Downloaded 47 times







![8
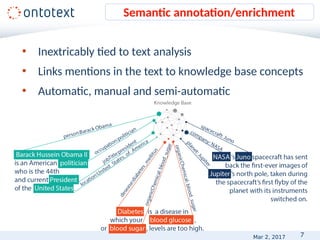
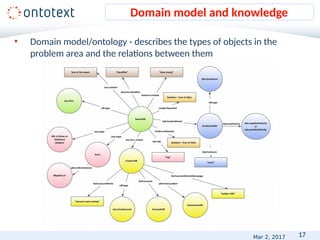
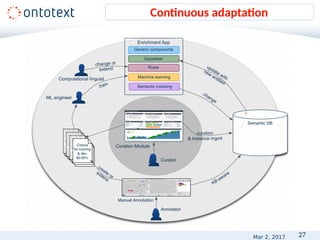
• Named Entity Recognition
– 60% F1 [OKE-challenge@ESWC2015]
– 82.9% F1 [Leaman and Lu, 2016] in the biomedical
domain
– above 90% for more specific tasks
State-of-the art
Mar 2, 2017](https://image.slidesharecdn.com/ontotextswebinartm02-170306095343/85/Efficient-Practices-for-Large-Scale-Text-Mining-Process-8-320.jpg)



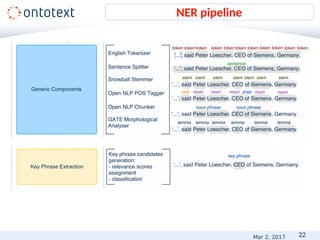
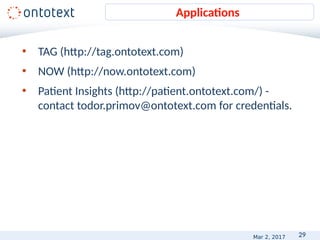
![14
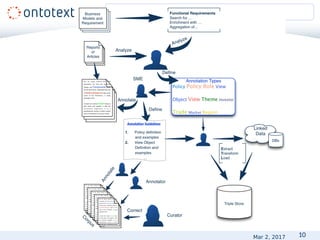
• Annotation types
• Person, Organization, Location
• Person, Organization, City
• Person, Organization, City, Country
• Annotation features
Location: string, geonames instance, latitude, longitude
Chemical: string, inChi, SMILES, CAS
PersonHasRoleInOrganization: person instance, role instance,
organization instance, timestamp
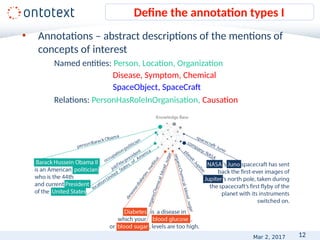
Define the annotation types II
string: the Gulf of Mexico
startOffset: 71
endOffset: 89
type: Location
inst: http://ontology.ontotext.com/resource/tsk7b61yf5ds
links: [http://sws.geonames.org/3523271/
http://dbpedia.org/resource/Gulf_of_Mexico]
latitude:25.368611
longitude:-90.390556
Mar 2, 2017](https://image.slidesharecdn.com/ontotextswebinartm02-170306095343/85/Efficient-Practices-for-Large-Scale-Text-Mining-Process-14-320.jpg)
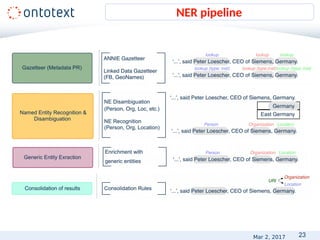
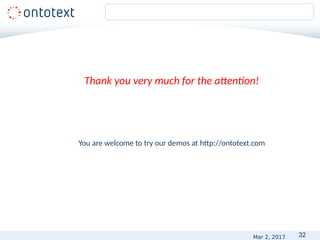
![16
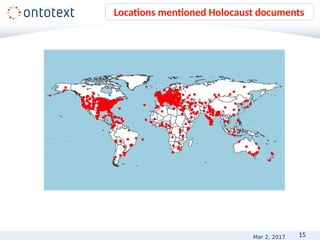
• Realistic
• Demonstrating the desired output
• Positive and negative
• “It therefore increases insulin secretion and reduces POS[glucose] levels,
especially postprandially.”
• “It acts by increasing POS[NEG[glucose]-induced insulin] release and by
reducing glucagon secretion postprandially.”
• Representative and balanced set of the types of problems
• In appropriate/commonly used format – XML, HTML, TXT,
CSV, DOC, PDF.
Provide examples
Mar 2, 2017](https://image.slidesharecdn.com/ontotextswebinartm02-170306095343/85/Efficient-Practices-for-Large-Scale-Text-Mining-Process-16-320.jpg)

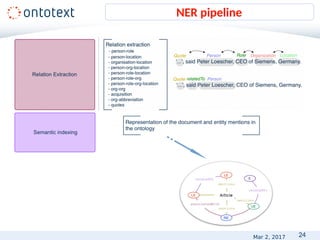
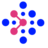
![19
• Gold standard – annotated data with superior quality
• Annotation guidelines - used as guidance for manually annotating the
documents.
POS[London] universities = universities located in London
NEG[London] City Council
NEG[London] Mayor
• Manual annotation tools – intuitive UI, visualization features, export formats
• MANT – Ontotext's in-house tool
• GATE – http://gate.ac.uk/ and https://gate.ac.uk/teamware/
• Brad - http://brat.nlplab.org/
• Annotation approach
• Manual vs. semi-automatic
• Domain experts vs. crowd annotation
• E.g. Mechanical Turk - https://www.mturk.com/
• Inter-annotator agreement
• Train:Test ratio – 60:40, 70:30
Gold standard
Mar 2, 2017](https://image.slidesharecdn.com/ontotextswebinartm02-170306095343/85/Efficient-Practices-for-Large-Scale-Text-Mining-Process-19-320.jpg)







The document discusses best practices for large-scale text mining processes, focusing on the importance of clearly defining business and text analysis problems. It outlines essential steps including data preparation, annotation types, and evaluation metrics while emphasizing the collaborative effort needed from domain experts and technical staff. The document concludes with key takeaways and common pitfalls to avoid in text mining implementations.










































































![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://cdn.slidesharecdn.com/ss_thumbnails/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Conference] Cognitive Graph Analytics on Company Data and News](https://cdn.slidesharecdn.com/ss_thumbnails/texas-data-day18-kiryakov-180131105058-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Webinar] FactForge Debuts: Trump World Data and Instant Ranking of Industry ...](https://cdn.slidesharecdn.com/ss_thumbnails/ranktrumpwebinarapr2017-170421150706-thumbnail.jpg?width=640&height=640&fit=bounds)




![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

















