The document discusses a parallel implementation of template matching using fast normalized cross-correlation (FNCC) on Nvidia GPUs, addressing the computational challenges associated with normalized cross-correlation. It presents novel strategies for efficiency, including the use of pre-computed sum-tables and asynchronous kernel execution, leading to significant reductions in execution time for high-resolution images. Experimental results demonstrate marked improvements in speed-up and processing time, paving the way for more effective real-time applications in image processing.



![1. Introduction
Template Matching has its applications in image and signal
processing like image registration, object detection, pattern
matching etc. Given a source image and a template, the
matching algorithm finds the location of template within the
image in terms of specific measures.
• Full search (FS) or exhaustive search algorithms consider
every pixel in the block to find out the best match --
computationally very expensive.
• Though there are different measures proposed. An empirical
study found NCC provides the best performance in all image
categories in the presence of various image distortions [9].
NCC is also more robust against image variations such as
illumination changes then widely used SAD and MAD .
3](https://image.slidesharecdn.com/adcon2011-120304073545-phpapp01/85/Efficient-Variable-Size-Template-Matching-Using-Fast-Normalized-Cross-Correlation-on-Multicore-Processors-3-320.jpg)
![• However NCC is computationally very expensive
than SAD or MAD, which is a significant drawback in
its real-time application.
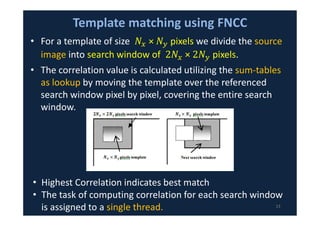
• In this paper we propose the parallel
implementation of template matching using Full
Search using NCC as a measure using the concept of
pre-computed sum-tables [10][11] referred to as
FNCC for high resolution images on NVIDIA’s
Graphics Processing Units (GP-GPU’s)
4](https://image.slidesharecdn.com/adcon2011-120304073545-phpapp01/85/Efficient-Variable-Size-Template-Matching-Using-Fast-Normalized-Cross-Correlation-on-Multicore-Processors-4-320.jpg)


![3. Normalized and Fast Normalized Cross Correlation
• NCC has been commonly used as a metric to evaluate the
similarity (or dissimilarity) measure between two
compared images[8][9].
• Template of size ܰ ݕܰ × ݔis matched with an image of
size .ݕܯ × ݔܯ
• The position ()ݏݒ , ݏݑof the template ݐin image ݂ is
determined by calculating the NCC value at every step.
• The basic equation for NCC is as given in (1)
∑ ( f ( x, y) − fu,v )(t( x − u, y − v) − t )
γ u,v = x, y
(1)
∑
x, y
( f ( x, y) − f u,v ) 2
∑
x, y
(t( x − u, y − v) −t ) 2
7](https://image.slidesharecdn.com/adcon2011-120304073545-phpapp01/85/Efficient-Variable-Size-Template-Matching-Using-Fast-Normalized-Cross-Correlation-on-Multicore-Processors-7-320.jpg)

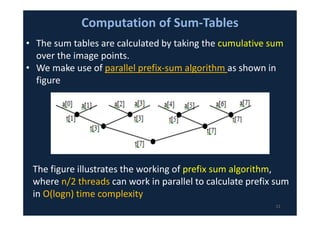
![Fast Normalized Cross Correlation (FNCC)
• Calculation of the denominator of equation using the
concept of sum-tables[10][11].
• ݒ ,ݑ(ݏሻ ܽ݊݀ 2ݏሺݒ ,ݑሻ are sum tables over image
function and image energy respectively.
• The sum-tables of image function and image energy
are computed recursively as given below:
(1)
(2)
(3)
(4)
9](https://image.slidesharecdn.com/adcon2011-120304073545-phpapp01/85/Efficient-Variable-Size-Template-Matching-Using-Fast-Normalized-Cross-Correlation-on-Multicore-Processors-9-320.jpg)





























![[Paper] learning video representations from correspondence proposals](https://cdn.slidesharecdn.com/ss_thumbnails/paperlearningvideorepresentationsfromcorrespondenceproposals-210410235049-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[Harvard CS264] 16 - Managing Dynamic Parallelism on GPUs: A Case Study of Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/managingdynamicparallelism-110430142356-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


































