Downloaded 10 times









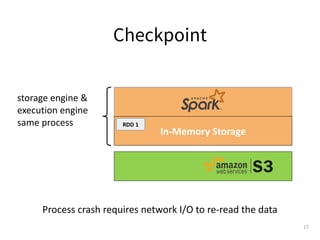
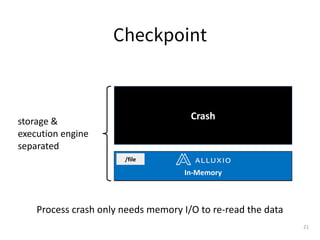






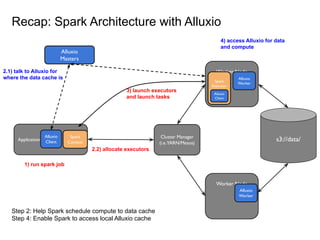
![Step 1: Schedule compute to data cache location
Cluster Manager
(i.e.YARN/Mesos)
Application
Spark
Context
Alluxio
Client
Alluxio
Masters
HostA: 196.0.0.7
Alluxio
Worker
HostB: 196.0.0.8
Alluxio
Worker
(3) allocate on [HostA]
block1
block2
(1) where is
block1?
(2) block1 is
served at
[HostA]
● Alluxio client implements HDFS compatible API with
block location info
● Alluxio masters keep track and serve a list of worker
nodes that currently have the cache.](https://image.slidesharecdn.com/2021-10-12runningsparkonalluxioforfastdataanalytics-211012170038/85/Best-Practice-in-Accelerating-Data-Applications-with-Spark-Alluxio-31-320.jpg)
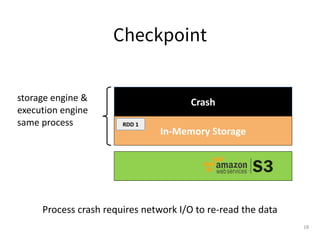
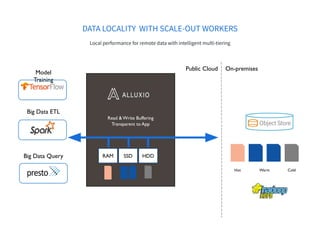
![Step 4: Find local Alluxio Worker and Efficient Data
Exchange
s3://data/
Spark Executor
Alluxio
Worker
Alluxio
Client
HostB: 196.0.0.8
Alluxio
Worker
HostA: 196.0.0.7
block1
Alluxio
Masters
block1?
[HostA]
Efficient I/O via local fs
(e.g., /mnt/ramdisk/) or
local domain socket
(/opt/domain)
● Spark Executor finds local Alluxio Worker by
hostname comparison
● Spark Executor talks to local Alluxio Worker
using either short-circuit access (via local
FS) or local domain socket](https://image.slidesharecdn.com/2021-10-12runningsparkonalluxioforfastdataanalytics-211012170038/85/Best-Practice-in-Accelerating-Data-Applications-with-Spark-Alluxio-32-320.jpg)









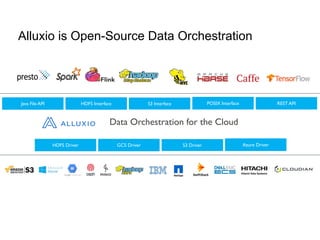
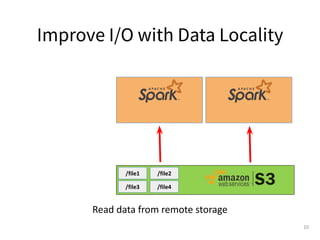
This document provides an overview of integrating Alluxio with Apache Spark for enhanced data analytics, focusing on improved input/output performance through better data locality and enabling data sharing between Spark jobs. It discusses the history of Alluxio as a data orchestration tool, its setup with Spark, and various use cases demonstrating its benefits, including faster data access and reduced computing costs. The document also outlines examples of coding practices for using Alluxio with Spark and mentions a growing community and potential career opportunities.























































































