Downloaded 135 times





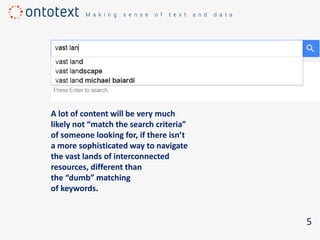
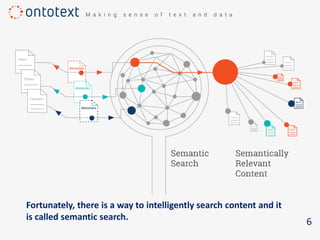
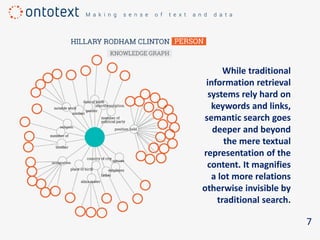
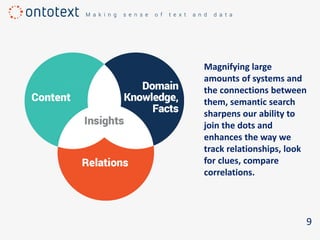
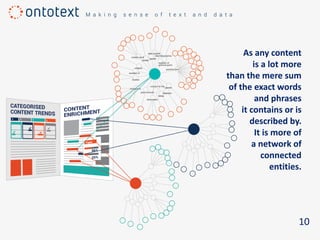
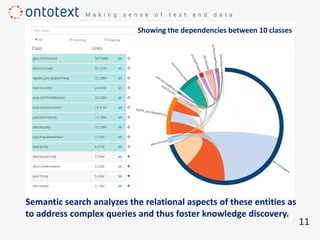
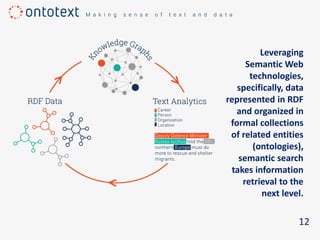
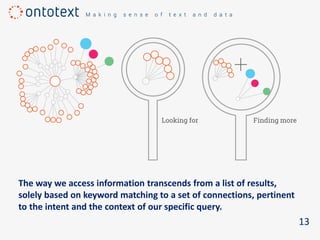


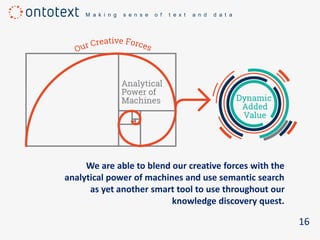

The document discusses the importance of semantic search in overcoming inefficiencies in content management and information retrieval, noting that traditional keyword-based approaches limit knowledge discovery. Semantic search enhances the ability to explore complex relationships between data entities and their meanings, providing a more intuitive and context-aware search experience. It leverages semantic web technologies to transform information retrieval from simple result lists to a network of relevant connections, maximizing the potential for turning data into insights.






































































![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://cdn.slidesharecdn.com/ss_thumbnails/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Conference] Cognitive Graph Analytics on Company Data and News](https://cdn.slidesharecdn.com/ss_thumbnails/texas-data-day18-kiryakov-180131105058-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Webinar] FactForge Debuts: Trump World Data and Instant Ranking of Industry ...](https://cdn.slidesharecdn.com/ss_thumbnails/ranktrumpwebinarapr2017-170421150706-thumbnail.jpg?width=640&height=640&fit=bounds)
























