Download as PDF, PPTX














![Convnets
●
●
LeNet-5 [LeCun et al. 1998] 32](https://image.slidesharecdn.com/dlmmdcud1l02deepneuralnetworks-170427160932/75/Deep-Neural-Networks-D1L2-Insight-DCU-Machine-Learning-Workshop-2017-32-2048.jpg)
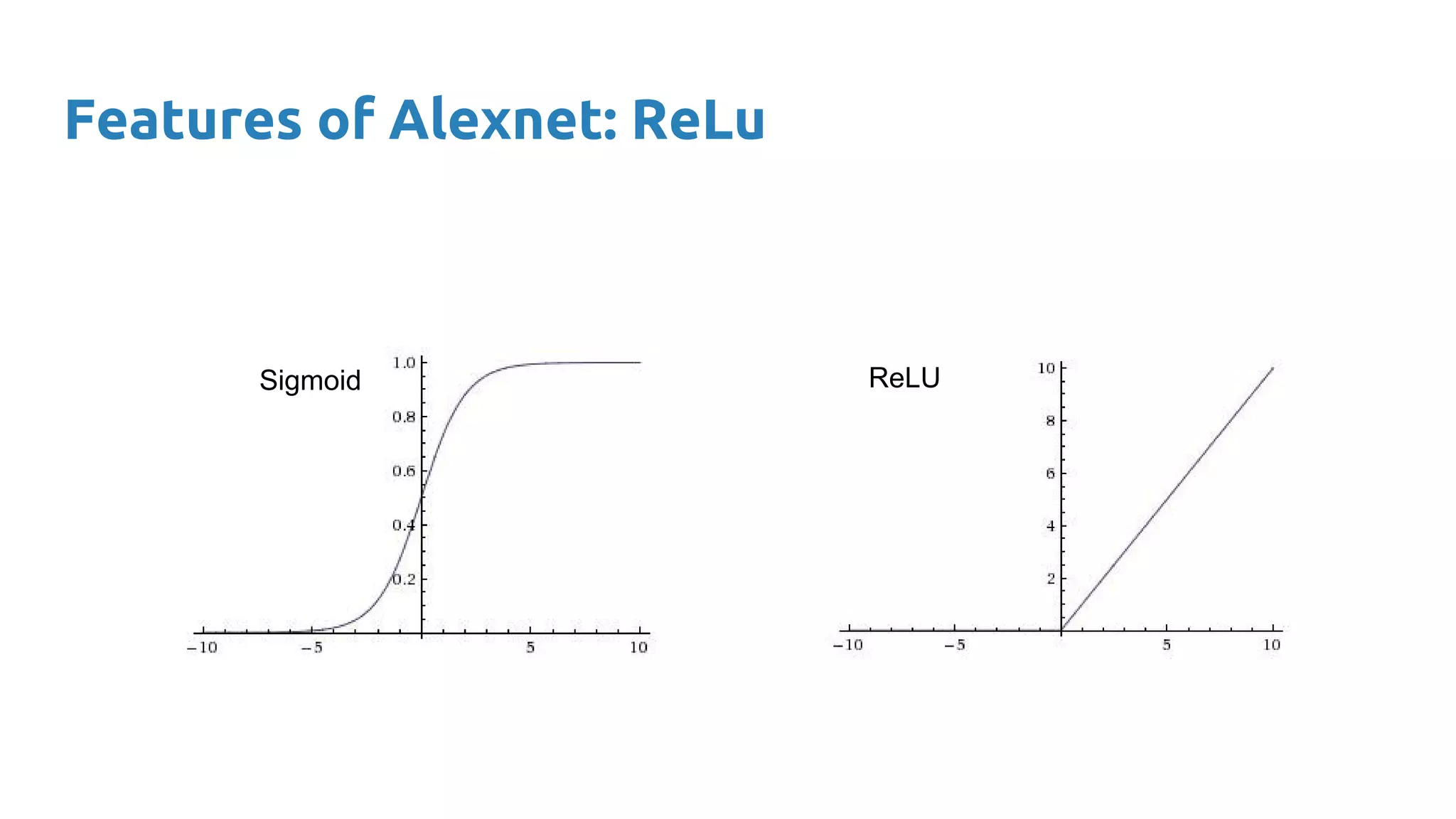





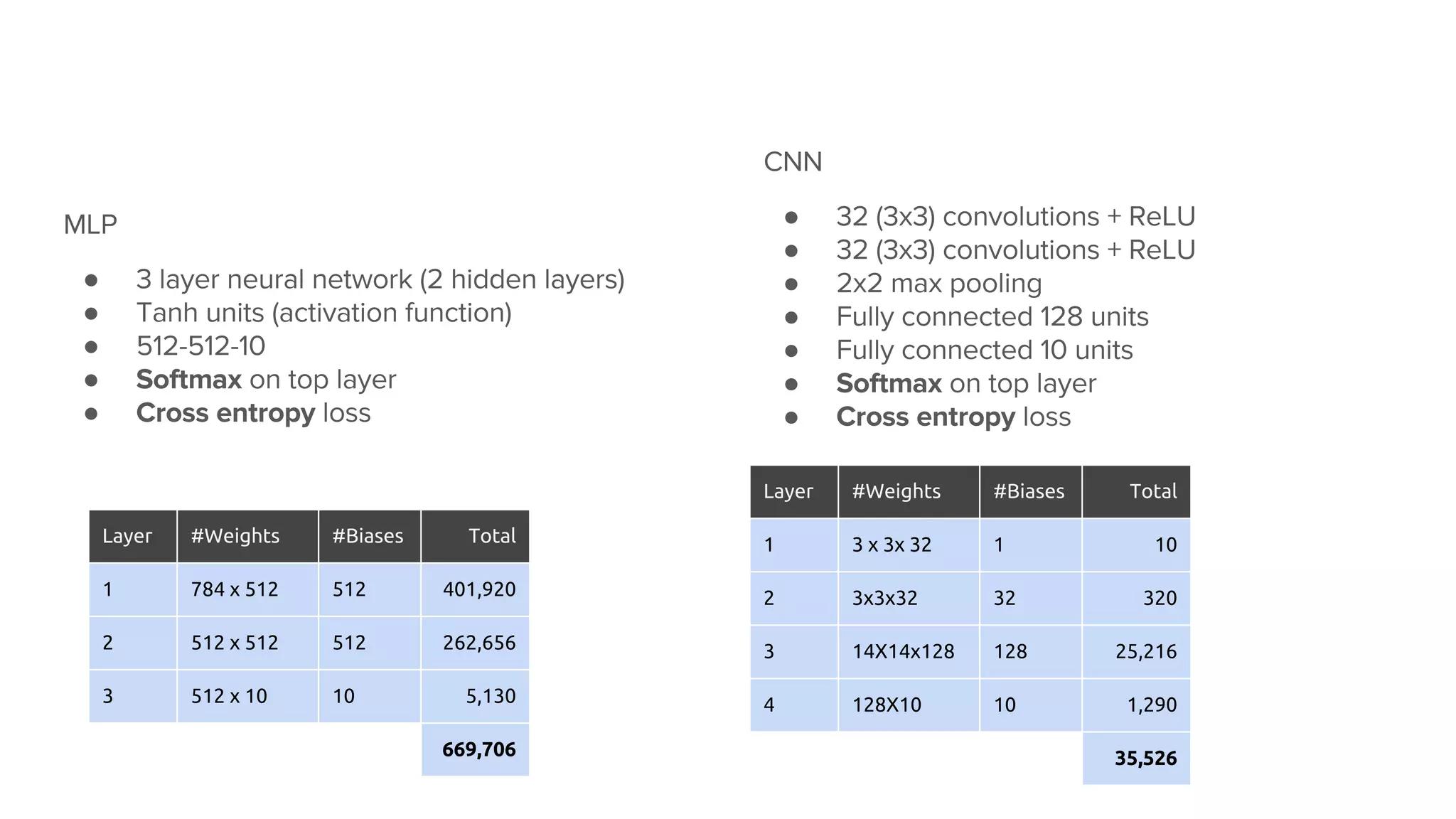

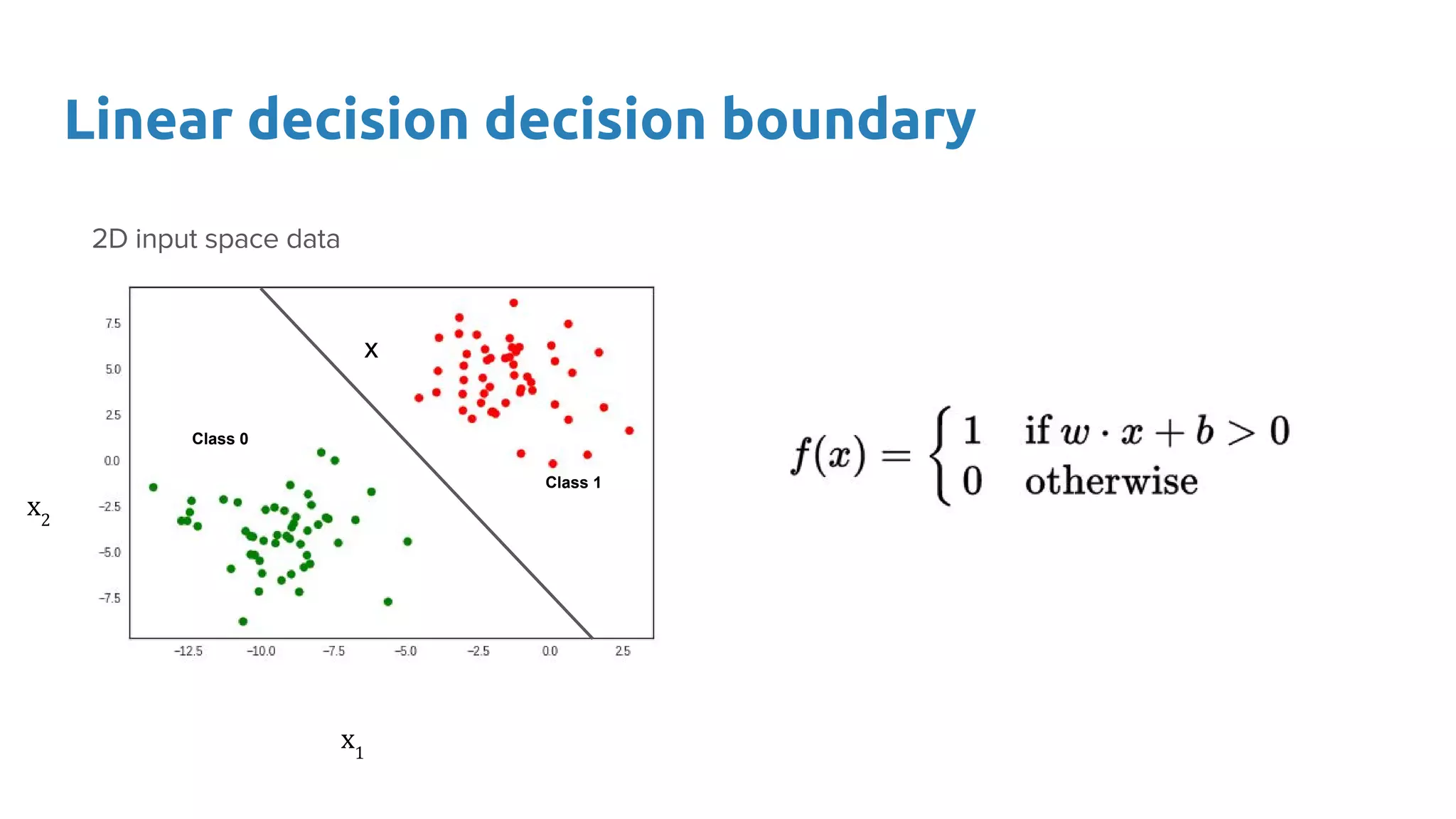
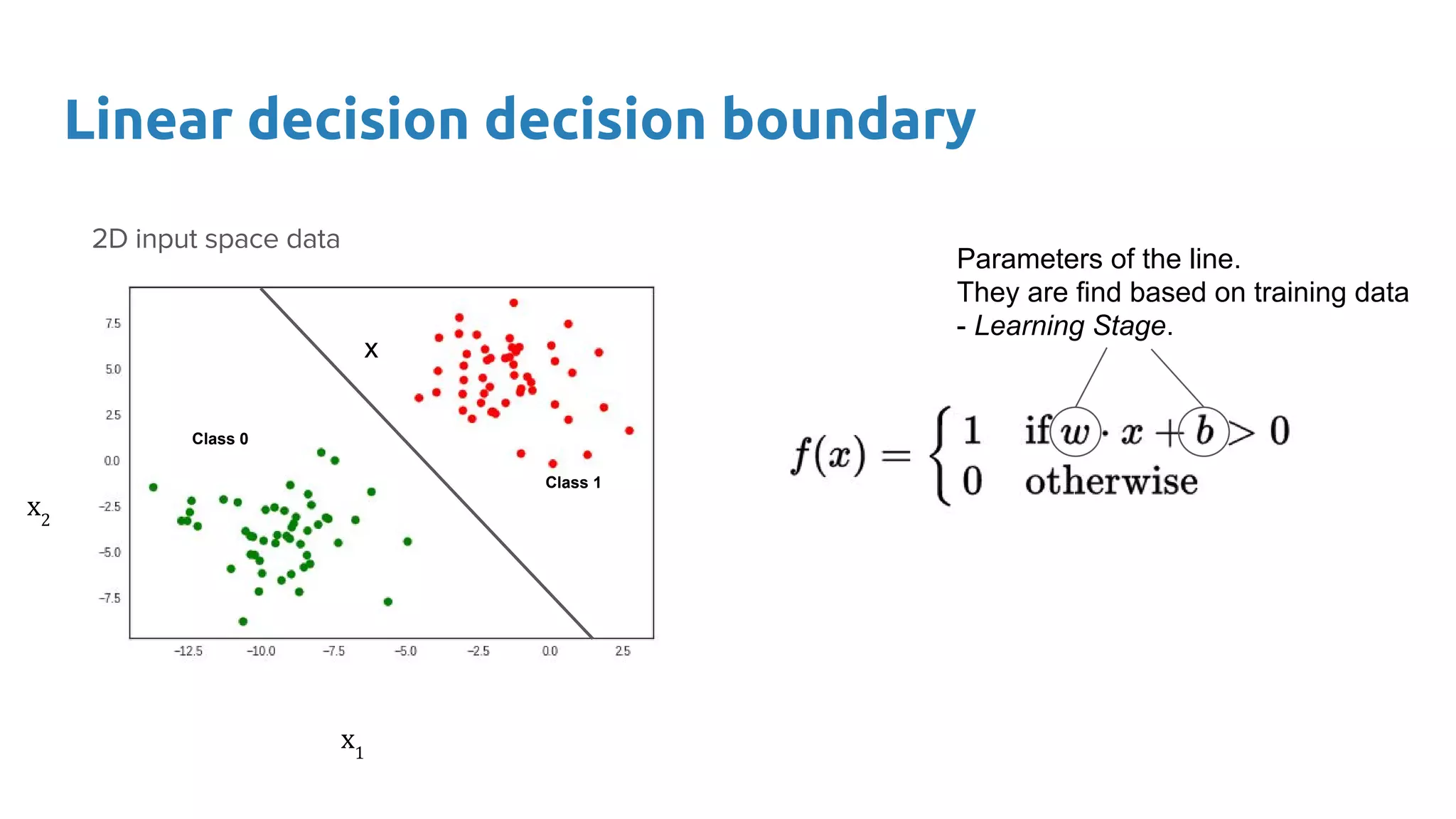
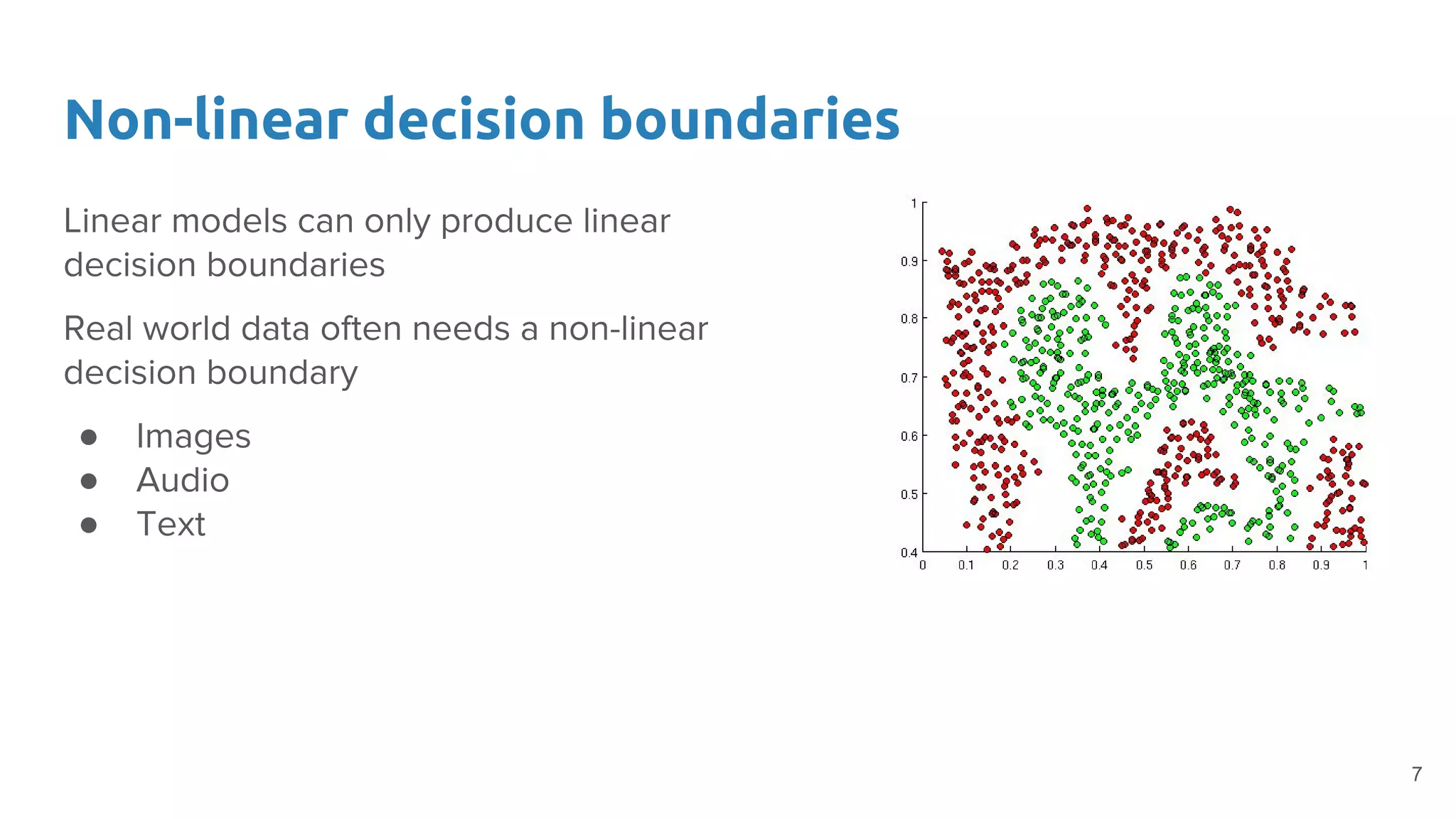
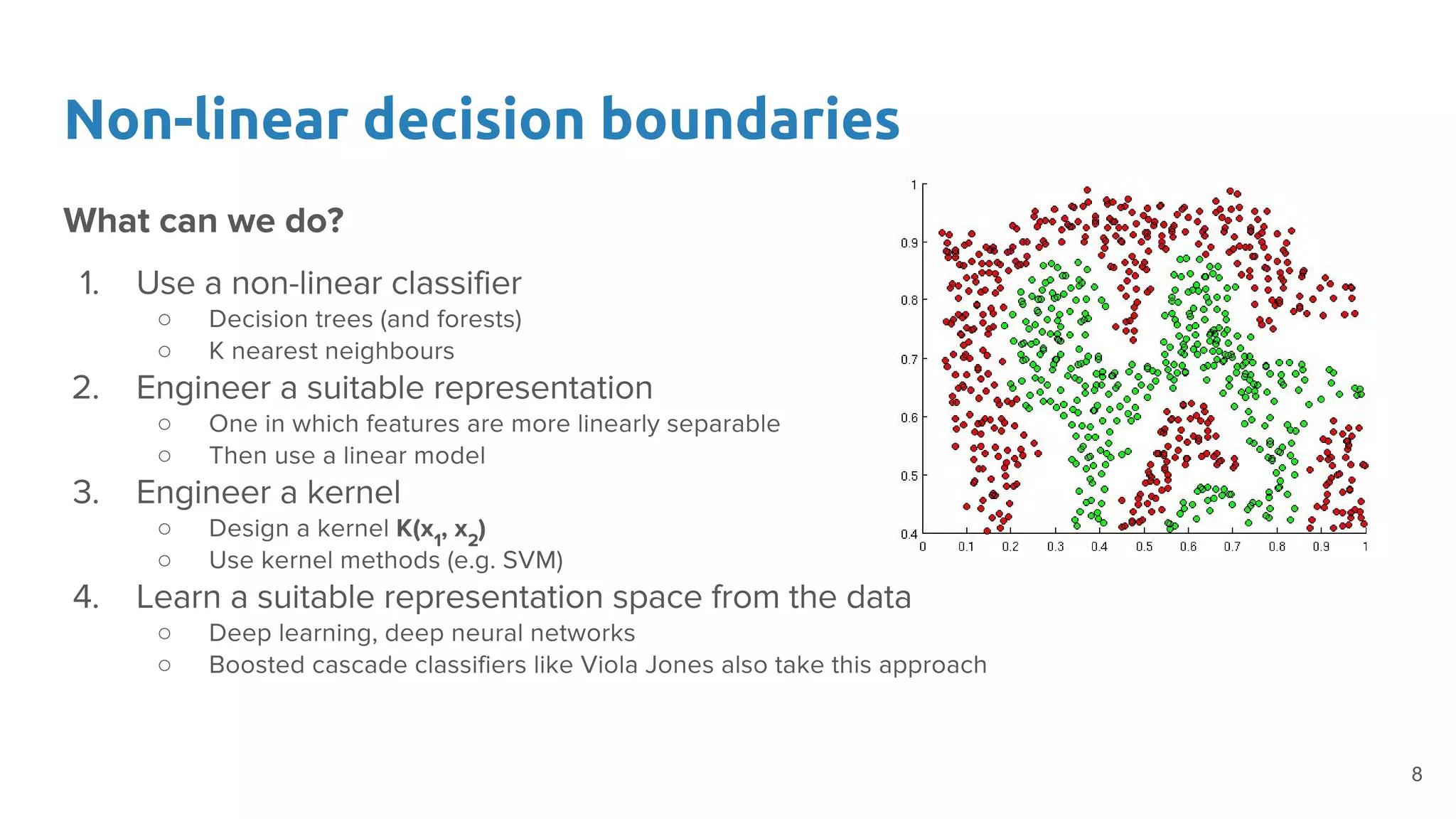
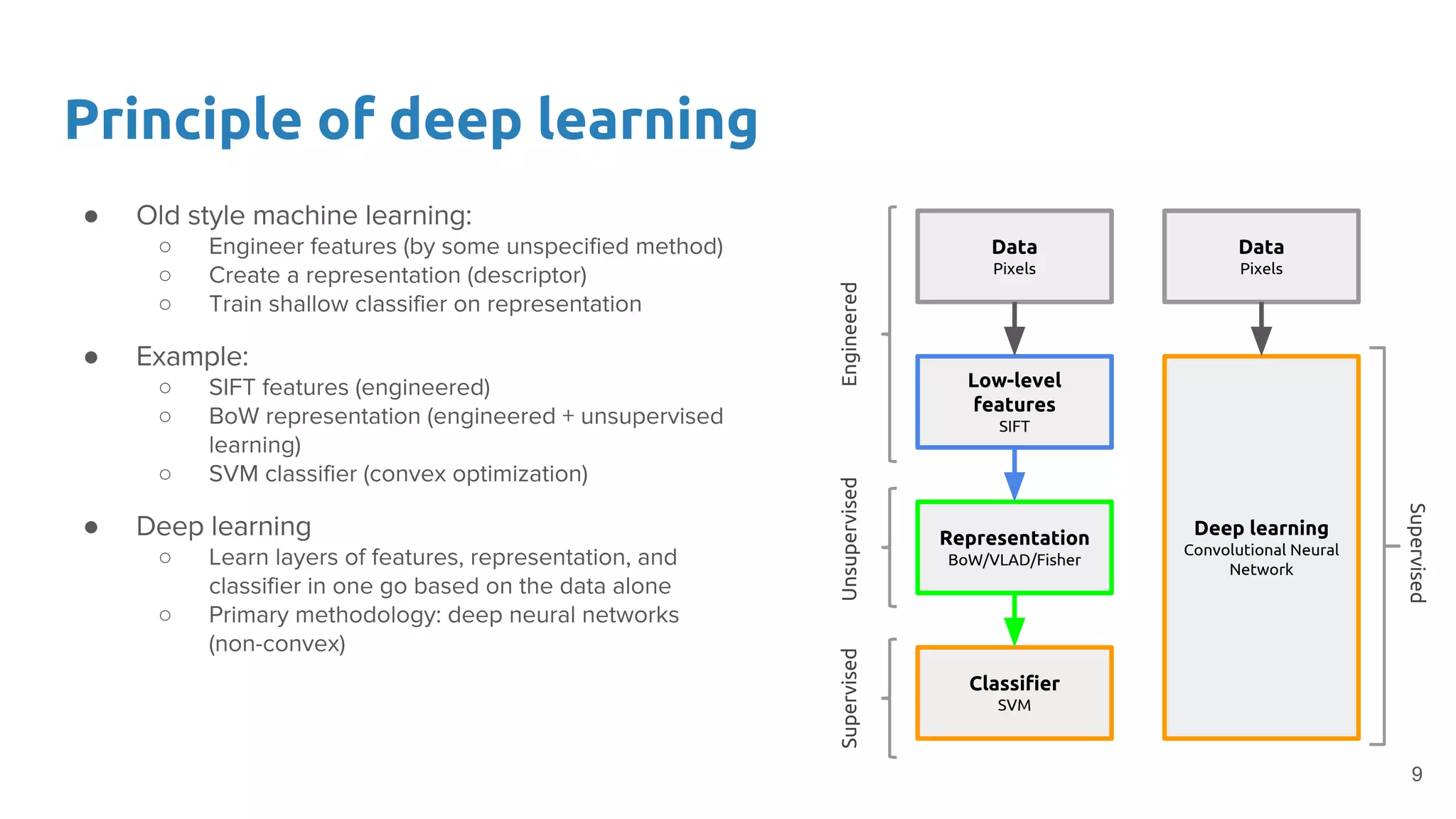
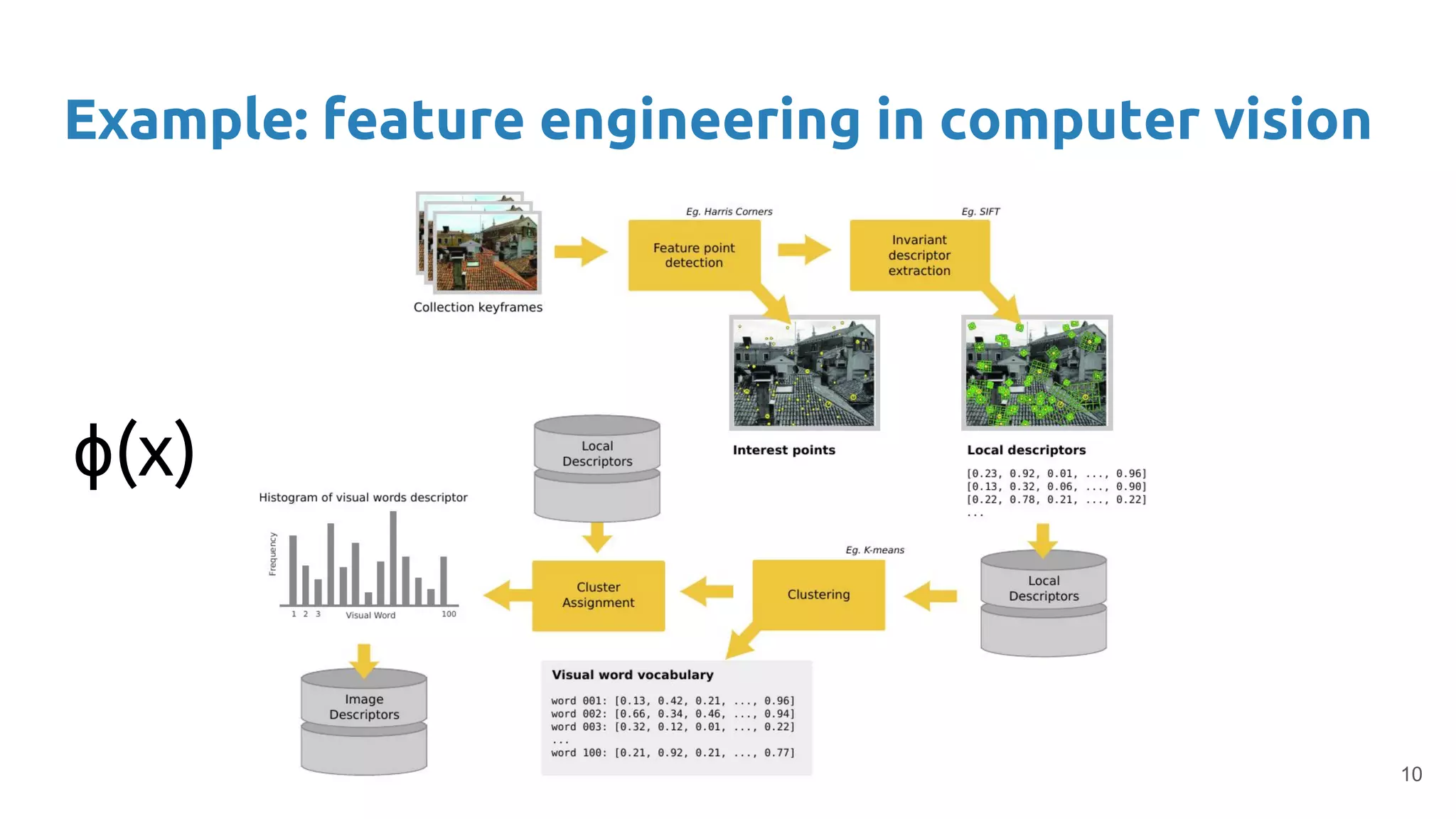
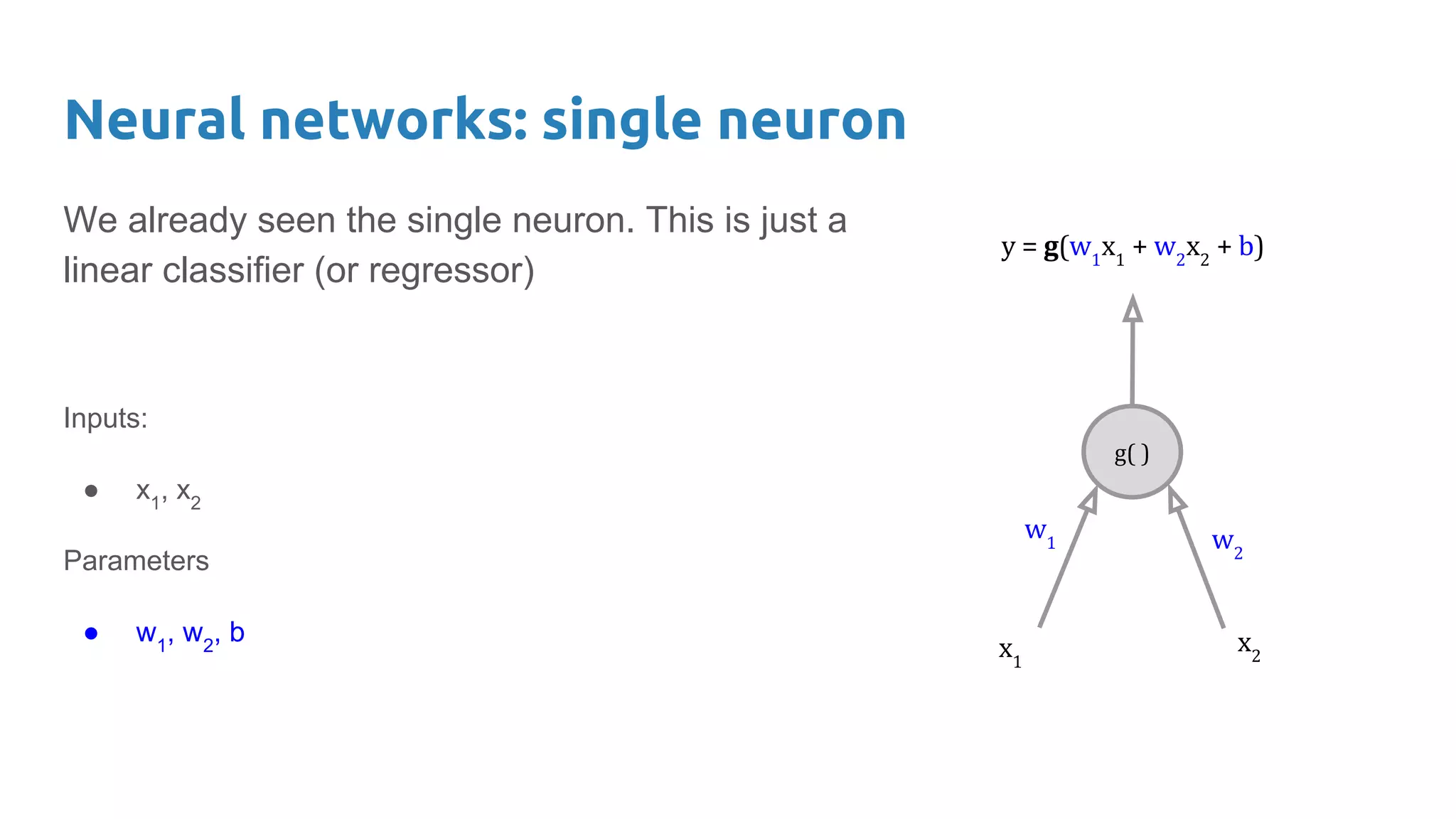
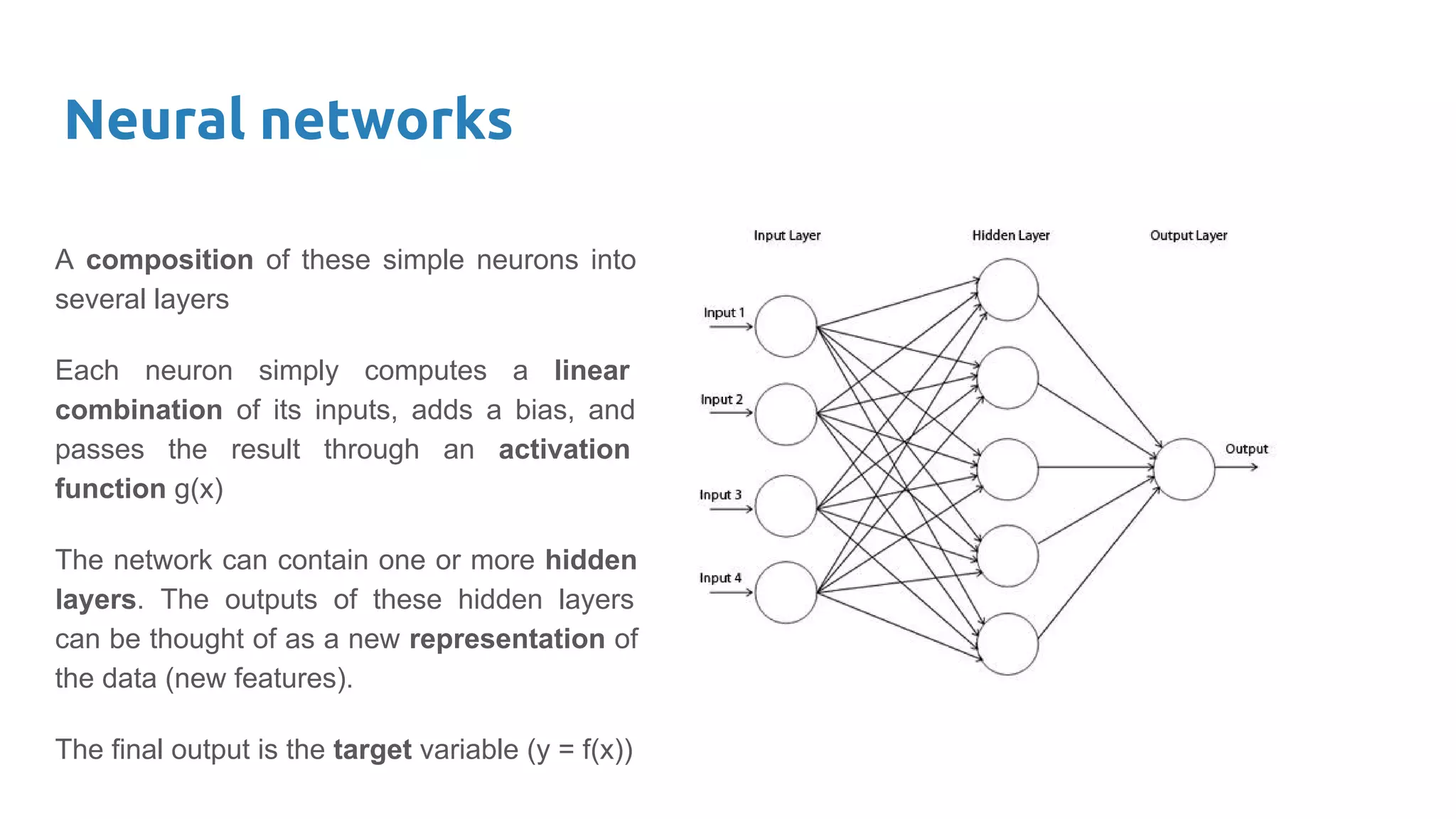
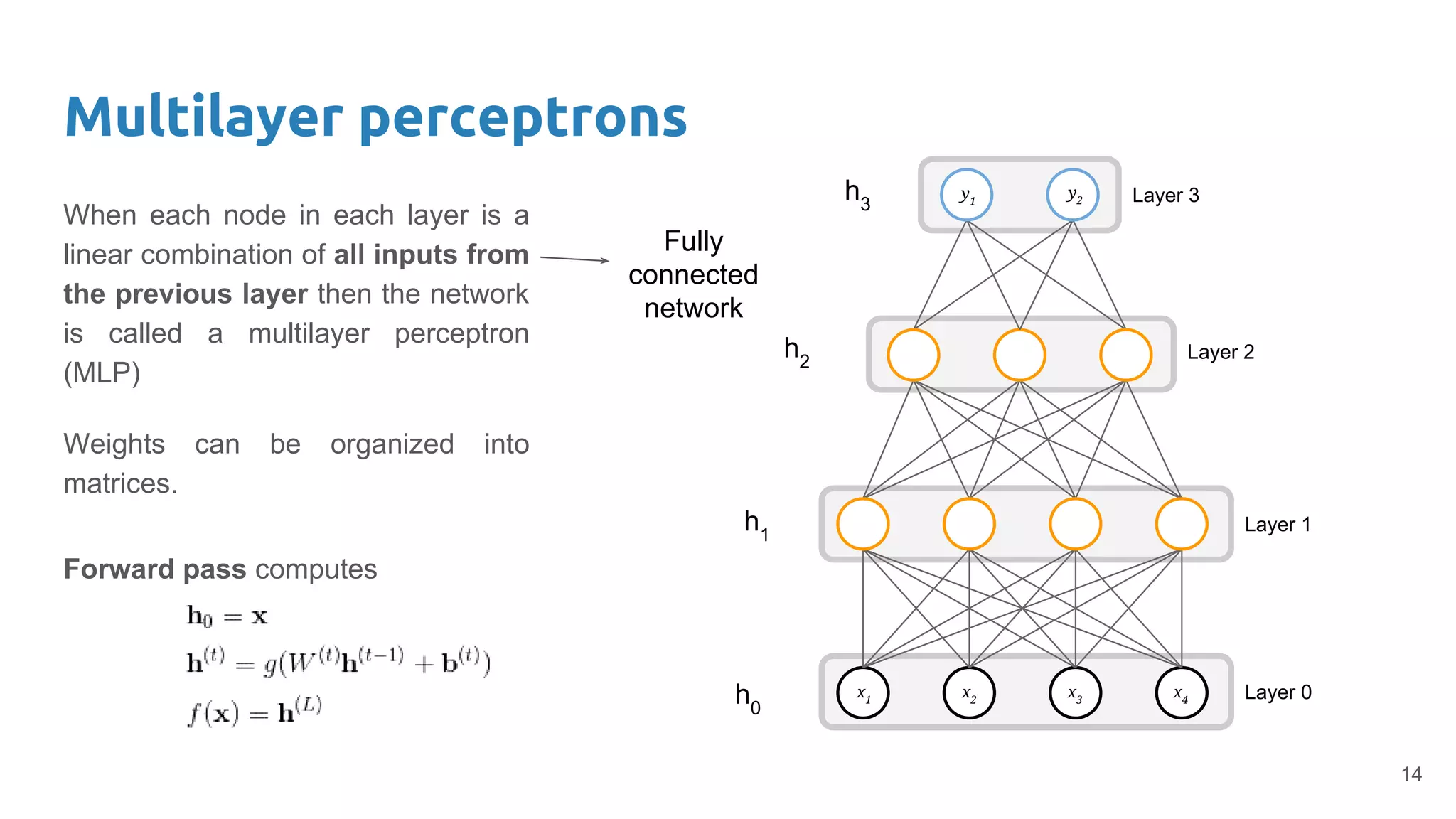
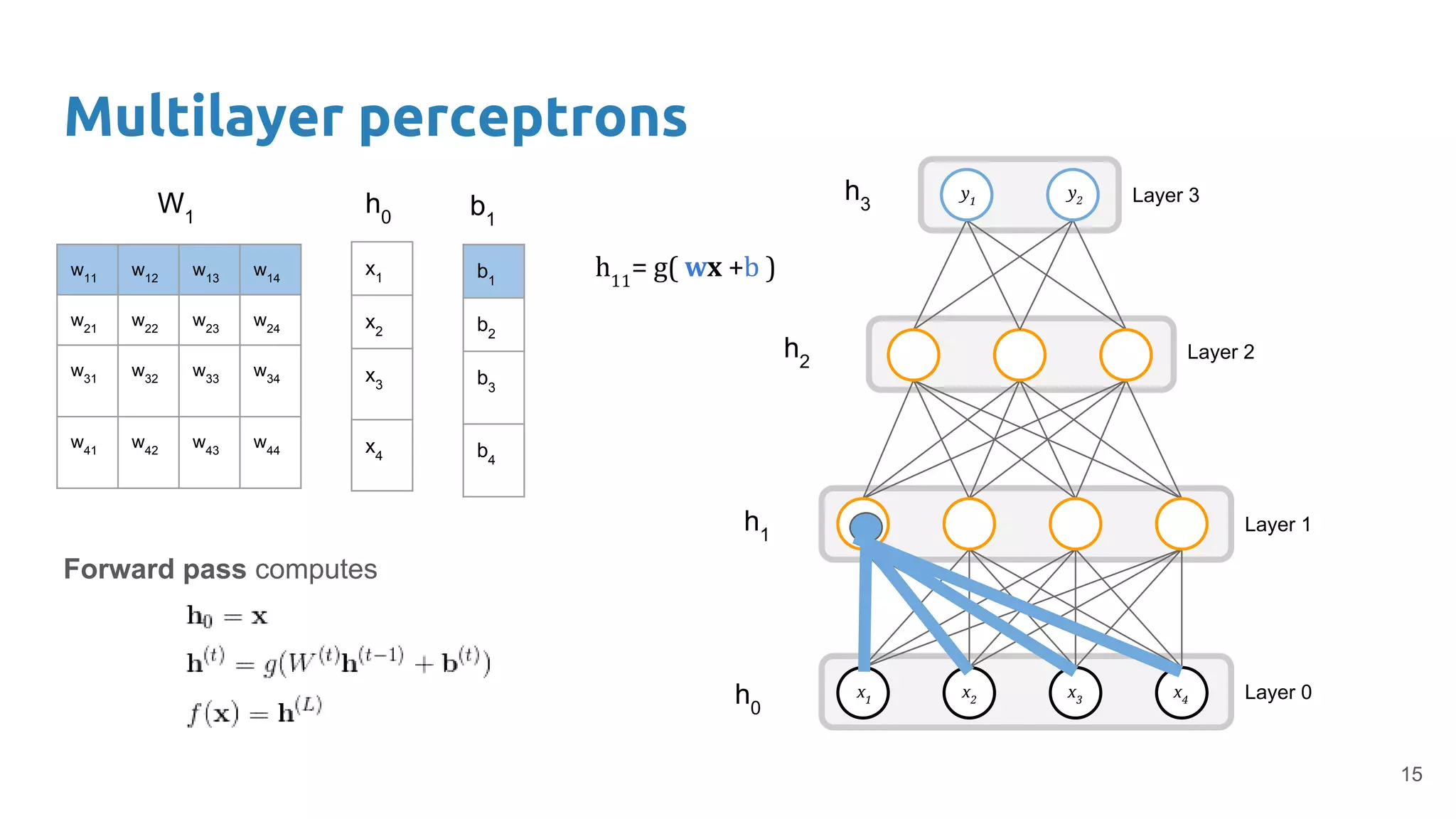
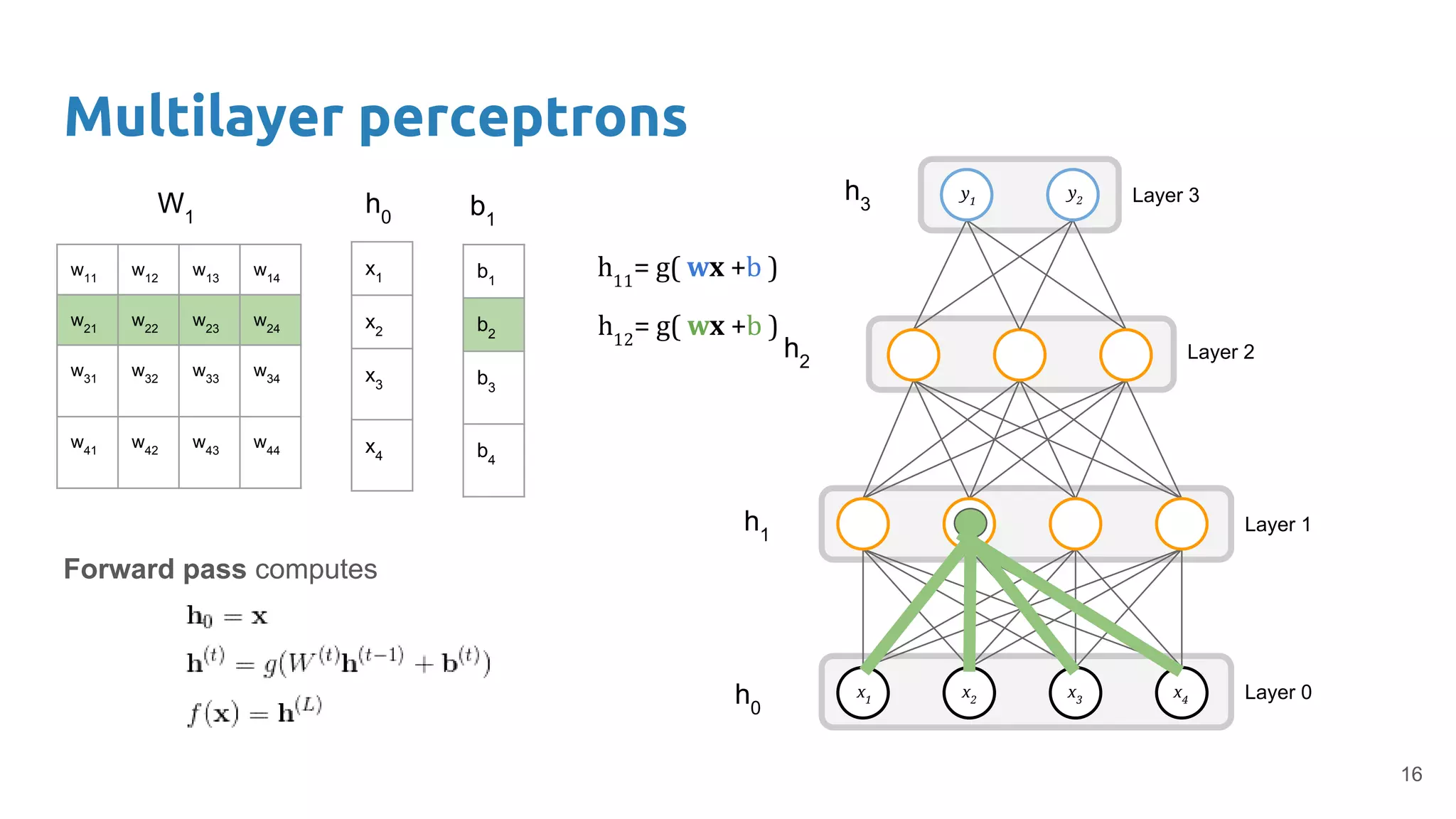
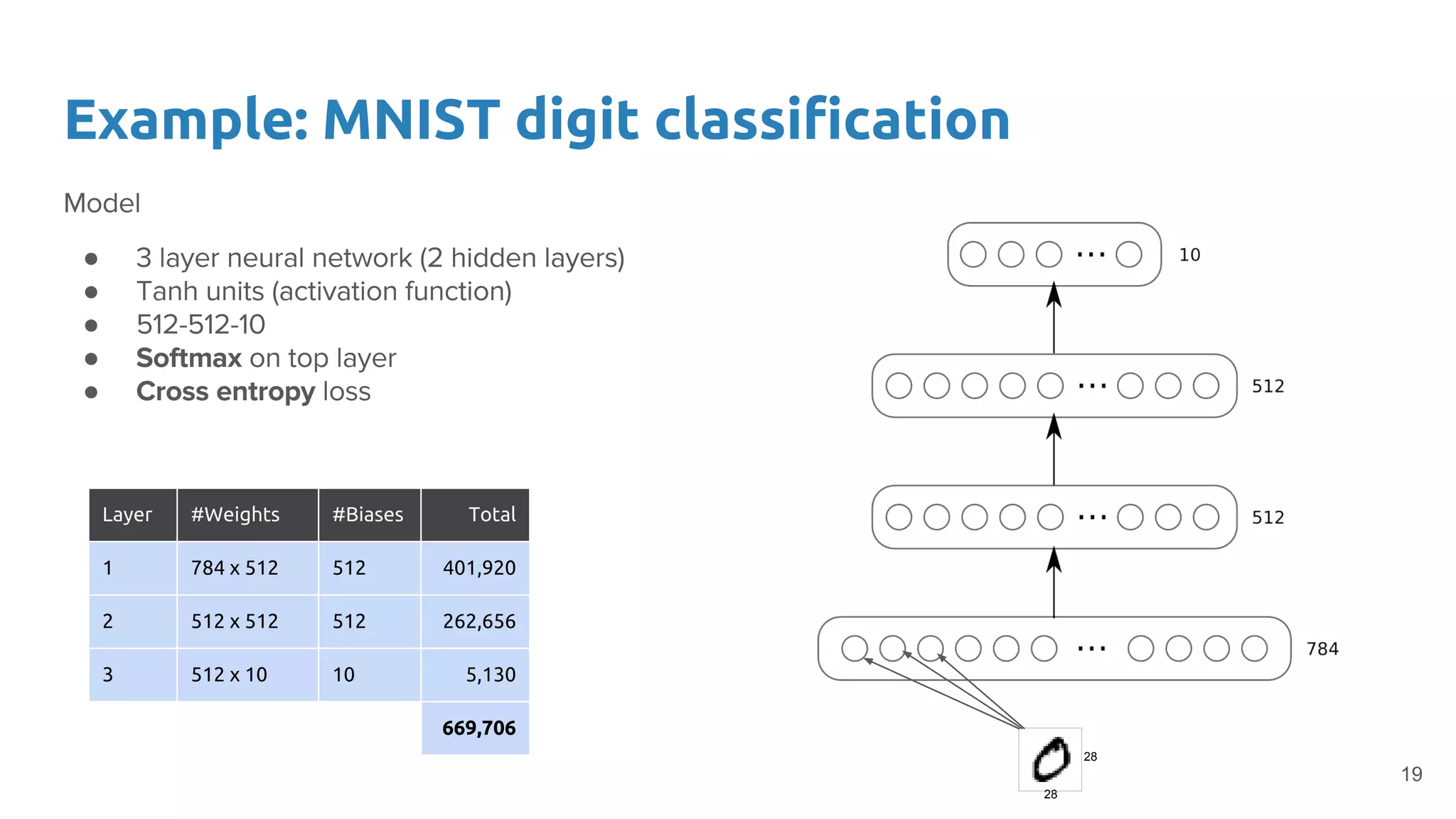
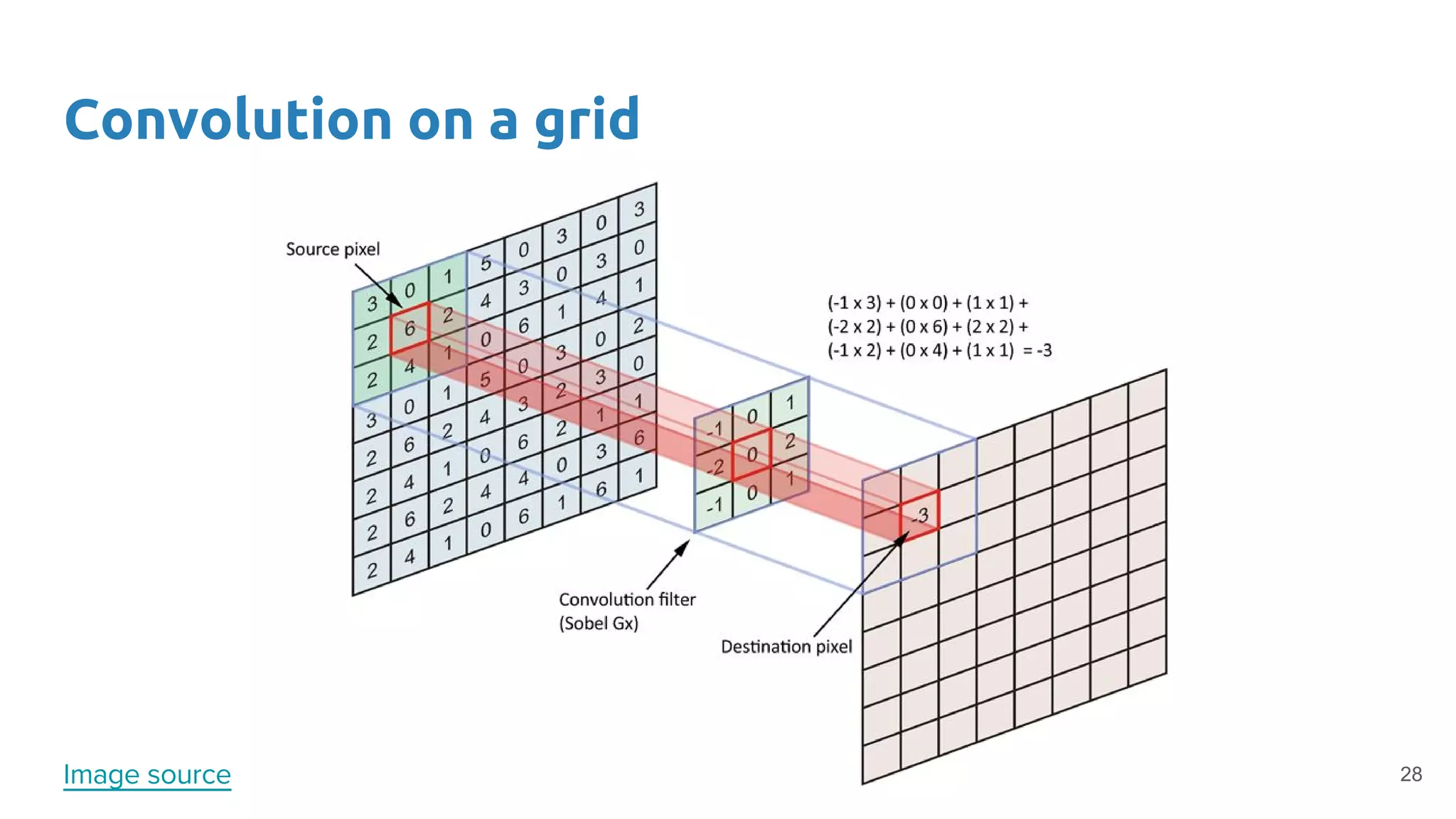
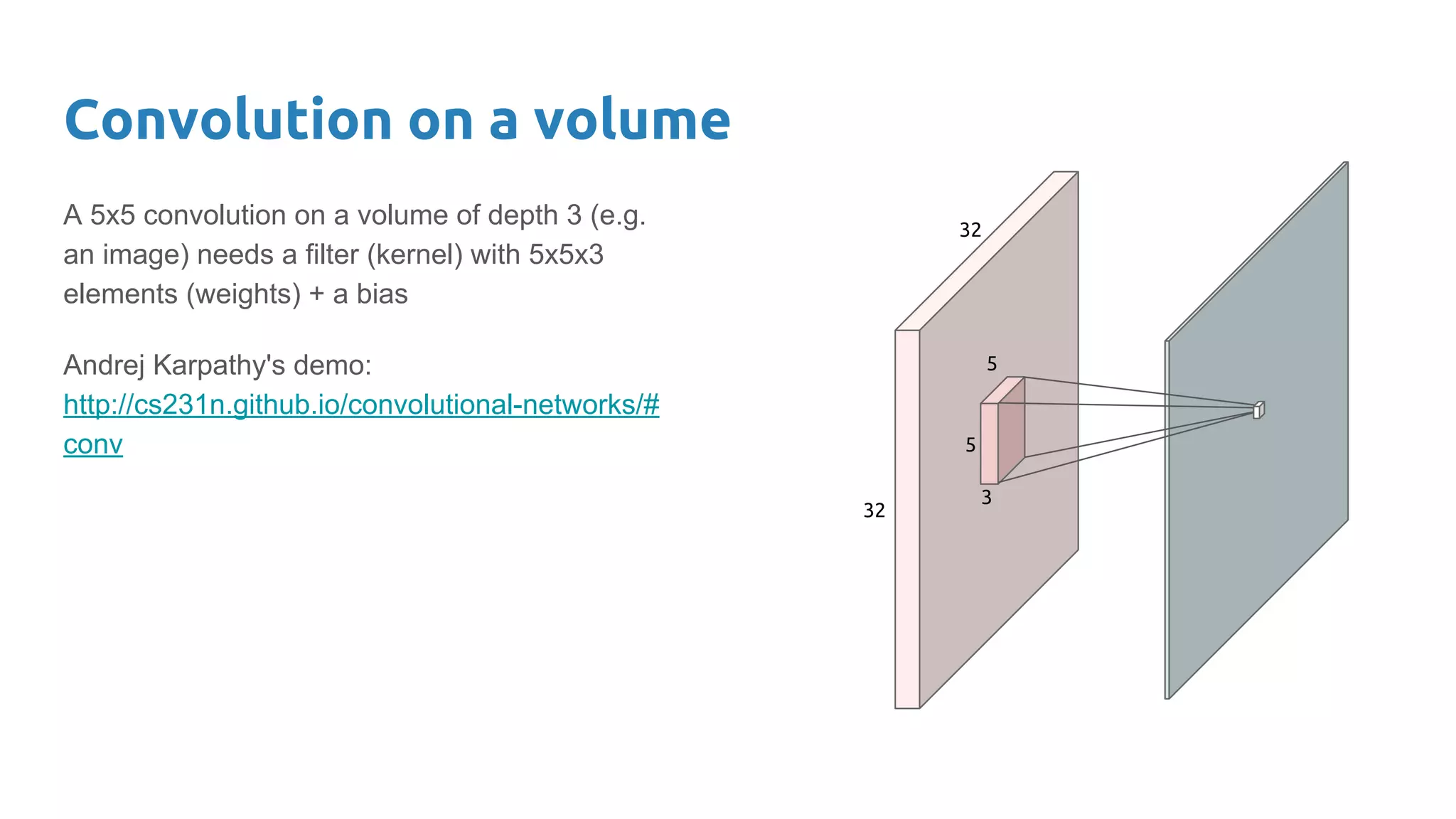
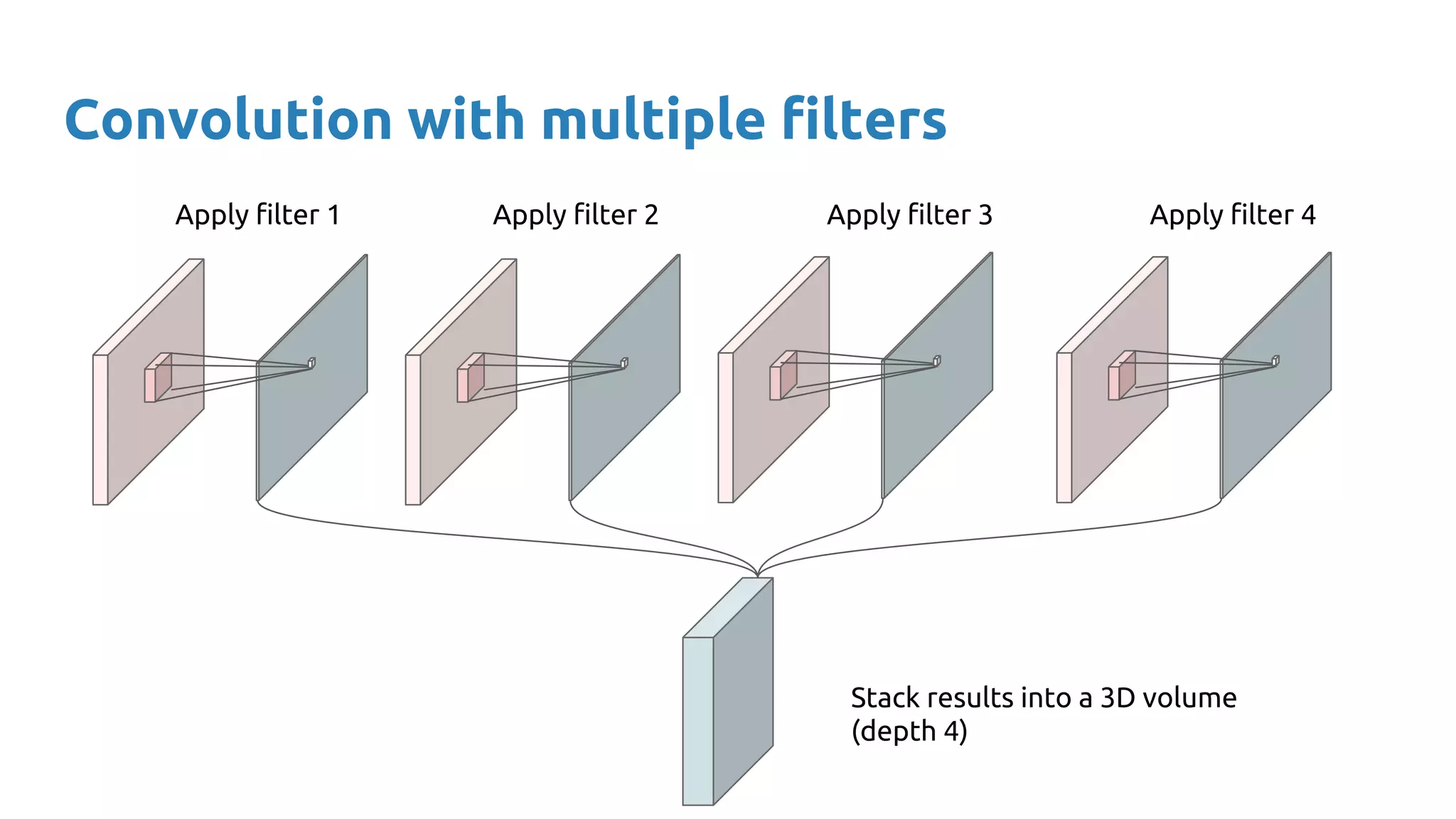
The document provides an overview of deep neural networks, including concepts like perceptrons, multilayer perceptrons, and convolutional neural networks (CNNs). It discusses the limitations of linear decision boundaries, the importance of activation functions, and the universal approximation theorem that supports the use of deep networks in complex function approximation. Additionally, it presents examples from the MNIST digit classification and highlights key features of CNNs such as filtering and pooling layers.






















































































