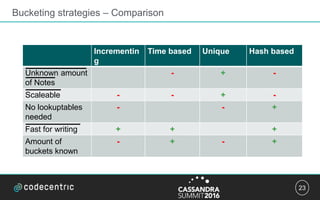
The document discusses strategies for managing data partitions in a system, emphasizing the need for efficient bucketing to avoid scalability issues caused by large partitions. It outlines various bucketing strategies such as incrementing IDs, unique identifiers, time-based, and hash-based methods, along with their pros and cons. Key recommendations include ensuring partitions remain manageable in size and minimizing the potential for deleted rows leading to performance problems.








![9
• A user (owner) can create a
notebook
• An owner can create notes
belonging to a notebook
• Users can fetch notes (idealy only
once), not necessarily in certain
order
• Users can delete notes
Use case
Note_by_notebook
P Notebook [text]
C Title [text]
Comment [text]
Owner [text]
CreatedOn
[timestamp]](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-9-320.jpg)

![11
Use case – Let‘s do the math
How many values do we store having
100.000 rows per notebook?‚
Nv = Nr ´(Nc - Npk - Ns )+ Ns
Note_by_notebook
P Notebook [text]
C Title [text]
Comment [text]
Creator [text]
CreatedOn
[timestamp]
num_rows
* num_regular_columns
+ num_static_columns
= values_per_notebook
100.000
* 3
+ 0
= 300.000](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-11-320.jpg)
![12
Use case – Size assumptions
Note_by_notebook
P Notebook [text] 16 bytes
C Title [text] 60 bytes
Comment [text] 200 bytes
Owner[text] 16 bytes
CreatedOn [timestamp] 8 bytes](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-12-320.jpg)
![13
Use case – Let‘s do the math
Ok, so how much data is that on disk?
sizeOf (cki
)+
i
å sizeOf (Csj
j
å )+ Nr ´ (sizeOf (Crk
)+ sizeOf (
l
å Ccl
))+8´ Nv
k
å
Note_by_notebook
P Notebook [text]
C Title [text]
Comment [text]
Owner [text]
CreatedOn [text]
sizeof(P)
+ sizeof(S)
+ num_rows
* (sizeof(C)+sizeof(regular_column))
+ 8*num_values
= bytes_per_partition
16 bytes
+ 0 bytes
+ 100.000
* (60 bytes + 224 bytes)
+ 8 bytes * 300.000
= 30.800.016 bytes](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-13-320.jpg)

![15
Use case – Let‘s do the math
How many data do we store having
300.000 rows per notebook?
Note_by_notebook
P Notebook [text]
C Title [text]
Comment [text]
Owner [text]
CreatedOn [text]
92.400.016 bytes](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-15-320.jpg)

![17
Use case – Let‘s do the math
Ok, just for fun: How much data is that on
disk?
sizeOf (cki
)+
i
å sizeOf (Csj
j
å )+ Nr ´ (sizeOf (Crk
)+ sizeOf (
l
å Ccl
))+8´ Nv
k
å
Note_by_notebook
P Notebook [text]
C Title [text]
Comment [text]
Owner [text]
CreatedOn [text]sum(sizeof(P))
+ sum(sizeof(S))
+ num_rows
* (sum(sizeof(C)+sum(regular_column))
+ 8*num_values
= bytes_per_partition
16 bytes
+ 0 bytes
+ 20.000.000
* (60 bytes + 224 bytes)
+ 8 bytes * 60.000.000
= 6.160.000.016 bytes](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-17-320.jpg)

![19
Bucketing strategies – Incrementing Bucket id
Incrementing bucket „counter“ based on row count inside
partition
+ Good if client is able to track the count
- Not very scalable
- Possible unreliable counter
insertNote bucketFull?
no
yes
Bucket++
notebook Bucket
n1 0
n1 1
Note_by_notebook
P Notebook [text]
P bucket [int]
C Title [text]
...](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-19-320.jpg)
![20
Bucketing strategies – Unique bucketing
insertNote bucketFull?
no
yes New bucket
uuid2
notebook Bucket
n1 uuid1
n1 uuid2
Identify buckets using uuids
+ Good if clients are able to track the count
+ Better scaleable
- Possibly unreliable counter
- Lookuptable(s) needed
Note_by_notebook
P Notebook [text]
P bucket [uuid]
C Title [text]
...](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-20-320.jpg)
![21
Bucketing strategies – Time based bucketing
Split partitions in descrete timeframes
e.g. new Bucket every 10
minutes
+ Amount of buckets per day defined
+ Fast solution on insert
- Not very scalable
Time notebook Bucket
0:00 – 0:10 n1 0
0:10 – 0:20 n1 1
0:20 – 0:30 n1 2
Note_by_notebook
P Notebook [text]
P bucket [int]
C Title [text]
...](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-21-320.jpg)
![22
Bucketing strategies – Hash based bucketing
Calculate buckets using primary key
Note_by_notebook
P Notebook [text]
C Title [text]
...
9523
% 2000
notebook Bucket
n1 1523
n1 1723
Example: Amount of Buckets = 2000
7723
% 2000
#
#
+ Amount of buckets defined
+ Deterministic
+ Fast solution
- Not possible if amount of rows is
unknown
Note_by_notebook
P Notebook [text]
P bucket [int]
C Title [text]
...](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-22-320.jpg)

![25
Datamodel – Unique bucketing
note_by_notebook
P Notebook [text]
P Bucket [timeuuid]
C Title [text]
Comment [text]
Creator [text]
CreatedOn
[timestamp]
notebook_partitions_by_na
me
P Notebook [text]
C Bucket [timeuuid]
notebook_partitions_by_note
P Notebook [text]
P Note_title [text]
Bucket [timeuuid]
Problems:
● How to make sure partitions
don‘t grow too big?
● How to make sure notes are not
picked twice?](https://image.slidesharecdn.com/cassandrasummit2016bucketyourpartitionswiselymarkushoefer-160908225537/85/Bucket-your-partitions-wisely-Cassandra-summit-2016-25-320.jpg)










































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

















