Download as PDF, PPTX






![Meta information
db=# select * from heap_page_items(get_raw_page('tbl',0));
-[ RECORD 1 ]-------------------
lp | 1
lp_off | 8160
lp_flags | 1
lp_len | 32
t_xmin | 720
t_xmax | 0
t_field3 | 0
t_ctid | (0,1)
t_infomask2 | 2
t_infomask | 2048
t_hoff | 24
t_bits |
t_oid |
t_data |](https://image.slidesharecdn.com/pgconfsvcompression-161116190735/85/PgconfSV-compression-8-320.jpg)





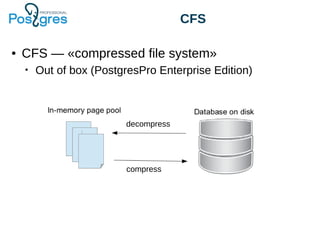
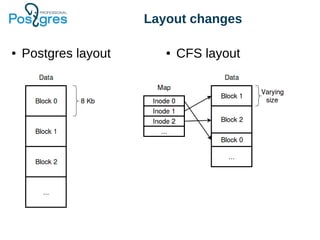

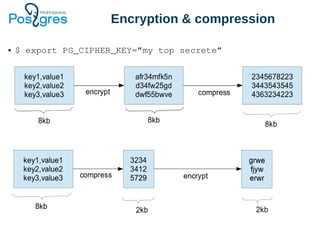




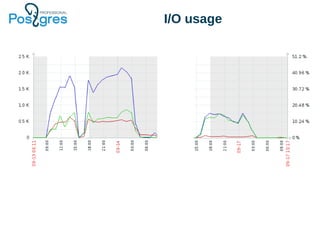
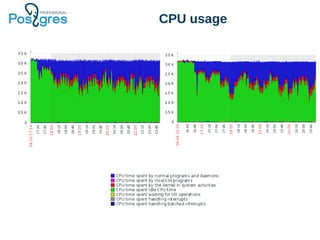





The document discusses PostgreSQL in-core compression features, particularly focusing on storage optimization techniques and the use of Compressed File System (CFS) in PostgreSQL Pro Edition. It covers best practices for schema design, data types, and the impact of various compression algorithms on performance and database size. Additionally, it outlines the advantages and disadvantages of CFS, as well as a roadmap for future improvements to PostgreSQL's storage capabilities.













![[Pgday.Seoul 2017] 3. PostgreSQL WAL Buffers, Clog Buffers Deep Dive - 이근오](https://cdn.slidesharecdn.com/ss_thumbnails/pgday171104-171106041604-thumbnail.jpg?width=640&height=640&fit=bounds)