Downloaded 162 times















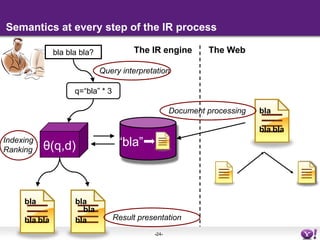




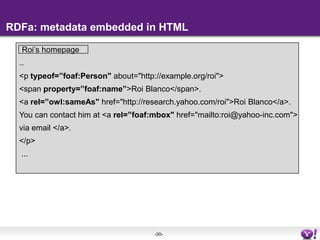




















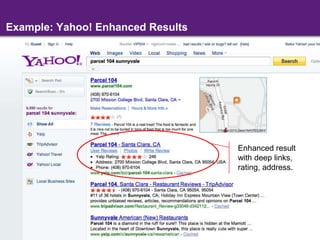
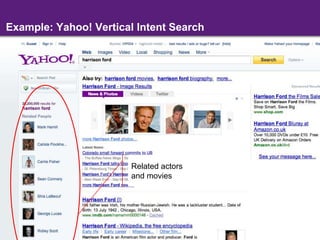
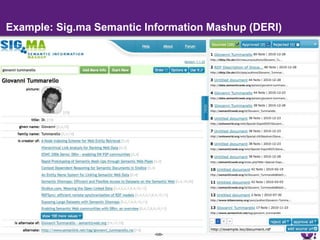
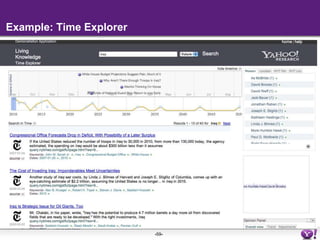




The document discusses the evolution of semantic search, its importance, and challenges from its inception in 2001 to its current state, highlighting the integration of structured data and user intent in search processes. It details various advancements, such as improvements in search accuracy, contextual and semantic search, and the need for better data quality and understanding of user behavior. The discussion also includes semantic web standards, publishers' interests in making content searchable, and the future directions for enhancing semantic search capabilities.










































































