




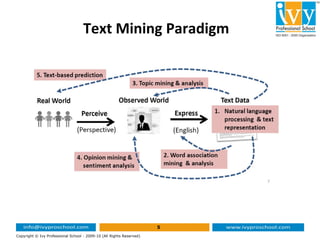
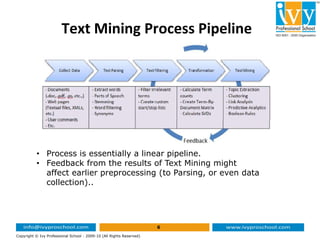





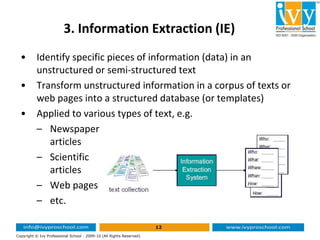


This document provides an introduction to text mining and analytics. It discusses how organizations encounter large amounts of textual data from various sources daily. It states that 80% of business information originates in unstructured text form. Text analytics uses algorithms to convert unstructured text into structured data that can be analyzed using statistical techniques. The key part of text mining is preprocessing the text to extract meaningful structured data through techniques like tokenization, stemming, lemmatization, part-of-speech tagging and named entity recognition. This structured data can then be analyzed through applications such as text clustering, trend analysis and sentiment analysis.






























































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)




![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)