Download to read offline








![PingCAP.com
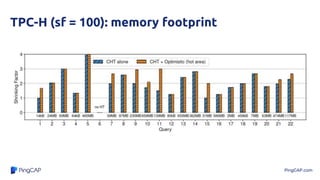
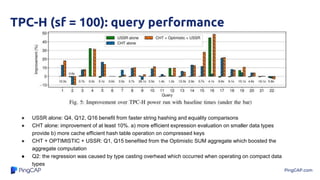
Micro-bench: Faster HashJoin Probe
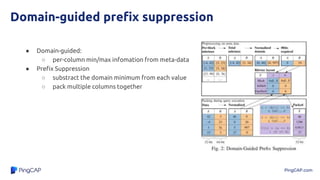
● micro-benchmark Domain-Guided Prefix Suppression
● 4 keys [0...1000], 4 payloads [0...10]
● 2.5x faster hash probe including the tuple
reconstruction cost
● > 10^6 rows, the speedups were caused by the
more cache-resident hash table
● < 10^6 rows, mostly affected by the more efficient
comparisons directly on compressed data](https://image.slidesharecdn.com/icde-2020-220209161641/85/Paper-Reading-Efficient-Query-Processing-with-Optimistically-Compressed-Hash-Tables-Strings-in-the-USSR-11-320.jpg)


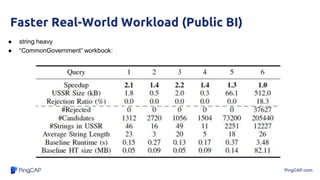


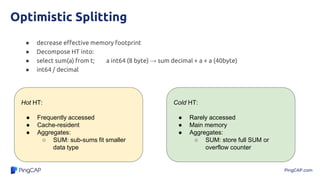
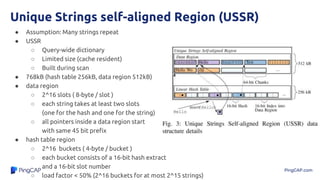
The document discusses efficient query processing using optimally compressed hash tables and strings, highlighting performance improvements through methods like domain-guided prefix suppression and optimistic splitting. It details how shrinking hash tables can enhance cache efficiency and increase query throughput while addressing memory bandwidth issues. Experimental results show significant lower memory consumption and improved query performance in analytical scenarios.
















































![[Paper Reading]Orca: A Modular Query Optimizer Architecture for Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/orca-211220090600-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]KVSSD: Close integration of LSM trees and flash translation la...](https://cdn.slidesharecdn.com/ss_thumbnails/kvssdcloseintegrationoflsmtreesandflashtranslationlayerforwrite-efficientkvstore-211206083654-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]Chucky: A Succinct Cuckoo Filter for LSM-Tree](https://cdn.slidesharecdn.com/ss_thumbnails/chuckyasuccinctcuckoofilterforlsm-tree-211122111631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]The Bw-Tree: A B-tree for New Hardware Platforms](https://cdn.slidesharecdn.com/ss_thumbnails/thebw-treeab-treefornewhardwareplatforms-211115032950-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] QAGen: Generating query-aware test databases](https://cdn.slidesharecdn.com/ss_thumbnails/datagenerator-211105075703-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Leases: An Efficient Fault-Tolerant Mechanism for Distribute...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingleases-211101103843-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper reading] Interleaving with Coroutines: A Practical Approach for Robust...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadinginterleavingwithcoroutinesapracticalapproachforrobustindexjoin-211011055753-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paperreading] Paxos made easy (by sen han)](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingpaxosmadeeasybysenhan-210926142716-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Generalized Sub-Query Fusion for Eliminating Redundant I/O fr...](https://cdn.slidesharecdn.com/ss_thumbnails/resin-210920113222-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Steering Query Optimizers: A Practical Take on Big Data Workl...](https://cdn.slidesharecdn.com/ss_thumbnails/steersigmod21-210913065908-thumbnail.jpg?width=640&height=640&fit=bounds)













![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















