Download to read offline




![Hassles of Making a Generator
● For simple query, the solution is simple and direct
○ select [cols...] from t1 join t2 on t1.pk = t2.fk
● What if we need to simulate some correlation
○ where a < ‘xx’ and b > ‘yy’
● Or proccess complex projection
○ select case when cond1 then ***, case when cond2
● And the combination of above circumstances….](https://image.slidesharecdn.com/datagenerator-211105075703/85/Paper-Reading-QAGen-Generating-query-aware-test-databases-4-320.jpg)


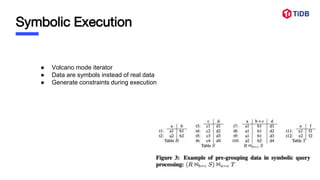


![Symbolic Execution - Selection
● GetNext for child, read tuple “t”
● [Positive Tuple Annotation] if output not reach c
○ for each symbol s in t, insert <s, p>
○ return t to parent
● [Negative Tuple Processing]
○ insert <s, !p>](https://image.slidesharecdn.com/datagenerator-211105075703/85/Paper-Reading-QAGen-Generating-query-aware-test-databases-11-320.jpg)
![Symbolic Execution - Join
● Generate Join Distribution
● GetNext for (outer) child, read tuple “t”
● [Positive Tuple Annotation] replace the fk with pk
● [Negative Tuple Processing]](https://image.slidesharecdn.com/datagenerator-211105075703/85/Paper-Reading-QAGen-Generating-query-aware-test-databases-12-320.jpg)







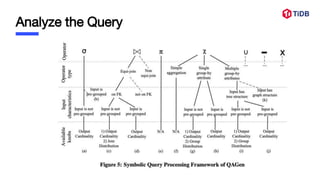
The document discusses the challenges and methods for simulating clients' business needs through query-aware database generators. It highlights two approaches: qagen, which uses symbolic execution to generate test databases, and dgl, a flexible database generation language for better workload handling. Both methods have pros and cons regarding efficiency and complexity in generating effective test data for complex queries.




























![[Paper Reading] Efficient Query Processing with Optimistically Compressed Has...](https://cdn.slidesharecdn.com/ss_thumbnails/icde-2020-220209161641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]Orca: A Modular Query Optimizer Architecture for Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/orca-211220090600-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]KVSSD: Close integration of LSM trees and flash translation la...](https://cdn.slidesharecdn.com/ss_thumbnails/kvssdcloseintegrationoflsmtreesandflashtranslationlayerforwrite-efficientkvstore-211206083654-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]Chucky: A Succinct Cuckoo Filter for LSM-Tree](https://cdn.slidesharecdn.com/ss_thumbnails/chuckyasuccinctcuckoofilterforlsm-tree-211122111631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]The Bw-Tree: A B-tree for New Hardware Platforms](https://cdn.slidesharecdn.com/ss_thumbnails/thebw-treeab-treefornewhardwareplatforms-211115032950-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Leases: An Efficient Fault-Tolerant Mechanism for Distribute...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingleases-211101103843-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper reading] Interleaving with Coroutines: A Practical Approach for Robust...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadinginterleavingwithcoroutinesapracticalapproachforrobustindexjoin-211011055753-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paperreading] Paxos made easy (by sen han)](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingpaxosmadeeasybysenhan-210926142716-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Generalized Sub-Query Fusion for Eliminating Redundant I/O fr...](https://cdn.slidesharecdn.com/ss_thumbnails/resin-210920113222-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Steering Query Optimizers: A Practical Take on Big Data Workl...](https://cdn.slidesharecdn.com/ss_thumbnails/steersigmod21-210913065908-thumbnail.jpg?width=640&height=640&fit=bounds)





























