Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
2,457 views
[DL輪読会]Pyramid Stereo Matching Network
2019/05/31 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 36 times
1
/ 28
2
/ 28
Most read
3
/ 28
4
/ 28
5
/ 28
6
/ 28
Most read
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PDF
[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation
by
Deep Learning JP
PDF
2018/12/28 LiDARで取得した道路上点群に対するsemantic segmentation
by
Takuya Minagawa
PPTX
StyleGAN解説 CVPR2019読み会@DeNA
by
Kento Doi
PDF
【メタサーベイ】Neural Fields
by
cvpaper. challenge
PPTX
【DL輪読会】"Instant Neural Graphics Primitives with a Multiresolution Hash Encoding"
by
Deep Learning JP
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
GAN(と強化学習との関係)
by
Masahiro Suzuki
[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation
by
Deep Learning JP
2018/12/28 LiDARで取得した道路上点群に対するsemantic segmentation
by
Takuya Minagawa
StyleGAN解説 CVPR2019読み会@DeNA
by
Kento Doi
【メタサーベイ】Neural Fields
by
cvpaper. challenge
【DL輪読会】"Instant Neural Graphics Primitives with a Multiresolution Hash Encoding"
by
Deep Learning JP
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
What's hot
PDF
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
ブラックボックス最適化とその応用
by
gree_tech
PDF
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
PPTX
[DLHacks]StyleGANとBigGANのStyle mixing, morphing
by
Deep Learning JP
PDF
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
PPTX
SLAM勉強会(3) LSD-SLAM
by
Iwami Kazuya
PDF
コンピューテーショナルフォトグラフィ
by
Norishige Fukushima
PDF
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた
by
Katsuya Ito
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
PDF
[DL輪読会]画像を使ったSim2Realの現況
by
Deep Learning JP
PPTX
SuperGlue; Learning Feature Matching with Graph Neural Networks (CVPR'20)
by
Yusuke Uchida
PDF
semantic segmentation サーベイ
by
yohei okawa
PPTX
[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation
by
Deep Learning JP
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
by
SSII
PDF
Introduction to YOLO detection model
by
WEBFARMER. ltd.
PPTX
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
ブラックボックス最適化とその応用
by
gree_tech
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
[DLHacks]StyleGANとBigGANのStyle mixing, morphing
by
Deep Learning JP
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
SLAM勉強会(3) LSD-SLAM
by
Iwami Kazuya
コンピューテーショナルフォトグラフィ
by
Norishige Fukushima
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた
by
Katsuya Ito
近年のHierarchical Vision Transformer
by
Yusuke Uchida
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
[DL輪読会]画像を使ったSim2Realの現況
by
Deep Learning JP
SuperGlue; Learning Feature Matching with Graph Neural Networks (CVPR'20)
by
Yusuke Uchida
semantic segmentation サーベイ
by
yohei okawa
[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation
by
Deep Learning JP
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
by
SSII
Introduction to YOLO detection model
by
WEBFARMER. ltd.
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
Similar to [DL輪読会]Pyramid Stereo Matching Network
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PDF
これからのコンピュータビジョン技術 - cvpaper.challenge in PRMU Grand Challenge 2016 (PRMU研究会 2...
by
cvpaper. challenge
PDF
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
PPTX
20190831 3 d_inaba_final
by
DaikiInaba
PPTX
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unk...
by
Kazuyuki Miyazawa
PDF
点群深層学習 Meta-study
by
Naoya Chiba
PDF
ICCV2019読み会「Learning Meshes for Dense Visual SLAM」
by
Sho Kagami
PDF
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2
by
Daiki Shimada
PDF
SSD: Single Shot MultiBox Detector (ECCV2016)
by
Takanori Ogata
PDF
Point net
by
Fujimoto Keisuke
PDF
Tatsuya Sueki Bachelor Thesis
by
pflab
PDF
論文紹介 Pixel Recurrent Neural Networks
by
Seiya Tokui
PDF
【2015.08】(4/5)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PDF
(文献紹介)深層学習による動被写体ロバストなカメラの動き推定
by
Morpho, Inc.
PPTX
[DL輪読会]Mask TextSpotter v3: Segmentation Proposal Network for Robust Scene Te...
by
Deep Learning JP
PPTX
PredCNN: Predictive Learning with Cascade Convolutions
by
harmonylab
PDF
論文読み会(DeMoN;CVPR2017)
by
Masaya Kaneko
PDF
Eccv 2020 dsmnet
by
Kenta Tanaka
PDF
【2015.06】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PDF
cvpaper.challenge in CVPR2015 (PRMU2015年12月)
by
cvpaper. challenge
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
これからのコンピュータビジョン技術 - cvpaper.challenge in PRMU Grand Challenge 2016 (PRMU研究会 2...
by
cvpaper. challenge
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
20190831 3 d_inaba_final
by
DaikiInaba
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unk...
by
Kazuyuki Miyazawa
点群深層学習 Meta-study
by
Naoya Chiba
ICCV2019読み会「Learning Meshes for Dense Visual SLAM」
by
Sho Kagami
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2
by
Daiki Shimada
SSD: Single Shot MultiBox Detector (ECCV2016)
by
Takanori Ogata
Point net
by
Fujimoto Keisuke
Tatsuya Sueki Bachelor Thesis
by
pflab
論文紹介 Pixel Recurrent Neural Networks
by
Seiya Tokui
【2015.08】(4/5)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
(文献紹介)深層学習による動被写体ロバストなカメラの動き推定
by
Morpho, Inc.
[DL輪読会]Mask TextSpotter v3: Segmentation Proposal Network for Robust Scene Te...
by
Deep Learning JP
PredCNN: Predictive Learning with Cascade Convolutions
by
harmonylab
論文読み会(DeMoN;CVPR2017)
by
Masaya Kaneko
Eccv 2020 dsmnet
by
Kenta Tanaka
【2015.06】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
cvpaper.challenge in CVPR2015 (PRMU2015年12月)
by
cvpaper. challenge
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
Recently uploaded
PDF
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
PDF
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
PPTX
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
PDF
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
PDF
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
[DL輪読会]Pyramid Stereo Matching Network
1.
PSMNet: Pyramid Stereo Matching
Network (CVPR 2018) Hiroaki Sugisaki, 上智大学 B4(休) 1
2.
スライドについて ● Google Slideで公開 ○
誤り等のご指摘があれば修正しますので最新版は以下のURLよりお願いします。 ○ https://docs.google.com/presentation/d/1lcTaWmU4ZIBO91cuyJWK-rHbevgwcUFBH--he- F7DKI/edit?usp=sharing 2
3.
論文情報 ● 書誌情報 ○ Pyramid
Stereo Matching Network (CVPR 2018) ○ https://arxiv.org/abs/1803.08669 ○ Jia-Ren Chang, Yong-Sheng Chen ● 要約 ○ END-to-ENDなステレオマッチングモデル ○ END-to-ENDが苦手とするill-posedな領域の精度をあげた (occulusion/繰り返しパターン) ■ SPPM (Spatial Pyramid Pooling Module) によって画像全体の中での文脈を把握(Global Context) ■ downsampleとupsampleを繰り返す3D CNNに通すことで出力を調整 ○ 個人的にはSemantic Segmentationに用いられている手法をStereo Matchingに適応している 印象がある 3
4.
内容 ● ステレオマッチングについて ● 関連研究 ●
PSMNet ● 実験と結果 ● 結論 4
5.
● ステレオマッチングについて ○ ステレオマッチング ○
Disparity Map 5
6.
ステレオマッチング ● ステレオカメラ ○ 対象物を複数の異なる方向から同時に撮影することのできるカメラ ●
ステレオマッチング ○ ステレオカメラによって撮影された画像の視差(disparity)を求めること ○ また求めた視差から三角測量を用いて被写体の深度を求めること. 6 右左 - ステレオカメラ - Wikipedia : https://ja.wikipedia.org/wiki/%E3%82%B9%E3%83%86%E3%83%AC%E3%82%AA%E3%82%AB%E3%83%A1%E3%83%A9 - 2003 Stereo Datasets : http://vision.middlebury.edu/stereo/data/scenes2003/
7.
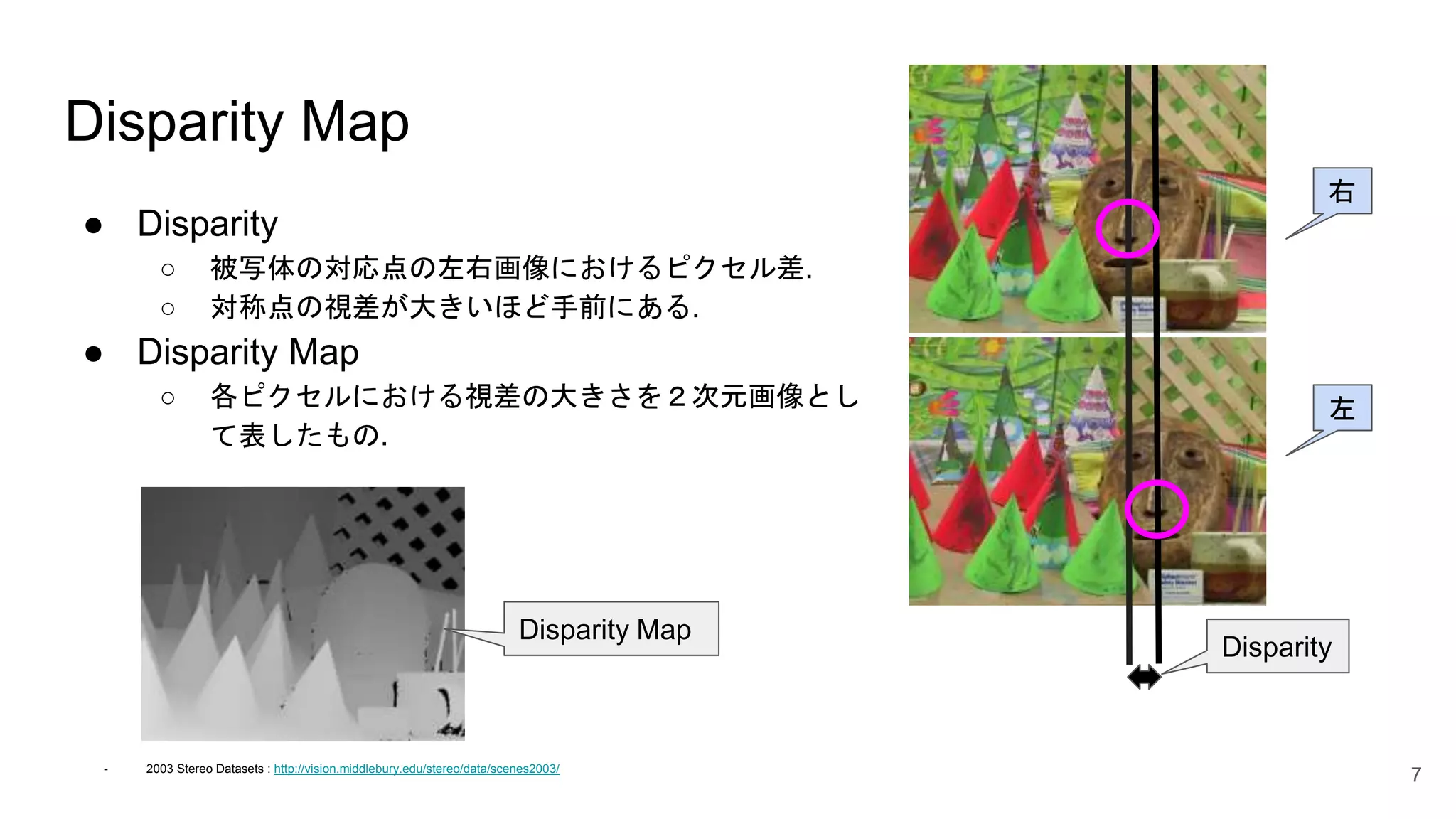
Disparity Map ● Disparity ○
被写体の対応点の左右画像におけるピクセル差. ○ 対称点の視差が大きいほど手前にある. ● Disparity Map ○ 各ピクセルにおける視差の大きさを2次元画像とし て表したもの. 7 右 左 Disparity Disparity Map - 2003 Stereo Datasets : http://vision.middlebury.edu/stereo/data/scenes2003/
8.
● 関連研究 ○ Dilated
Convolution ○ SPP (Spatial Pyramid Pooling) ○ PSPNet (Pyramid Scene Parsing Network) 8
9.
Dilated Convolution ● 以前までの受容野を広げる方法 ○
層の数を増やす => 解像度が大きいと限界 ○ フィルターを大きくする => 解像度が大きいと限界 ○ プーリング層を使う => 解像度が落ちる ● メリット ○ 簡単にかつ解像度を失わずに受容野(Receptive Field)を広げることができる ○ 線形増加するパラメータ数に対して受容野は指数関数的に広がる ■ の受容野は 9 - Dilated Convolution - ジョイジョイジョイ : http://joisino.hatenablog.com/ - arXiv : Multi-Scale Context Aggregation by Dilated Convolutions : https://arxiv.org/abs/1511.07122 - https://towardsdatascience.com/review-dilated-convolution-semantic-segmentation-9d5a5bd768f5 2-dilated 1-dilated = 普通のConv
10.
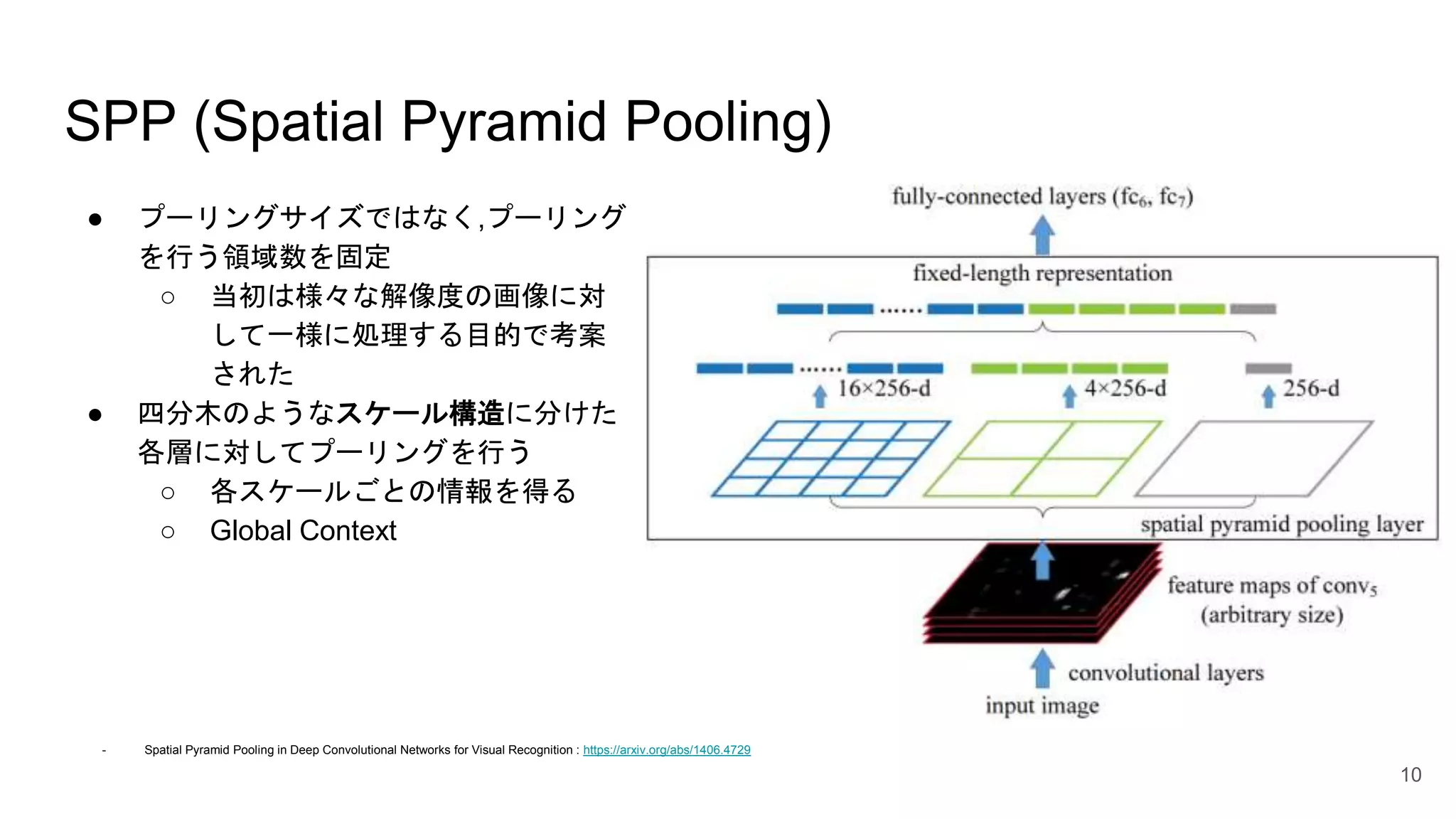
SPP (Spatial Pyramid
Pooling) ● プーリングサイズではなく,プーリング を行う領域数を固定 ○ 当初は様々な解像度の画像に対 して一様に処理する目的で考案 された ● 四分木のようなスケール構造に分けた 各層に対してプーリングを行う ○ 各スケールごとの情報を得る ○ Global Context 10 - Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition : https://arxiv.org/abs/1406.4729
11.
PSPNet (Pyramid Scene
Parsing Network) ● Pyramid Pooling Module ○ 処理の流れ ■ → SPPのプーリング ■ → 各スケールごとに1x1のConvフィルタに通すことでチャネル方向を圧縮 ■ → プーリング前のサイズにupsample ○ 各スケールの内包関係などの階層的情報を伝達 11 - [1612.01105] Pyramid Scene Parsing Network : https://arxiv.org/abs/1612.01105
12.
Stacked Hourglass Networks ●
Hourglassデザイン ○ 様々なスケールにおける情報を取得するモチベーション ○ Human Pose Estimationで体の部位の関係を取得するのに利用 12- [1603.06937] Stacked Hourglass Networks for Human Pose Estimation : https://arxiv.org/abs/1603.06937
13.
● PSMNet ○ 全体構造 ○
CNNによる特徴抽出 ○ SPP Module ○ Cost Volume ○ 3D CNN ○ Loss 13
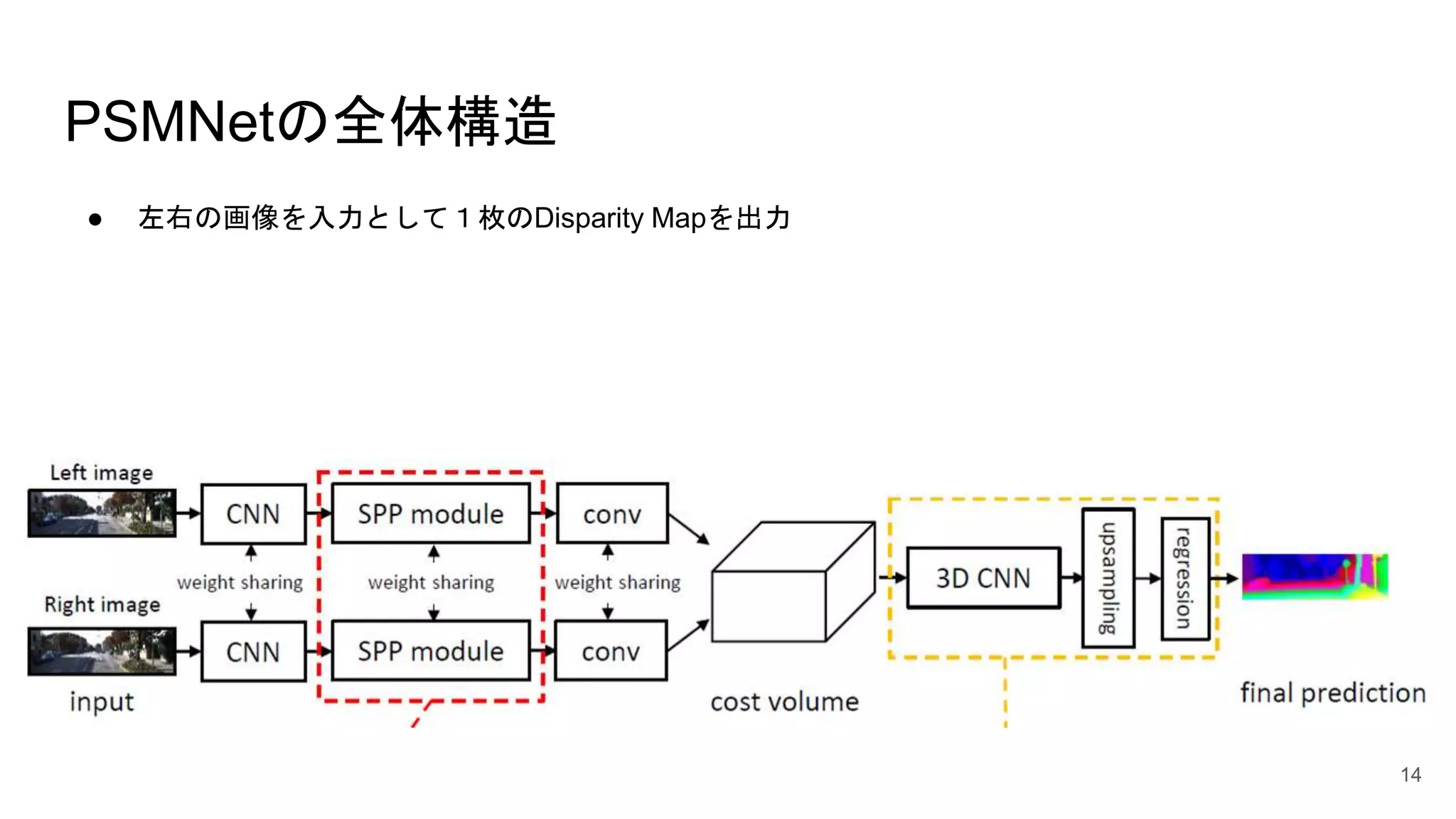
14.
PSMNetの全体構造 ● 左右の画像を入力として1枚のDisparity Mapを出力 14
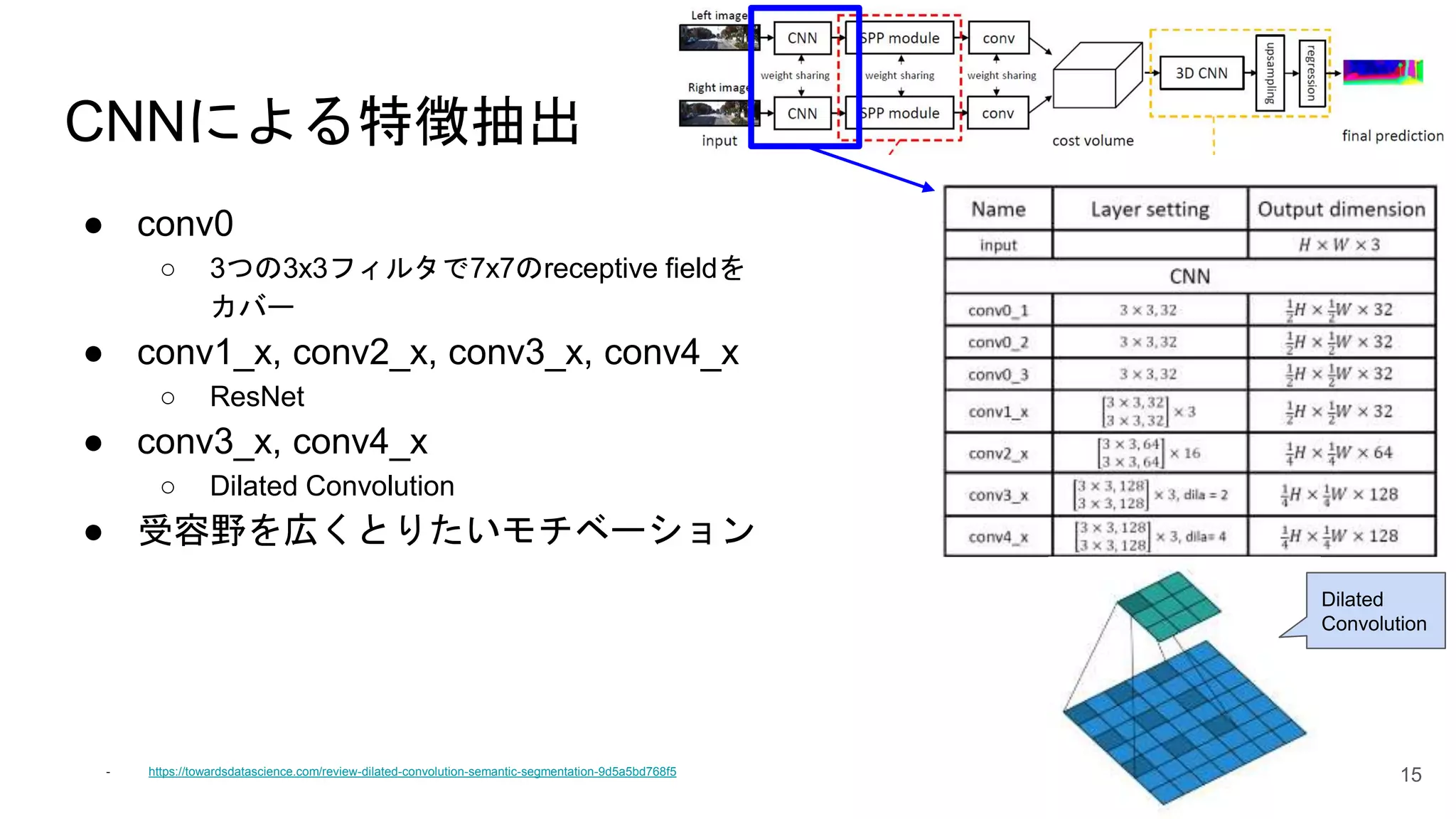
15.
CNNによる特徴抽出 ● conv0 ○ 3つの3x3フィルタで7x7のreceptive
fieldを カバー ● conv1_x, conv2_x, conv3_x, conv4_x ○ ResNet ● conv3_x, conv4_x ○ Dilated Convolution ● 受容野を広くとりたいモチベーション - https://towardsdatascience.com/review-dilated-convolution-semantic-segmentation-9d5a5bd768f5 15 Dilated Convolution
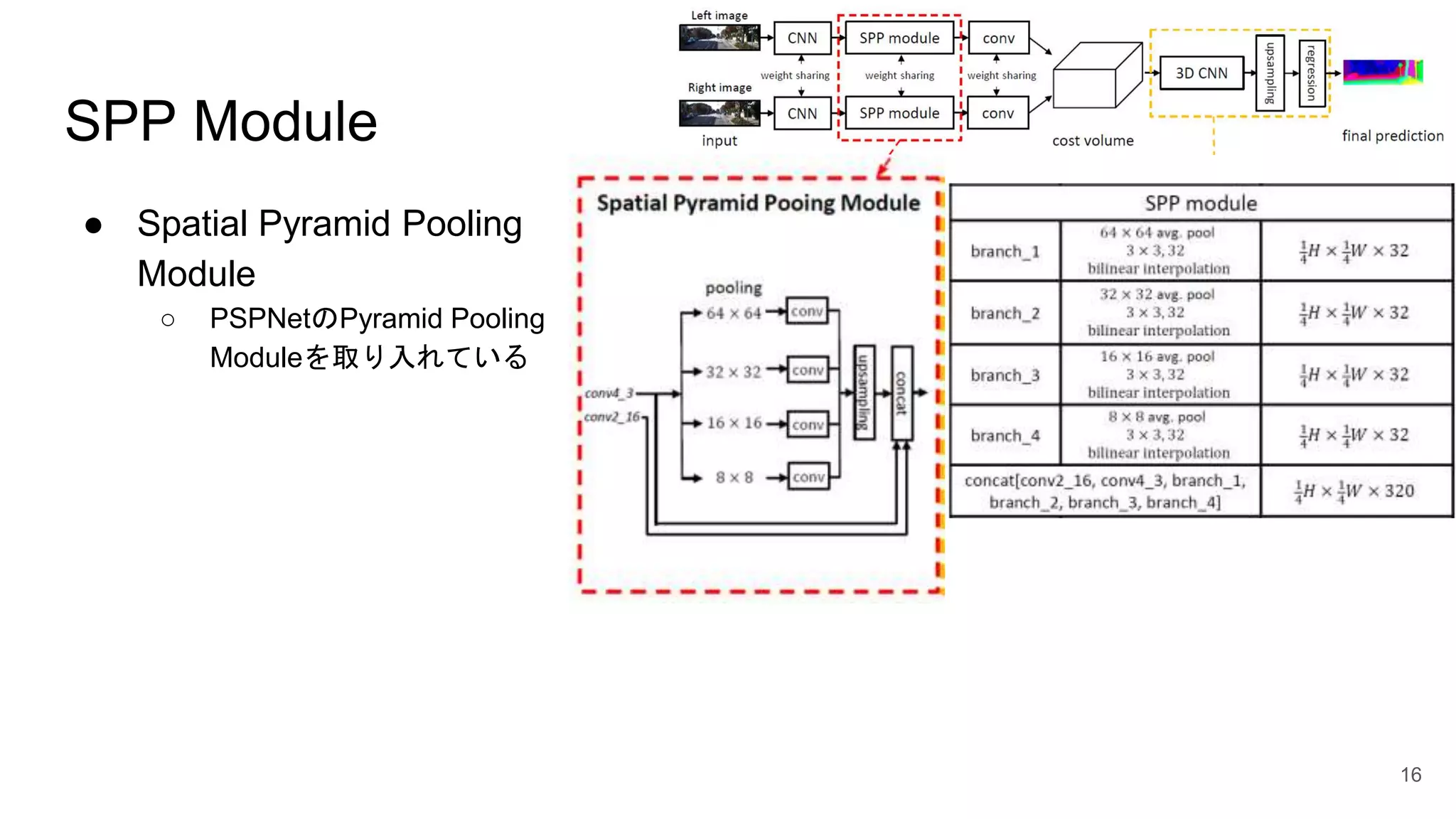
16.
SPP Module ● Spatial
Pyramid Pooling Module ○ PSPNetのPyramid Pooling Moduleを取り入れている 16
17.
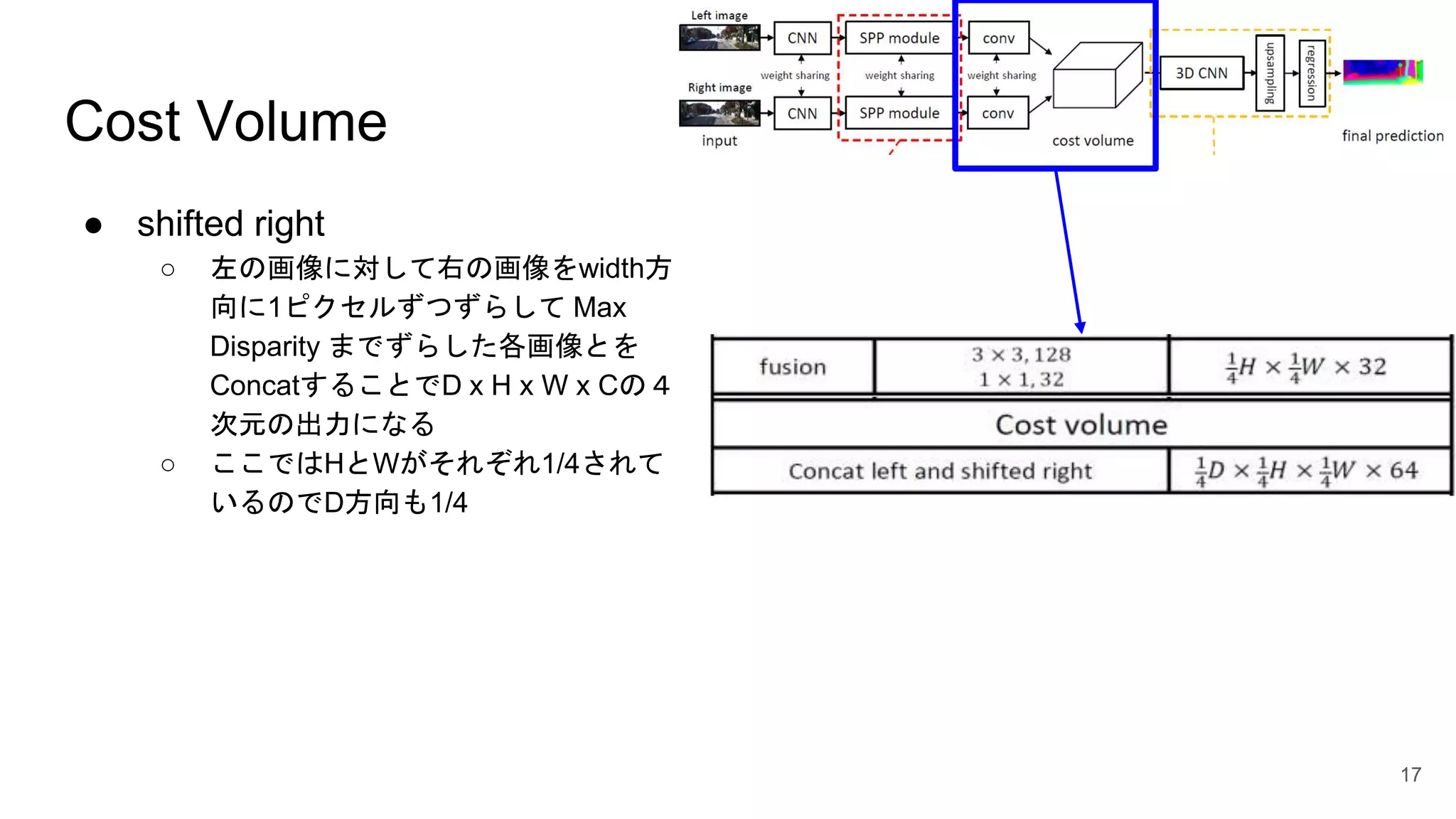
Cost Volume ● shifted
right ○ 左の画像に対して右の画像をwidth方 向に1ピクセルずつずらして Max Disparity までずらした各画像とを ConcatすることでD x H x W x Cの4 次元の出力になる ○ ここではHとWがそれぞれ1/4されて いるのでD方向も1/4 17
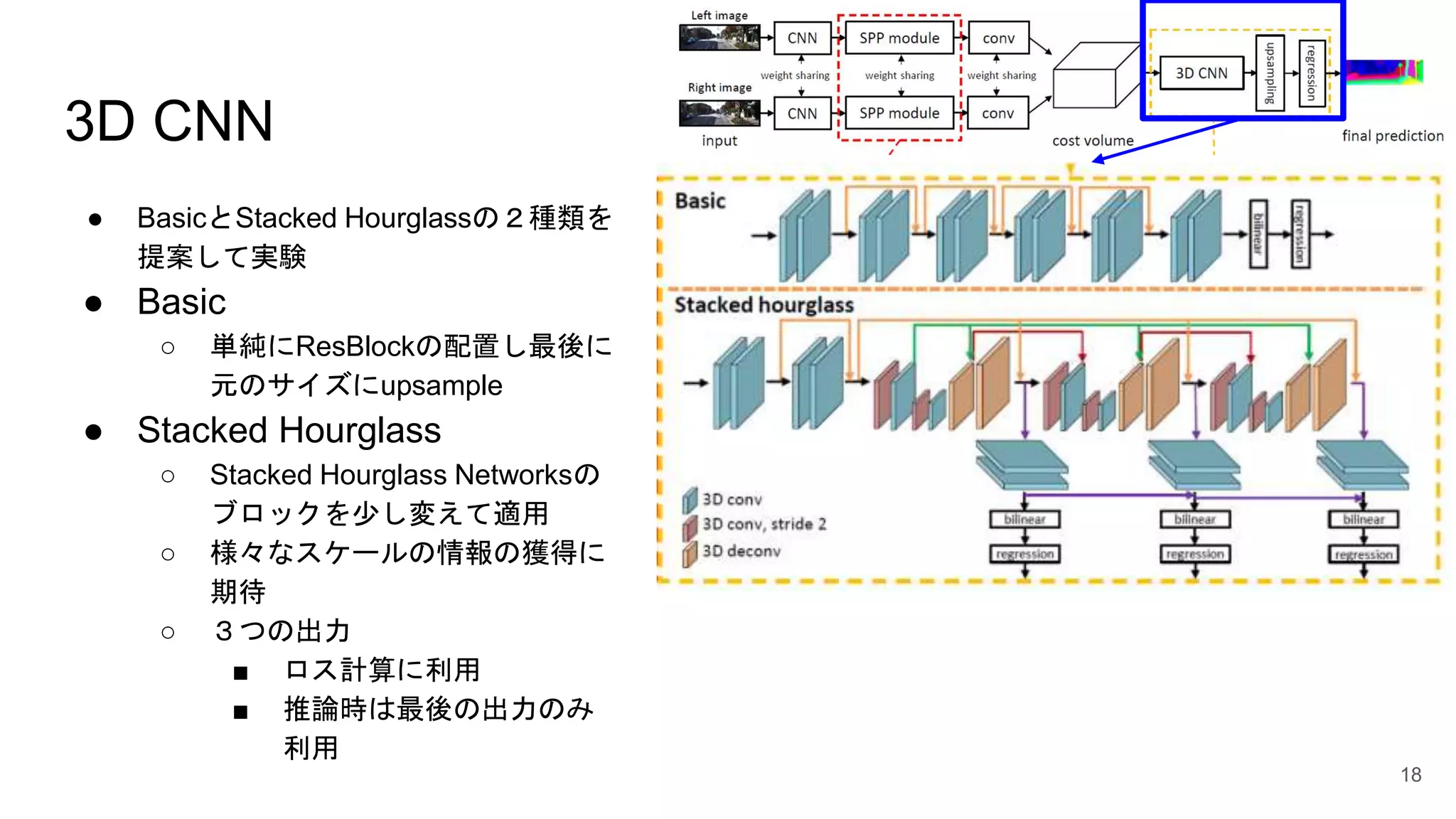
18.
3D CNN ● BasicとStacked
Hourglassの2種類を 提案して実験 ● Basic ○ 単純にResBlockの配置し最後に 元のサイズにupsample ● Stacked Hourglass ○ Stacked Hourglass Networksの ブロックを少し変えて適用 ○ 様々なスケールの情報の獲得に 期待 ○ 3つの出力 ■ ロス計算に利用 ■ 推論時は最後の出力のみ 利用 18
19.
Disparity Regression ● regressionに渡される出力
は各disparity(d)に対するコストを表す ● σはソフトマックス関数 ● 以下のような重み積で表すことで連続的な出力が得られる ● クラス分類で表すよりロバスト性があるらしい (※) 19 - ※ [1703.04309] End-to-End Learning of Geometry and Context for Deep Stereo Regression : https://arxiv.org/abs/1703.04309
20.
Loss ● Smooth L1 ○
外れ値に対してロバスト性があり,物体検出のBoundingBoxのLossでも使われている 20
21.
● 実験と結果 ○ データセット ○
学習 ○ Stacked Hourglassの実験 ○ Lossの比重を変えた実験 ○ KITTIの結果 21
22.
データセット ● Scene Flow
… シミュレーションから生成されたデータセット ○ H = 540, W = 960 の画像 ○ train : 35,454枚, test: 4370枚 ○ 密なDensity MapのGT (Ground Truth) ● KITTI 2015 … 自動車ビジョンデータセット ○ H = 376, W = 1240 の画像 ○ train : 200枚 → 80% (train), 20% (validation) ○ LiDARによって取得した疎なDensity MapのGT ● KITTI 2012 ○ H = 376, W = 1240 の画像 ○ train : 194枚 → 160枚 (train), 34枚 (validation) ○ LiDARによって取得した疎なDensity MapのGT 22
23.
学習 ● 画像中からランダムに H=256,
W=512 を切り出して学習 ● OptimizerにAdamを使用 ● maximum disparity (D) を 192 と指定 ● Scene Flowに対して10エポック学習. (そのままScene Flowの評価に使用) ● Scene Flowで学習したものをKITTIデータセットを用いてfine-tuning (100エポック) 23
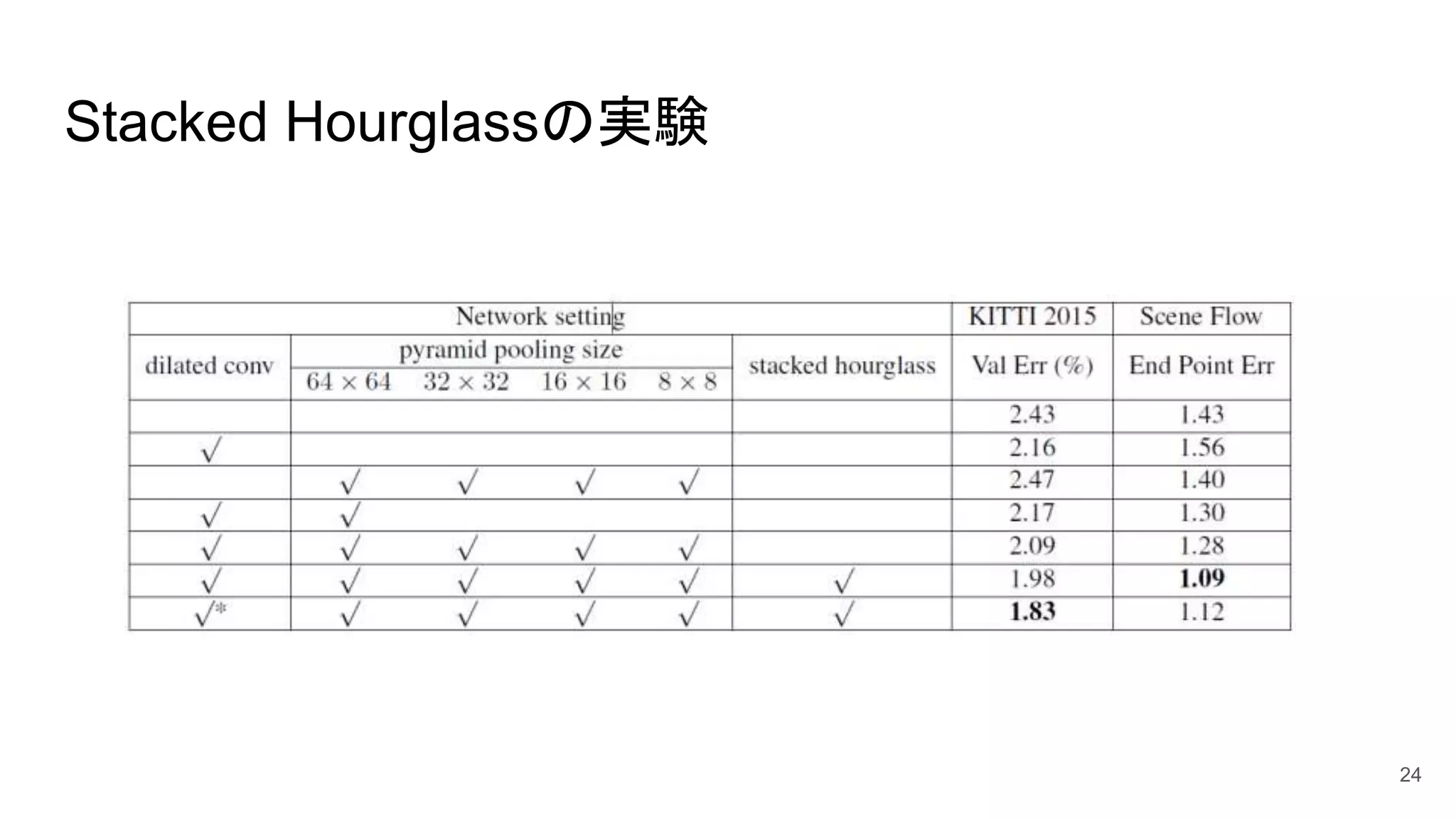
24.
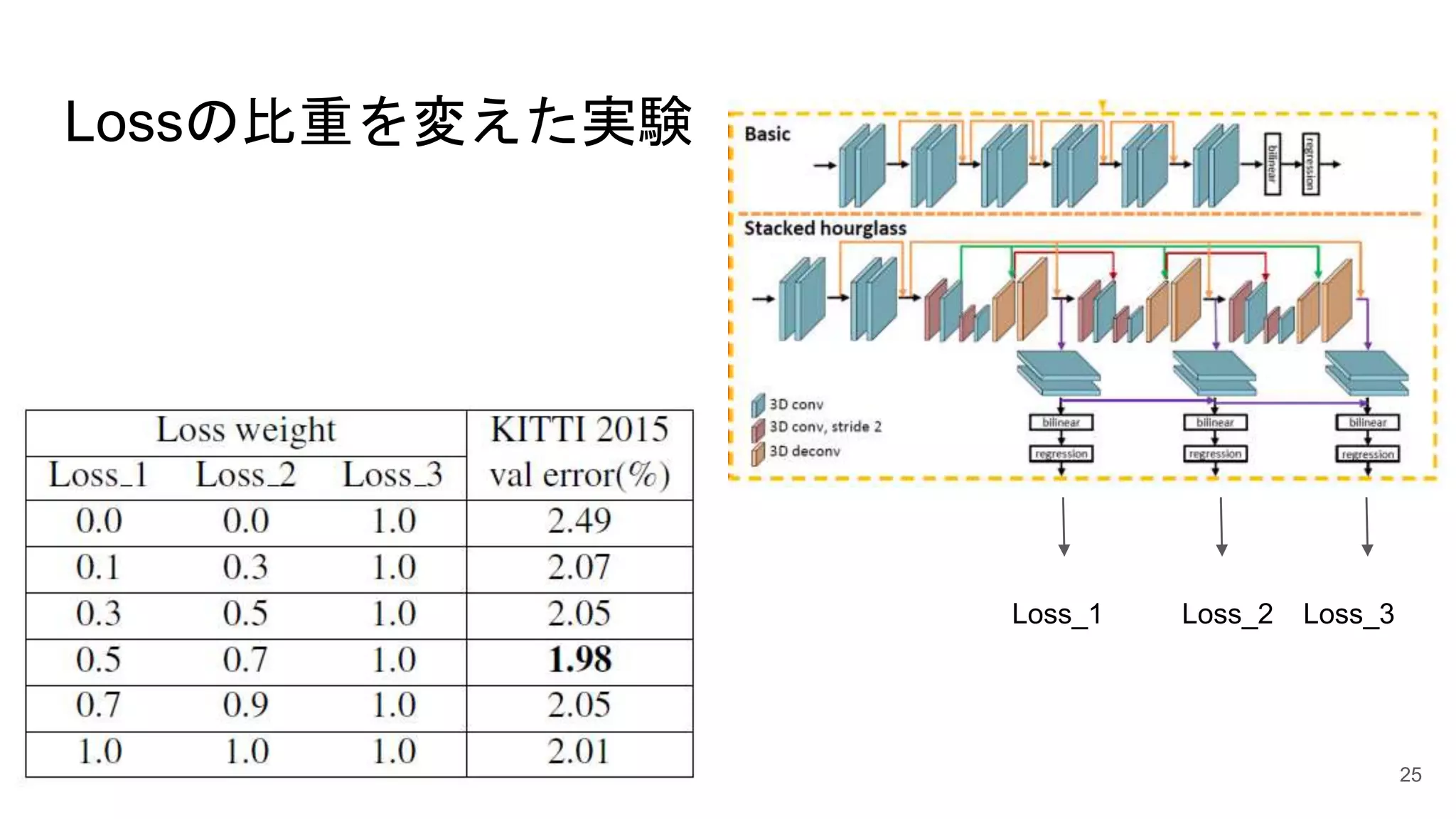
Stacked Hourglassの実験 24
25.
Lossの比重を変えた実験 25 Loss_1 Loss_2 Loss_3
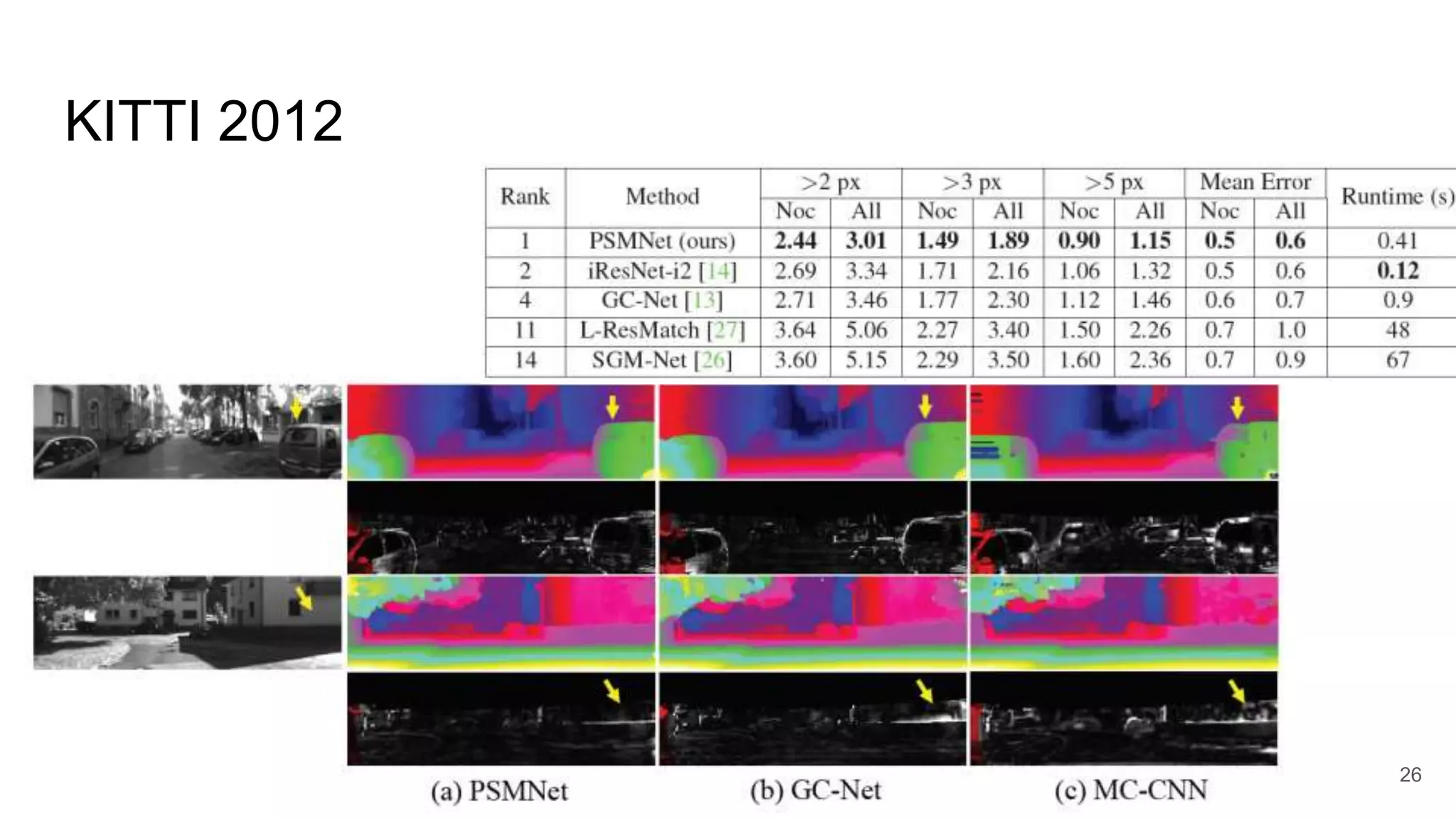
26.
KITTI 2012 26
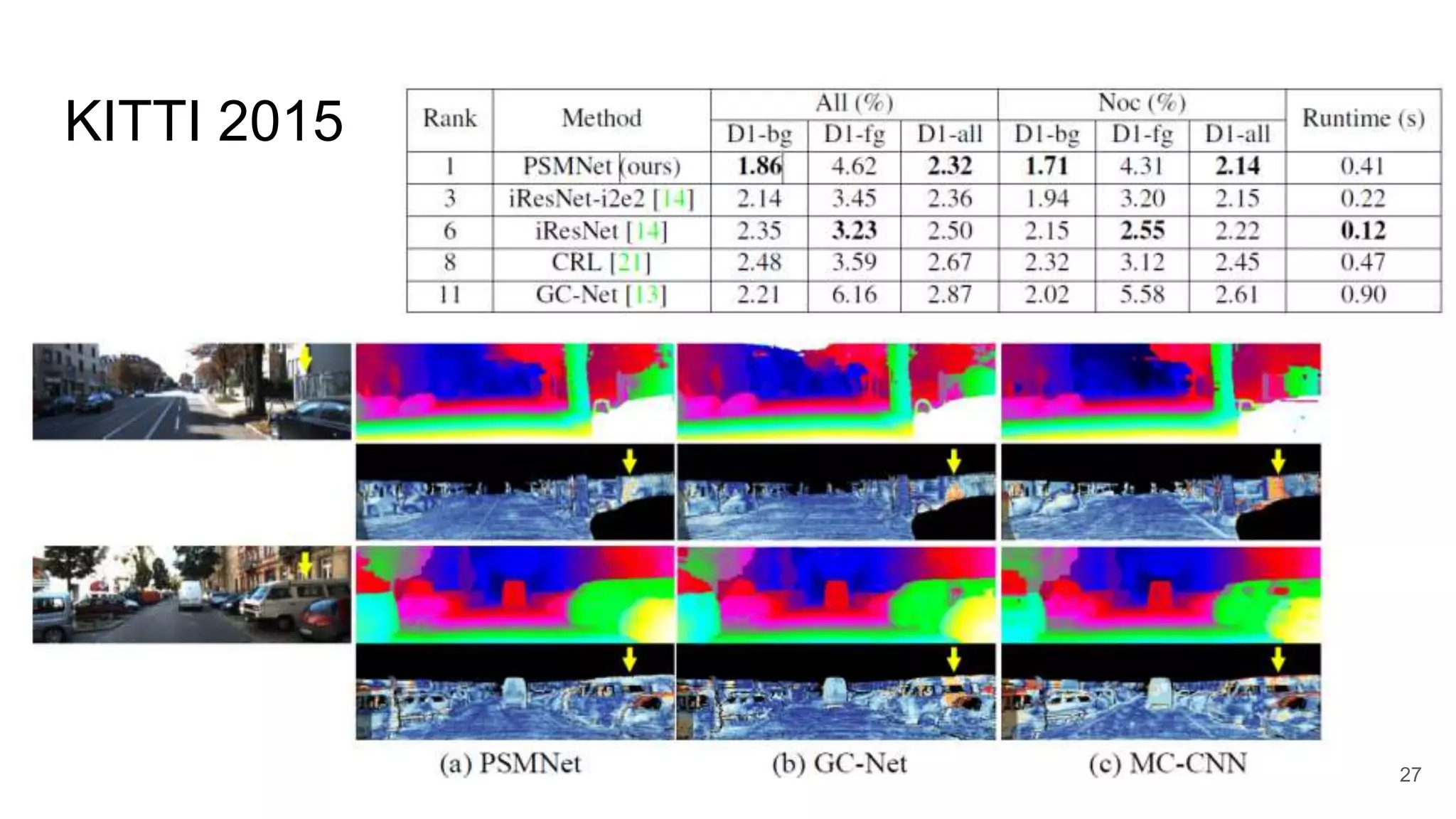
27.
KITTI 2015 27
28.
結論 ● SPPとDilated convolutionを用いることでピクセルレベルから異なるスケール の領域ごとの情報を取得 ●
Stacked Hourglass 3D CNNにおけるtop-down/bottom-up方式でglobal context の獲得に寄与 28
Editor's Notes
#7
https://ja.wikipedia.org/wiki/%E3%82%B9%E3%83%86%E3%83%AC%E3%82%AA%E3%82%AB%E3%83%A1%E3%83%A9 http://vision.middlebury.edu/stereo/data/scenes2003/
#8
http://vision.middlebury.edu/stereo/data/scenes2003/
Download








![PSPNet (Pyramid Scene Parsing Network)
● Pyramid Pooling Module
○ 処理の流れ
■ → SPPのプーリング
■ → 各スケールごとに1x1のConvフィルタに通すことでチャネル方向を圧縮
■ → プーリング前のサイズにupsample
○ 各スケールの内包関係などの階層的情報を伝達
11
- [1612.01105] Pyramid Scene Parsing Network : https://arxiv.org/abs/1612.01105](https://image.slidesharecdn.com/2019-05-31psmnetpyramidstereomatchingnetwork-hiroakisugisaki-190531000258/75/DL-Pyramid-Stereo-Matching-Network-11-2048.jpg)
![Stacked Hourglass Networks
● Hourglassデザイン
○ 様々なスケールにおける情報を取得するモチベーション
○ Human Pose Estimationで体の部位の関係を取得するのに利用
12- [1603.06937] Stacked Hourglass Networks for Human Pose Estimation : https://arxiv.org/abs/1603.06937](https://image.slidesharecdn.com/2019-05-31psmnetpyramidstereomatchingnetwork-hiroakisugisaki-190531000258/75/DL-Pyramid-Stereo-Matching-Network-12-2048.jpg)

![Disparity Regression
● regressionに渡される出力 は各disparity(d)に対するコストを表す
● σはソフトマックス関数
● 以下のような重み積で表すことで連続的な出力が得られる
● クラス分類で表すよりロバスト性があるらしい (※)
19
- ※ [1703.04309] End-to-End Learning of Geometry and Context for Deep Stereo Regression : https://arxiv.org/abs/1703.04309](https://image.slidesharecdn.com/2019-05-31psmnetpyramidstereomatchingnetwork-hiroakisugisaki-190531000258/75/DL-Pyramid-Stereo-Matching-Network-19-2048.jpg)






![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/20220121gudalin-220121050547-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Mask TextSpotter v3: Segmentation Proposal Network for Robust Scene Te...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023deeplearningjpyokota3-201023031708-thumbnail.jpg?width=640&height=640&fit=bounds)






























