Downloaded 35 times





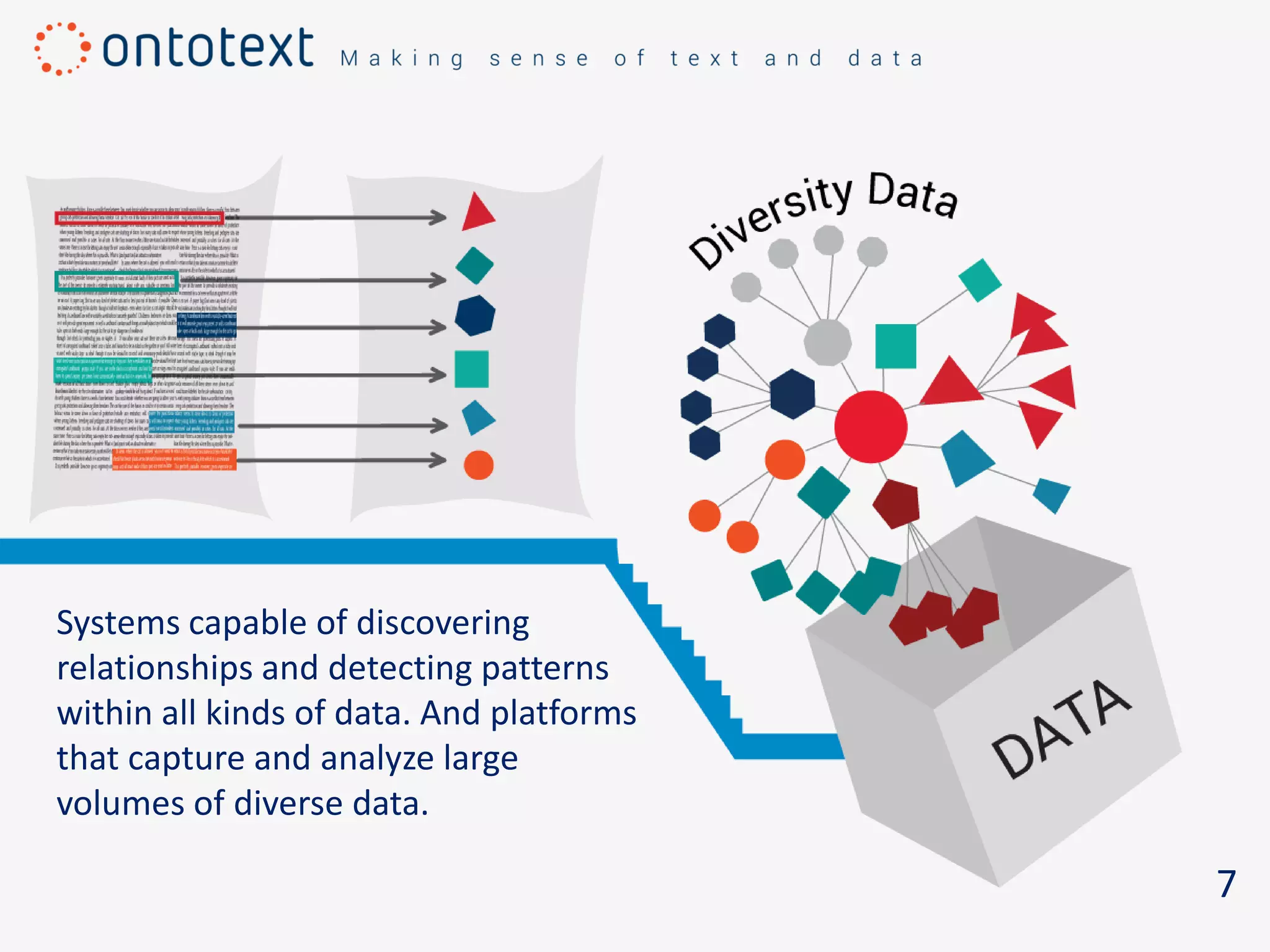

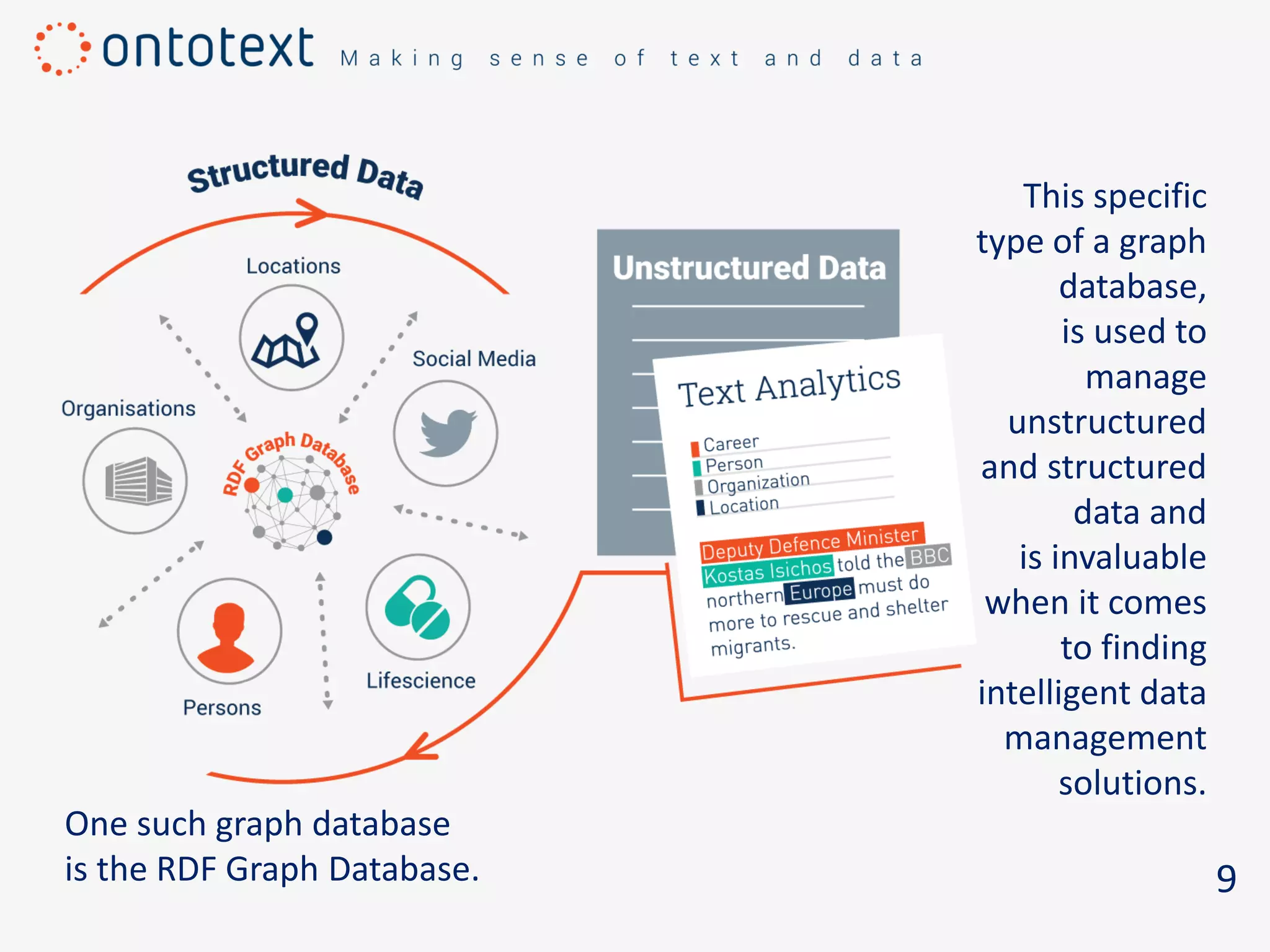
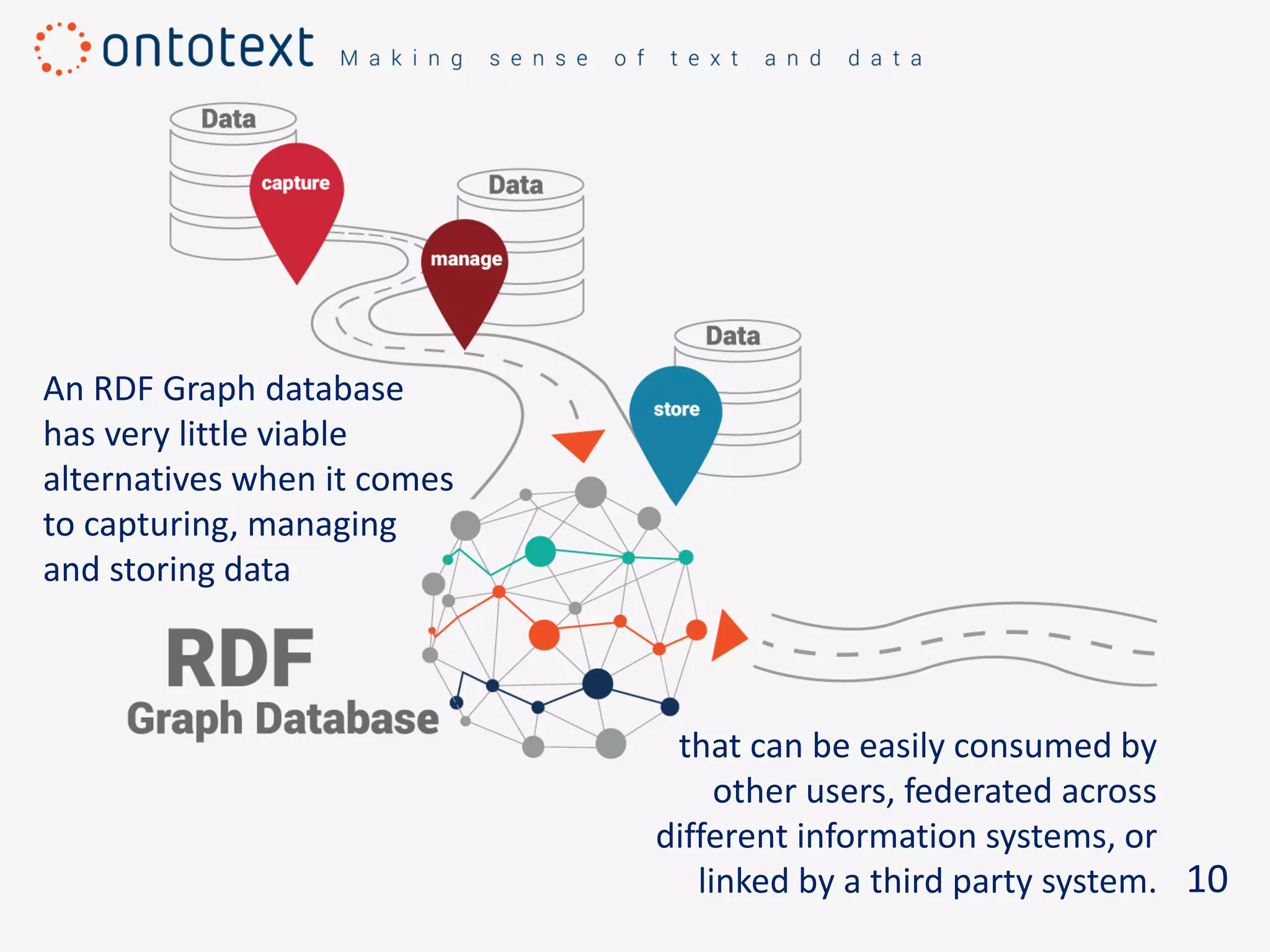




The document discusses the challenges of managing large volumes of diverse data and emphasizes the need for systems like RDF graph databases to convert data into understanding and actionable insights. RDF graph databases are highlighted for their ability to manage both structured and unstructured data, aiding in intelligent data management and integration across information systems. It concludes by encouraging users to consider an RDF database to enhance their data's meaning and utility.



























































![[Conference] Cognitive Graph Analytics on Company Data and News](https://cdn.slidesharecdn.com/ss_thumbnails/texas-data-day18-kiryakov-180131105058-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Webinar] FactForge Debuts: Trump World Data and Instant Ranking of Industry ...](https://cdn.slidesharecdn.com/ss_thumbnails/ranktrumpwebinarapr2017-170421150706-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://cdn.slidesharecdn.com/ss_thumbnails/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)






![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)







