Download to read offline















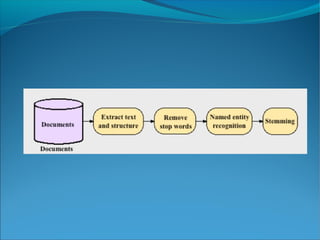










The document discusses text mining, including defining it as the extraction of information from unstructured text using computational methods. It covers topics such as structured vs unstructured data, common text mining practice areas like information retrieval and document clustering, and challenges in text mining including ambiguity in language. Pre-processing techniques for text mining are also outlined, such as normalization, tokenization, stemming and removing stop words to clean and prepare text for analysis.


















































































