Download as PDF, PPTX

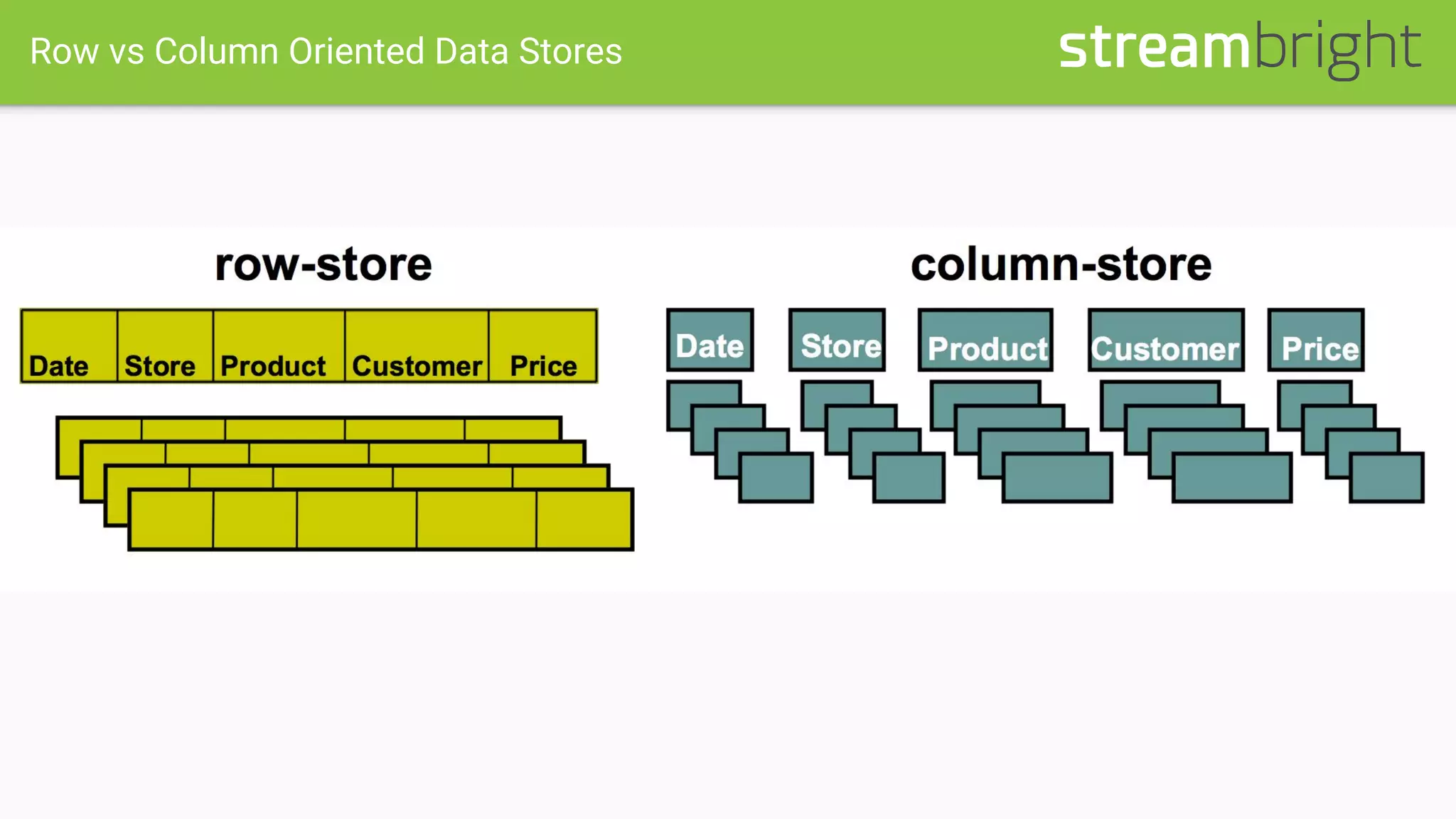















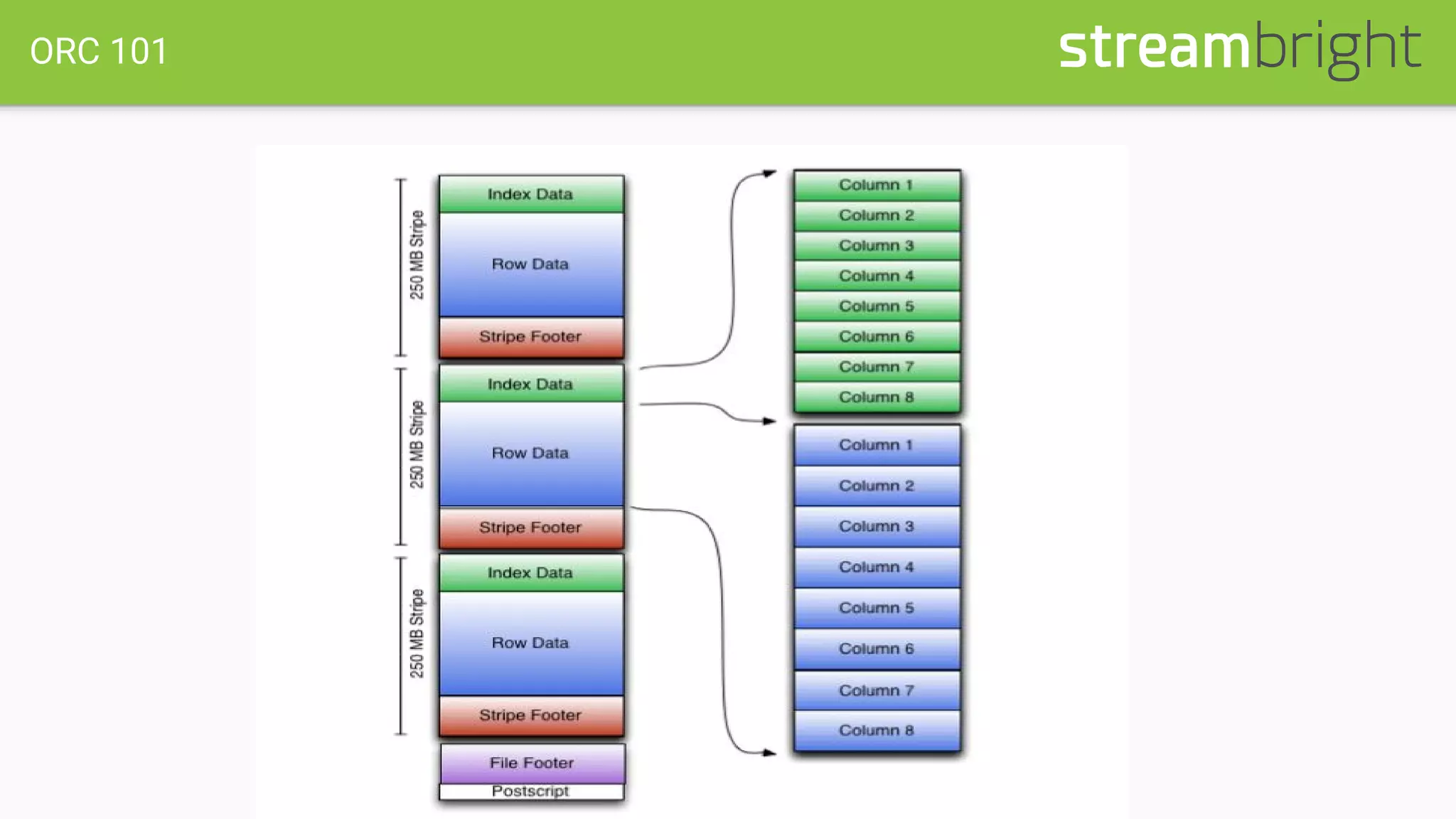



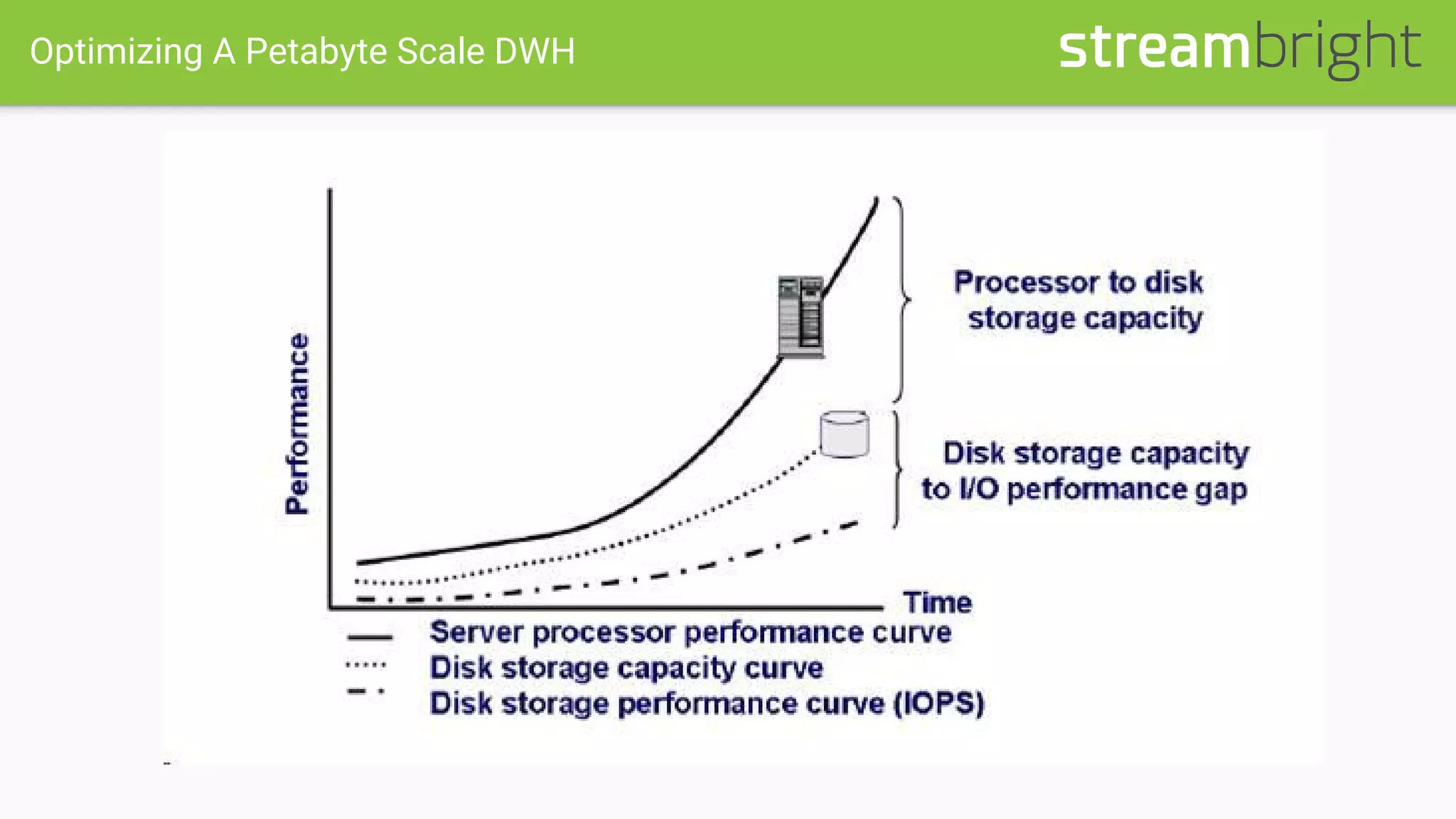







This document discusses optimizing columnar data stores. It begins with an overview of row-oriented versus column-oriented data stores, noting that column stores are well-suited for read-heavy analytical loads as they only need to read relevant data. The document then covers the history of columnar stores and notable features like data encoding, compression techniques like run-length encoding, and lazy decompression. Specific columnar file formats like RCFile, ORC, and Parquet are mentioned. The document concludes with a case study describing optimizations made to a 1PB Hive table that resulted in a 3x query performance improvement through techniques like explicit sorting, improved compression, increased bucketing, and stripe size tuning.


















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















