Download as PDF, PPTX











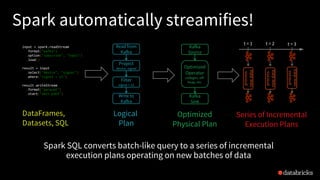





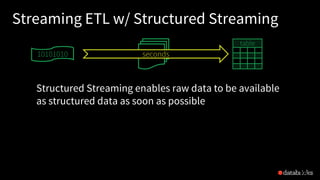
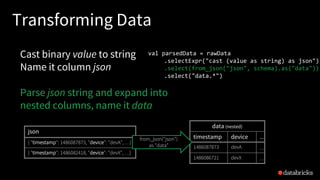
![Traditional ETL
Hours of delay before taking decisions on latest data
Unacceptable when time is of essence
[intrusion detection, anomaly detection, etc.]
file
dump
seconds hours
table
10101010](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummiteurope2017-171026155757/85/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-with-Tathagata-Das-19-320.jpg)

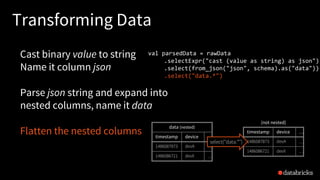
![Reading from Kafka
Specify options to configure
How?
kafka.boostrap.servers => broker1,broker2
What?
subscribe => topic1,topic2,topic3 // fixed list of topics
subscribePattern => topic* // dynamic list of topics
assign => {"topicA":[0,1] } // specific partitions
Where?
startingOffsets => latest(default) / earliest / {"topicA":{"0":23,"1":345} }
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummiteurope2017-171026155757/85/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-with-Tathagata-Das-22-320.jpg)
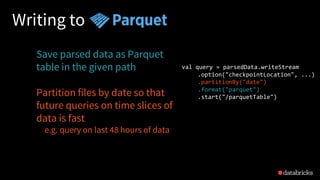
![Reading from Kafka
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()
rawData dataframe has
the following columns
key value topic partition offset timestamp
[binary] [binary] "topicA" 0 345 1486087873
[binary] [binary] "topicB" 3 2890 1486086721](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummiteurope2017-171026155757/85/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-with-Tathagata-Das-23-320.jpg)


















![Other Interesting Operations
Streaming Deduplication
Watermarks to limit state
Joins
Stream-batch joins supported,
stream-stream joins coming in 2.3
Arbitrary Stateful Processing
[map|flatMap]GroupsWithState
parsedData.join(batchData, "device")
parsedData.dropDuplicates("eventId")
[See my other talk at 4:20 PM, today for a deep dive into stateful ops]
ds.groupByKey(_.id)
.mapGroupsWithState
(timeoutConf)
(mappingWithStateFunc)](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummiteurope2017-171026155757/85/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-with-Tathagata-Das-47-320.jpg)
![Monitoring Streaming Queries
Get last progress of the
streaming query
Current input and processing rates
Current processed offsets
Current state metrics
Get progress asynchronously
through by registering your own
StreamingQueryListener
new StreamingQueryListener {
def onQueryStart(...)
def onQueryProgress(...)
def onQueryTermination(...)
}
streamingQuery.lastProgress()
{ ...
"inputRowsPerSecond" : 10024.225210926405,
"processedRowsPerSecond" : 10063.737001006373,
"durationMs" : { ... },
"sources" : [ ... ],
"sink" : { ... }
...
}](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummiteurope2017-171026155757/85/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-with-Tathagata-Das-48-320.jpg)





![Read from
rawLogs = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("subscribe", "rawLogs")
.load()
augmentedLogs = rawLogs
.withColumn("msg",
from_json($"value".cast("string"),
schema))
.select("timestamp", "msg.*")
.join(table("customers"), ["customer_id"])
DataFrames can be
reused for multiple
streams
Can build libraries of
useful DataFrames and
share code between
applications
JSON ETL](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummiteurope2017-171026155757/85/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-with-Tathagata-Das-54-320.jpg)



![Simple Alerts
sparkErrors
.as[ClusterHeartBeat]
.filter(_.load > 99)
.writeStream
.foreach(new PagerdutySink(credentials))
E.g. Alert when Spark cluster load > threshold
Latency: ~100 ms
Alerts
notify PagerDuty](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummiteurope2017-171026155757/85/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-with-Tathagata-Das-58-320.jpg)
![Complex Alerts
sparkErrors
.as[ClusterHeartBeat]
.groupBy(_.id)
.flatMapGroupsWithState(Update, EventTimeTimeout) {
(id: Int, events: Iterator[ClusterHeartBeat], state: GroupState[ClusterState]) =>
... // check if cluster non-responsive for a while
}
E.g. Monitor health of Spark clusters
using custom stateful logic
Latency: ~10 seconds
Alerts
react if no heartbeat
from cluster for 1 min](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummiteurope2017-171026155757/85/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-with-Tathagata-Das-59-320.jpg)







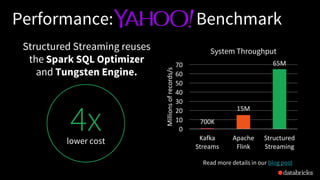
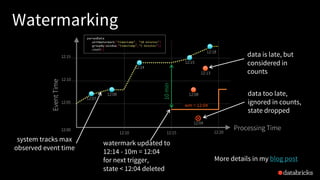
The document discusses the complexities of building scalable and fault-tolerant stream processing applications using Structured Streaming with Apache Spark. It highlights key features such as handling diverse data formats and storage systems, ensuring exactly-once processing semantics, and leveraging Spark SQL for incremental execution. The presentation covers practical examples and concepts like triggers, output modes, and watermarking to efficiently manage state and late data in streaming queries.



































![[Sneak Preview] Apache Spark: Preparing for the next wave of Reactive Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/coll-report-typesafe-apache-spark-slide-share-150127023731-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)





















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)








