[DL輪読会]High-Quality Self-Supervised Deep Image Denoising
1.
1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
High-Quality Self-Supervised Deep Image Denoising
Hirono Okamoto, Matsuo Lab
2.
書誌情報: High-Quality Self-SupervisedDeep Image Denoising
n NIPS 2019 accepted
n 筆頭著者: Samuli Laine (NVIDIA)
n ⼀⾔でいうと:
n ベイジアンアプローチと効率的なblind-spot networkにより,教師なしで(訓練データはノイズあり画像
のみで),ハイクオリティな画像デノイジングを可能にした
教師ありデノイジングと
ほぼ変わらない結果
関連⼿法: Noise2Voidとは︖
n まわりのピクセルΩ! のみからノイズがないピクセル 𝑥 を予測するように 𝑓" を学習する
n ここで,教師はノイズのピクセル 𝑦 とするため,ノイズなしデータはいらない
n ノイズの平均が0のときならOK [Lehtinen+, 2018]
12.
関連⼿法: Noise2Voidの限界
n Noise2Voidは𝑥 の情報を多く持った 𝑦 を⼊⼒として使っていない
n 使ってしまうと, 𝑦 はターゲットなので,モデル 𝑓! が学習してくれなくなるから
n → そこで,筆者らは訓練時には使わずに,テスト時に使うことを提案する
n 事後分布 p 𝑥 𝑦, Ω" を計算する
13.
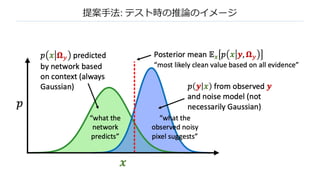
提案⼿法: 𝑥の事後分布(の平均)を利⽤する
n 訓練時:ノイズモデル p(𝑦|𝑥) は Ω! と独⽴だと仮定すると,周辺分布は次の式
n p(𝑥|Ω") を⾊のチャネル次元を持つ多変量ガウシアン分布 𝑁(µ#, Σ# ) とする
n µ#, Σ# は Ω" を⼊⼒としたときの 𝑓! の出⼒である
n 推論時: 𝑥の事後分布は,ベイズの定理より次のように求まる
n 最終的には事後平均𝐸# p 𝑥 𝑦, Ω" を計算する(このときPSNRが最⼤化されるため)
結論・今後の課題
n まとめ
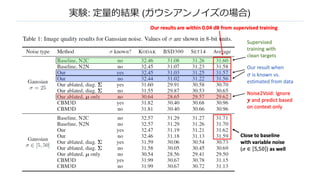
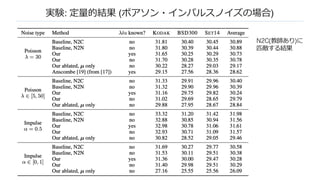
n ノイズ画像のみからデノイジングの訓練が可能になった
nデノイジング結果としてこれまでの教師あり画像とほぼ同じクオリティが得られた
n 今後の研究
n 今回はピクセルごとにノイズがiidである仮定をおいている(画像で共通のσである)が,iidではない
場合の仮定に和らげることはできないか︖
n データからノイズモデルが推定できると良い
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
High-Quality Self-Supervised Deep Image Denoising
Hirono Okamoto, Matsuo Lab](https://image.slidesharecdn.com/high-qualityself-superviseddeepimagedenoising-200501014639/85/DL-High-Quality-Self-Supervised-Deep-Image-Denoising-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
High-Quality Self-Supervised Deep Image Denoising
Hirono Okamoto, Matsuo Lab](https://image.slidesharecdn.com/high-qualityself-superviseddeepimagedenoising-200501014639/75/DL-High-Quality-Self-Supervised-Deep-Image-Denoising-1-2048.jpg)


![背景: Noise2Noiseを使った学習⽅法 [Lehtinen+, 2018]
n 教師としてノイズなし学習は必要ではないが,別のノイズ画像が必要](https://image.slidesharecdn.com/high-qualityself-superviseddeepimagedenoising-200501014639/85/DL-High-Quality-Self-Supervised-Deep-Image-Denoising-4-320.jpg)
![背景: Noise2Voidを使った学習⽅法 [Krull+, 2018]
n ノイズなし画像なしで学習が可能に](https://image.slidesharecdn.com/high-qualityself-superviseddeepimagedenoising-200501014639/85/DL-High-Quality-Self-Supervised-Deep-Image-Denoising-5-320.jpg)





![関連⼿法: Noise2Voidとは︖
n まわりのピクセル Ω! のみからノイズがないピクセル 𝑥 を予測するように 𝑓" を学習する
n ここで,教師はノイズのピクセル 𝑦 とするため,ノイズなしデータはいらない
n ノイズの平均が0のときならOK [Lehtinen+, 2018]](https://image.slidesharecdn.com/high-qualityself-superviseddeepimagedenoising-200501014639/85/DL-High-Quality-Self-Supervised-Deep-Image-Denoising-11-320.jpg)


![提案⼿法: ノイズモデルがガウシアンの例
n 平均0,分散σ# 𝐼のノイズが元画像の加わったと仮定した場合,
𝑝 𝑦 𝑥 = 𝑓 𝑦; µ!, Σ! = 𝑁(µ$, Σ$ + σ# 𝐼) となる
n このとき,𝑓" を最適化するためのロス関数は負の対数尤度で以下の式となる
n Σ"が単位⾏列ならNoise2Voidのときと同じ
n ここで,正規化されていない事後分布は次の式
n 最後に,事後分布の平均を求める
n 実は上記の平均は事後分布の平均に⼀致する [Bromiley, 2018]
← 𝑥の推論に𝑦の値を使っていることがわかる](https://image.slidesharecdn.com/high-qualityself-superviseddeepimagedenoising-200501014639/85/DL-High-Quality-Self-Supervised-Deep-Image-Denoising-15-320.jpg)
![提案⼿法: ノイズモデルがポアソン分布の例
n ポアソンノイズは,シグナルに依存するガウシアンノイズに近似できる [Hasinoff, 2014]
n よって,𝑝 𝑦 𝑥 の平均と共分散は下式
n あとはガウシアンノイズのときと同じ](https://image.slidesharecdn.com/high-qualityself-superviseddeepimagedenoising-200501014639/85/DL-High-Quality-Self-Supervised-Deep-Image-Denoising-16-320.jpg)

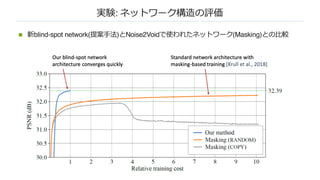
![提案⼿法: 効率的なblind-spot network
n blind-spot network: ノイズのない,あるピクセル 𝑥 を予測するために,4⽅向からpixelCNN
のように回帰するネットワーク [Krull+, 2018]
効率的に
パラメタシェアでパラメタ数を1/4になる](https://image.slidesharecdn.com/high-qualityself-superviseddeepimagedenoising-200501014639/85/DL-High-Quality-Self-Supervised-Deep-Image-Denoising-18-320.jpg)







![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]10分で10本の論⽂をざっくりと理解する (ICML2020)](https://cdn.slidesharecdn.com/ss_thumbnails/20200828-ant-200828025358-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Regularization with stochastic transformations and perturbations for d...](https://cdn.slidesharecdn.com/ss_thumbnails/regularizationwithstochastictransformationsandperturbationsfordeepsemi-supervisedlearning-170215034444-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Unsupervised Learning by Predicting Noise](https://cdn.slidesharecdn.com/ss_thumbnails/dlrinkonat-170512005324-thumbnail.jpg?width=640&height=640&fit=bounds)























