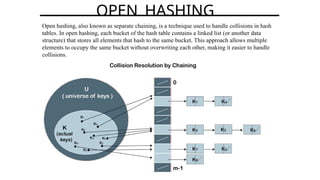
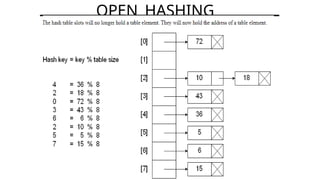
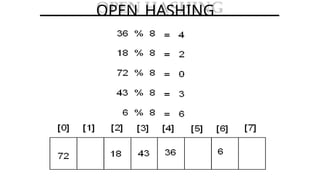
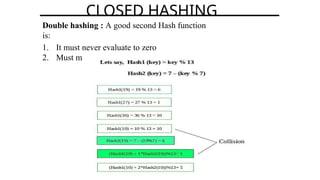
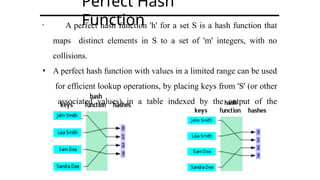
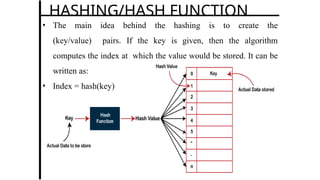
Hashing is a method for efficiently mapping keys to their storage addresses using hash functions, allowing for quick data retrieval in hash tables. While hash tables provide numerous benefits such as constant time complexity for operations and high performance, they also face challenges like collisions and limitations on key values. Various techniques exist for resolving collisions, including open hashing (chaining) and closed hashing, each with its own advantages and disadvantages.










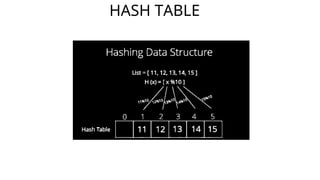

![• A function that maps a key into the range [0 to Max − 1], the
result of which is used as an index (or address) to hash table for
storing and retrieving record
HASH FUNCTION](https://image.slidesharecdn.com/hashingandcollision-240902165254-2e62d24f/85/Hashing-and-Collision-Advanced-data-structure-and-algorithm-12-320.jpg)















![4. Multiplication method :
Example:
k = 12345
A = 0.357840
M = 100
h(12345) = floor[ 100 (12345*0.357840 mod 1)]
= floor[ 100 (4417.5348 mod 1) ]
= floor[ 100 (0.5348) ]
= floor[ 53.48 ]
= 53
TYPES OF HASH FUNCTION](https://image.slidesharecdn.com/hashingandcollision-240902165254-2e62d24f/85/Hashing-and-Collision-Advanced-data-structure-and-algorithm-32-320.jpg)