Downloaded 82 times
















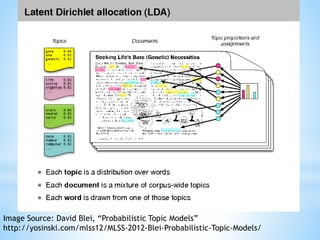







![* Bag of word model
* Ignores structure (syntax) and
meaning (semantics) of sentences
* Representation vector length is the
size of set of unique words in corpus
* Stemming used to remove
morphological differences
* Each word is assigned an index in the
representation vector, V
* The value V[i] is non-zero if word
appears in sentence represented by
vector
* The non-zero value is a function of
the frequency of the word in the
sentence and the frequency of the
term in the corpus
*](https://image.slidesharecdn.com/sullivanbigdatatechcon2015bostonv3-150427161712-conversion-gate01/85/Tools-and-Techniques-for-Analyzing-Texts-Tweets-to-Intellectual-Property-26-320.jpg)















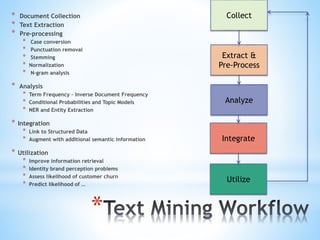
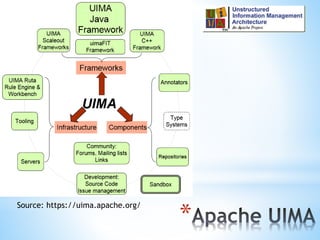








The document discusses various text mining techniques including sentiment analysis, topic modeling, classification, named entity recognition, and event extraction. It provides examples of applications and considerations for each technique. Performance factors like scalability, language support, and integration rules are also covered. Overall the document serves as an introduction to common text analytics methods.





















































































