Downloaded 30 times




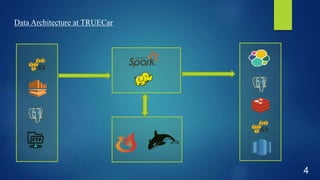
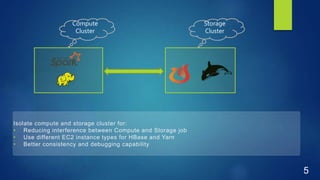




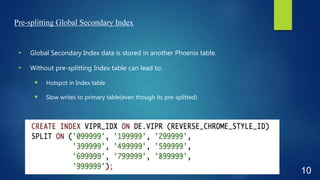






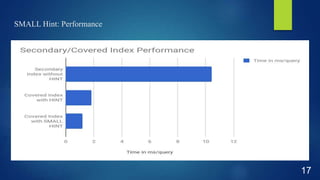


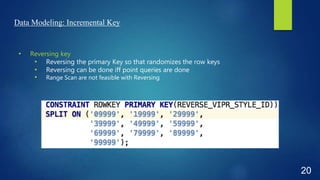



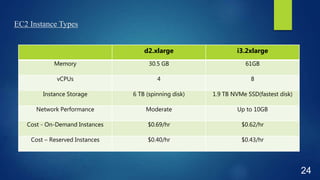



This document discusses performance optimization techniques for Apache HBase and Phoenix at TRUECar. It begins with an agenda and overview of TRUECar's data architecture. It then discusses use cases for HBase/Phoenix at TRUECar and various performance optimization techniques including cluster settings, table settings, data modeling, and EC2 instance types. Specific techniques covered include pre-splitting tables, bloom filters, hints like SMALL and NO_CACHE, in-memory storage, incremental keys, and using faster instance types like i3.2xlarge. The document aims to provide insights on optimizing HBase/Phoenix performance gained from TRUECar's experiences.


















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)















