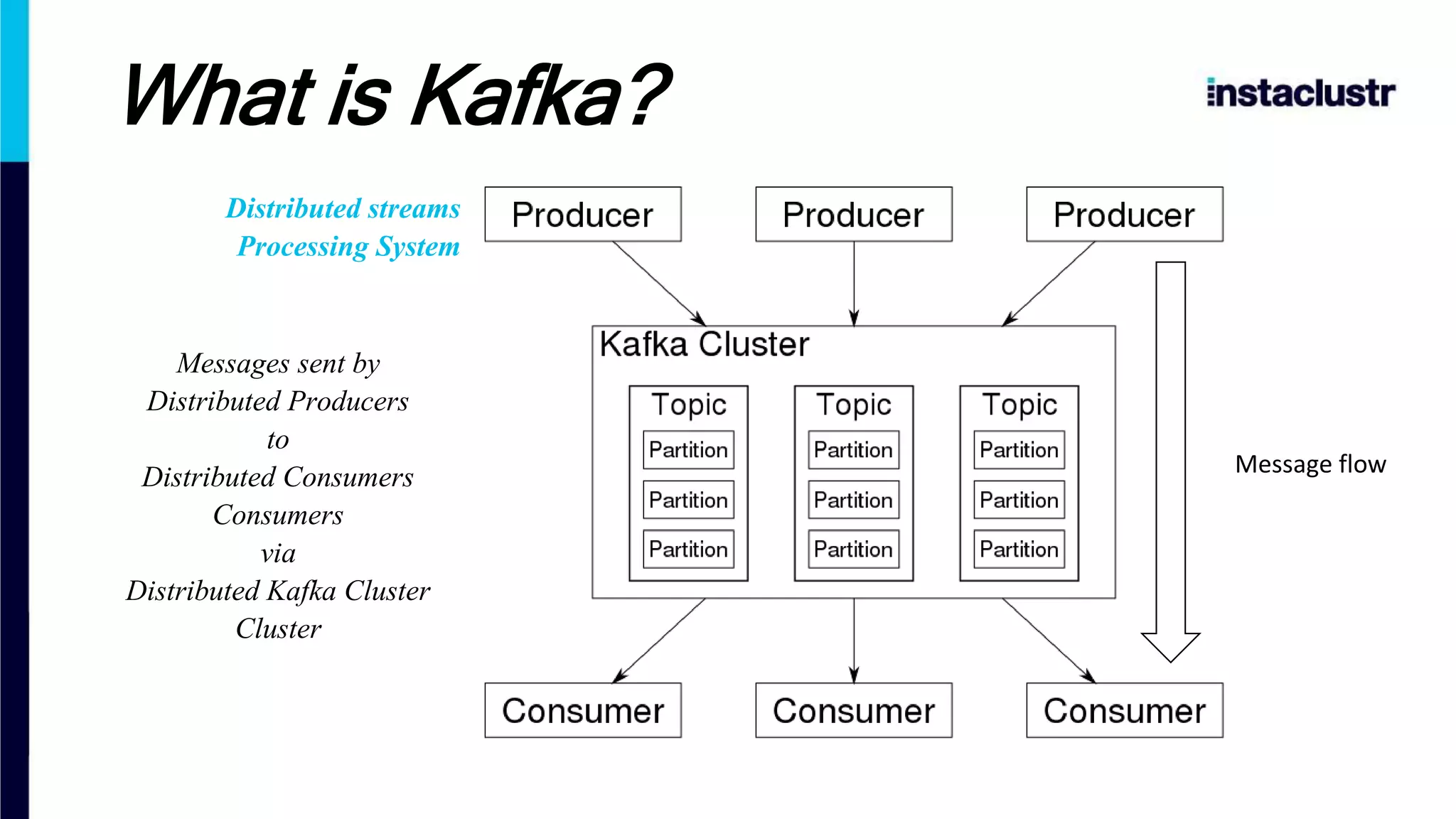
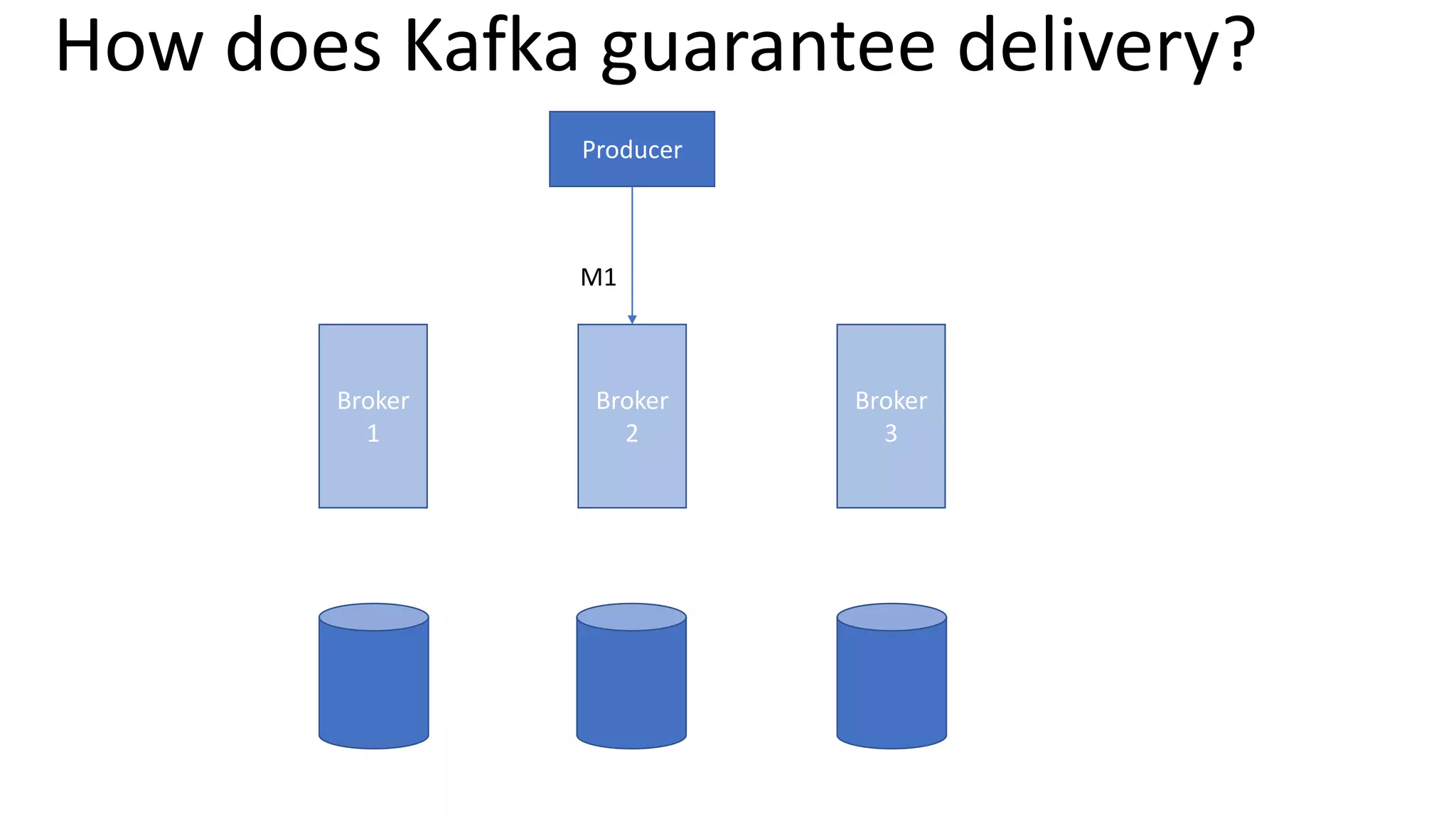
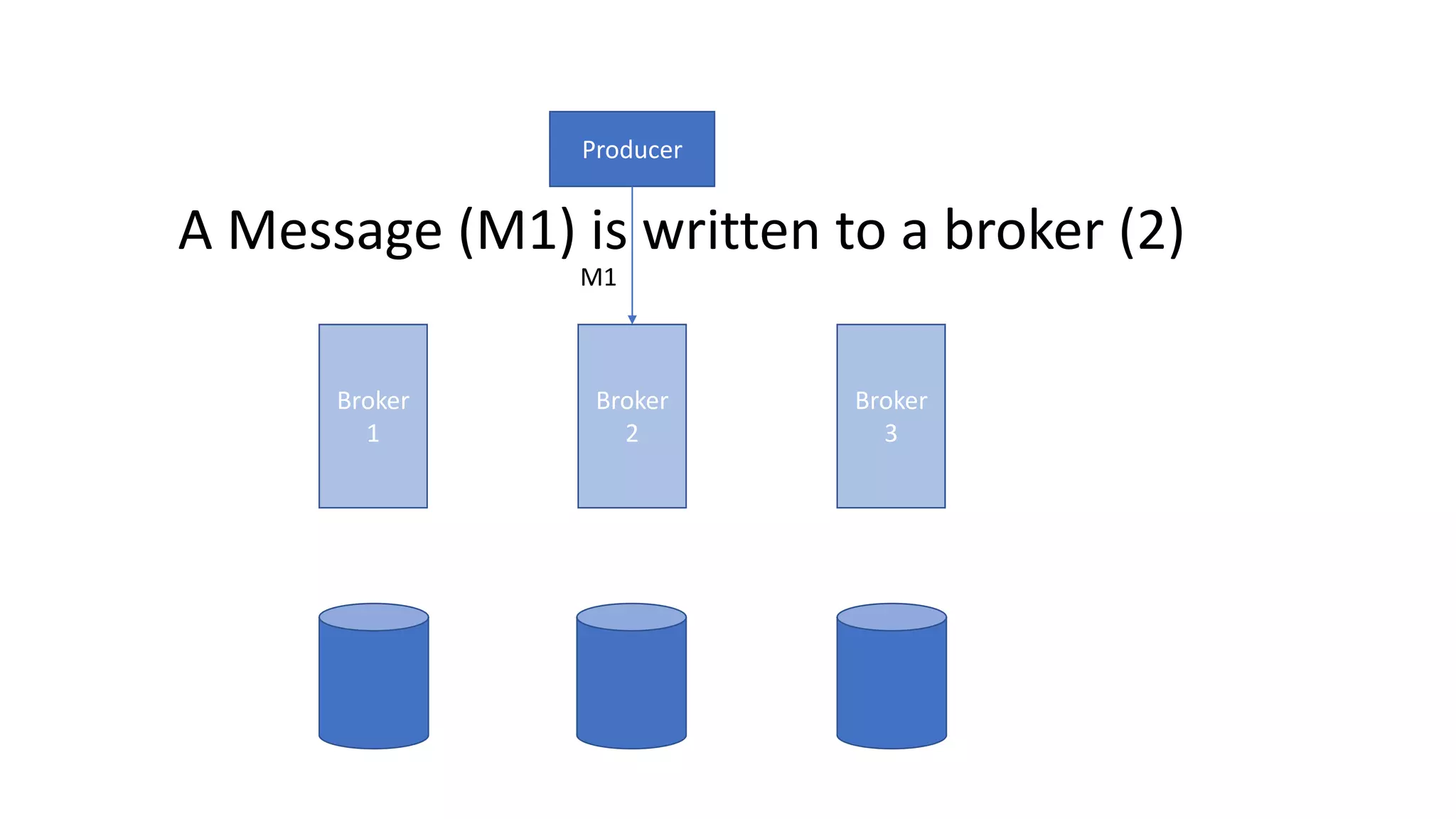
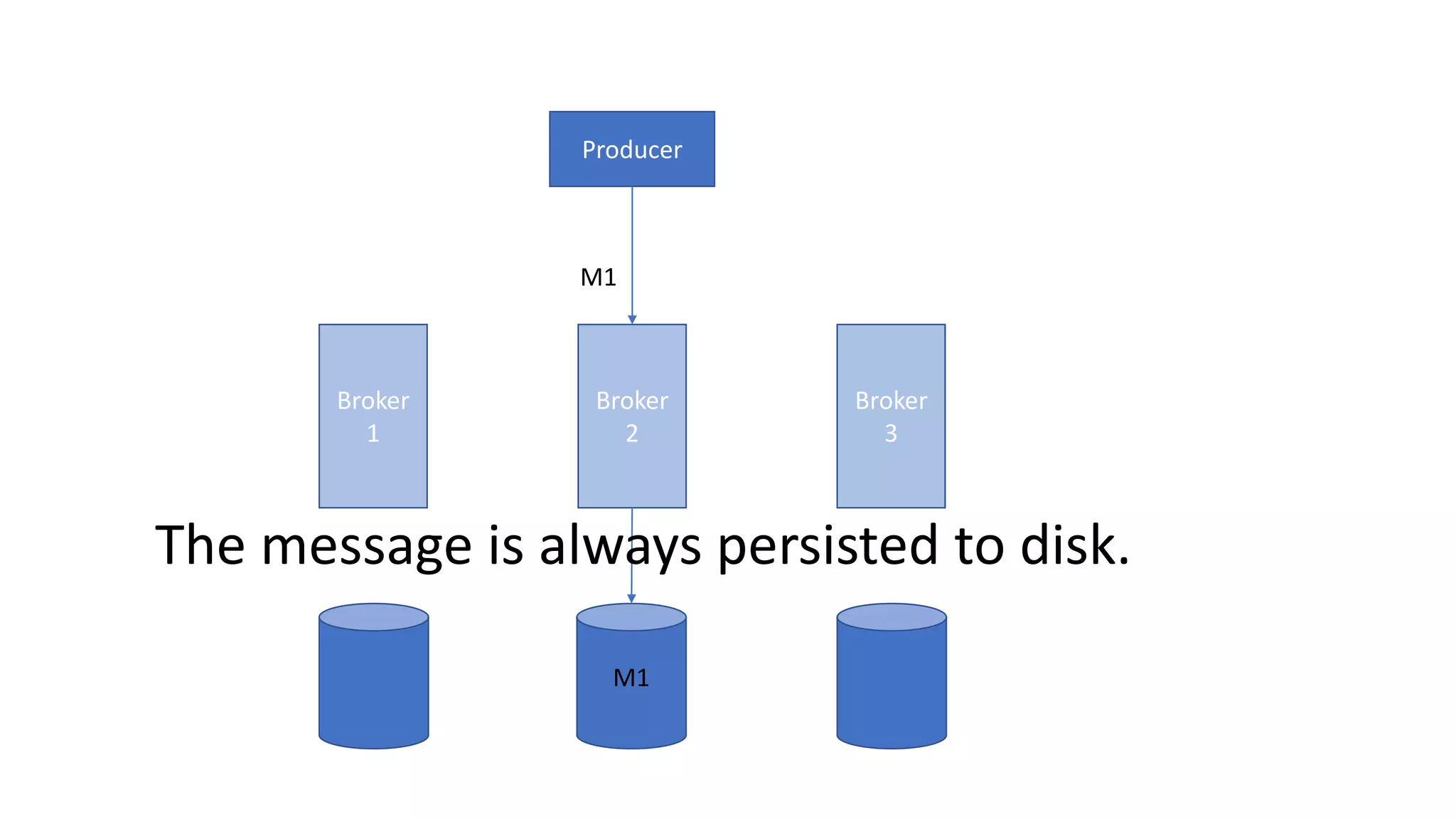
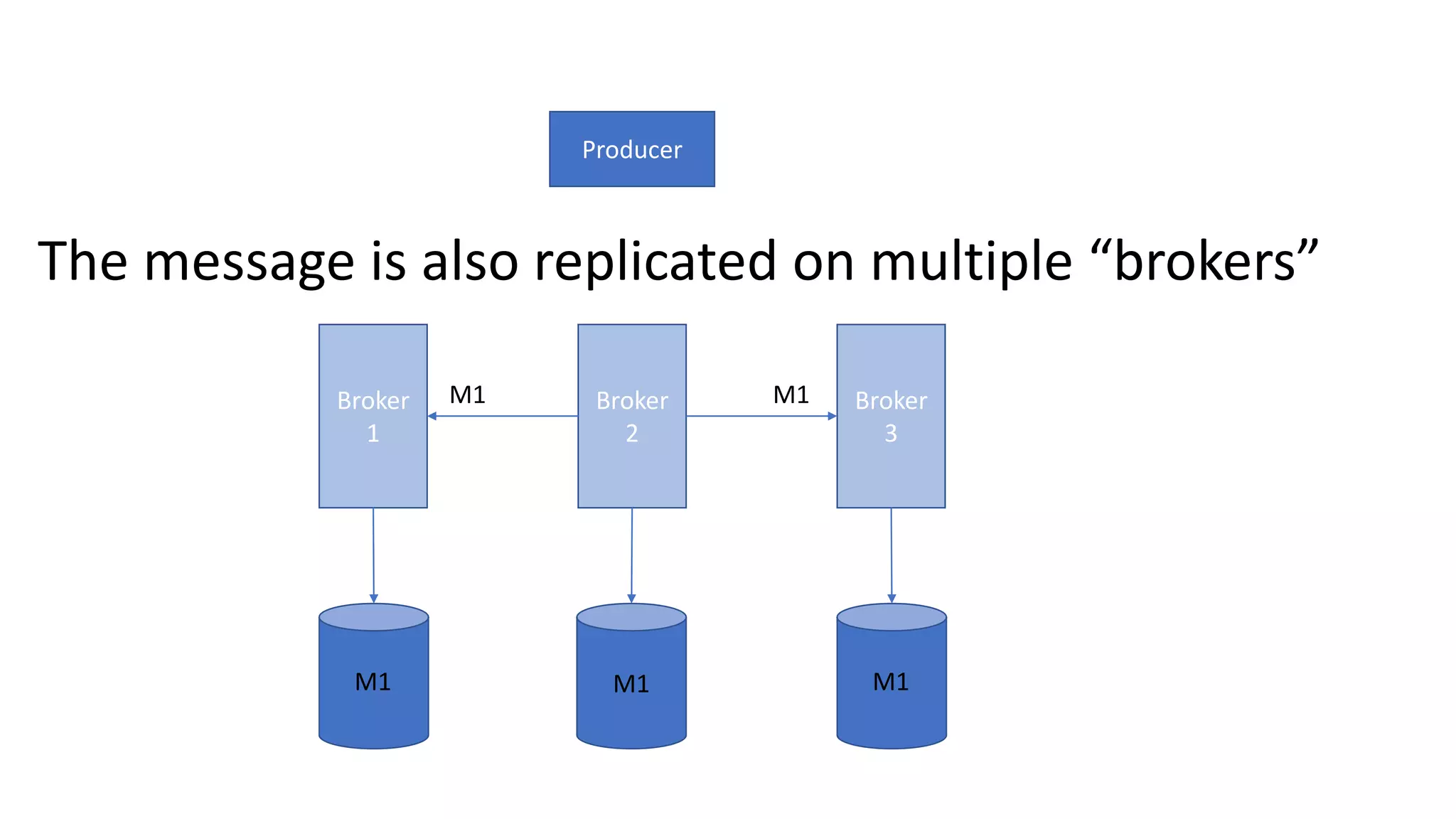
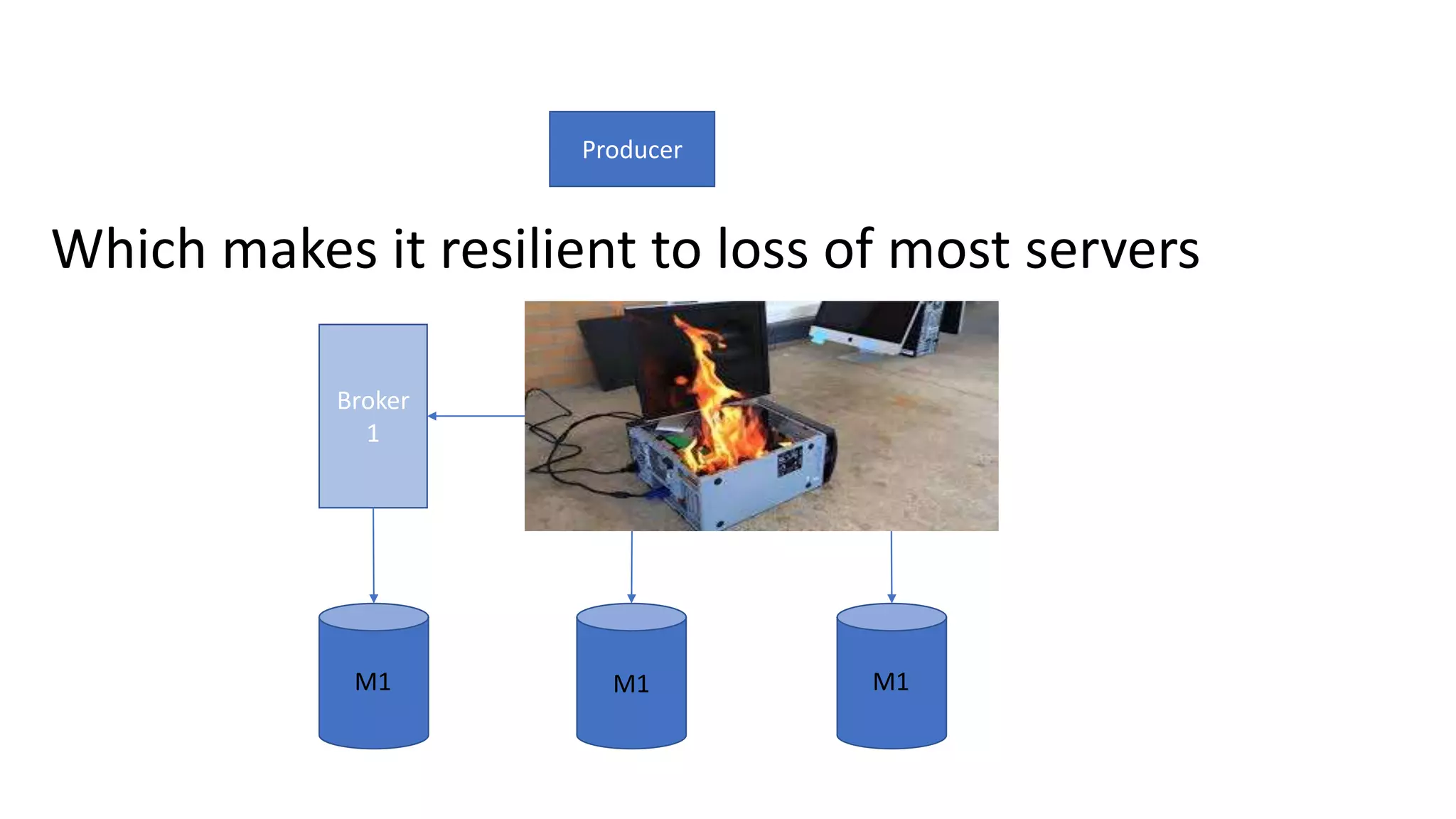
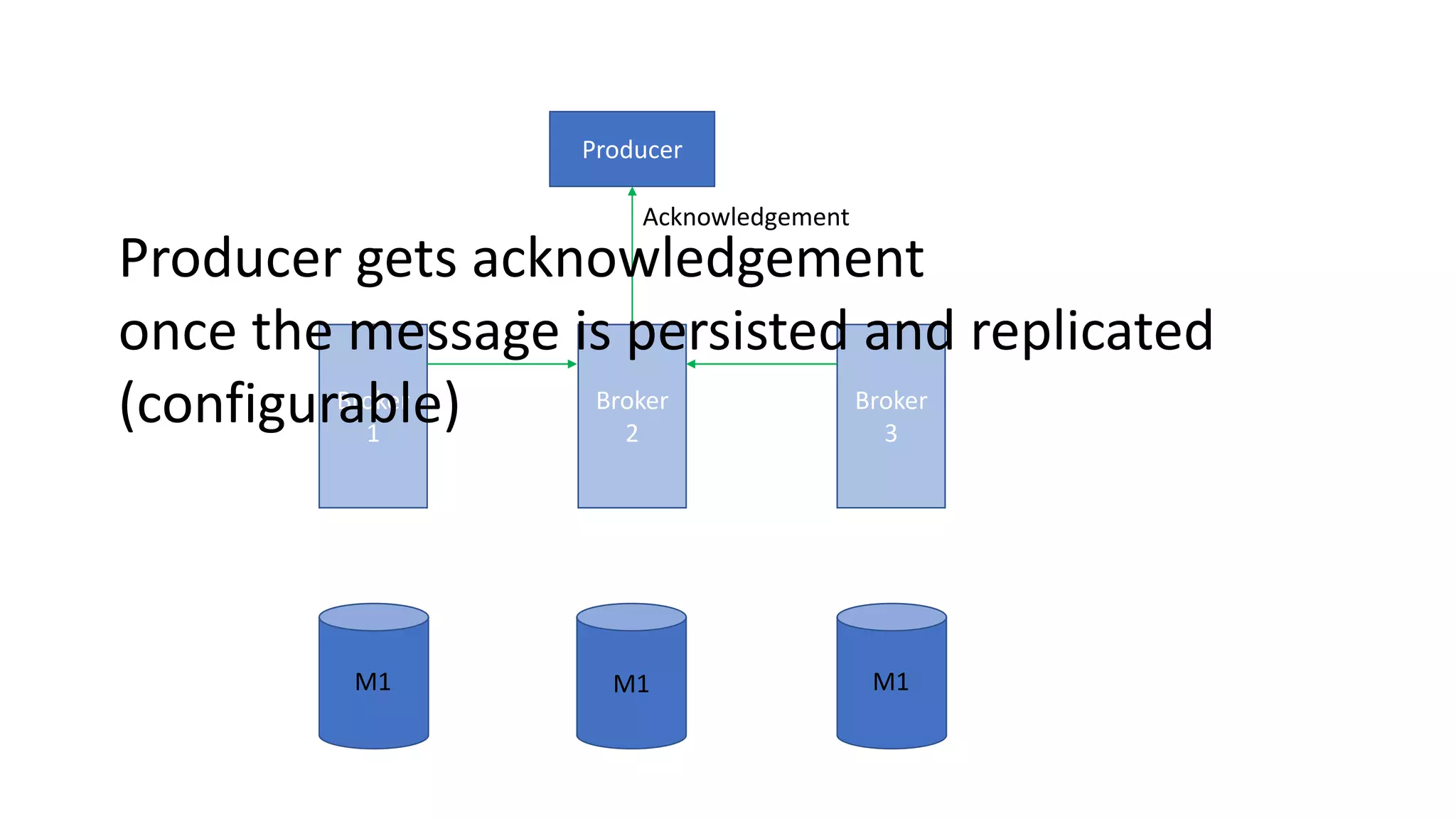
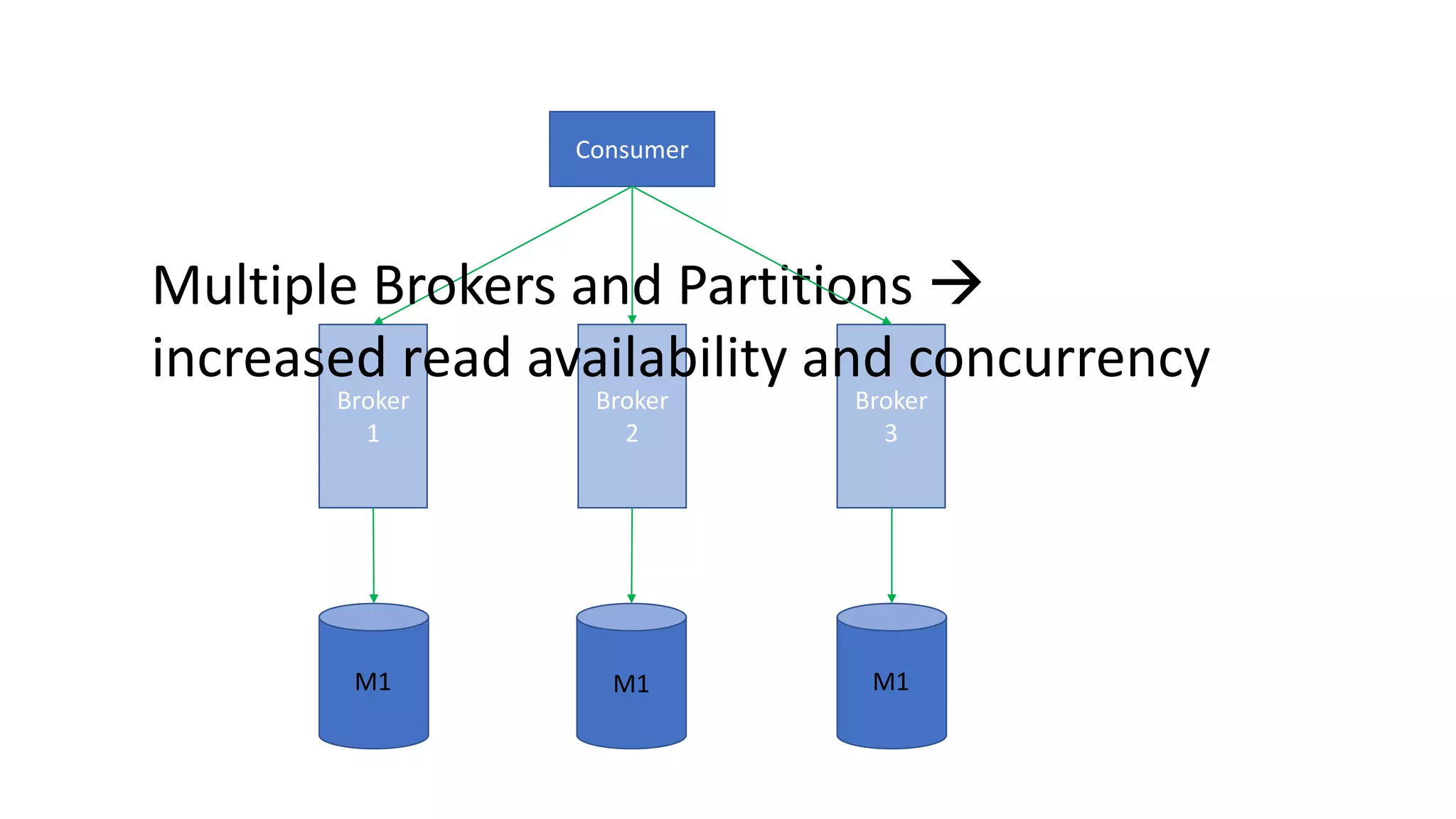
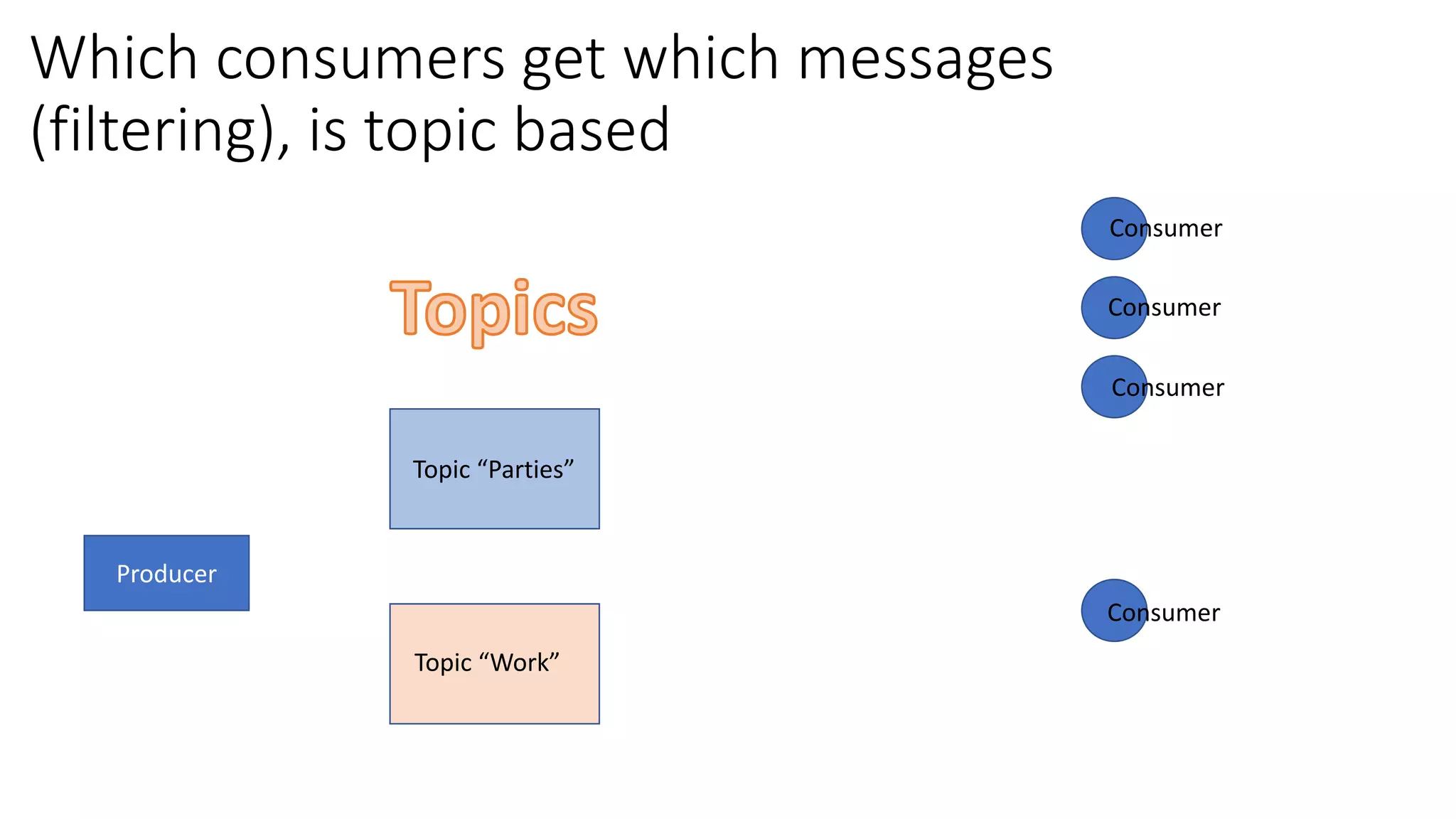
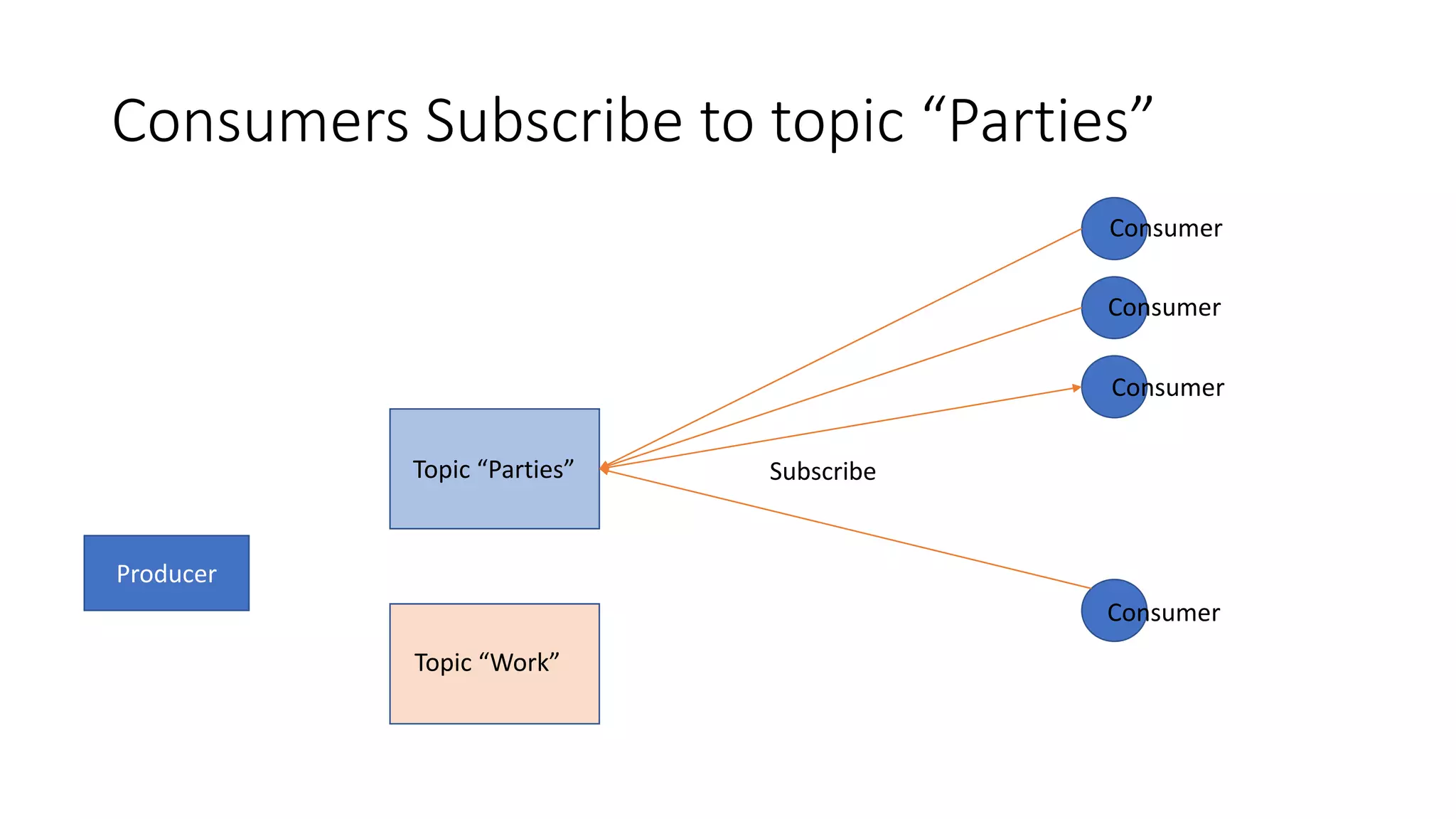
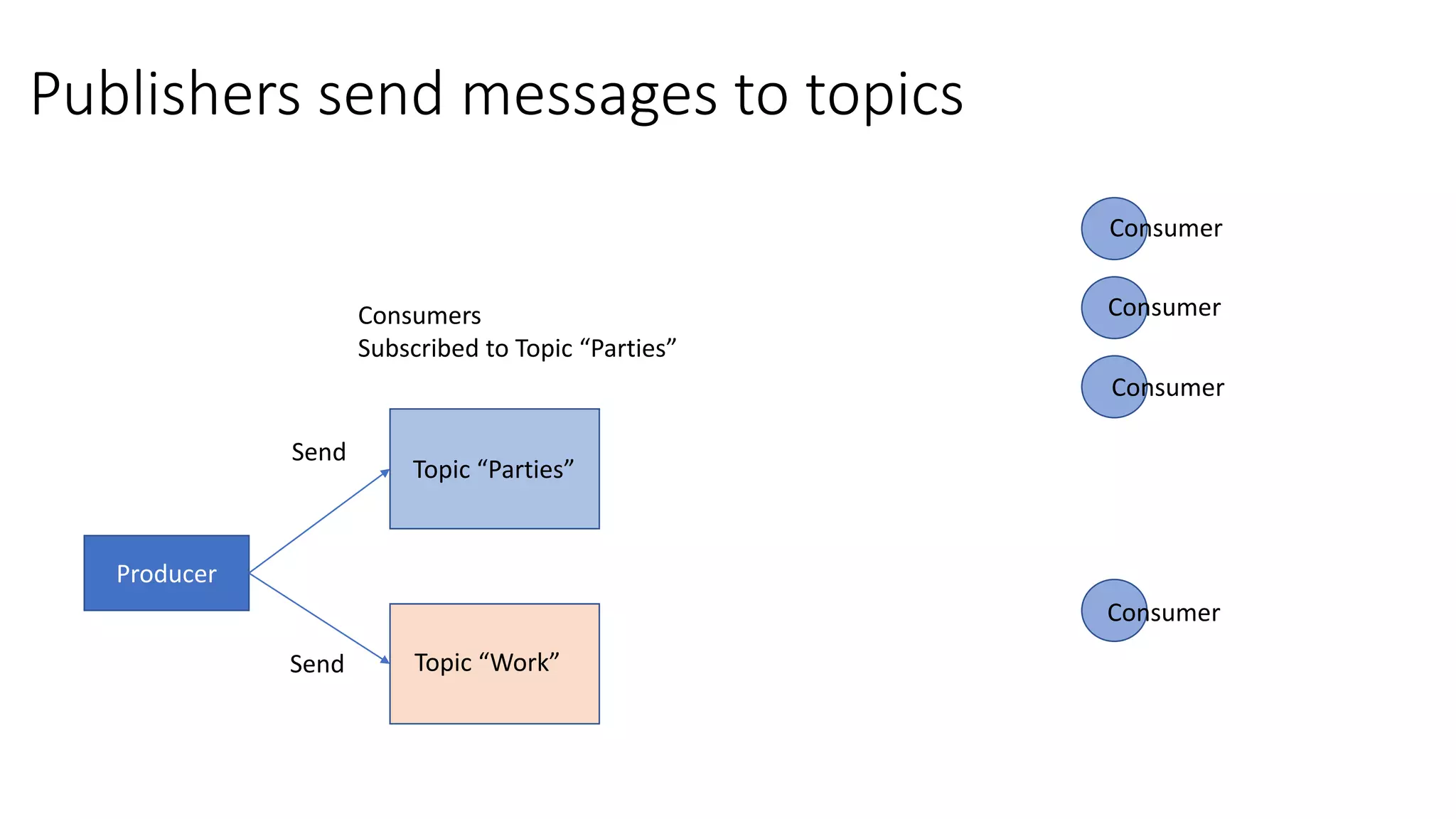
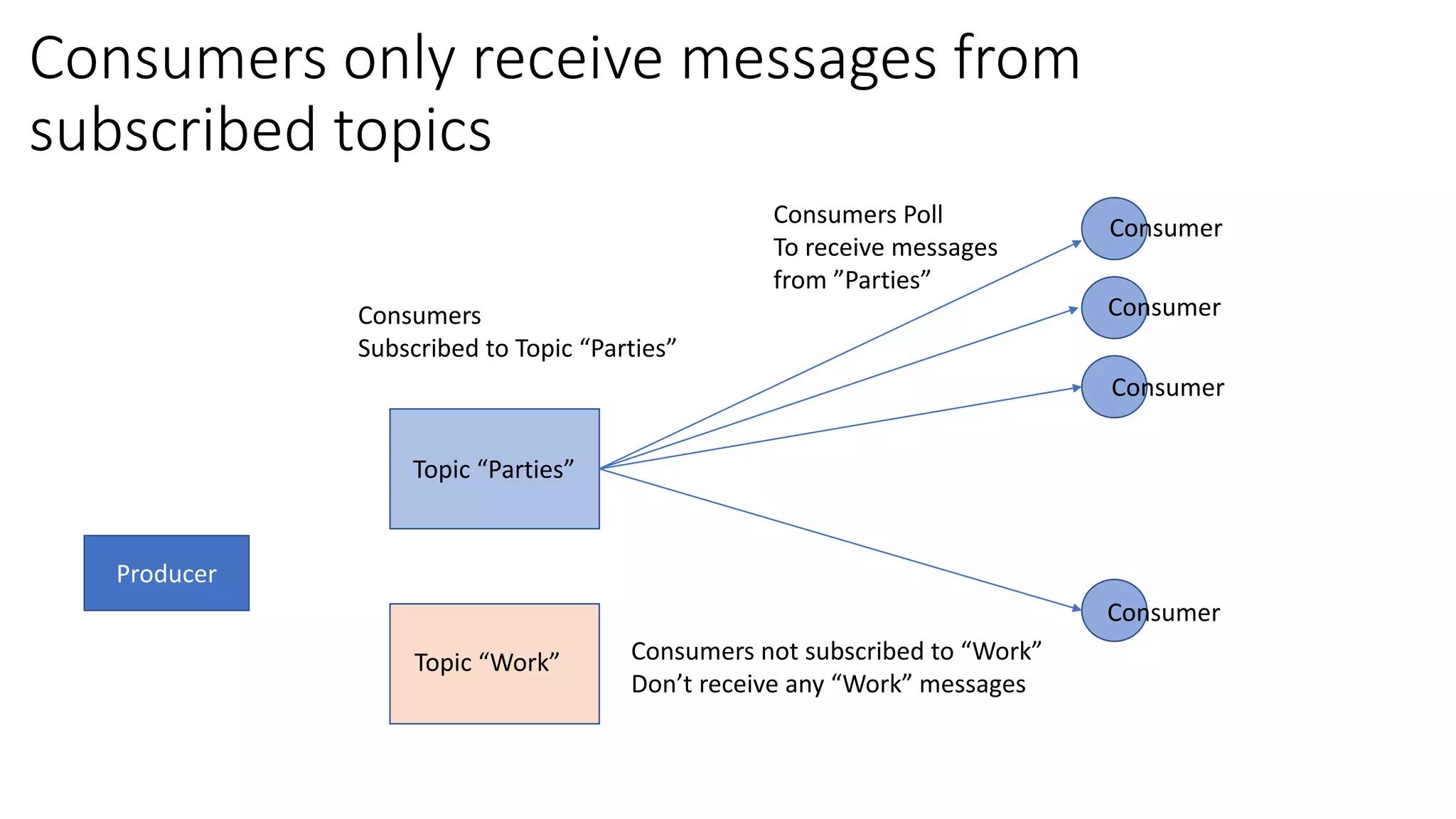
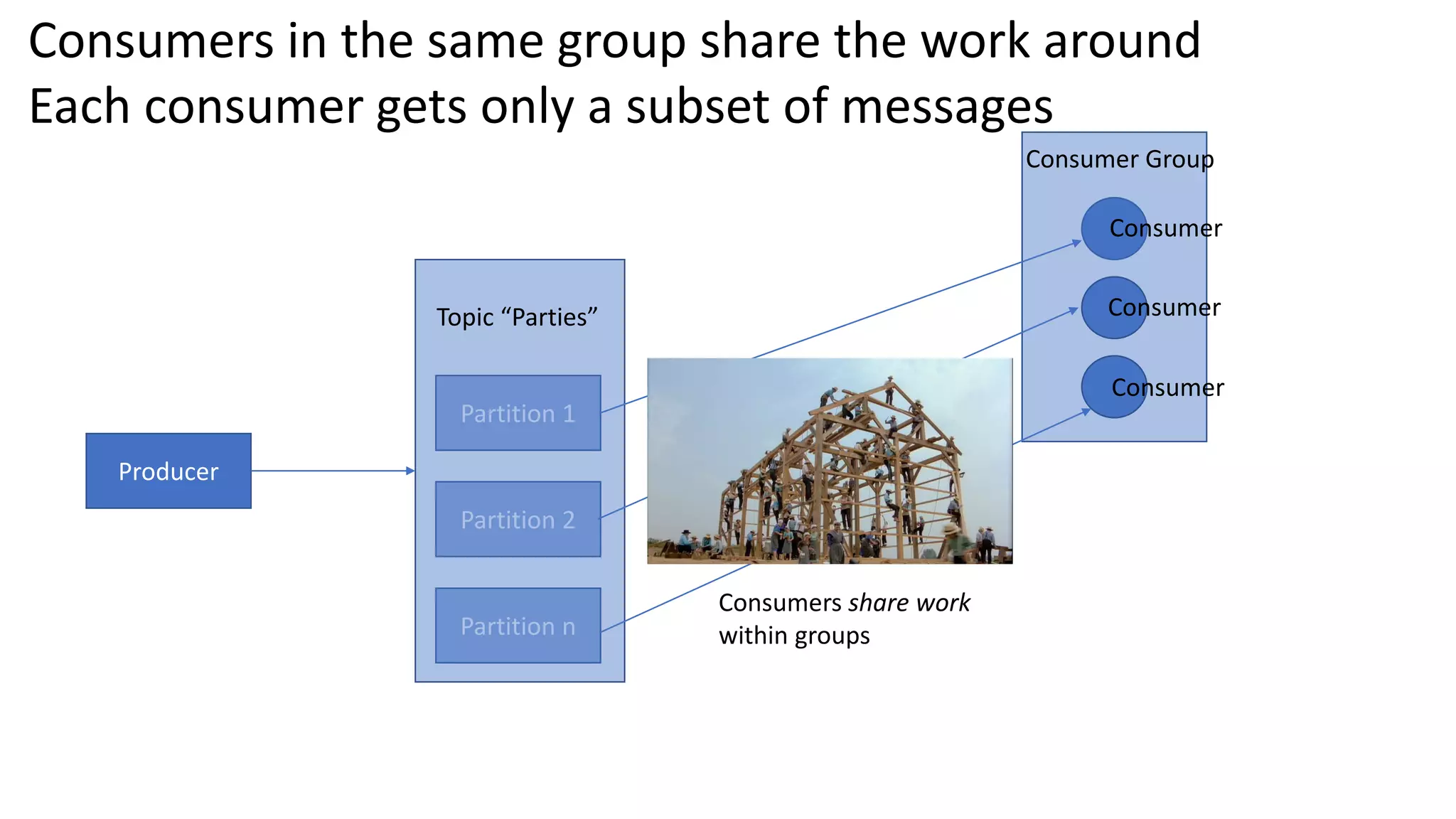
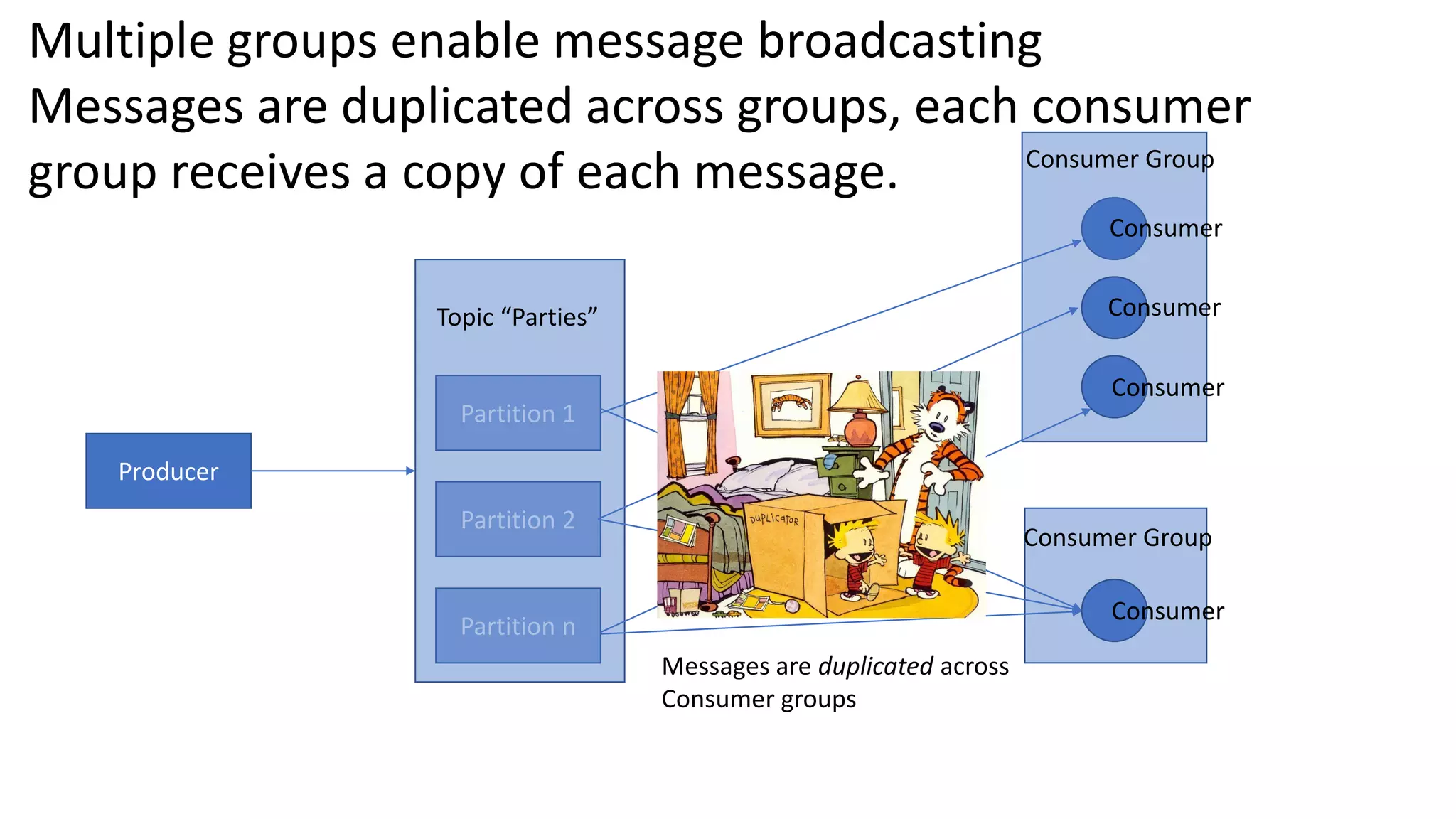
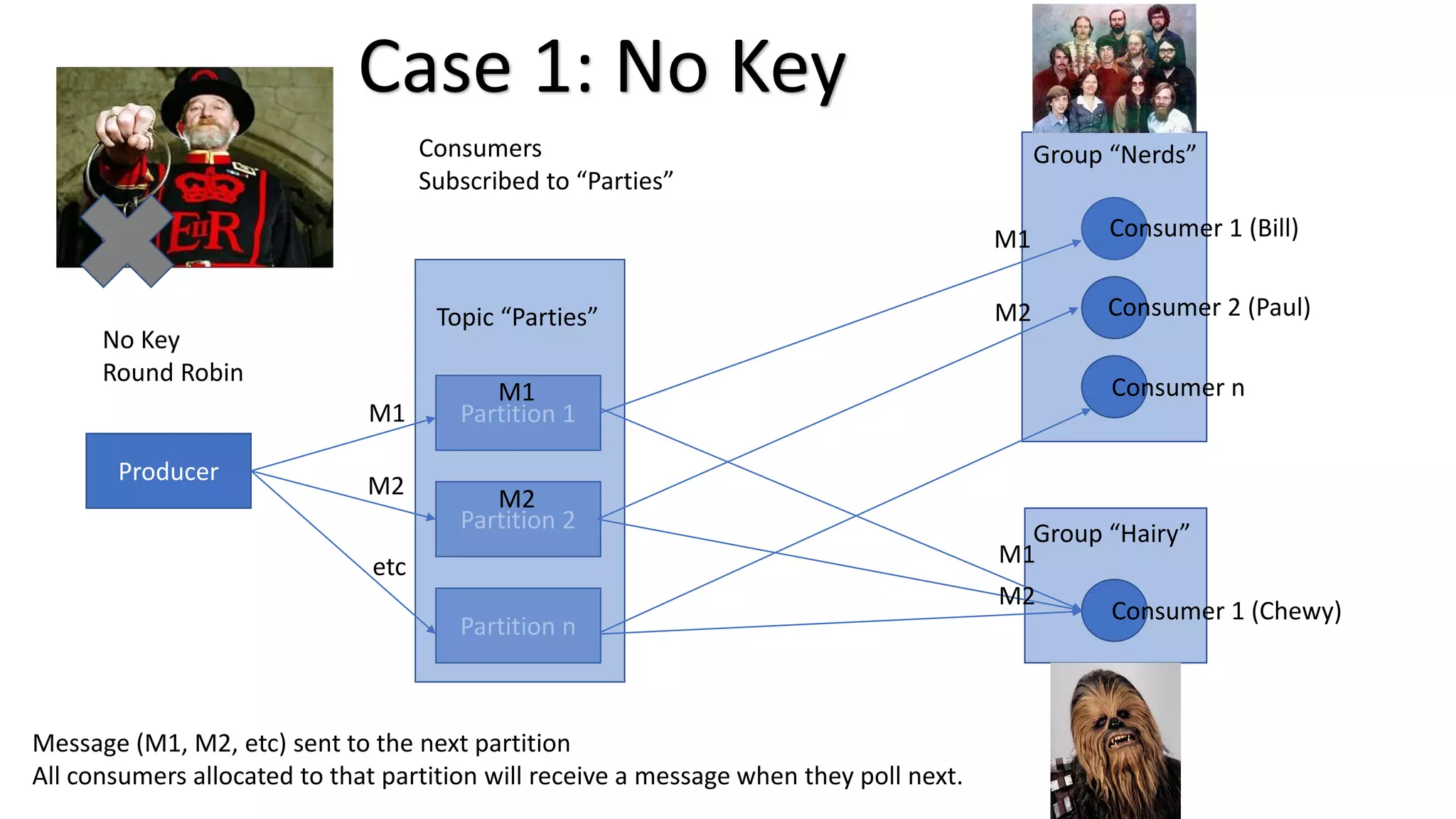
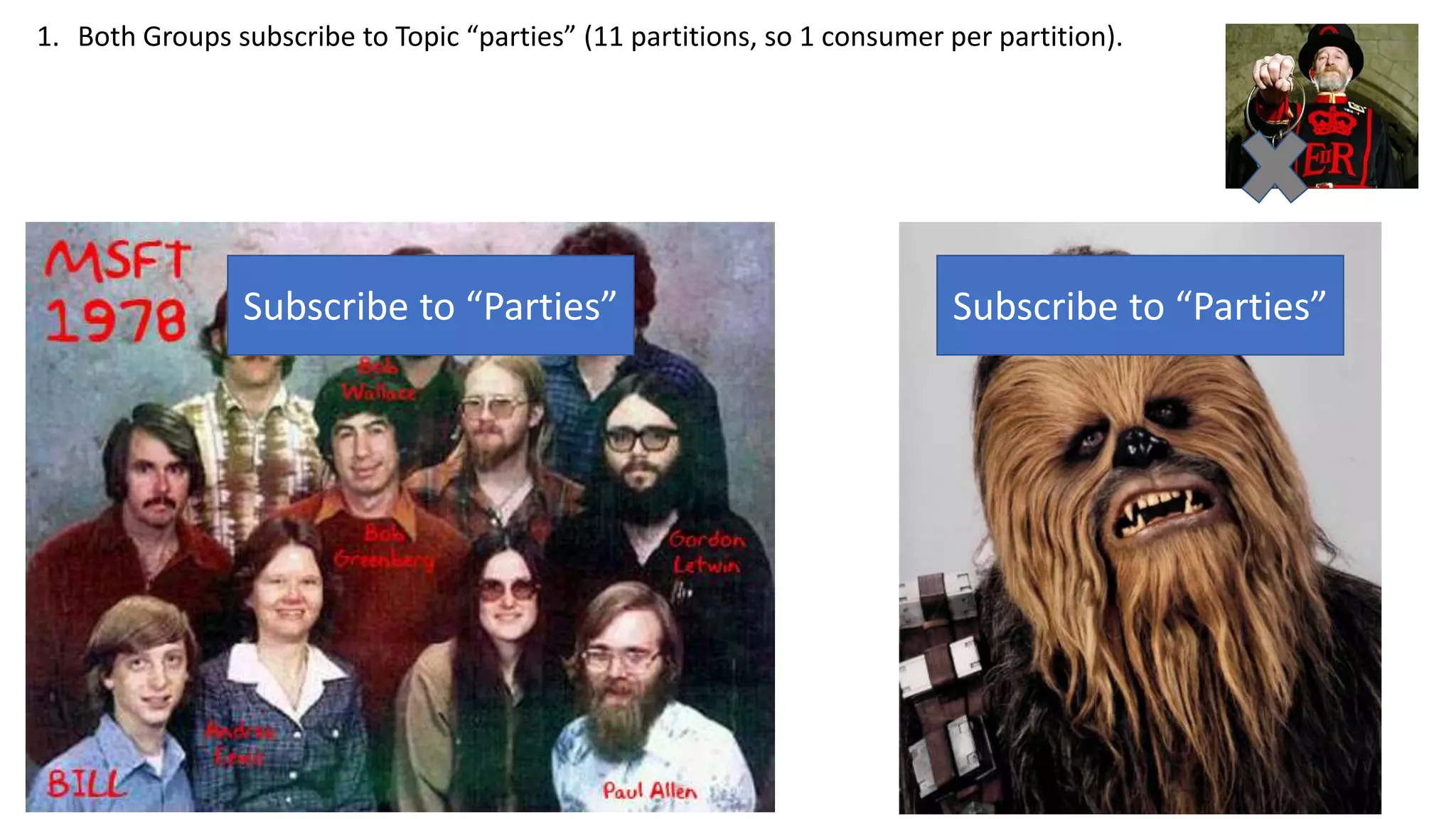
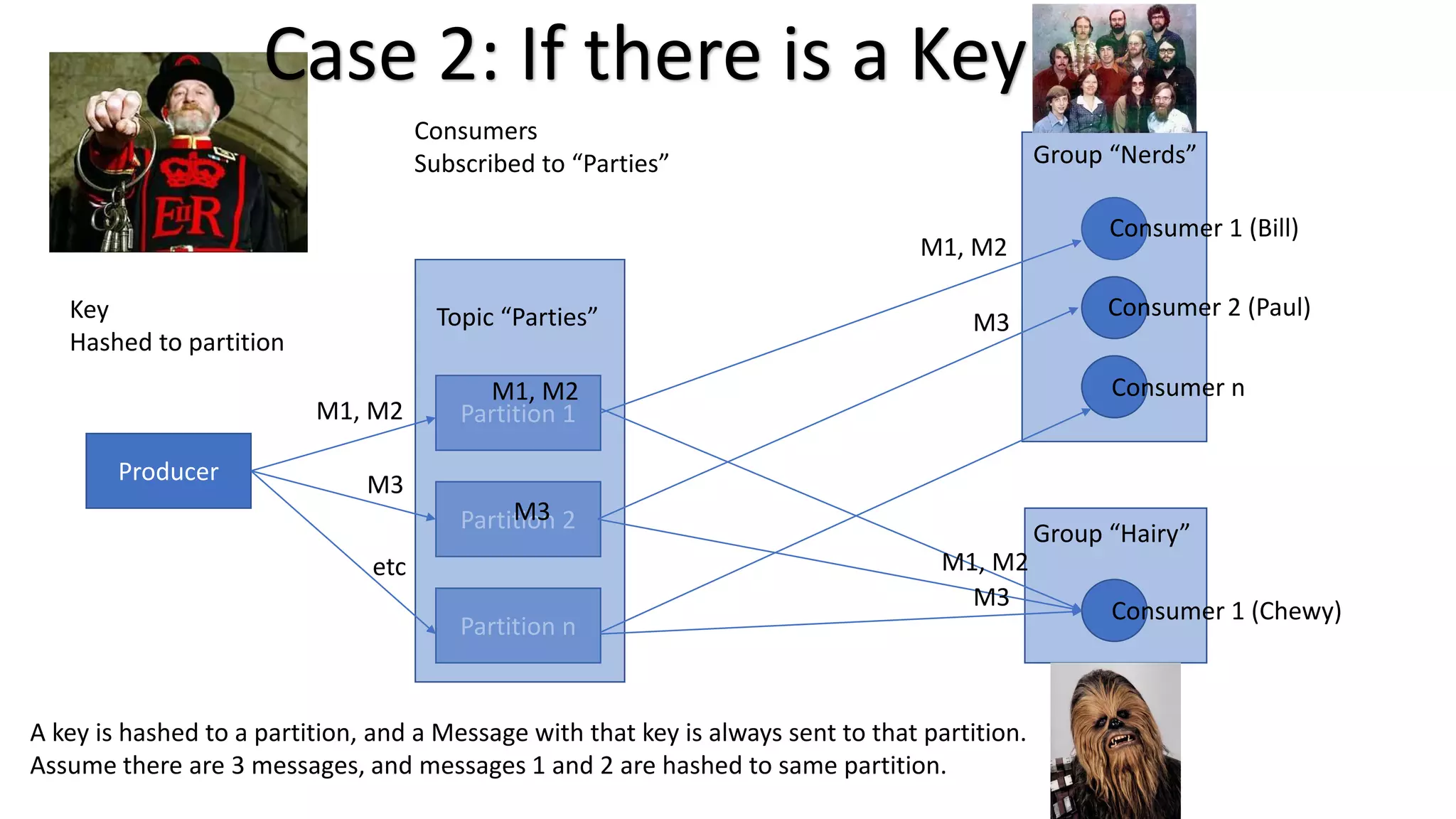
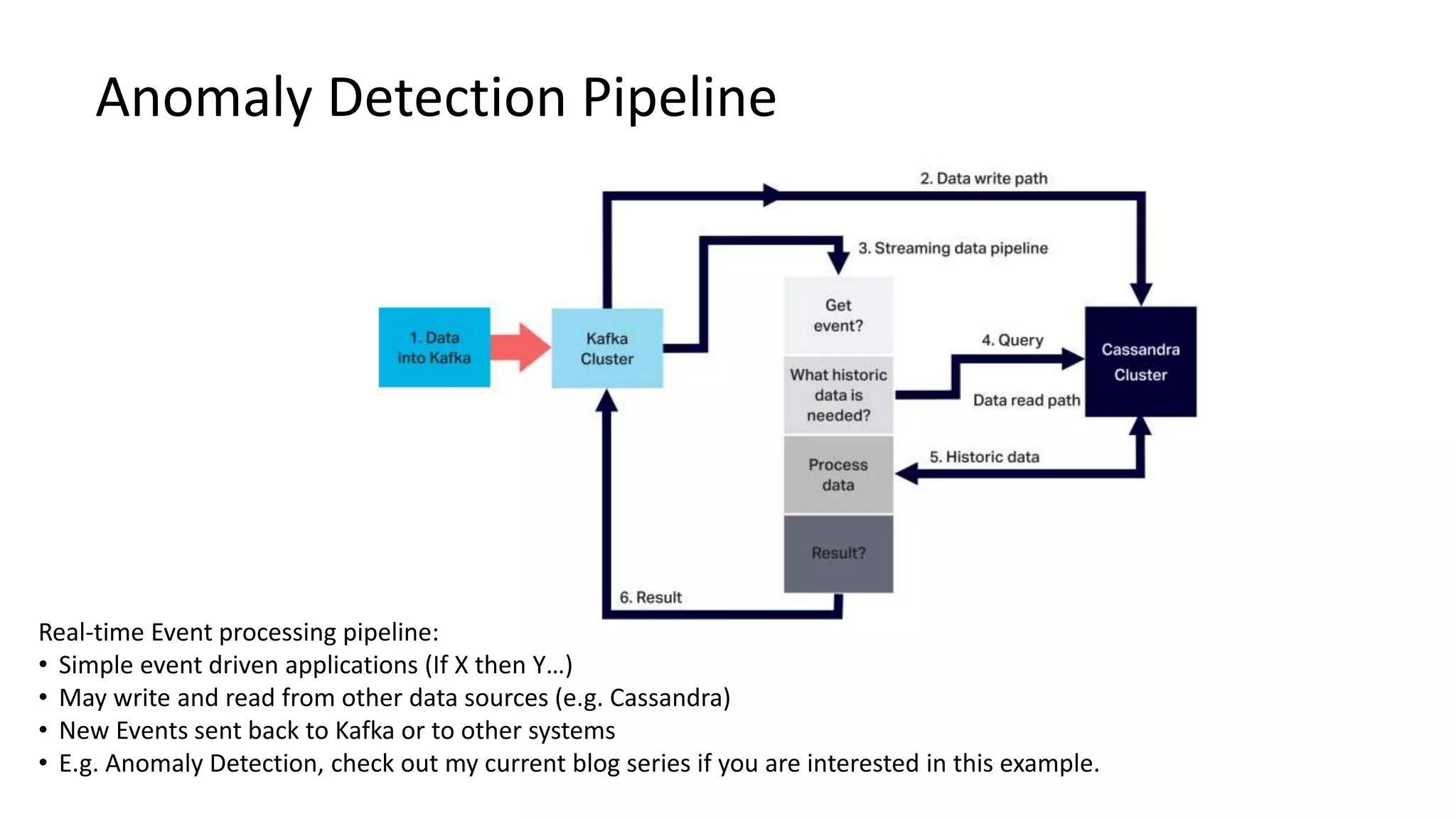
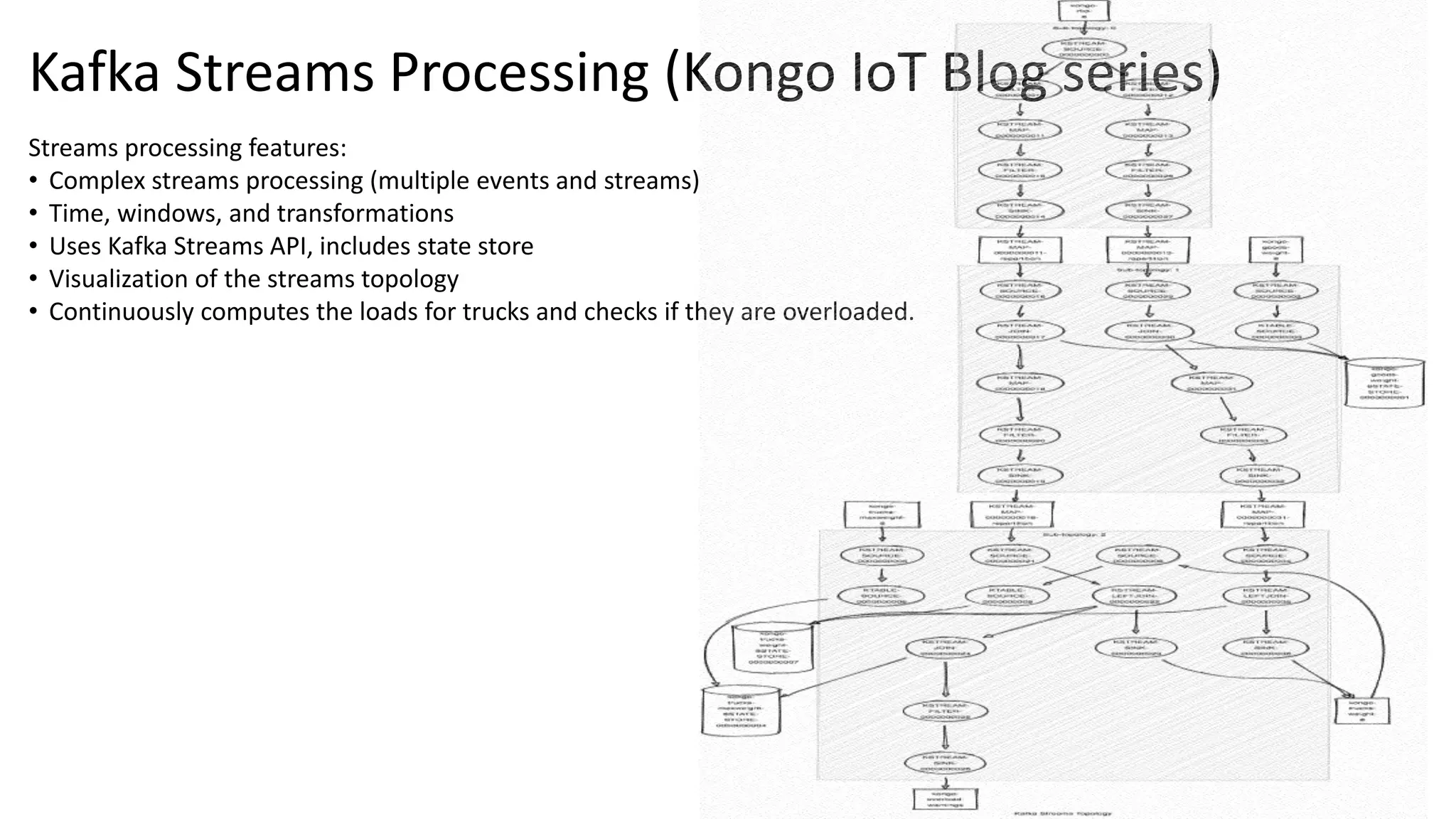
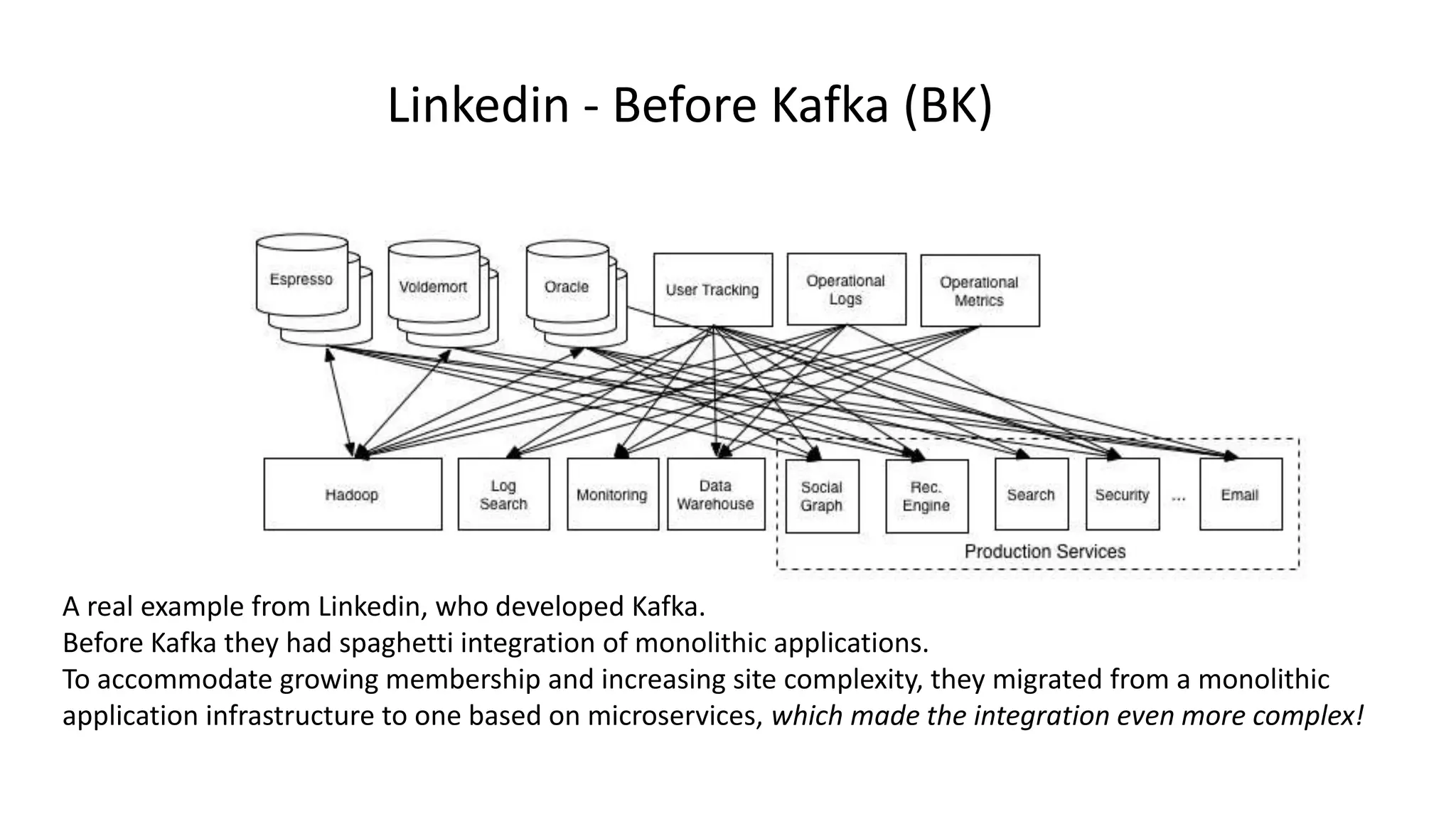
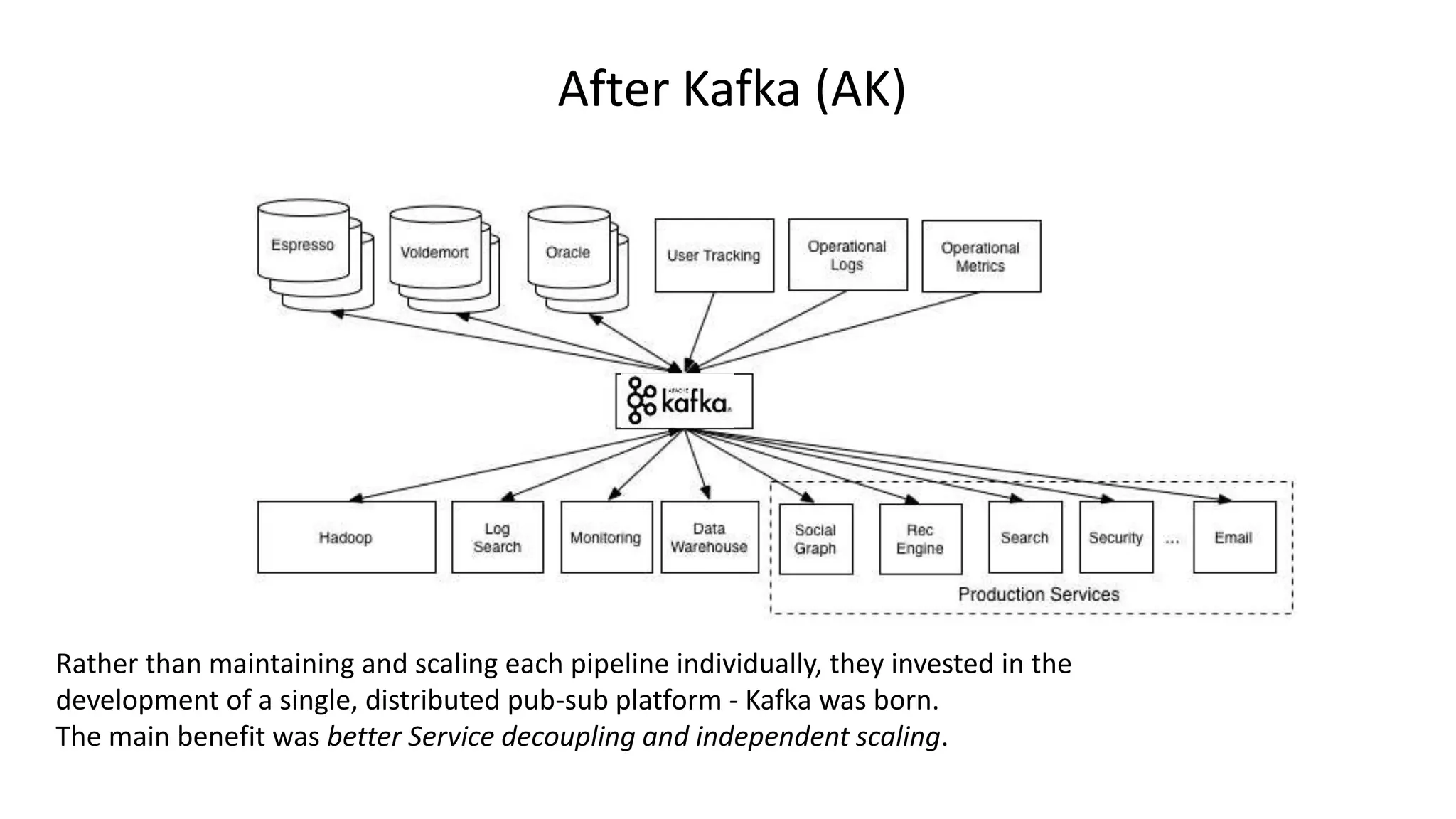
The document introduces Apache Kafka, a distributed streaming platform that facilitates high-throughput, fault-tolerant message delivery between producers and consumers. It highlights Kafka's features, including scalability, durability, and reliability, while explaining how messages are organized in topics and partitions. Additionally, it outlines Kafka's delivery semantics and use cases, demonstrating its utility in real-time data processing and integration within complex application architectures.