Download as PDF, PPTX





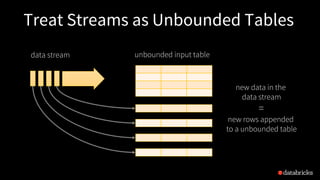


![Anatomy of a Streaming Query
spark.readStream.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()
Kafka DataFrame
key value topic partition offset timestamp
[binary] [binary] "topic" 0 345 1486087873
[binary] [binary] "topic" 3 2890 1486086721](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-8-320.jpg)



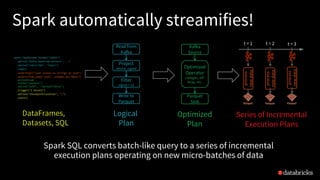

























![MapGroupsWithState - How to use?
2. Define function to update
state of each grouping
key using the new data
Input
Grouping key: userId
New data: new user actions
Previous state: previous status
of this user
case class UserAction(
userId: String, action: String)
case class UserStatus(
userId: String, active: Boolean)
def updateState(
userId: String,
actions: Iterator[UserAction],
state: GroupState[UserStatus]):UserStatus = {
}](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-48-320.jpg)
![MapGroupsWithState - How to use?
2. Define function to update
state of each grouping key
using the new data
Body
Get previous user status
Update user status with actions
Update state with latest user status
Return the status
def updateState(
userId: String,
actions: Iterator[UserAction],
state: GroupState[UserStatus]):UserStatus = {
}
val prevStatus = state.getOption.getOrElse {
new UserStatus()
}
actions.foreah { action =>
prevStatus.updateWith(action)
}
state.update(prevStatus)
return prevStatus](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-49-320.jpg)
![MapGroupsWithState - How to use?
3. Use the user-defined function
on a grouped Dataset
Works with both batch and
streaming queries
In batch query, the function is called
only once per group with no prior state
def updateState(
userId: String,
actions: Iterator[UserAction],
state: GroupState[UserStatus]):UserStatus = {
}
// process actions, update and return status
userActions
.groupByKey(_.userId)
.mapGroupsWithState(updateState)](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-50-320.jpg)




![FlatMapGroupsWithState
More general version where the
function can return any number
of events, possibly none at all
Example: instead of returning
user status, want to return
specific actions that are
significant based on the history
def updateState(
userId: String,
actions: Iterator[UserAction],
state: GroupState[UserStatus]):
Iterator[SpecialUserAction] = {
}
userActions
.groupByKey(_.userId)
.flatMapGroupsWithState
(outputMode, timeoutConf)
(updateState)](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-55-320.jpg)
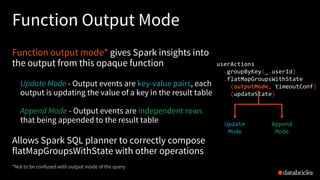


![Monitoring the state of Query State
Get current state metrics using the
last progress of the query
Total number of rows in state
Total memory consumed (approx.)
Get it asynchronously through
StreamingQueryListener API
val progress = query.lastProgress
print(progress.json)
{
...
"stateOperators" : [ {
"numRowsTotal" : 660000,
"memoryUsedBytes" : 120571087
...
} ],
}
new StreamingQueryListener {
...
def onQueryProgress(
event: QueryProgressEvent)
}](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-59-320.jpg)

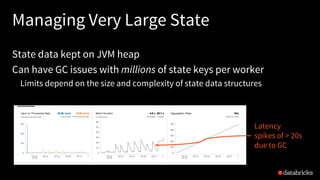
![Managing Very Large Statewith RocksDB
In Databricks Runtime, you can store state locally in RocksDB
Avoids JVM heap, no GC issues with 100 millions state keys per worker
Local RocksDB snapshot files automatically checkpointed to HDFS
Same exactly-once fault-tolerant guarantees
Latency
capped
at 10s
[More info in Databricks Docs]](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-63-320.jpg)





The document details stateful stream processing in Apache Spark's Structured Streaming, highlighting its fast, scalable, and fault-tolerant capabilities with high-level APIs. It covers the anatomy of streaming queries, including sources, transformations, and sinks, while emphasizing the importance of state management, watermarking, and fault recovery mechanisms. Additionally, it discusses various operations such as streaming aggregation, deduplication, and user-defined stateful processing using APIs like mapGroupsWithState.
















![[pgday.Seoul 2022] PostgreSQL with Google Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-postgresqlwithgooglecloud-221114013605-5def484f-thumbnail.jpg?width=640&height=640&fit=bounds)






































































