Download as PDF, PPTX







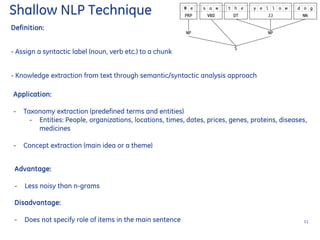

![Definition:
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships: Located in, employed by, part of, married to
Applications:
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection
- Life science: prediction activities based on complex RNA-Sequence
Deep NLP technique
Example:
The above sentence can be represented using triples (Subject: Predicate [Modifier]: Object)
without loosing the context.
Triples:
driver : crash : car
driver : crash with : bumper
driver : be from : Europe
13](https://image.slidesharecdn.com/textmining101v3e-160808141327/85/Text-Mining-Analytics-101-13-320.jpg)
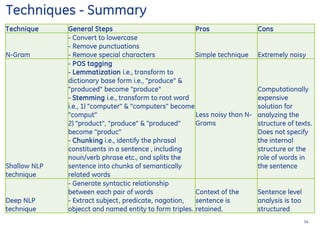


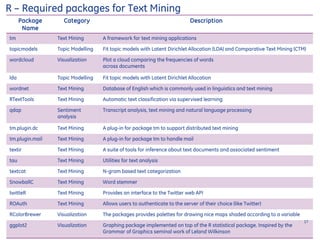




The document provides a comprehensive overview of text mining processes, including data assembly, processing, and visualization techniques. It elaborates on term weight calculations, similarity distance measures, and common text mining techniques such as n-grams and natural language processing. Additionally, it lists required R packages and examples for implementing the procedures, specifically focusing on Twitter data analysis and ensemble classification using Rtexttools.















































































