Download to read offline










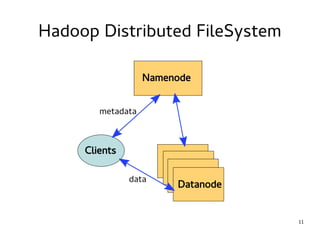
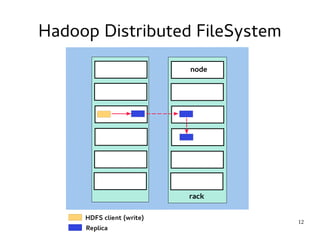
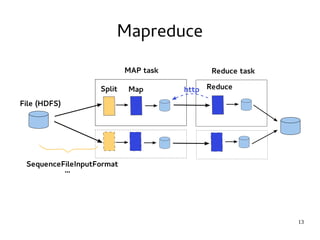
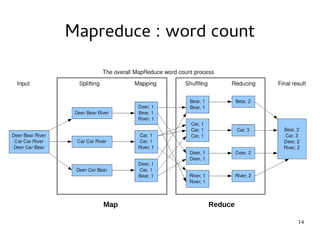
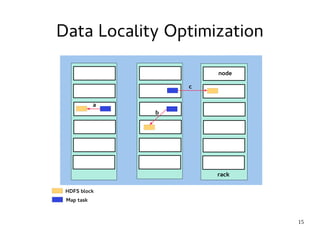
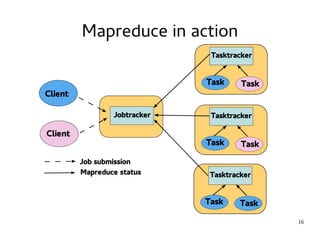


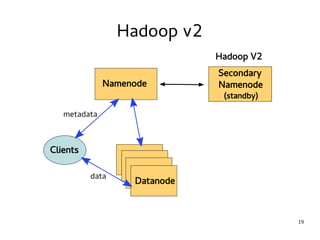
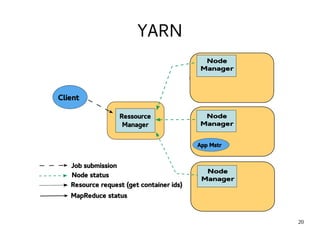
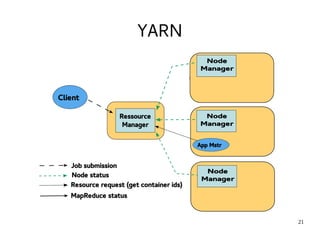
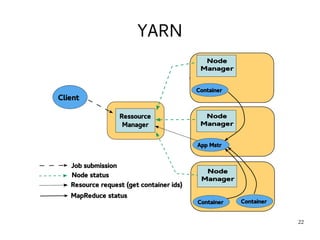
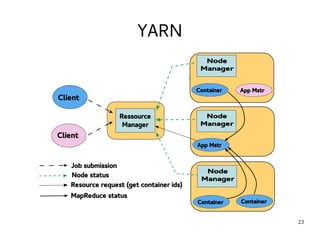
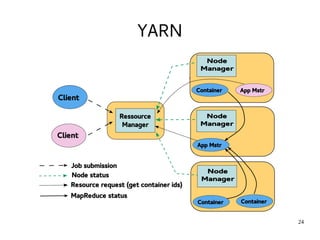
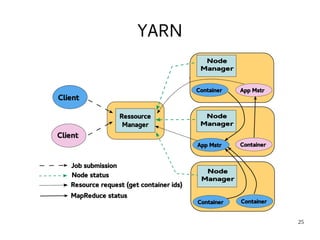




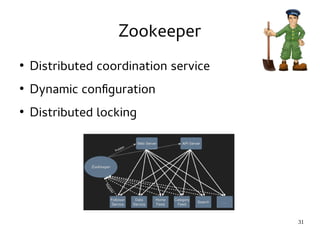



This document introduces Hadoop, an open-source software platform for distributed storage and processing of large datasets across clusters of computers. It discusses the key components of Hadoop including the Hadoop Distributed File System (HDFS) for storage, MapReduce for processing, and YARN for resource management. The document also briefly introduces related projects like Pig for data flows and Hive for SQL-like queries that build on Hadoop.



































































