Downloaded 28 times








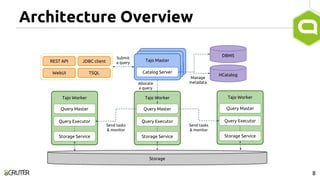
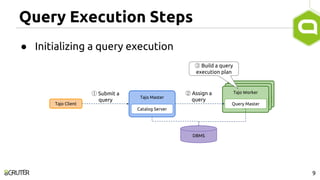
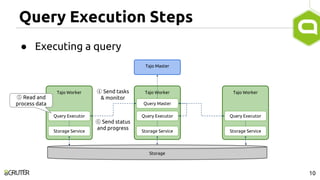
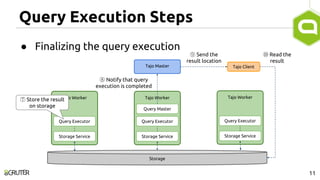


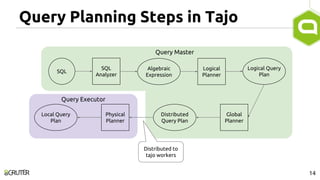
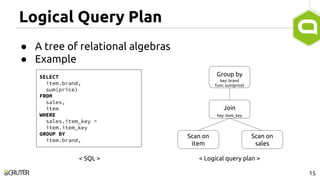
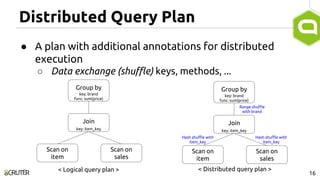
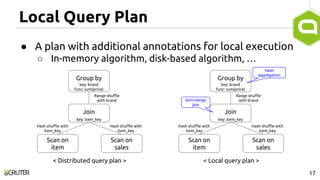
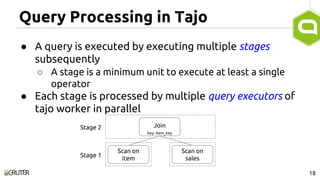
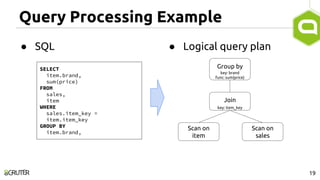
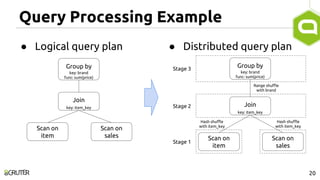
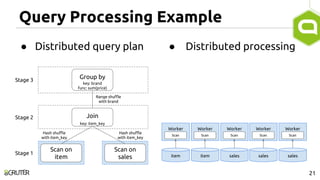
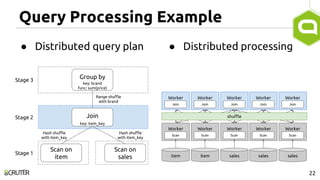
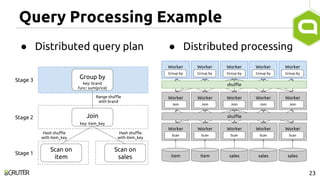


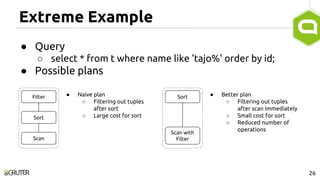






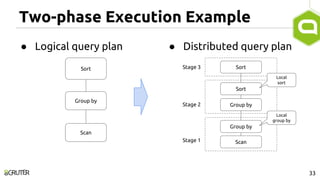

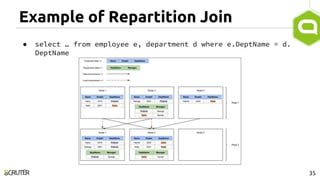
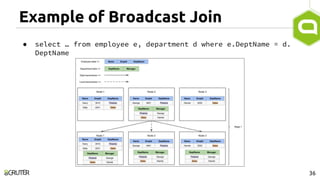

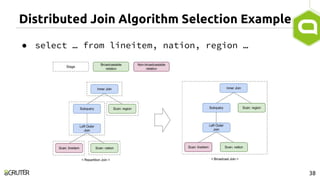


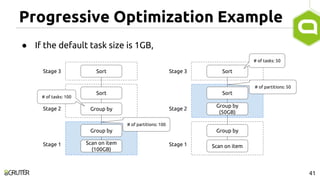



This document discusses query optimization in Apache Tajo. It describes how Tajo generates logical, distributed, and local query plans and optimizes them using rule-based and cost-based techniques. Some key optimization techniques include pushing down filters, selecting join algorithms, and optimizing data partitioning progressively during query execution based on intermediate statistics. The document provides examples of query planning and optimization in Tajo.



![[Paper Reading] Efficient Query Processing with Optimistically Compressed Has...](https://cdn.slidesharecdn.com/ss_thumbnails/icde-2020-220209161641-thumbnail.jpg?width=640&height=640&fit=bounds)





































































