Download as PDF, PPTX









![Dataset/DataFrame
SQL
spark.sql("
SELECT type, sum(signal)
FROM devices
GROUP BY type
")
Most familiar to BI Analysts
Supports SQL-2003, HiveQL
val df: DataFrame =
spark.table("device-data")
.groupBy("type")
.sum("signal"))
Great for Data Scientists familiar
with Pandas, R Dataframes
DataFrames Dataset
val ds: Dataset[(String, Double)] =
spark.table("device-data")
.as[DeviceData]
.groupByKey(_.type)
.mapValues(_.signal)
.reduceGroups(_ + _)
Great for Data Engineers who
want compile-time type safety
You choose your hammer for whatever nail you have!](https://image.slidesharecdn.com/885dasdaseasyscalablefault-tolerantstreamprocessingwithstructuredstreaminginapachespark-170626213434/85/Easy-Scalable-Fault-tolerant-stream-processing-with-Structured-Streaming-in-Apache-Spark-17-320.jpg)




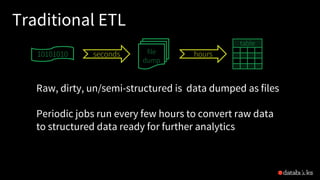
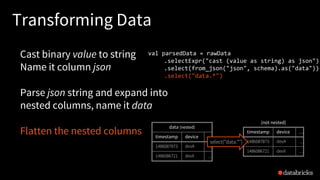
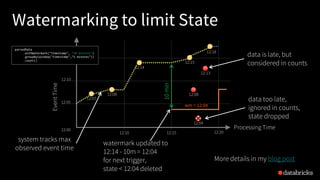
![Traditional ETL
Hours of delay before taking decisions on latest data
Unacceptable when time is of essence
[intrusion detection, anomaly detection, etc.]
file
dump
seconds hours
table
10101010](https://image.slidesharecdn.com/885dasdaseasyscalablefault-tolerantstreamprocessingwithstructuredstreaminginapachespark-170626213434/85/Easy-Scalable-Fault-tolerant-stream-processing-with-Structured-Streaming-in-Apache-Spark-24-320.jpg)
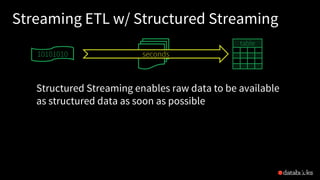

![Reading from Kafka
Specify options to configure
How?
kafka.boostrap.servers => broker1,broker2
What?
subscribe => topic1,topic2,topic3 // fixed list of topics
subscribePattern => topic* // dynamic list of topics
assign => {"topicA":[0,1] } // specific partitions
Where?
startingOffsets => latest(default) / earliest / {"topicA":{"0":23,"1":345} }
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()](https://image.slidesharecdn.com/885dasdaseasyscalablefault-tolerantstreamprocessingwithstructuredstreaminginapachespark-170626213434/85/Easy-Scalable-Fault-tolerant-stream-processing-with-Structured-Streaming-in-Apache-Spark-27-320.jpg)
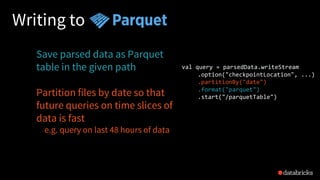
![Reading from Kafka
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()
rawData dataframe has
the following columns
key value topic partition offset timestamp
[binary] [binary] "topicA" 0 345 1486087873
[binary] [binary] "topicB" 3 2890 1486086721](https://image.slidesharecdn.com/885dasdaseasyscalablefault-tolerantstreamprocessingwithstructuredstreaminginapachespark-170626213434/85/Easy-Scalable-Fault-tolerant-stream-processing-with-Structured-Streaming-in-Apache-Spark-28-320.jpg)

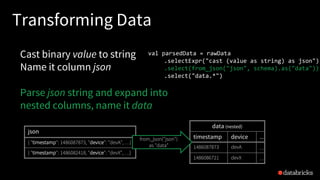



![More Kafka Support [Spark 2.2]
Write out to Kafka
Dataframe must have binary fields
named key and value
Direct, interactive and batch
queries on Kafka
Makes Kafka even more powerful
as a storage platform!
result.writeStream
.format("kafka")
.option("topic", "output")
.start()
val df = spark
.read // not readStream
.format("kafka")
.option("subscribe", "topic")
.load()
df.registerTempTable("topicData")
spark.sql("select value from topicData")](https://image.slidesharecdn.com/885dasdaseasyscalablefault-tolerantstreamprocessingwithstructuredstreaminginapachespark-170626213434/85/Easy-Scalable-Fault-tolerant-stream-processing-with-Structured-Streaming-in-Apache-Spark-37-320.jpg)
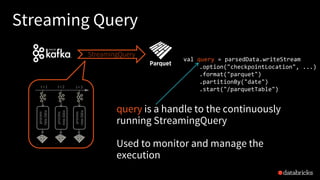
![Amazon Kinesis [Databricks Runtime 3.0]
Configure with options (similar to Kafka)
How?
region => us-west-2 / us-east-1 / ...
awsAccessKey (optional) => AKIA...
awsSecretKey (optional) => ...
What?
streamName => name-of-the-stream
Where?
initialPosition => latest(default) / earliest / trim_horizon
spark.readStream
.format("kinesis")
.option("streamName", "myStream")
.option("region", "us-west-2")
.option("awsAccessKey", ...)
.option("awsSecretKey", ...)
.load()](https://image.slidesharecdn.com/885dasdaseasyscalablefault-tolerantstreamprocessingwithstructuredstreaminginapachespark-170626213434/85/Easy-Scalable-Fault-tolerant-stream-processing-with-Structured-Streaming-in-Apache-Spark-38-320.jpg)







![Arbitrary Stateful Operations [Spark 2.2]
mapGroupsWithState
allows any user-defined
stateful function to a
user-defined state
Direct support for per-key
timeouts in event-time or
processing-time
Supports Scala and Java
48
ds.groupByKey(_.id)
.mapGroupsWithState
(timeoutConf)
(mappingWithStateFunc)
def mappingWithStateFunc(
key: K,
values: Iterator[V],
state: GroupState[S]): U = {
// update or remove state
// set timeouts
// return mapped value
}](https://image.slidesharecdn.com/885dasdaseasyscalablefault-tolerantstreamprocessingwithstructuredstreaminginapachespark-170626213434/85/Easy-Scalable-Fault-tolerant-stream-processing-with-Structured-Streaming-in-Apache-Spark-48-320.jpg)







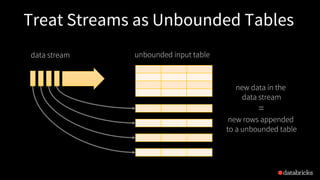
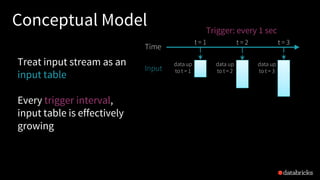
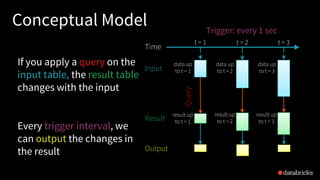
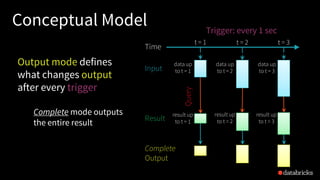
The document discusses the complexities of building robust stream processing applications using Apache Spark's Structured Streaming, which simplifies processing complex data and workloads. It outlines the conceptual model of treating data streams as unbounded tables, provides technical insights into querying data, managing state, checkpointing, and watermarking for fault tolerance, and explains how to perform real-time analytics with structured data. Additionally, it covers various use cases and APIs for connecting to sources like Kafka and Kinesis, enabling efficient processing and querying of event-time data.






















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)