Downloaded 120 times























![Many big data workloads are now
compute bound
● Network optimizations can only reduce job completion time by a median of
at most 2%.
● Optimizing or eliminating disk accesses can only reduce job completion
time by a median of at most 19%
● [1]](https://image.slidesharecdn.com/anatomy-of-inmemory-processing-in-spark-160215173515/75/Anatomy-of-in-memory-processing-in-Spark-29-2048.jpg)




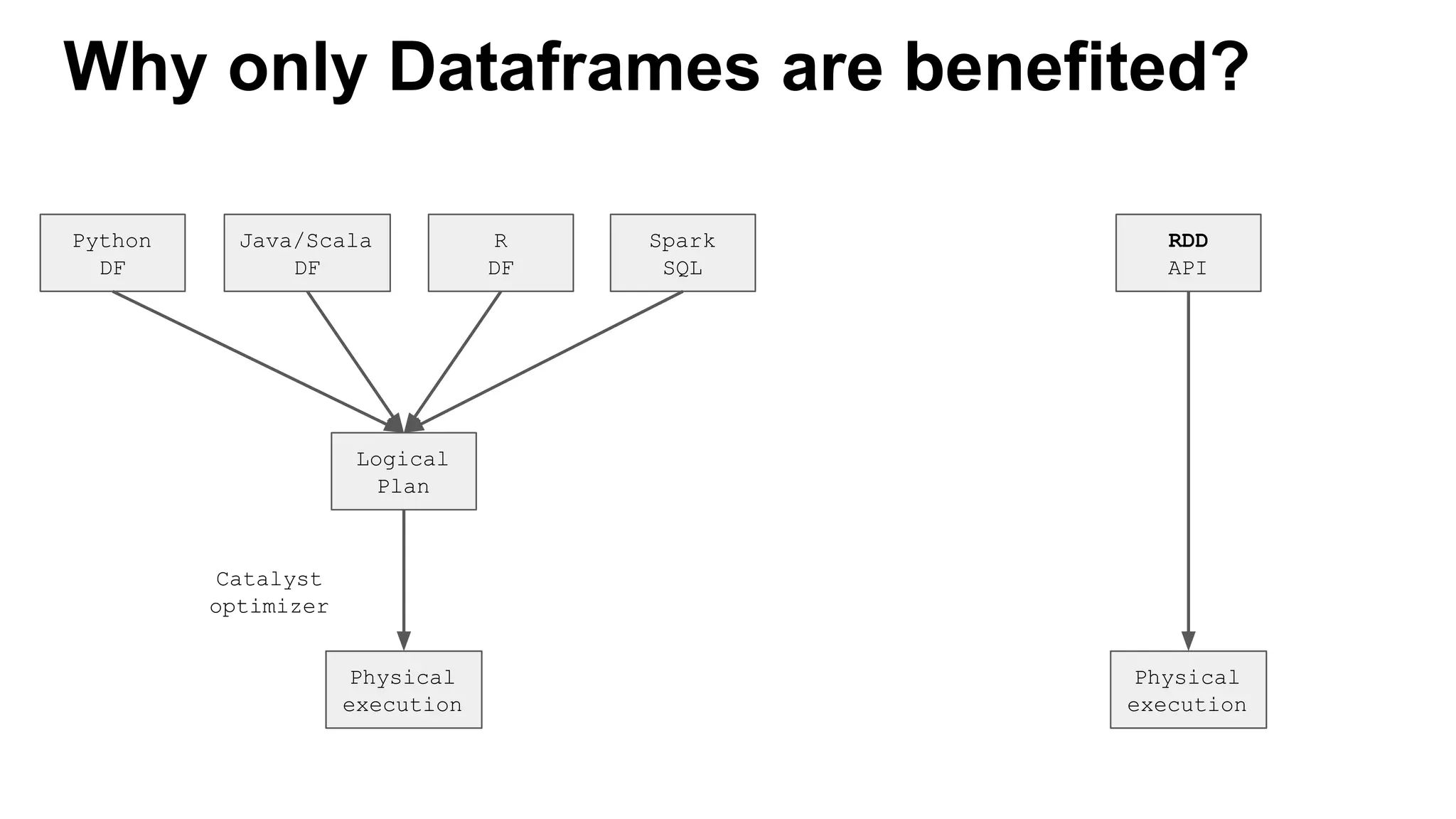

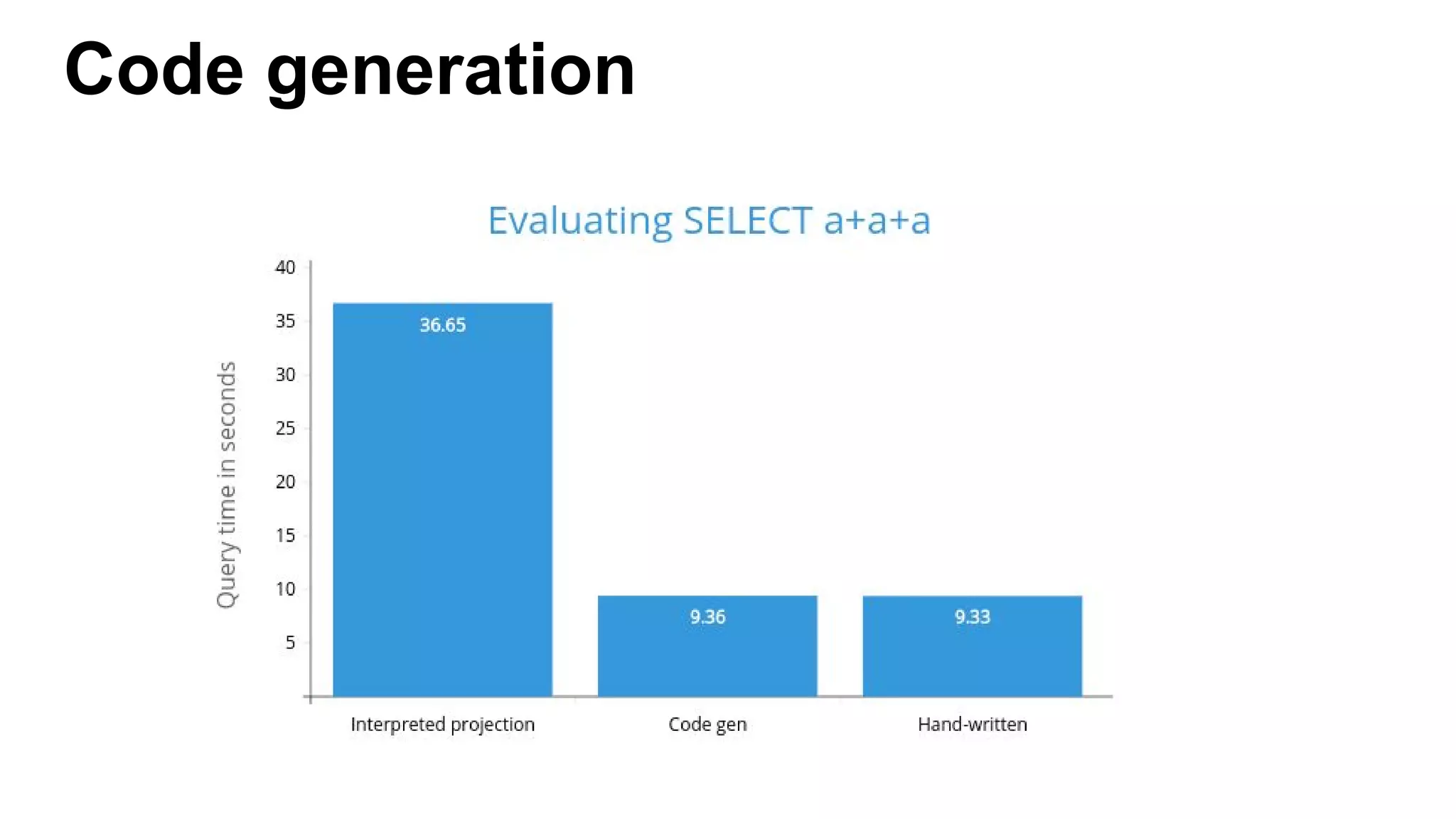

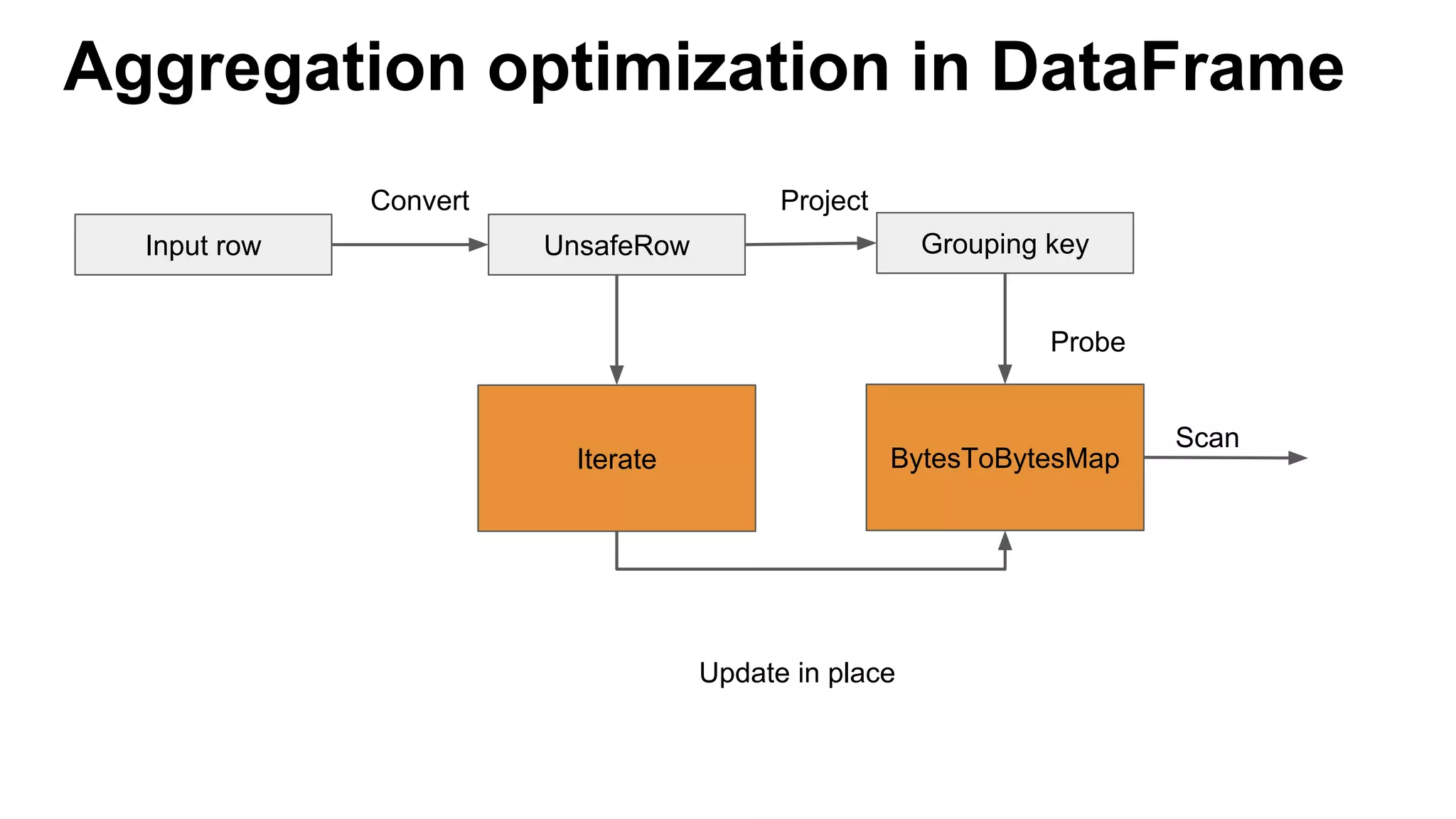
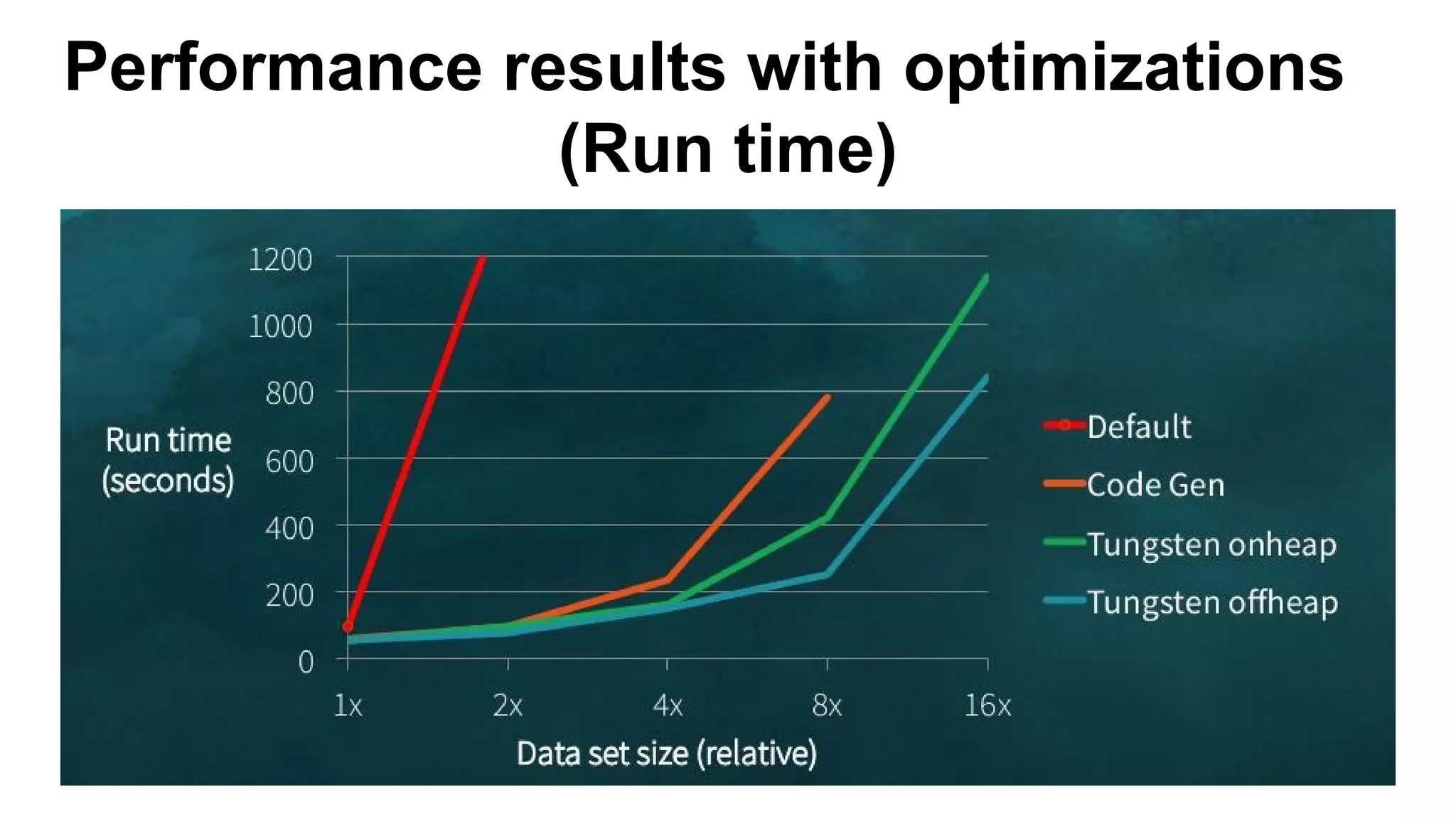
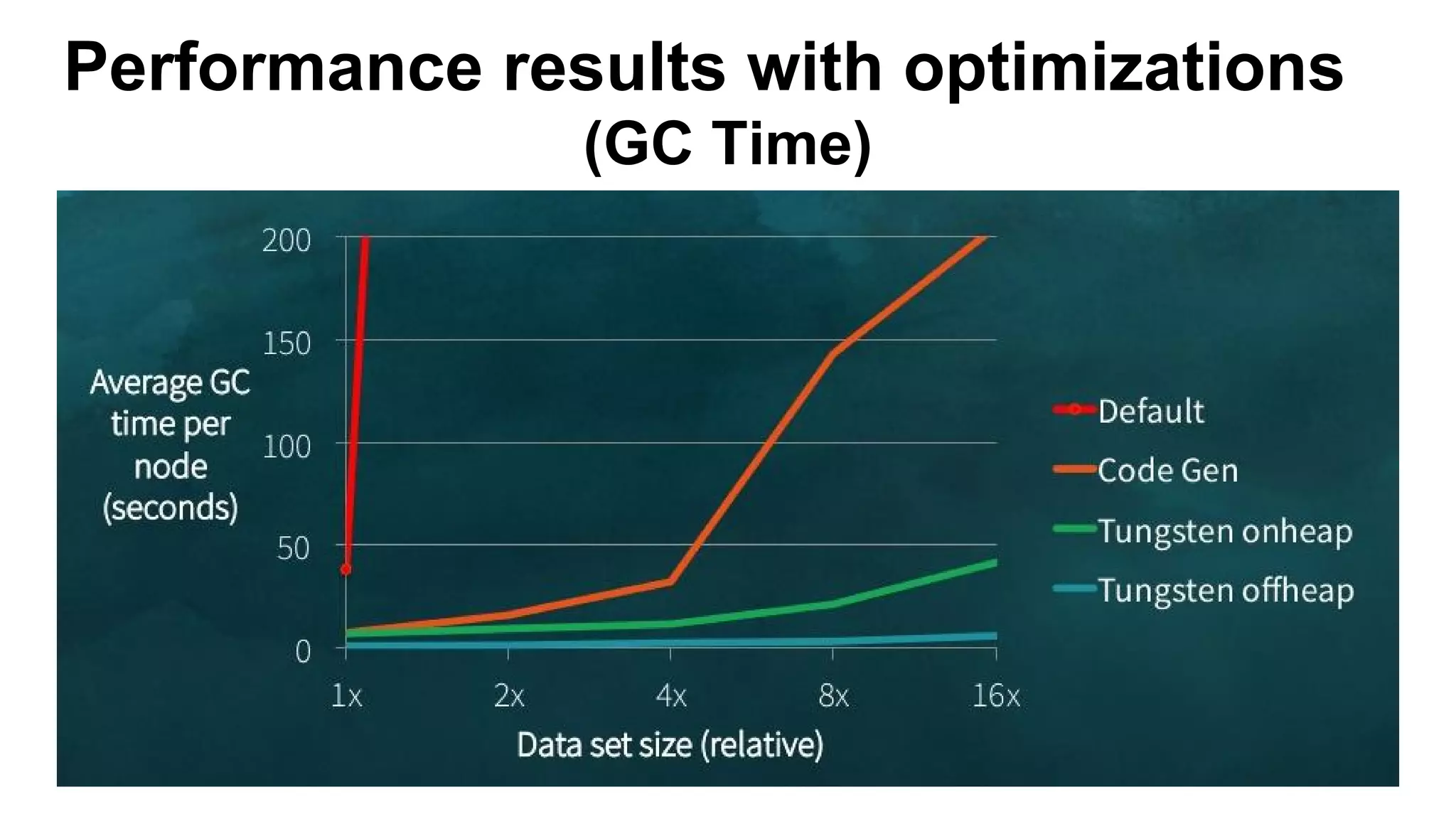


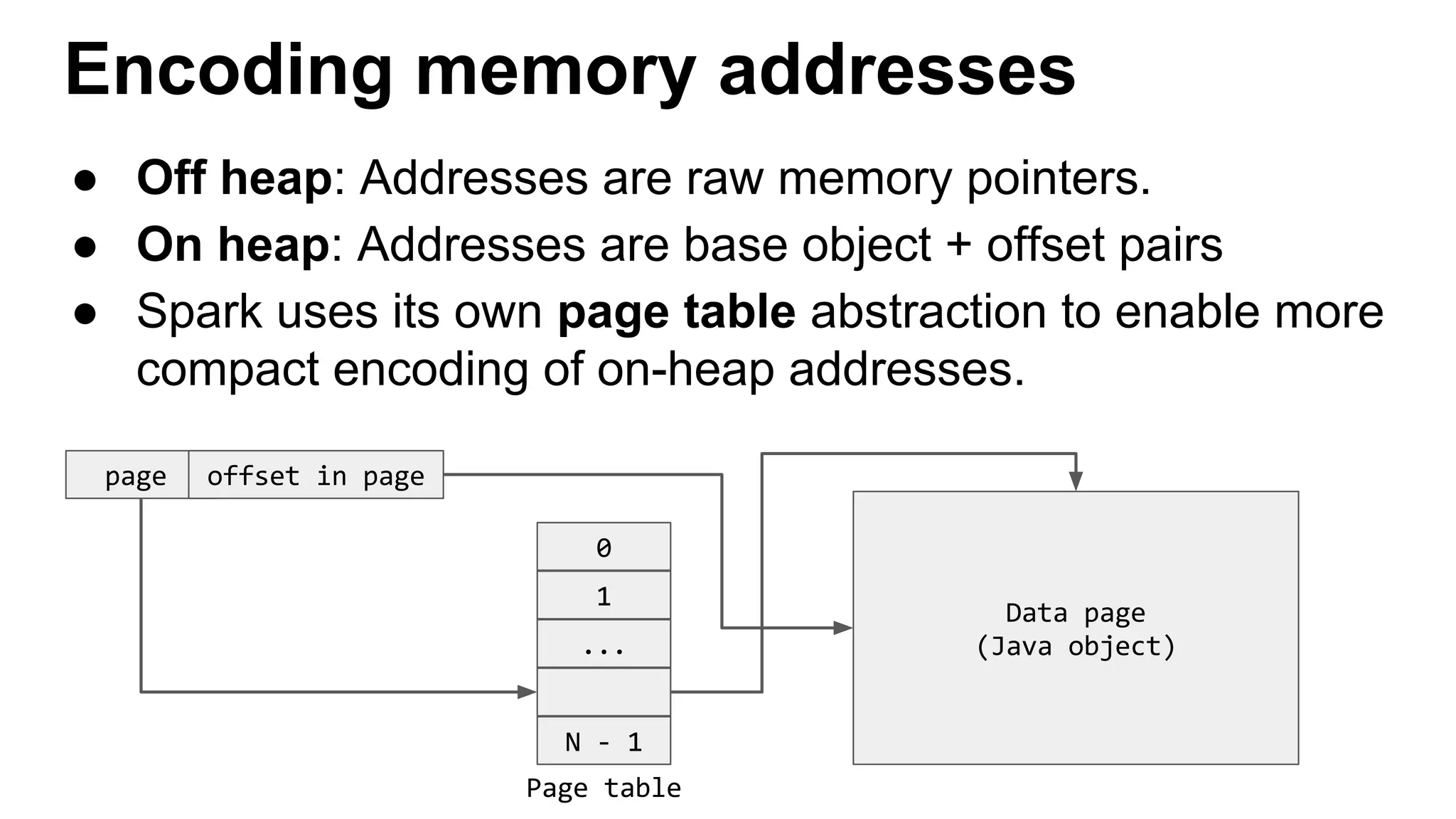
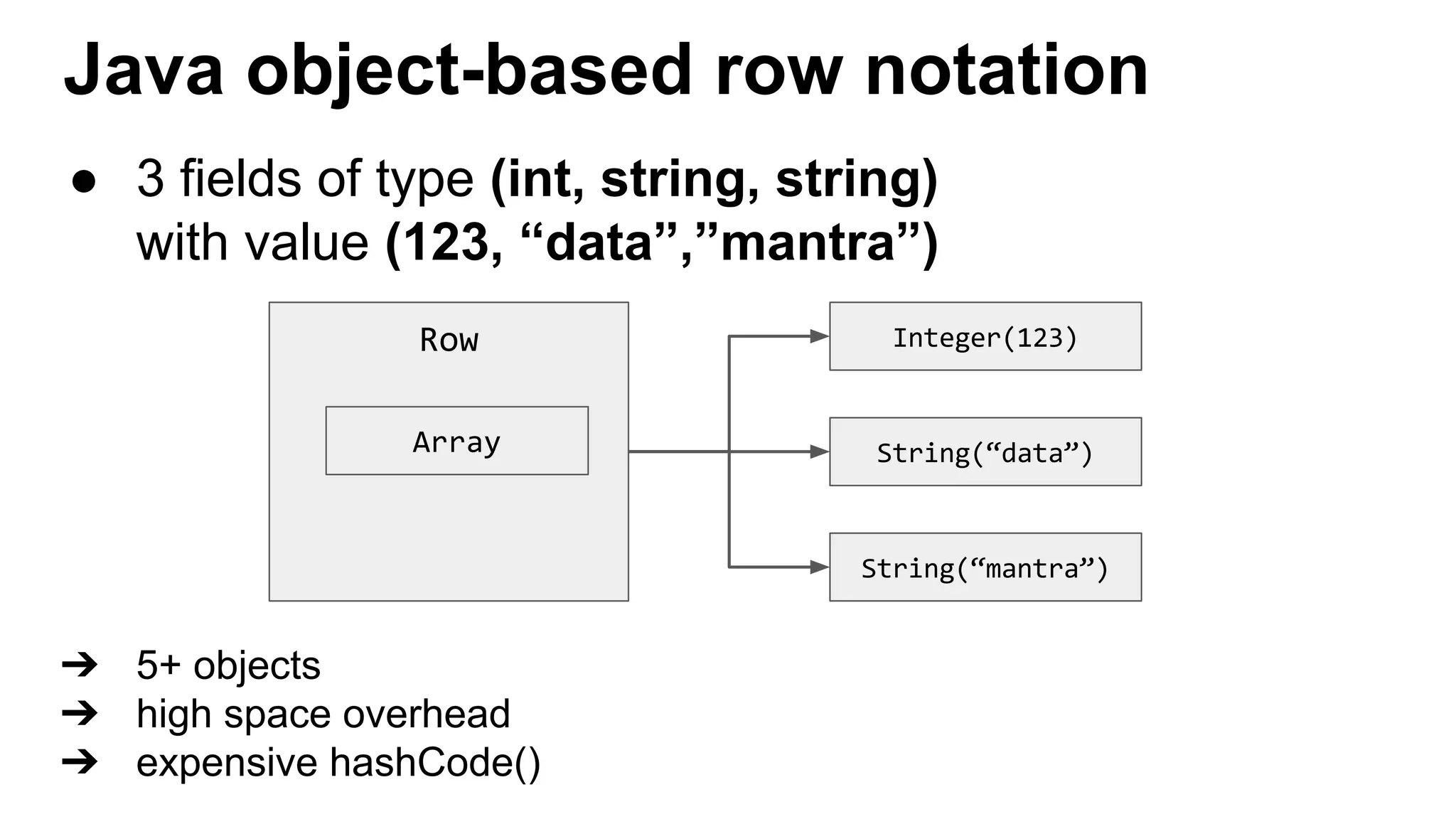
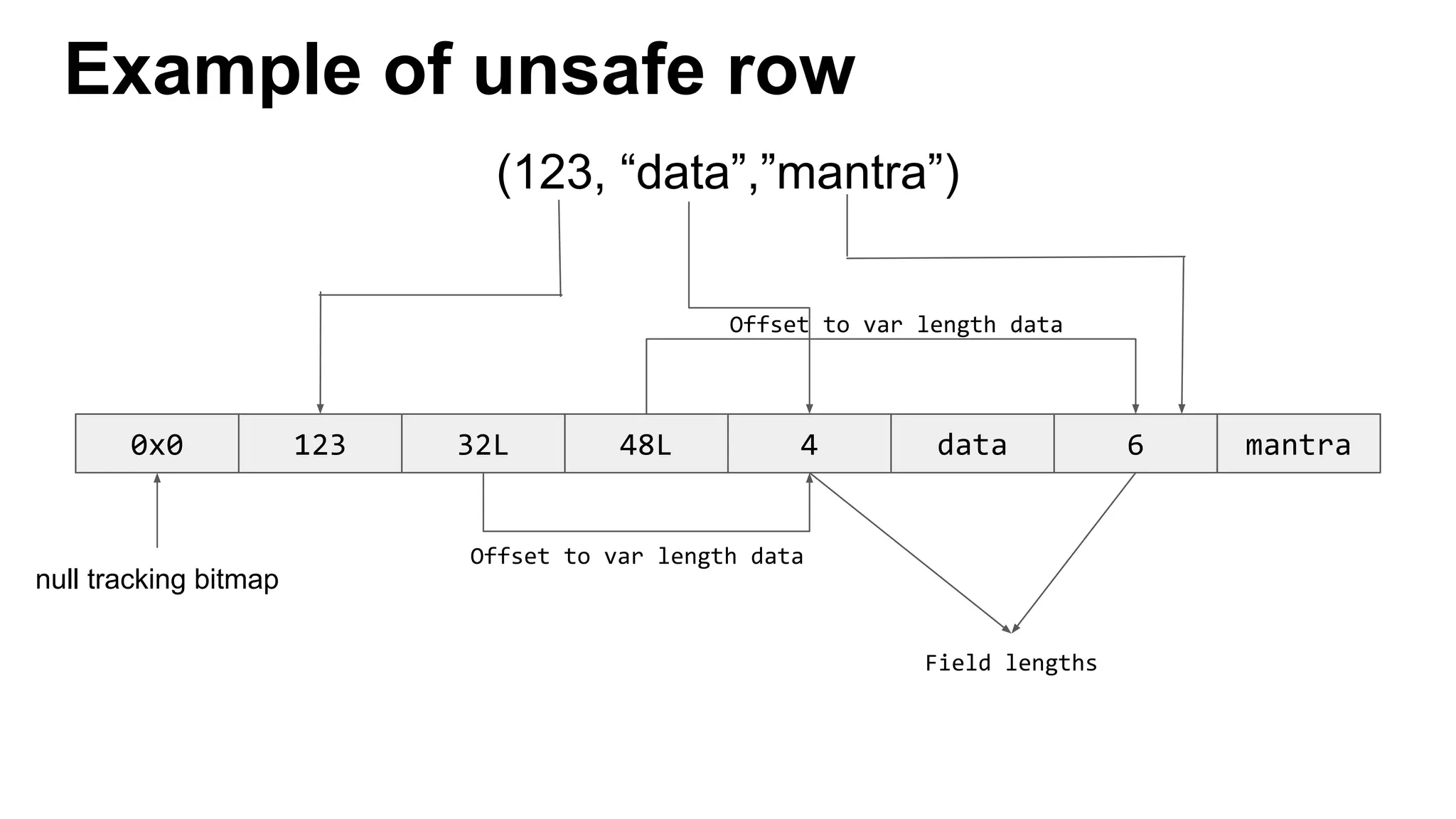
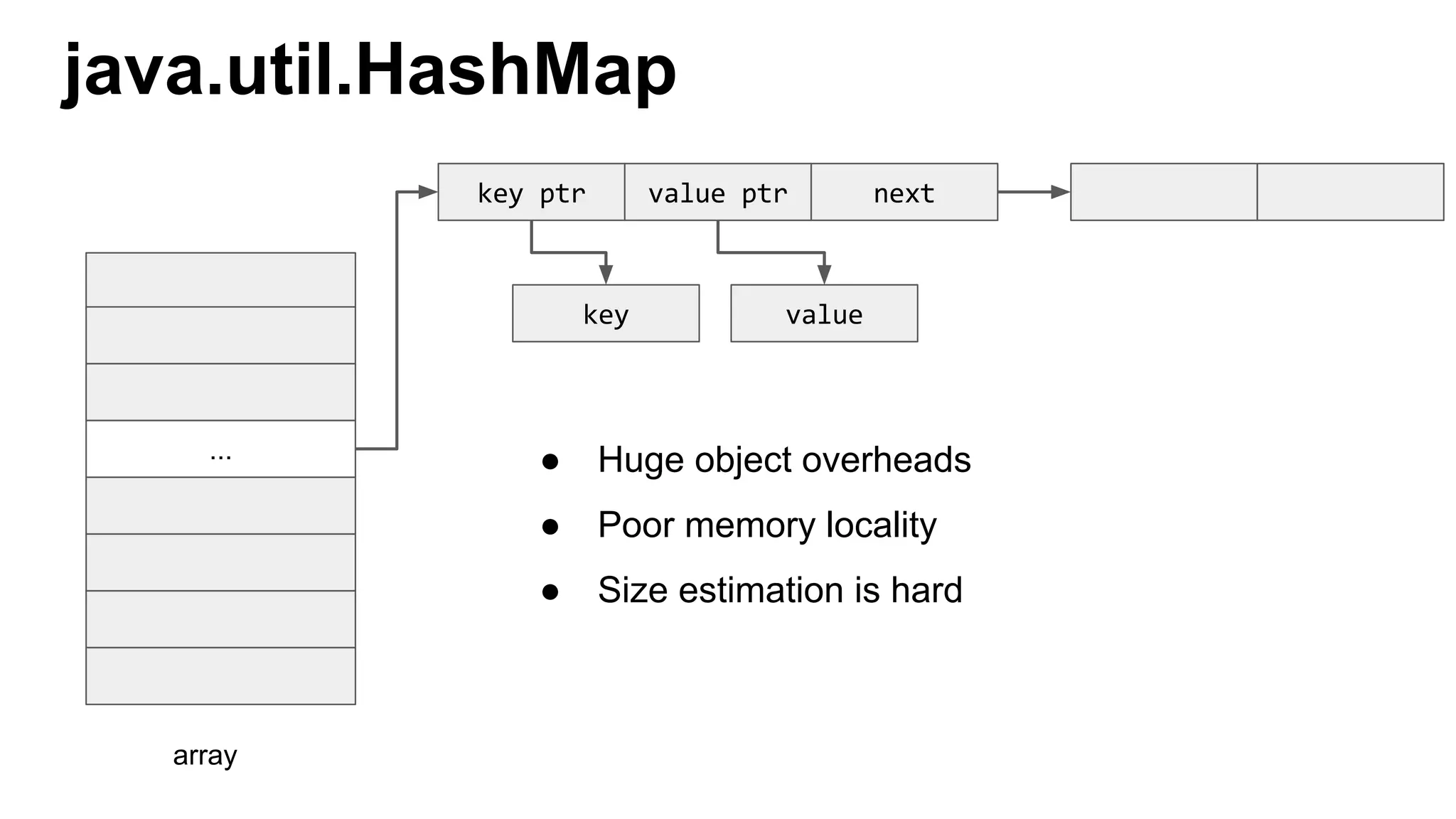
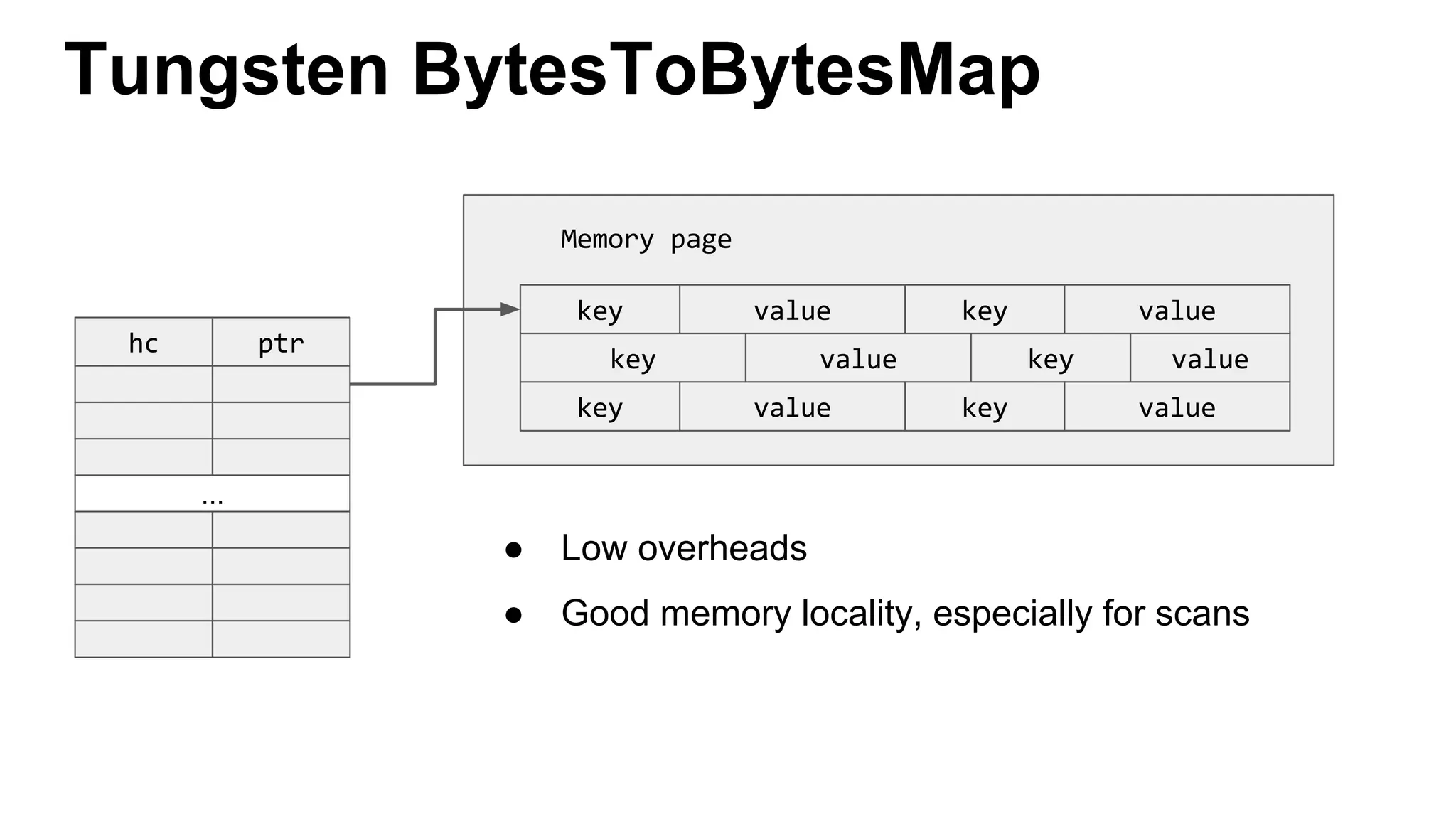
This document discusses custom memory management techniques in Spark that provide performance benefits over the standard JVM approach. It covers how Spark uses unsafe off-heap memory allocation, fixed-width serialization, and just-in-time code generation to process data more efficiently in memory. These techniques allow Spark to avoid object overhead, reduce garbage collection costs, and optimize aggregation operations. Measurements show they can significantly reduce processing time and garbage collection overhead compared to the standard JVM approach.









































































![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)




