Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
KM
Uploaded by
Koji Matsuda
23,041 views
「今日から使い切る」 ための GNU Parallel による並列処理入門
東北大学 乾・岡崎研究室で 2016/01/25 に行われた研究会でショートトークを行った際に使用した GNU Parallel のイントロダクションです。
Software
◦
Related topics:
Natural Language Processing
•
Computer Science Basics
•
Read more
23
Save
Share
Embed
Embed presentation
Download
Downloaded 34 times
1
/ 14
2
/ 14
3
/ 14
4
/ 14
5
/ 14
Most read
6
/ 14
7
/ 14
8
/ 14
9
/ 14
10
/ 14
11
/ 14
12
/ 14
Most read
13
/ 14
Most read
14
/ 14
More Related Content
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PDF
最適化超入門
by
Takami Sato
PDF
ChatGPT 人間のフィードバックから強化学習した対話AI
by
Shota Imai
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
Transformer メタサーベイ
by
cvpaper. challenge
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
最適化超入門
by
Takami Sato
ChatGPT 人間のフィードバックから強化学習した対話AI
by
Shota Imai
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
What's hot
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
(修正)機械学習デザインパターン(ML Design Patterns)の解説
by
Hironori Washizaki
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PPTX
学習時に使ってはいないデータの混入「リーケージを避ける」
by
西岡 賢一郎
PDF
Marp Tutorial
by
Rui Watanabe
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PPTX
【LT資料】 Neural Network 素人なんだけど何とかご機嫌取りをしたい
by
Takuji Tahara
PDF
不老におけるOptunaを利用した分散ハイパーパラメータ最適化 - 今村秀明(名古屋大学 Optuna講習会)
by
Preferred Networks
PDF
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PDF
研究効率化Tips Ver.2
by
cvpaper. challenge
PDF
ナレッジグラフとオントロジー
by
University of Tsukuba
PDF
深層生成モデルと世界モデル, 深層生成モデルライブラリPixyzについて
by
Masahiro Suzuki
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
最適輸送の計算アルゴリズムの研究動向
by
ohken
(修正)機械学習デザインパターン(ML Design Patterns)の解説
by
Hironori Washizaki
Attentionの基礎からTransformerの入門まで
by
AGIRobots
深層生成モデルと世界モデル
by
Masahiro Suzuki
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
学習時に使ってはいないデータの混入「リーケージを避ける」
by
西岡 賢一郎
Marp Tutorial
by
Rui Watanabe
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
【LT資料】 Neural Network 素人なんだけど何とかご機嫌取りをしたい
by
Takuji Tahara
不老におけるOptunaを利用した分散ハイパーパラメータ最適化 - 今村秀明(名古屋大学 Optuna講習会)
by
Preferred Networks
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
研究効率化Tips Ver.2
by
cvpaper. challenge
ナレッジグラフとオントロジー
by
University of Tsukuba
深層生成モデルと世界モデル, 深層生成モデルライブラリPixyzについて
by
Masahiro Suzuki
Viewers also liked
KEY
スタート形態素解析
by
tod esking
PDF
Sintesis informativa 03 de marzo 2017
by
megaradioexpress
PDF
研究生のためのC++ no.5
by
Tomohiro Namba
DOCX
Cecibel curimilma blog
by
Cecibel Curimilma
PDF
M3 Imp Unitwise
by
Math Arulselvan
DOCX
Agenda cecibel
by
Cecibel Curimilma
DOCX
Practica n1 ceci
by
Cecibel Curimilma
PDF
Practica funciones (1)
by
Cecibel Curimilma
PDF
Taller Música
by
analabradorcra
PDF
Taller Informática
by
analabradorcra
PDF
Taller Inglés
by
analabradorcra
PPTX
Guía aval 3
by
analabradorcra
PPT
Quiz on computing scientists
by
SabahtHussein
PPT
Professionalism
by
Greg Tampus
PDF
15分でざっくり分かるScala入門
by
SatoYu1ro
PDF
Nuevas tecnologías
by
Carolina Cardoso
PPTX
知識を紡ぐための言語処理と、 そのための言語資源
by
Koji Matsuda
PDF
Spiderストレージエンジンのご紹介
by
Kentoku
スタート形態素解析
by
tod esking
Sintesis informativa 03 de marzo 2017
by
megaradioexpress
研究生のためのC++ no.5
by
Tomohiro Namba
Cecibel curimilma blog
by
Cecibel Curimilma
M3 Imp Unitwise
by
Math Arulselvan
Agenda cecibel
by
Cecibel Curimilma
Practica n1 ceci
by
Cecibel Curimilma
Practica funciones (1)
by
Cecibel Curimilma
Taller Música
by
analabradorcra
Taller Informática
by
analabradorcra
Taller Inglés
by
analabradorcra
Guía aval 3
by
analabradorcra
Quiz on computing scientists
by
SabahtHussein
Professionalism
by
Greg Tampus
15分でざっくり分かるScala入門
by
SatoYu1ro
Nuevas tecnologías
by
Carolina Cardoso
知識を紡ぐための言語処理と、 そのための言語資源
by
Koji Matsuda
Spiderストレージエンジンのご紹介
by
Kentoku
Similar to 「今日から使い切る」 ための GNU Parallel による並列処理入門
PDF
Linuxにて複数のコマンドを並列実行(同時実行数の制限付き)
by
Hiro H.
PDF
分散メモリ環境におけるシェルスクリプトの高速化手法の提案
by
Keisuke Umeno
PDF
Start Concurrent
by
Akira Takahashi
PDF
PostgreSQLのパラレル化に向けた取り組み@第30回(仮名)PostgreSQL勉強会
by
Shigeru Hanada
PDF
EmbulkのGCS/BigQuery周りのプラグインについて
by
Satoshi Akama
PDF
マルチタスクって奥が深い #mishimapm
by
鉄次 尾形
Linuxにて複数のコマンドを並列実行(同時実行数の制限付き)
by
Hiro H.
分散メモリ環境におけるシェルスクリプトの高速化手法の提案
by
Keisuke Umeno
Start Concurrent
by
Akira Takahashi
PostgreSQLのパラレル化に向けた取り組み@第30回(仮名)PostgreSQL勉強会
by
Shigeru Hanada
EmbulkのGCS/BigQuery周りのプラグインについて
by
Satoshi Akama
マルチタスクって奥が深い #mishimapm
by
鉄次 尾形
More from Koji Matsuda
PPTX
Reading Wikipedia to Answer Open-Domain Questions (ACL2017) and more...
by
Koji Matsuda
PPTX
KB + Text => Great KB な論文を多読してみた
by
Koji Matsuda
PPTX
Large-Scale Information Extraction from Textual Definitions through Deep Syn...
by
Koji Matsuda
PDF
場所参照表現タグ付きコーパスの 構築と評価
by
Koji Matsuda
PPTX
Entity linking meets Word Sense Disambiguation: a unified approach(TACL 2014)の紹介
by
Koji Matsuda
PDF
いまさら聞けない “モデル” の話 @DSIRNLP#5
by
Koji Matsuda
PDF
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
PDF
Align, Disambiguate and Walk : A Unified Approach forMeasuring Semantic Simil...
by
Koji Matsuda
PDF
Joint Modeling of a Matrix with Associated Text via Latent Binary Features
by
Koji Matsuda
PPTX
Vanishing Component Analysis
by
Koji Matsuda
PDF
A Machine Learning Framework for Programming by Example
by
Koji Matsuda
PDF
Information-Theoretic Metric Learning
by
Koji Matsuda
PDF
Unified Expectation Maximization
by
Koji Matsuda
PDF
Language Models as Representations for Weakly-Supervised NLP Tasks (CoNLL2011)
by
Koji Matsuda
PDF
研究室内PRML勉強会 11章2-4節
by
Koji Matsuda
PDF
研究室内PRML勉強会 8章1節
by
Koji Matsuda
PDF
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010)
by
Koji Matsuda
PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
Reading Wikipedia to Answer Open-Domain Questions (ACL2017) and more...
by
Koji Matsuda
KB + Text => Great KB な論文を多読してみた
by
Koji Matsuda
Large-Scale Information Extraction from Textual Definitions through Deep Syn...
by
Koji Matsuda
場所参照表現タグ付きコーパスの 構築と評価
by
Koji Matsuda
Entity linking meets Word Sense Disambiguation: a unified approach(TACL 2014)の紹介
by
Koji Matsuda
いまさら聞けない “モデル” の話 @DSIRNLP#5
by
Koji Matsuda
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
Align, Disambiguate and Walk : A Unified Approach forMeasuring Semantic Simil...
by
Koji Matsuda
Joint Modeling of a Matrix with Associated Text via Latent Binary Features
by
Koji Matsuda
Vanishing Component Analysis
by
Koji Matsuda
A Machine Learning Framework for Programming by Example
by
Koji Matsuda
Information-Theoretic Metric Learning
by
Koji Matsuda
Unified Expectation Maximization
by
Koji Matsuda
Language Models as Representations for Weakly-Supervised NLP Tasks (CoNLL2011)
by
Koji Matsuda
研究室内PRML勉強会 11章2-4節
by
Koji Matsuda
研究室内PRML勉強会 8章1節
by
Koji Matsuda
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010)
by
Koji Matsuda
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
「今日から使い切る」 ための GNU Parallel による並列処理入門
1.
「今⽇から使い切る」 ための GNU Parallel による並列処理⼊⾨ Koji
Matsuda 1
2.
並列処理: ビッグデータ時代のリテラシー • 我々が扱うべきデータ量は爆発的に増⼤ – 例)研究室で収集しているツイート:1⽇XXXX 万ツイート(圧縮してXGB)、年間XXX億ツイート •
1CPUの性能向上は年間数⼗%、その代わり、 コア数はドンドン増えてる – 乾・岡崎研はXXXコアくらいあります 「今日から使える」「プログラミング言語非依存な」 並列処理(バカパラ)の方法を共有したい 2 既存のコードを変更しなくて良い
3.
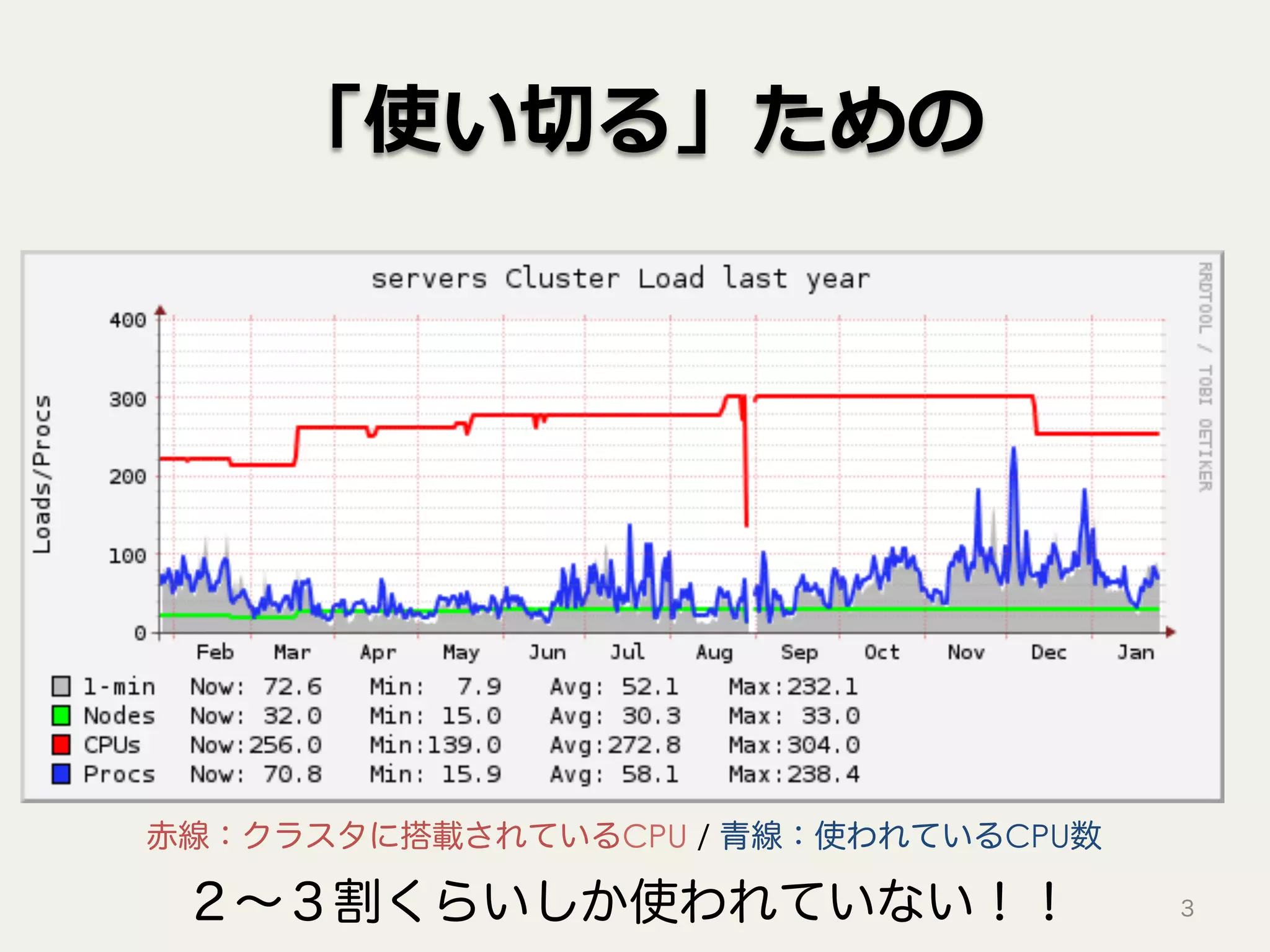
「使い切る」ための 3 赤線:クラスタに搭載されているCPU / 青線:使われているCPU数 2∼3割くらいしか使われていない!!
4.
• 並列実⾏関係の機能が詰まったユーティリティ • 便利なソフトウェアではあるのだが、マニュアル が不親切(※ボリュームがありすぎる) 4 For
people who live life in the parallel lane. http://www.gnu.org/software/parallel/man.html http://www.gnu.org/software/parallel/parallel_tutorial.html インスピレーションを刺激 する例も多くて良いドキュ メントだとは思うのです が・・・ 研究室生活でよく直面するユースケースに限って説明
5.
バカパラの三つのパターン 1. ⼩さなファイルが超⼤量、それぞれに処理 ex. Wikipediaのすべての記事(100万記事) 2.
(1⾏1レコードの)巨⼤なファイル各⾏に処理 ex. ツイートログファイル(1ファイル数GB) 3. パラメータとその組み合わせが⼤量 ex. ディープラーニング • 層数、次元数、初期化、学習率, etc… GNU Parallel でワンストップに対応 5 参考:実際に動くチュートリアルが、 https://bitbucket.org/cl-tohoku/bakapara_tutorial にあります。 乾研の大半のサーバーには GNU Parallel はインストール済なので、すぐ試せるはず
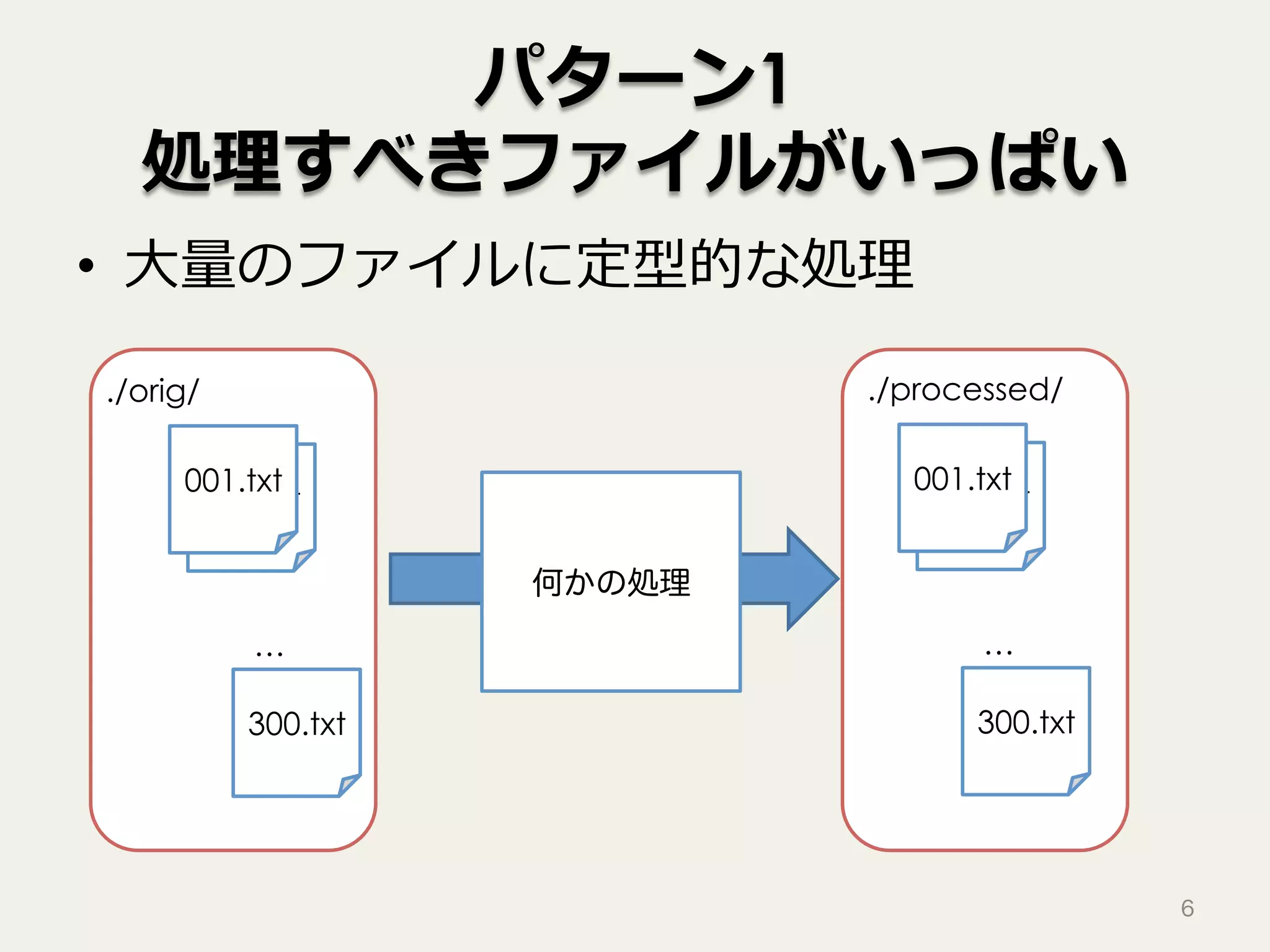
6.
パターン1 処理すべきファイルがいっぱい • ⼤量のファイルに定型的な処理 6 001.txt 001.txt ./orig/ … 300.txt ./processed/ 001.txt 001.txt … 300.txt 何かの処理
7.
パターン1 処理すべきファイルがいっぱい • GNU Parallel
のファイル名置換を使う 7 ls orig/* | parallel –j 10 “mecab < {} > processed/{/}” 意味: orig/ ディレクトリ以下のす べてのファイルに対して並列 で mecab を実行し、 processed/ 以下に出力せよ 処理するファイル のリストを生成 {} がファイル名に 置換される ex. orig/1.txt {/} はファイル名 からディレクトリを 取り除いたもの ex. orig/1.txt => 1.txt 並列数 並列数(-j) 所要時間(s) 1 13.70 3 4.61 5 3.79 10 3.21 表:並列数に対する所要時間の変化 @tequila
8.
パターン2 ⼤きなファイルのすべての⾏に 8 original.txt (100万行) processed.txt (100万行)何かの処理
9.
パターン2 ⼤きなファイルのすべての⾏に • --pipe オプションを使う 9 cat
original.txt | parallel --pipe --L 10000 “hoge.py” > processed.txt original.txt (100万行) original.txt を 1万行づつの「塊」に分解して、それぞ れを並列に hoge.py にパイプで入力せよ。結果を processed.txtにまとめよ。 1万行 hoge.py 1万行 hoge.py 1万行 hoge.py 1万行 hoge.py processed.txt (100万行) 並列実行
10.
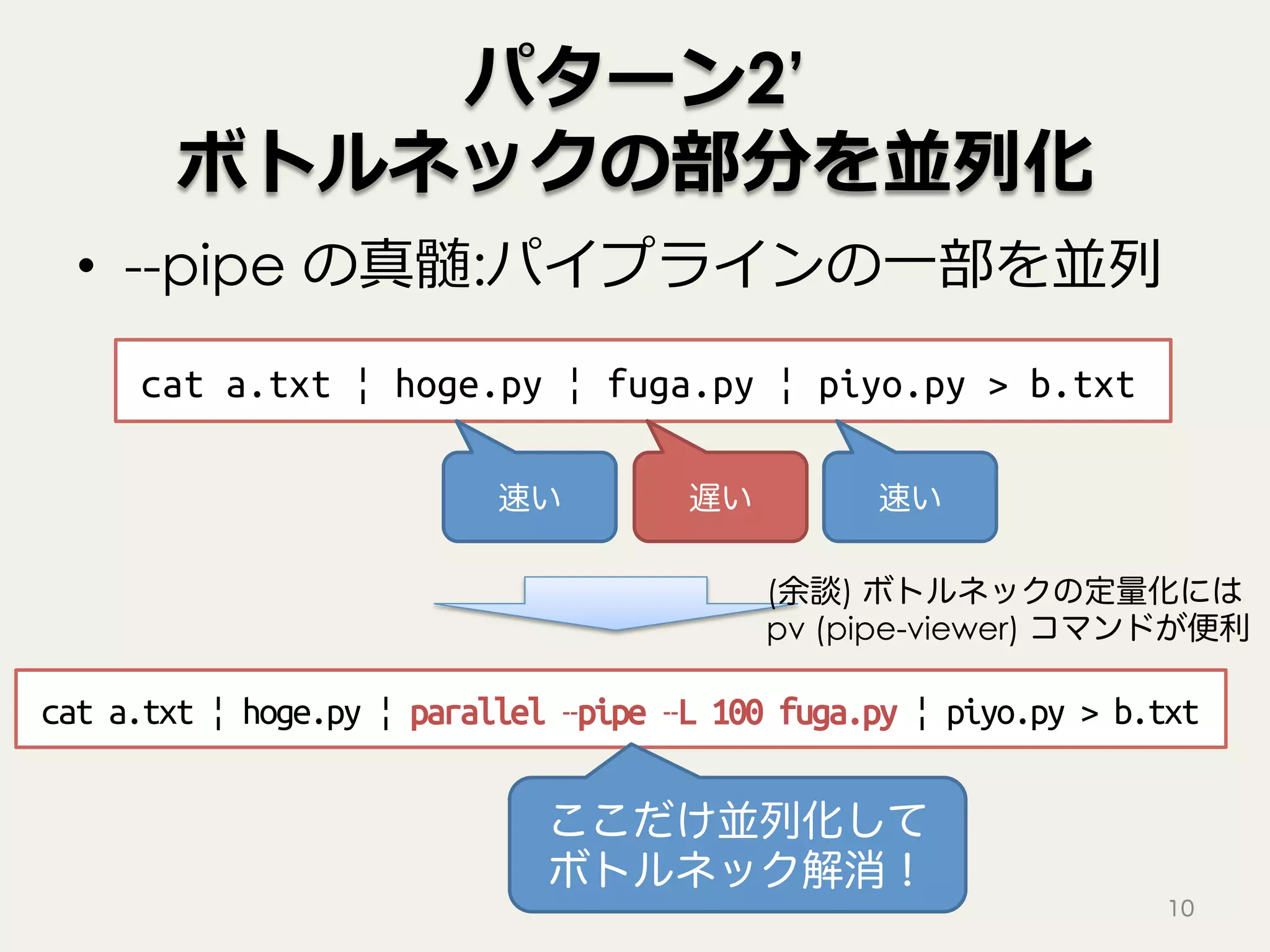
パターン2’ ボトルネックの部分を並列化 • --pipe の真髄:パイプラインの⼀部を並列 10 cat
a.txt | hoge.py | fuga.py | piyo.py > b.txt 遅い速い 速い cat a.txt | hoge.py | parallel –pipe –L 100 fuga.py | piyo.py > b.txt ここだけ並列化して ボトルネック解消! (余談) ボトルネックの定量化には pv (pipe-viewer) コマンドが便利
11.
パターン3 試すべきパラメータがいっぱい 11 train.txt 学習率 0.1 0.01 0.001 層数 1 2 3 ユニット 100 200 300 train.py ./log/ lr=0.1_layer=1_u=100.log lr=0.1_layer=1_u=200.log … lr=0.1_layer=3_u=300.log ./model/ lr=0.1_layer=1_u=100.model lr=0.1_layer=1_u=200.model … lr=0.1_layer=3_u=300.model すべての組 み合わせを 試したい
12.
パターン3 試すべきパラメータがいっぱい • GNU Parallel
の 組み合わせ展開( ::: )を使う 12 lr=(0 0.05 0.1 0.5 1.0 5) # 学習率! units=(100 200 300 400) # 隠れ層のユニット数! ! parallel “train.py --lr={1} --units={2} > log/{1}_{2}.txt“ ! "::: ${lr[@]} ::: ${units[@]} これまでfor文の多重ループで書いていた 処理が、たった3行に!!(しかも並列実行) Pythonの string.fmt と似た文法
13.
注意点 / Tips •
気をつけておきたいこと: – time コマンドでこまめに計測 • とくにパイプ並列の場合、早くならないこともある – IO / メモリが重い処理は控えめな並列数で – ⻑時間占有する場合は –nice オプションを – まずは --dry-run オプションをつけて実⾏ • どういうコマンドが実⾏されるか、教えてくれる • Tips – --bar : 進捗状況を表⽰、残り時間の推定 – -S オプション: マシンを跨いだ並列処理 – 並列数は –j オプションで指定、デフォルトではCPU数 13 --bar の例:63%のタスクが終了し、残りは8秒
14.
まとめ • GNU Parallel
を使うことのメリット: – J簡潔に書けて – J柔軟に実⾏できる – J既存のコードとの組み合わせが容易 • GNU Parallel を使うことのデメリット: – Lあまりにも簡単なので、計算機資源の奪い合い が・・? • 是⾮「今⽇から」使ってみてください • 他にもいい使い⽅があったらシェアしてくだ さいJ 14
Download








![パターン3
試すべきパラメータがいっぱい
• GNU Parallel の 組み合わせ展開( ::: )を使う
12
lr=(0 0.05 0.1 0.5 1.0 5) # 学習率!
units=(100 200 300 400) # 隠れ層のユニット数!
!
parallel “train.py --lr={1} --units={2} > log/{1}_{2}.txt“ !
"::: ${lr[@]} ::: ${units[@]}
これまでfor文の多重ループで書いていた
処理が、たった3行に!!(しかも並列実行)
Pythonの string.fmt と似た文法](https://image.slidesharecdn.com/bakaparapub-160125103205/75/GNU-Parallel-12-2048.jpg)






![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)




























































