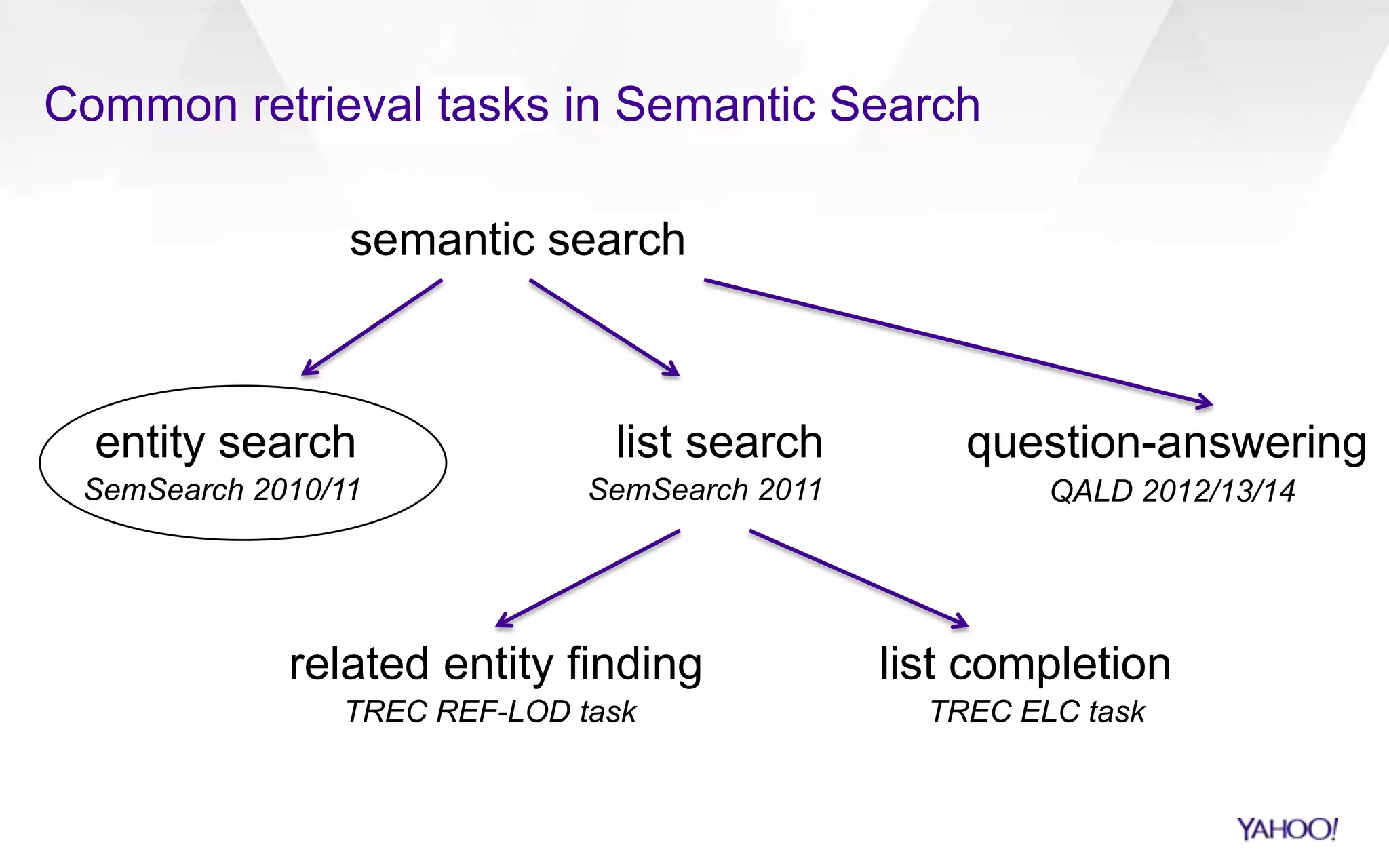
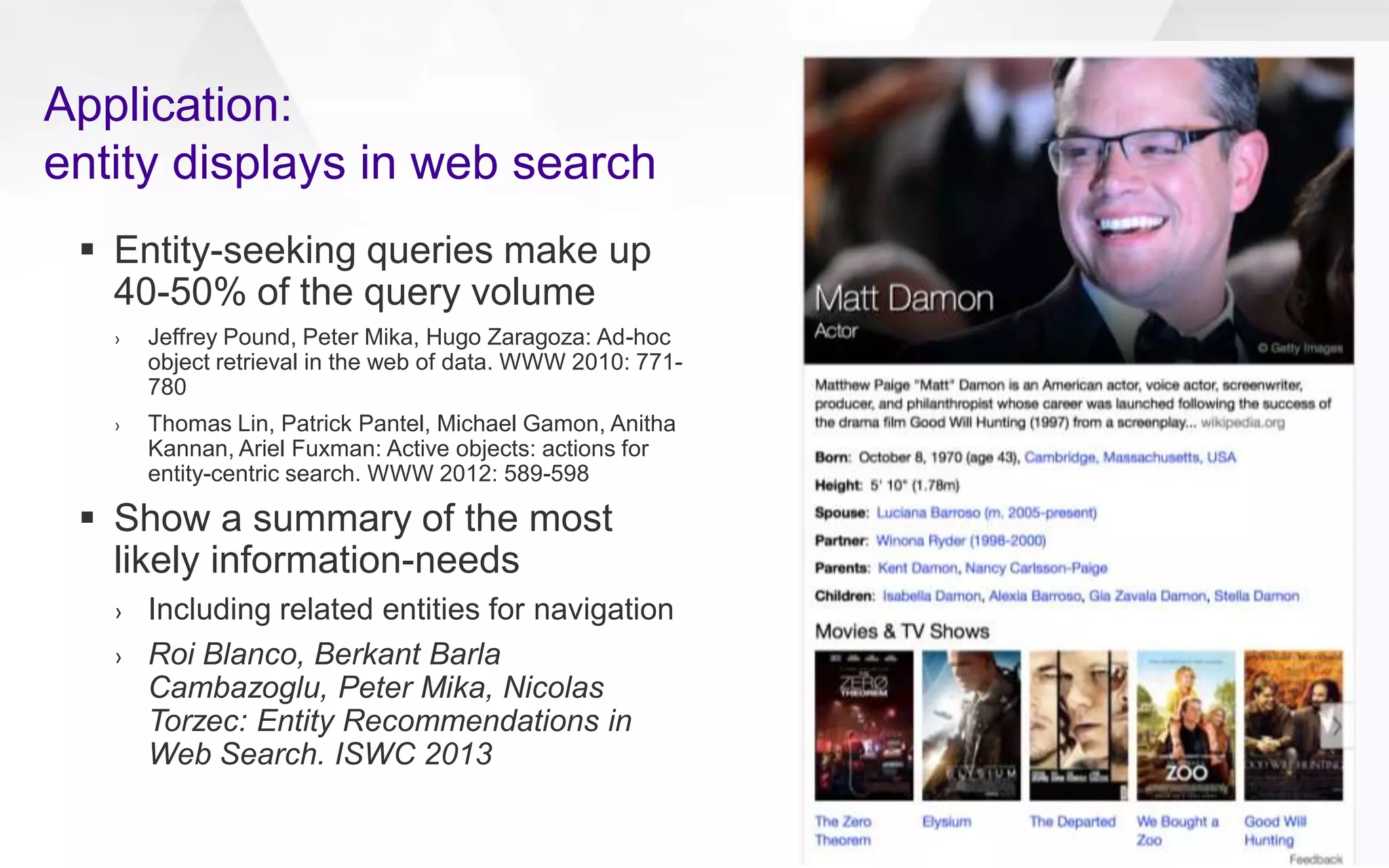
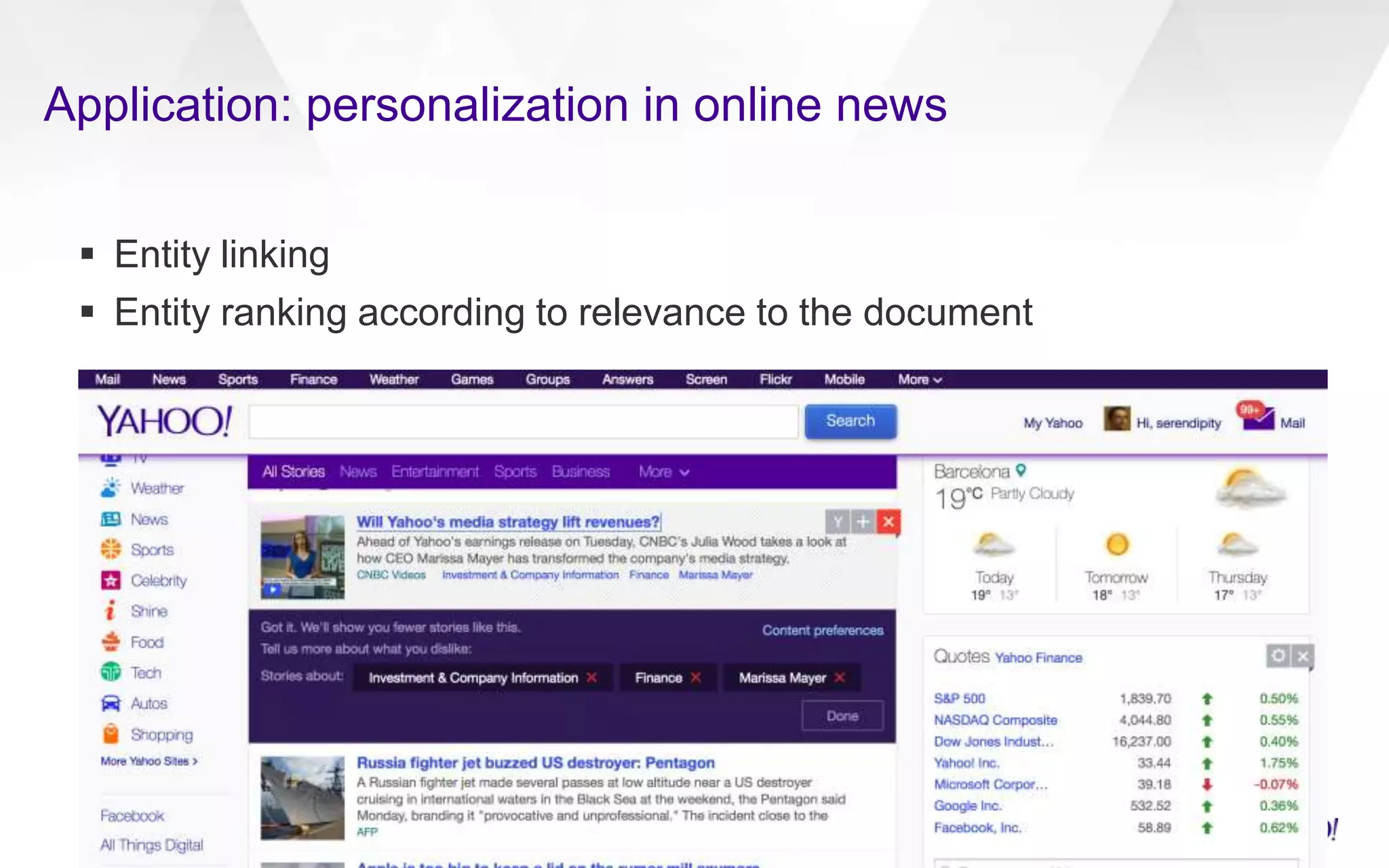
Downloaded 88 times
















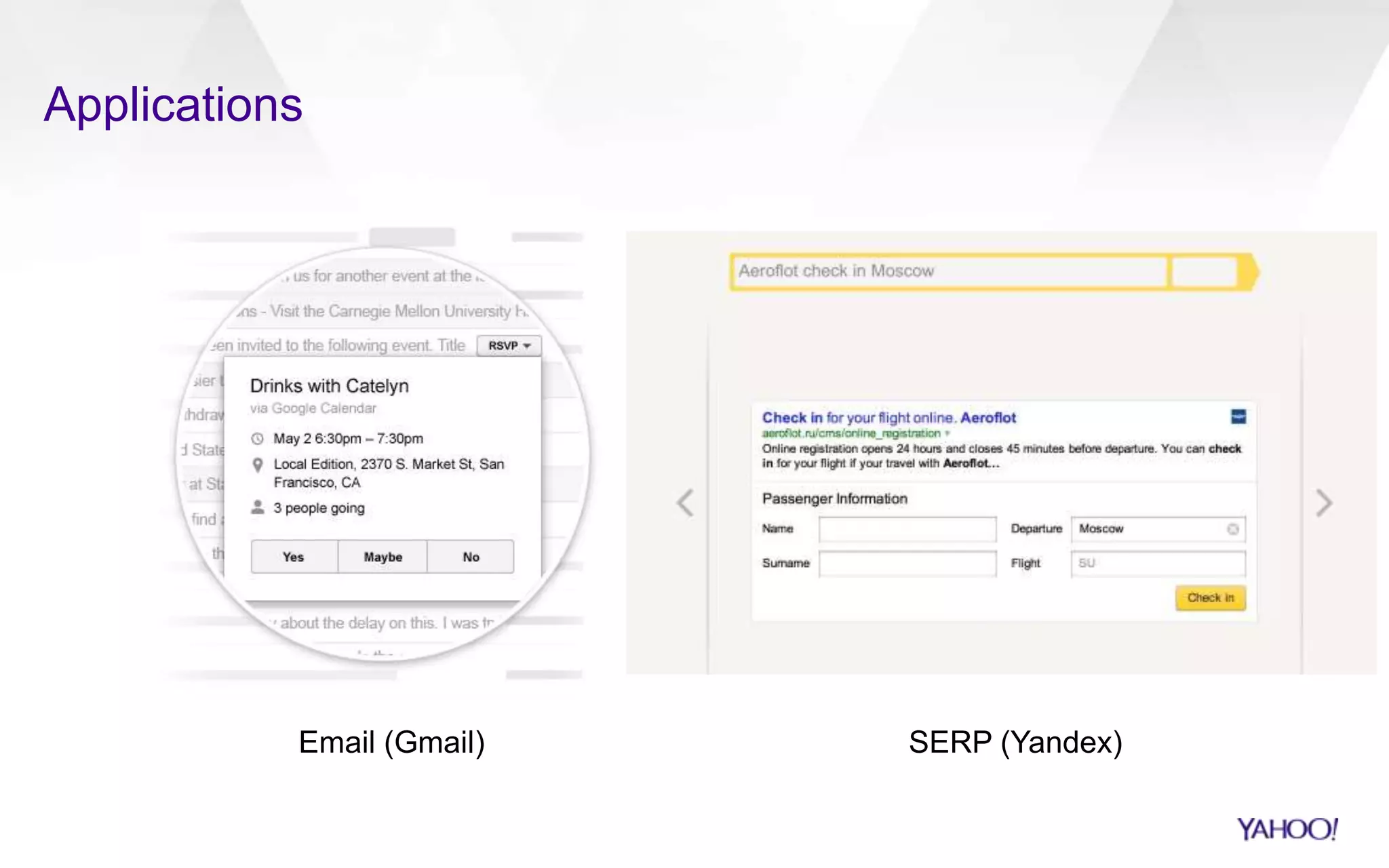
![Mobile search on the rise
Information access on-the-go requires hands-free operation
› Driving, walking, gym, etc.
• Americans spend 540 hours a year in their cars [1] vs. 348 hours browsing the Web [2]
~50% of queries are coming from mobile devices (and growing)
› Changing habits, e.g. iPad usage peaks before bedtime
› Limitations in input/output
[1] http://answers.google.com/answers/threadview?id=392456
[2] http://articles.latimes.com/2012/jun/22/business/la-fi-tn-top-us-brands-news-web-sites-20120622](https://image.slidesharecdn.com/semsearch-ecir-140416055524-phpapp02/75/Semantic-Search-at-Yahoo-28-2048.jpg)





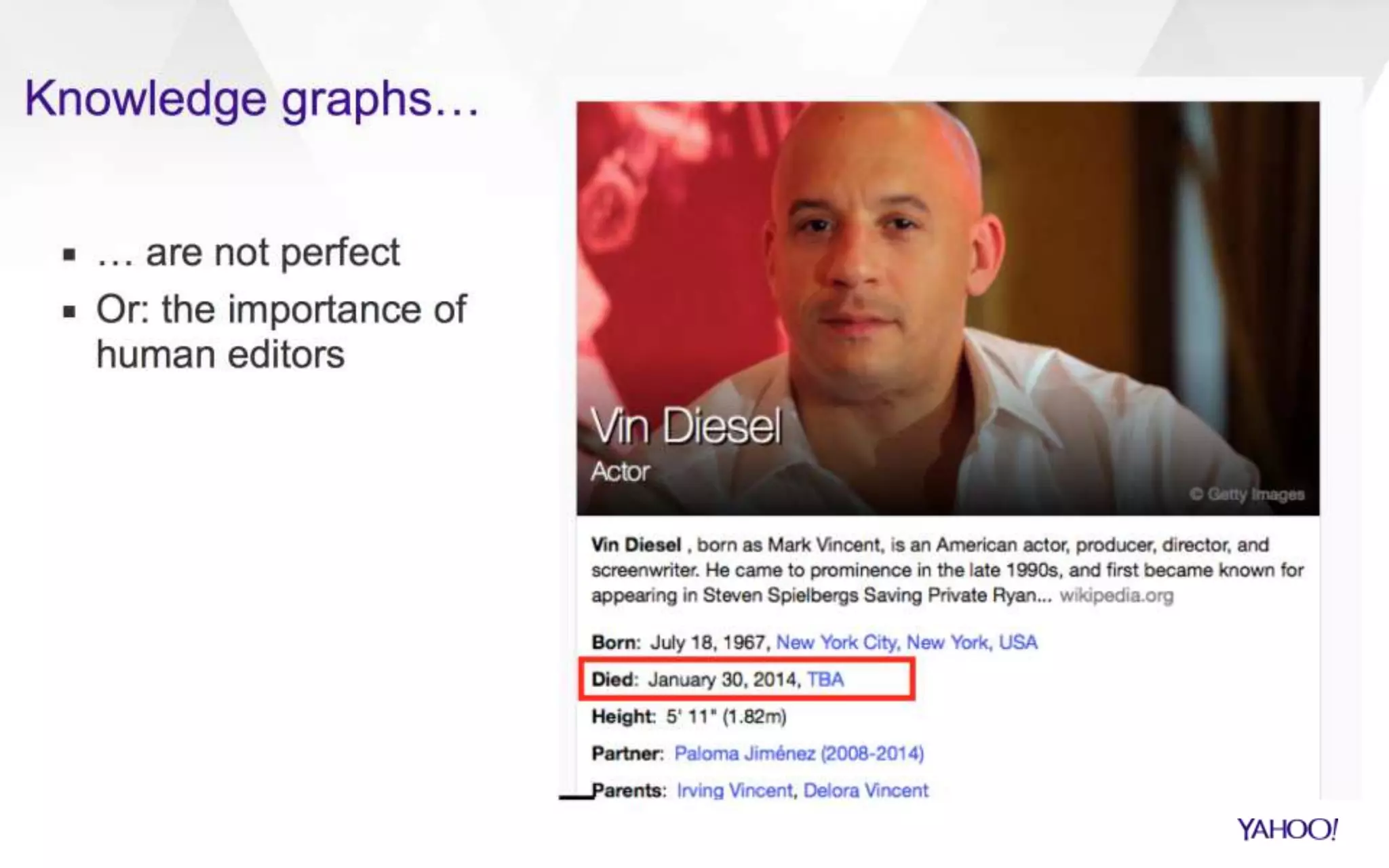
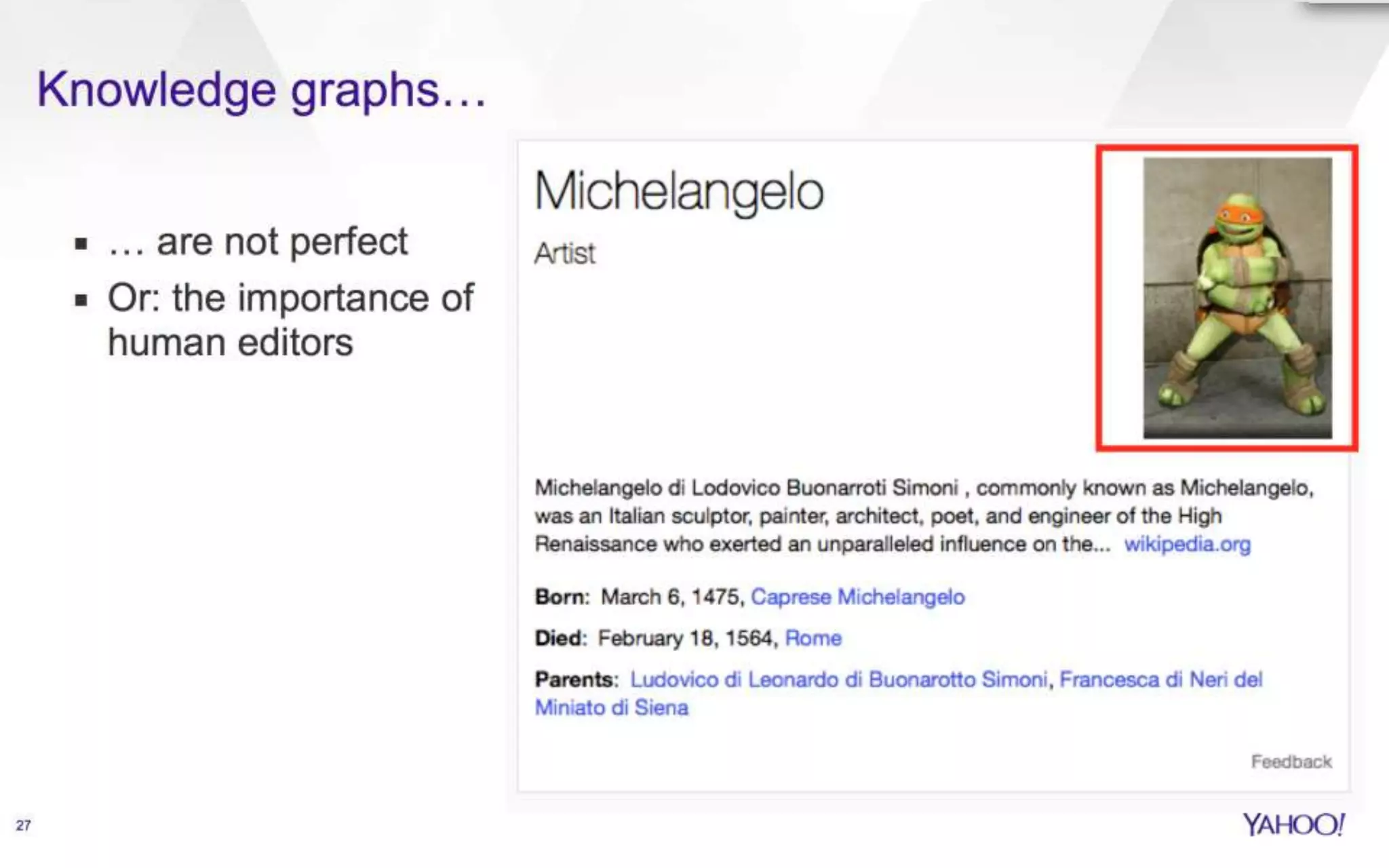
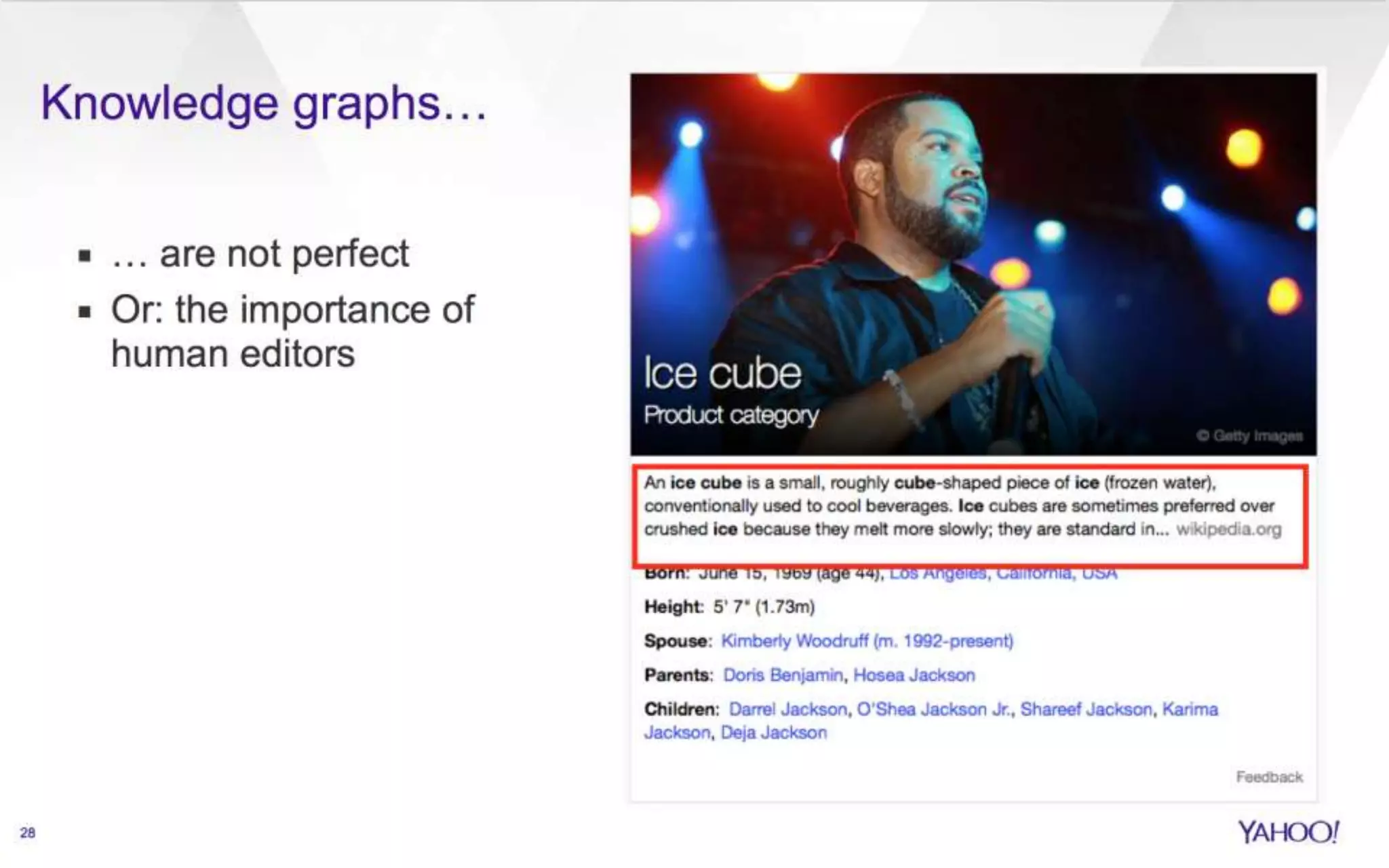
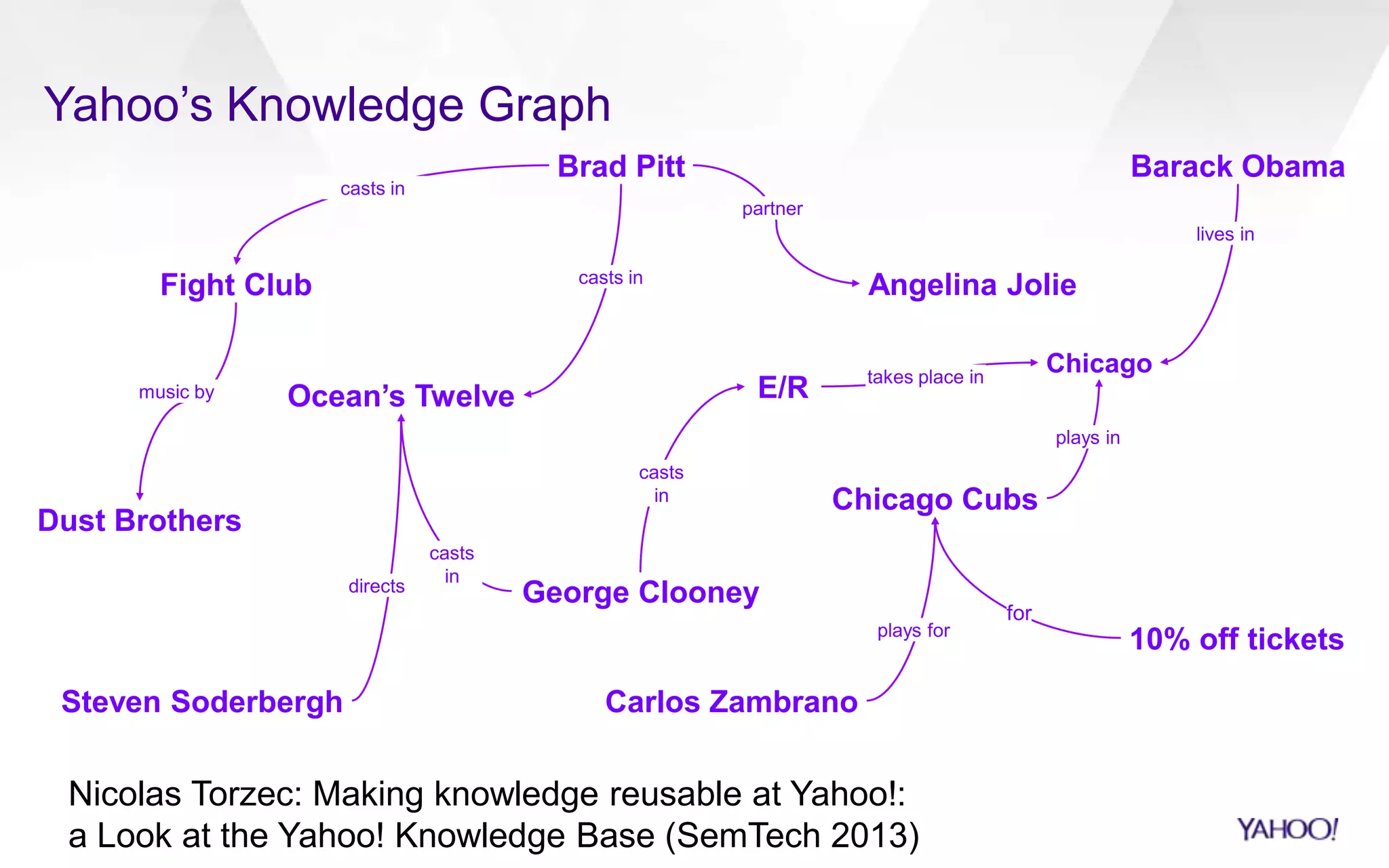
The document discusses semantic search capabilities at Yahoo. It describes how Yahoo has developed techniques to extract structured data and metadata from webpages to power enhanced search results. This includes information extraction, data fusion, and curating knowledge in a graph. Yahoo uses this knowledge to better understand search queries and present relevant entities and attributes in results. Semantic search remains an active area of research.





































![[WEBINAR] Boost Your Paid Search ROI with Bing and Yahoo! Search](https://cdn.slidesharecdn.com/ss_thumbnails/adcentertradawebinarvfinal-120502151017-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















































