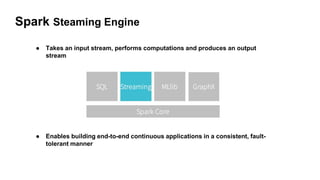
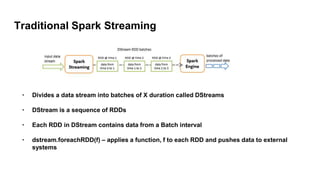
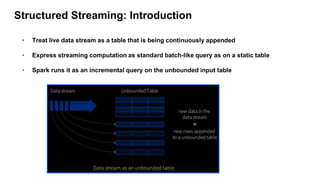
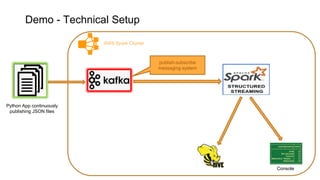
Spark Structured Streaming is Spark's API for building end-to-end streaming applications. It allows expressing streaming computations as standard SQL queries and executes them continuously as new data arrives. Key features include built-in input sources like Kafka, transformations using DataFrames/SQL, output sinks, triggers to control batching, and checkpointing for fault tolerance. The presentation demonstrated a sample Structured Streaming application reading from Kafka and writing to the console using Spark on AWS.









![File Output sinks example
val kafkaDF = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", xx.xx.xx.xx:9092,xx.xx.xx.xxx:9092)
.option("subscribe", “topic_json”)
.load()
.select(get_json_object(($"value").cast("string"), "$.country").alias("Country"))
.groupBy($"Country")
.count()
.writeStream
.format("json")
.option("path", ‘path/to/dir’) [can be S3, Hdfs etc]
12](https://image.slidesharecdn.com/sparkstructuredstreaming-seattledatascienceanddataengineeringmeetup-170921044307/85/Spark-Structured-Streaming-12-320.jpg)






























































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)












