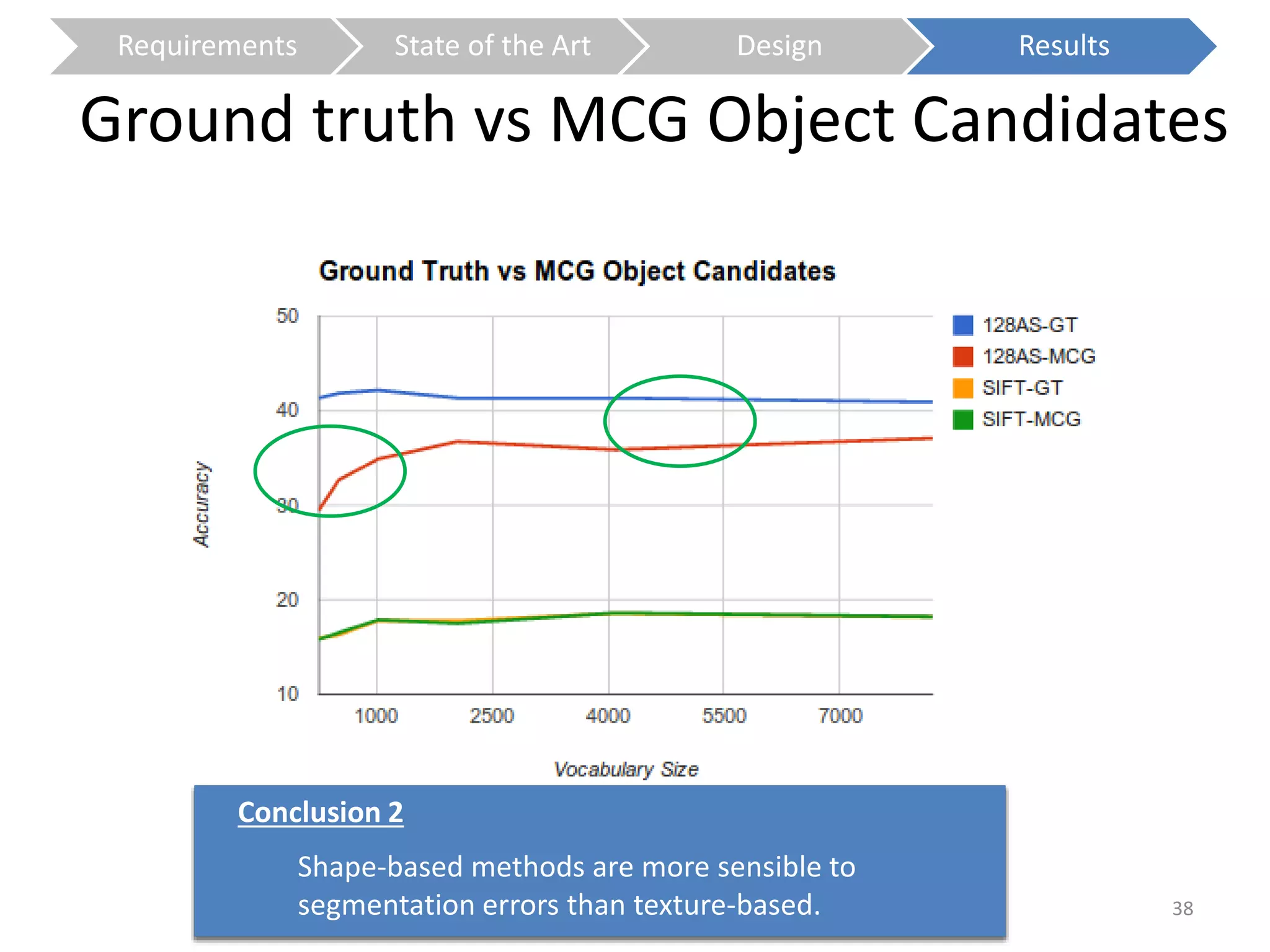
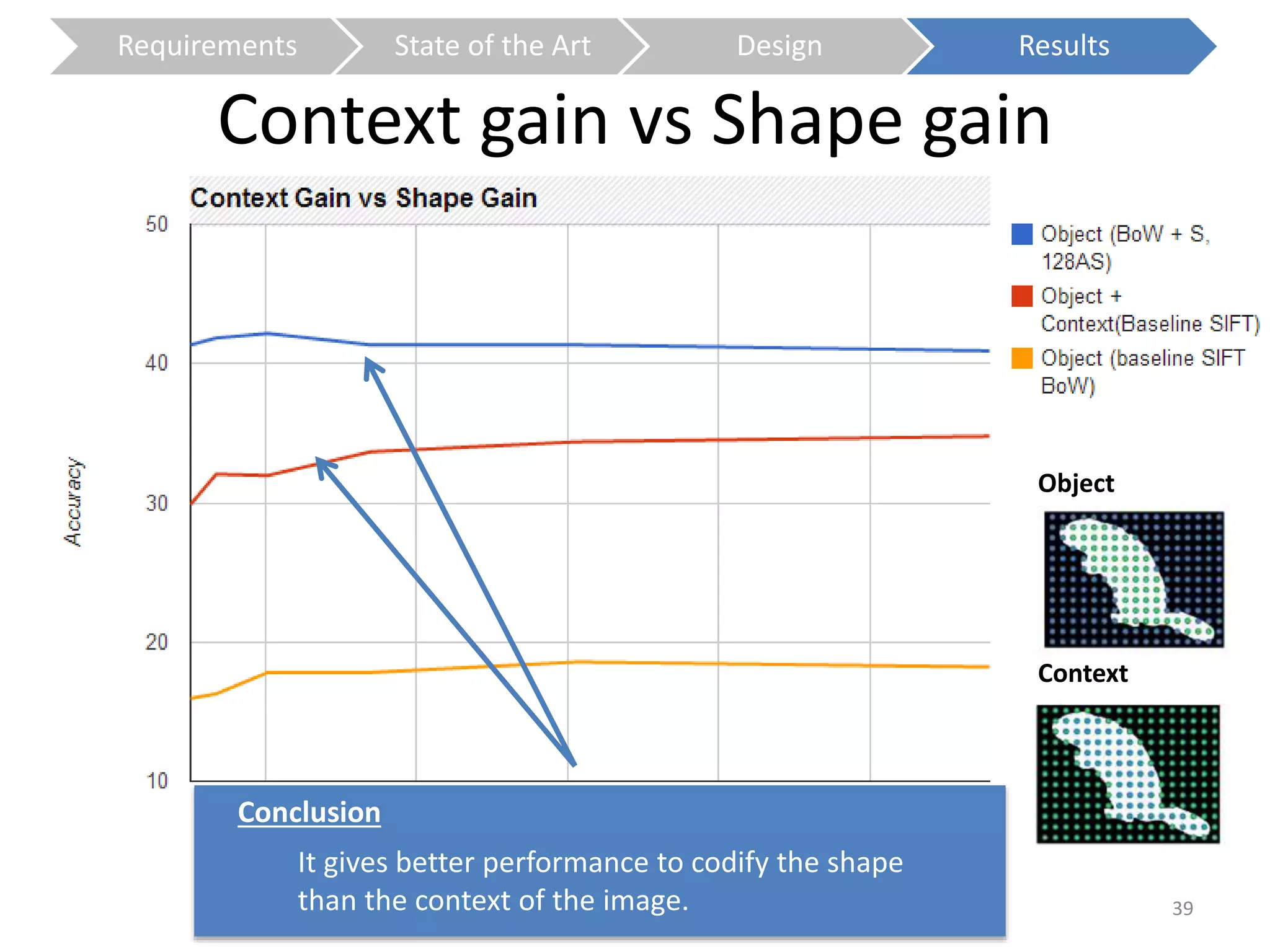




The document presents a study on contextless object recognition using a shape-enriched SIFT approach, aiming to analyze the implications of shape features in object classification. It explores a detailed methodology which includes creating histograms and utilizing a bag-of-words framework for feature integration, leading to improved performance metrics. The study concludes with observations on the effectiveness of shape-based methods versus texture-based methods, emphasizing the significance of feature quantity and organization.







































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














