Download to read offline





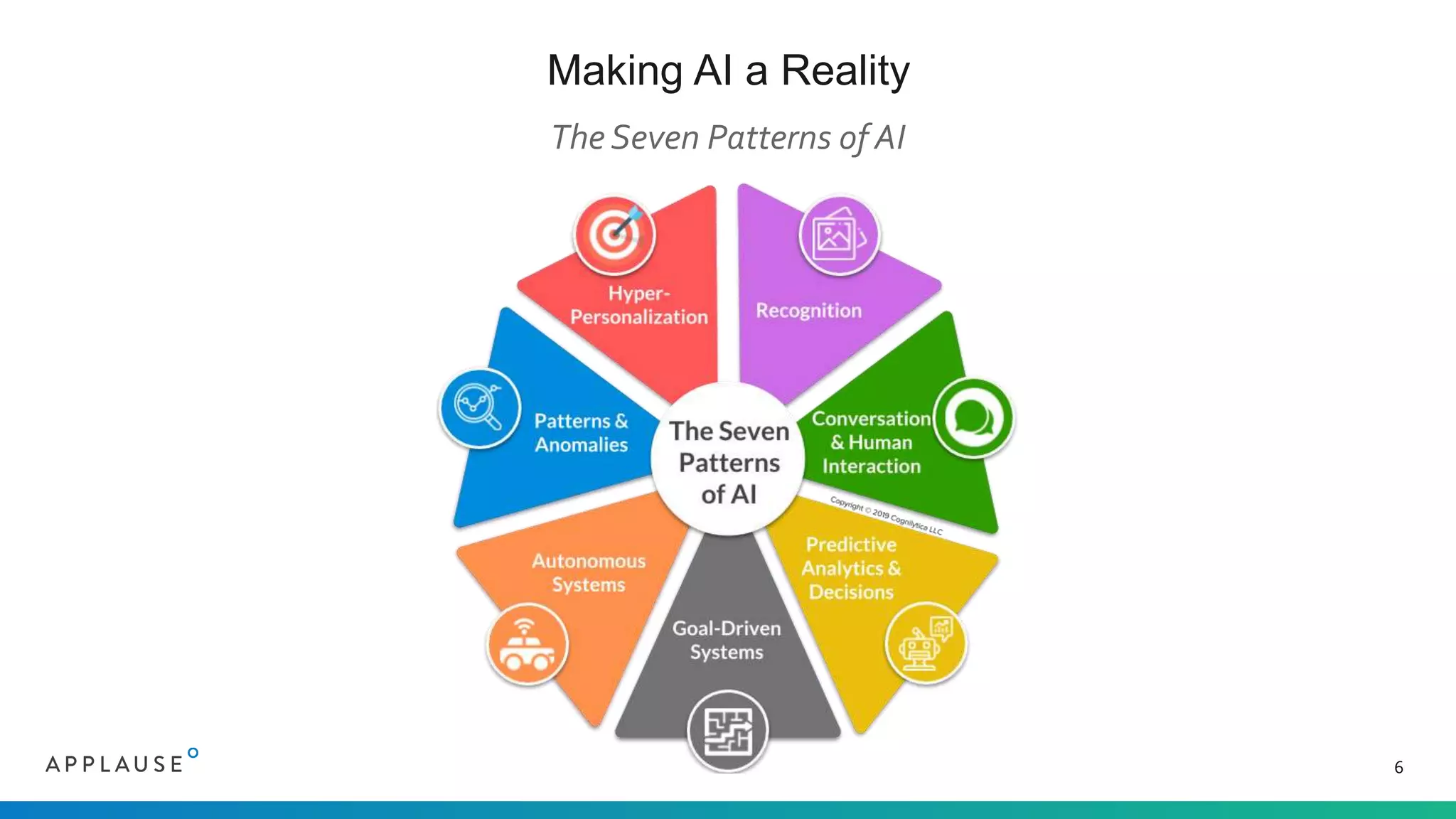


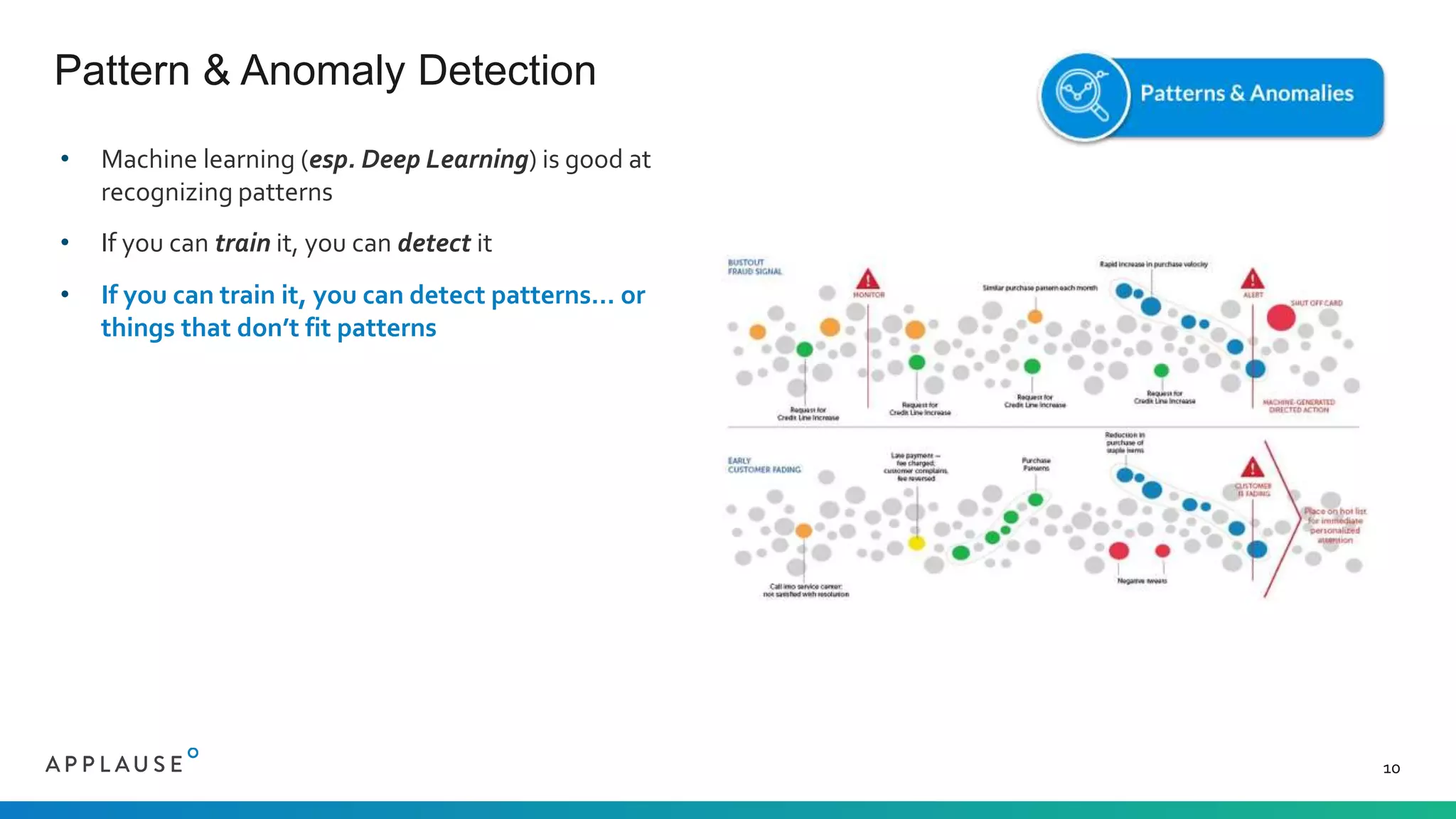

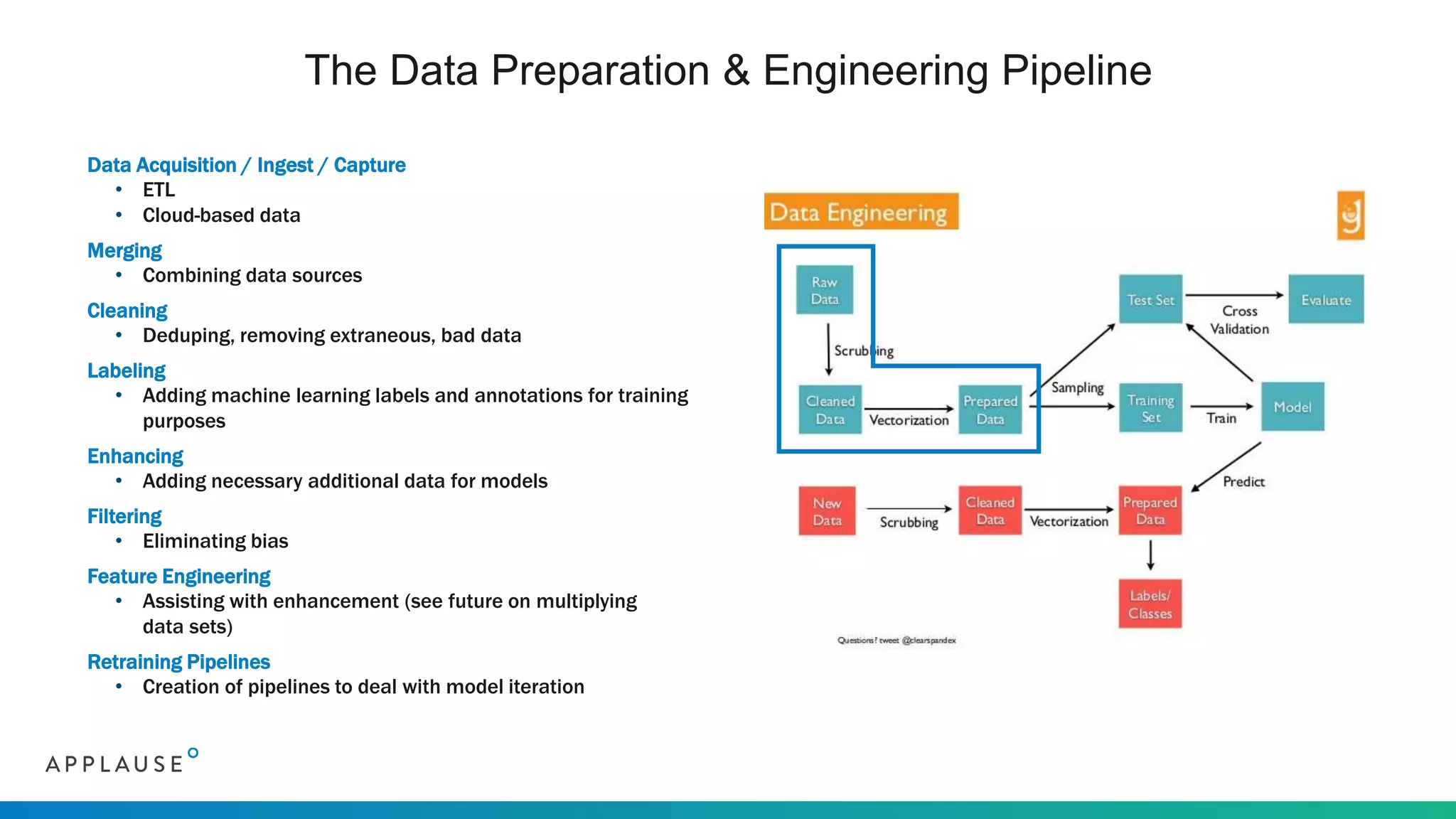

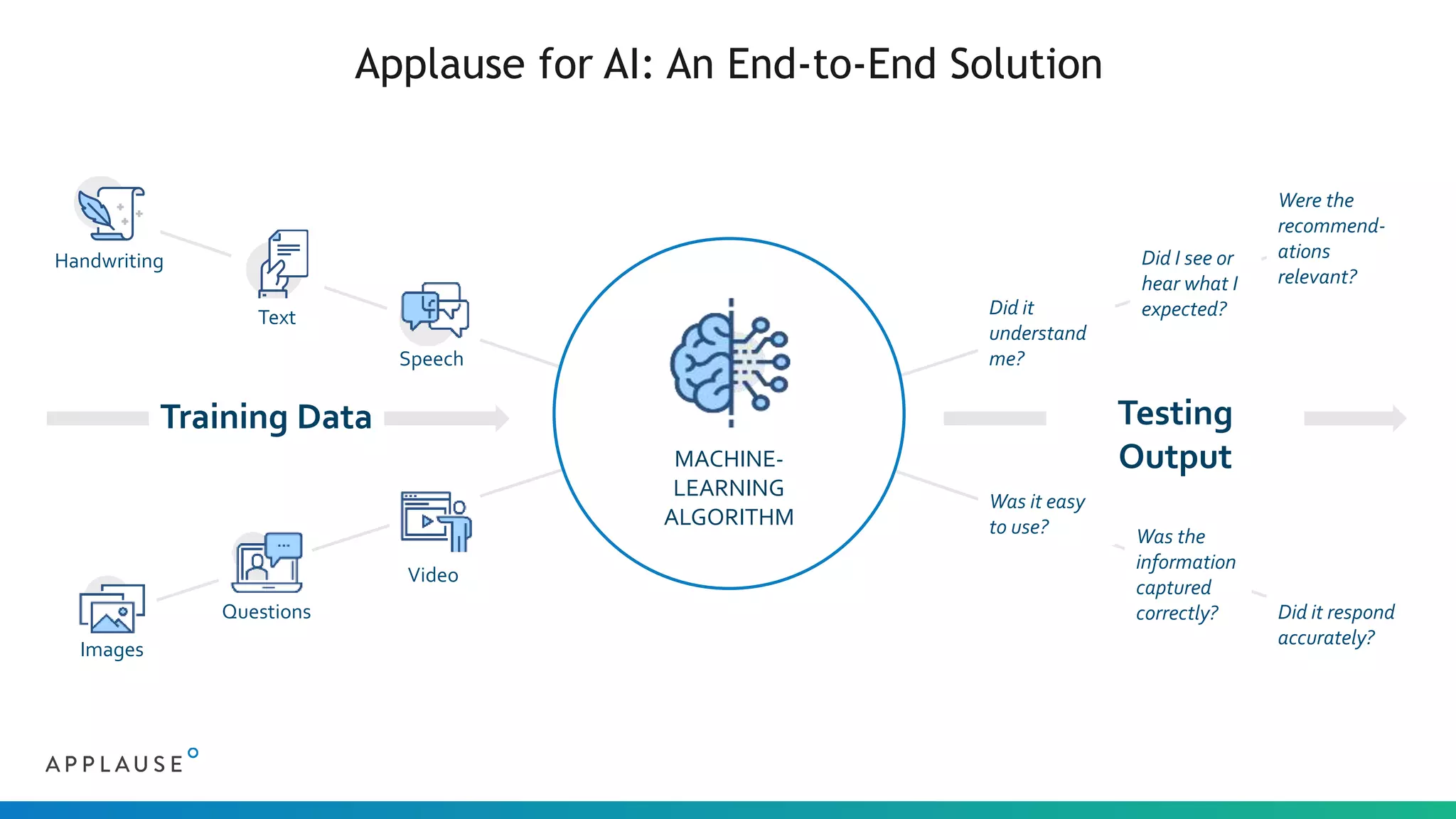

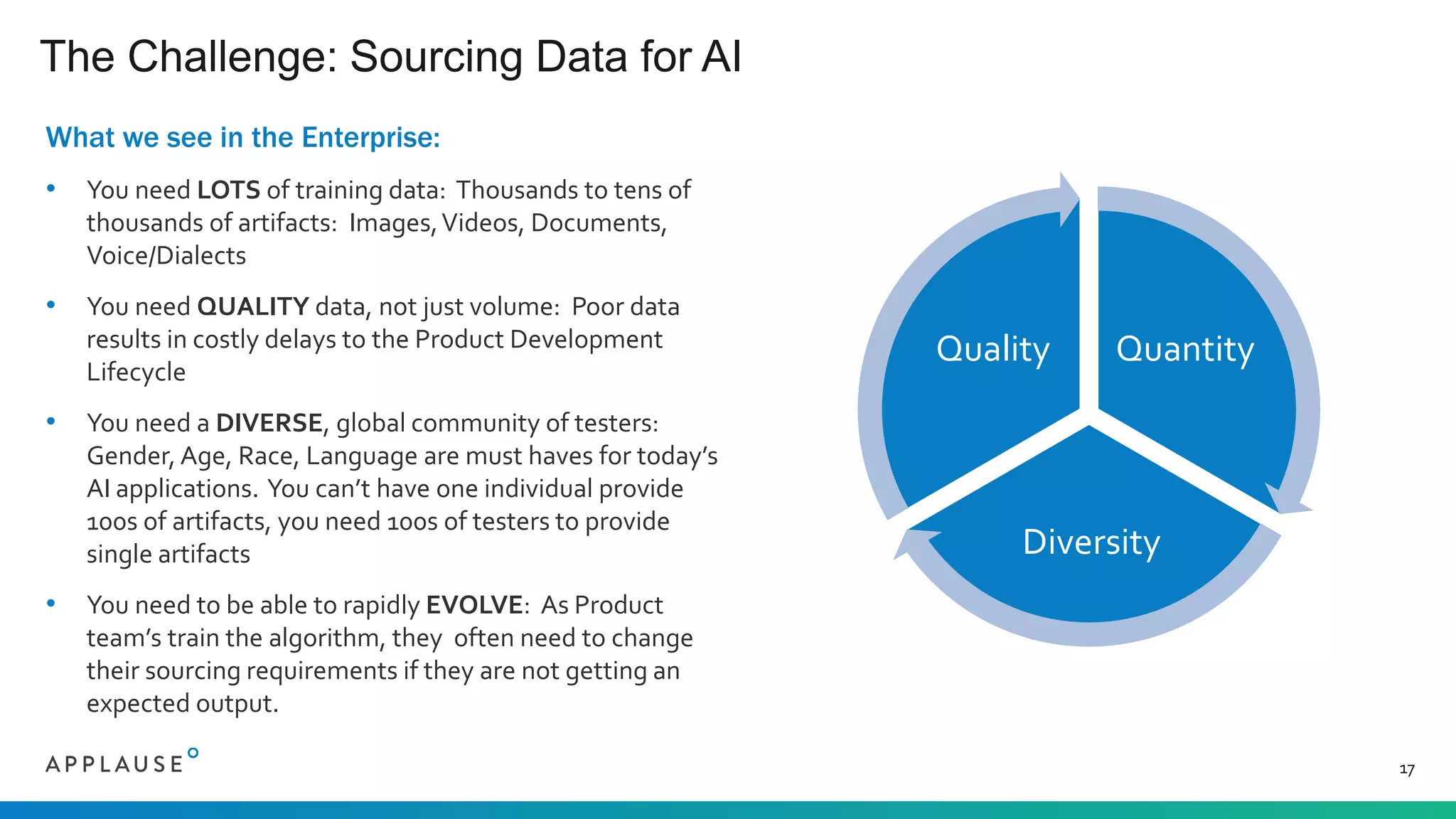










The document discusses the challenges and processes involved in sourcing quality training data for AI applications, highlighting the importance of clean, diverse, and well-labeled data. It outlines seven AI patterns and emphasizes the necessity of extensive data collection and community involvement for successful AI implementation. The document also presents Applause's approach to address these challenges through a vetted community of testers and stringent privacy measures.























































































