Download to read offline

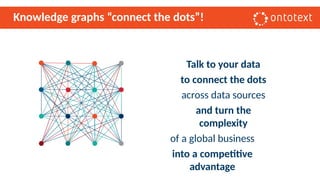

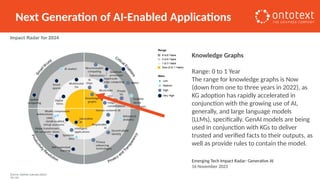

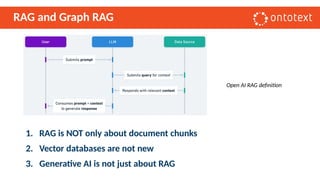


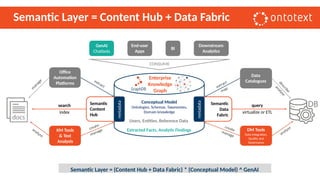



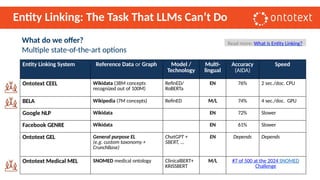

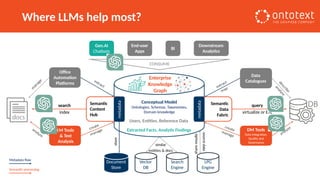






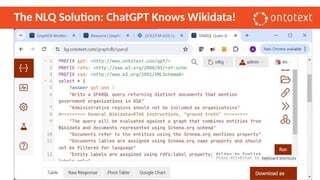


The document presents an overview of knowledge graphs and their integration with generative AI technologies, highlighting their role in transforming complex business data into competitive advantages. It discusses the capabilities of various graph data management systems, their use cases in entity linking, and the benefits of fine-tuning large language models with knowledge graphs. Additionally, it addresses challenges faced in applying retrieval-augmented generation (RAG) and proposes solutions for enhancing data discoverability and effectiveness in managing and utilizing organizational data.


































![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://cdn.slidesharecdn.com/ss_thumbnails/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Conference] Cognitive Graph Analytics on Company Data and News](https://cdn.slidesharecdn.com/ss_thumbnails/texas-data-day18-kiryakov-180131105058-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Webinar] FactForge Debuts: Trump World Data and Instant Ranking of Industry ...](https://cdn.slidesharecdn.com/ss_thumbnails/ranktrumpwebinarapr2017-170421150706-thumbnail.jpg?width=640&height=640&fit=bounds)


























