Download as PDF, PPTX




























![GATE
✤ “The Volkswagen Beetle of language processing”
✤ “...more than a decade of collecting reusable code and building a
community has lead [to] a mature ecosystem for solving language
processing problems quickly.”
✤ Hamish Cunningham 2010
Tuesday, November 29, 2011](https://image.slidesharecdn.com/gettingstartedunstrucdata-111207101502-phpapp02/85/Getting-Started-with-Unstructured-Data-35-320.jpg)







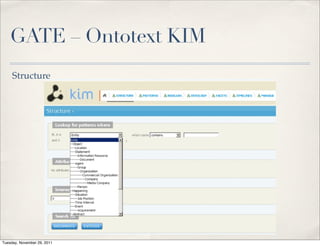
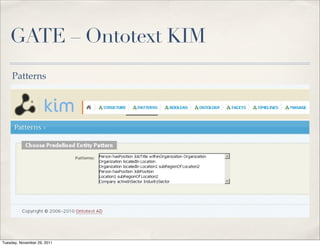
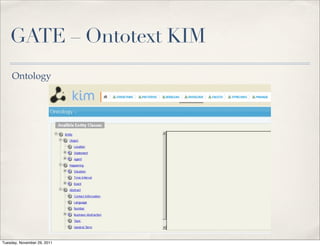
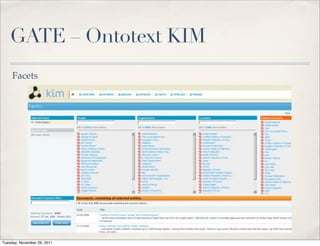




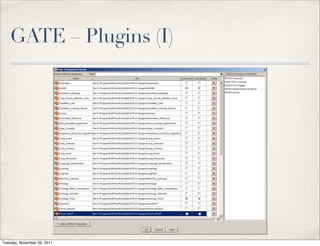
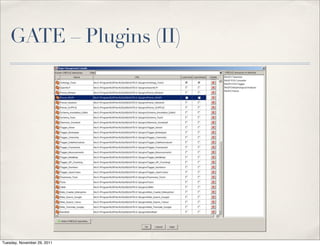
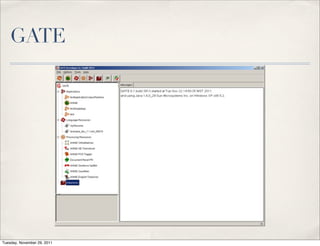









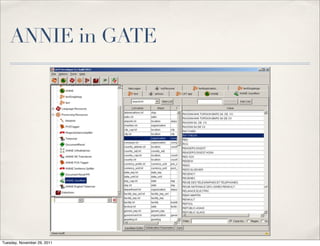


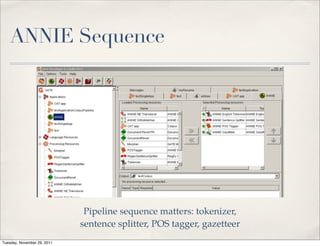





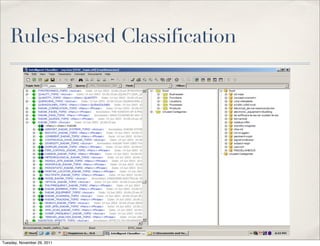

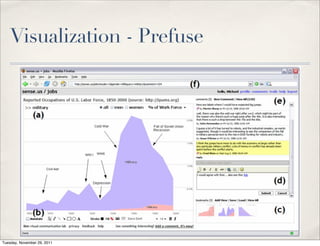
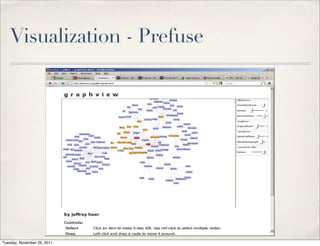
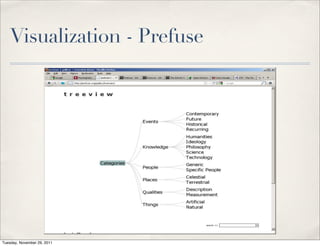
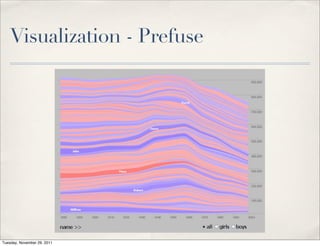
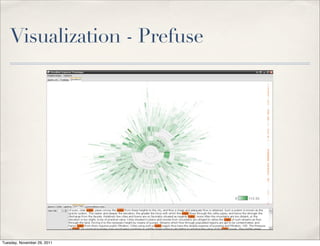
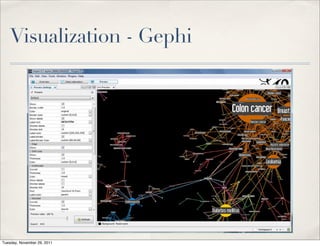
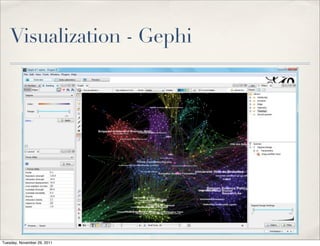
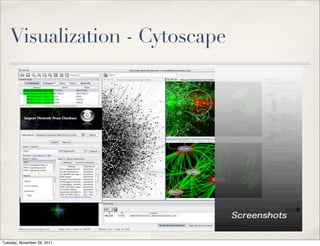








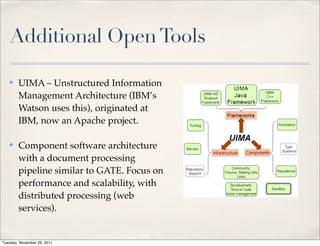






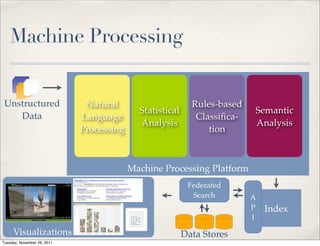
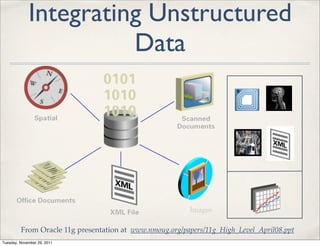
The document discusses unstructured data, defining it as data not organized in a database and often comprising text-based documents, audio/video files, and more. It emphasizes the prevalence of unstructured data in various sources, highlights its importance in understanding business contexts, and details methods for converting unstructured data into actionable knowledge through machine processing and tools like GATE. It also examines concepts like information extraction and named entity recognition as vital components in handling unstructured data.





























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
