Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PDF, PPTX
493 views
【DL輪読会】“PanopticDepth: A Unified Framework for Depth-aware Panoptic Segmentation (CVPR 2022)”
2022/8/5 Deep Learning JP http://deeplearning.jp/seminar-2/
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PDF
[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...
by
Deep Learning JP
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PDF
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
PPTX
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...
by
Deep Learning JP
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
What's hot
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
PDF
Generating Diverse High-Fidelity Images with VQ-VAE-2
by
harmonylab
PDF
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PDF
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
PPTX
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
PDF
(DL輪読)Matching Networks for One Shot Learning
by
Masahiro Suzuki
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
PDF
多様な強化学習の概念と課題認識
by
佑 甲野
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
Generating Diverse High-Fidelity Images with VQ-VAE-2
by
harmonylab
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
(DL輪読)Matching Networks for One Shot Learning
by
Masahiro Suzuki
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
多様な強化学習の概念と課題認識
by
佑 甲野
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
機械学習モデルの判断根拠の説明
by
Satoshi Hara
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
Similar to 【DL輪読会】“PanopticDepth: A Unified Framework for Depth-aware Panoptic Segmentation (CVPR 2022)”
PDF
論文紹介:Task-aligned Part-aware Panoptic Segmentation through Joint Object-Part ...
by
Toru Tamaki
PPTX
[DL輪読会]Deep Face Recognition: A Survey
by
Deep Learning JP
PDF
論文紹介:Video Panoptic Segmentation
by
Toru Tamaki
PDF
論文紹介:Panoptic-aware Image-to-Image Translation
by
Toru Tamaki
PDF
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
PPTX
[論文解説]Unsupervised monocular depth estimation with Left-Right Consistency
by
Ryutaro Yamauchi
PDF
[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
by
Deep Learning JP
PPTX
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unk...
by
Kazuyuki Miyazawa
論文紹介:Task-aligned Part-aware Panoptic Segmentation through Joint Object-Part ...
by
Toru Tamaki
[DL輪読会]Deep Face Recognition: A Survey
by
Deep Learning JP
論文紹介:Video Panoptic Segmentation
by
Toru Tamaki
論文紹介:Panoptic-aware Image-to-Image Translation
by
Toru Tamaki
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
[論文解説]Unsupervised monocular depth estimation with Left-Right Consistency
by
Ryutaro Yamauchi
[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
by
Deep Learning JP
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unk...
by
Kazuyuki Miyazawa
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】“PanopticDepth: A Unified Framework for Depth-aware Panoptic Segmentation (CVPR 2022)”
1.
DEEP LEARNING JP [DL
Papers] “PanopticDepth: A Unified Framework for Depth-aware Panoptic Segmentation (CVPR 2022)” Yoshifumi Seki http://deeplearning.jp/
2.
書誌情報 ● 投稿先 ○ CVPR
2022 ● 投稿者 ○ 後で ● 選定理由 ○ 最近画像認識周りを転職先の仕事も あって勉強し始めていて Panoptic Segmentation周りを今掘っていたとこ ろだった ○
3.
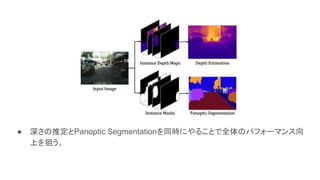
● 深さの推定とPanoptic Segmentationを同時にやることで全体のパフォーマンス向 上を狙う。
4.
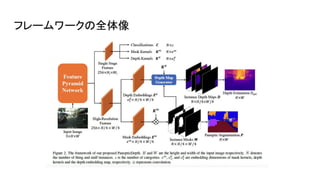
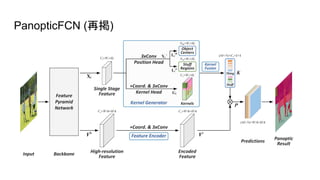
フレームワークの全体像
5.
フレームワークは3つのsub-networkからなる ● Kernel Producer ○
instance classification, instance-specific mask, depth convolution kernelを生み出すところ ● Panoptic Segmentation ○ Panoptic Segmentationをやるところ ● Instance-wise depth map generator ○ インスタンスごとの深さ推定をやるところ
6.
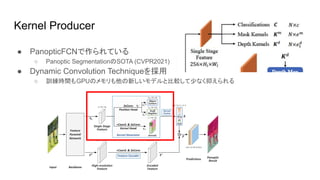
Kernel Producer ● PanopticFCNで作られている ○
Panoptic SegmentationのSOTA (CVPR2021) ● Dynamic Convolution Techniqueを採用 ○ 訓練時間もGPUのメモリも他の新しいモデルと比較して少なく抑えられる
7.
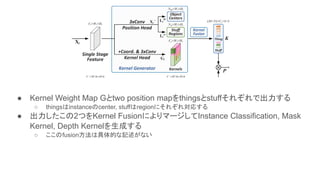
● Kernel Weight
Map Gとtwo position mapをthingsとstuffそれぞれで出力する ○ thingsはinstanceのcenter, stuffはregionにそれぞれ対応する ● 出力したこの2つをKernel FusionによりマージしてInstance Classification, Mask Kernel, Depth Kernelを生成する ○ ここのfusion方法は具体的な記述がない
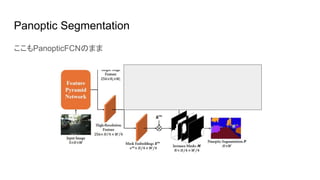
8.
Panoptic Segmentation ここもPanopticFCNのまま
9.
PanopticFCN (再掲)
10.
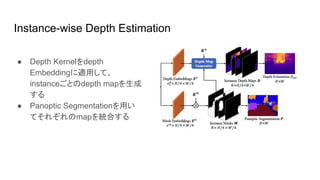
Instance-wise Depth Estimation ●
Depth Kernelをdepth Embeddingに適用して、 instanceごとのdepth mapを生成 する ● Panoptic Segmentationを用い てそれぞれのmapを統合する
11.
Depth Map Generator ●
depth Kernelとdepth Embeddingによってdepth mapを生成 ● 各instance maskにおいて、depthの分布を正規化する ○ dmaxは今回の実験データセットでは 88にこてい ○ d_r: depth range: N+1次元 ○ d_s: depth shift: N+1次元 ● ニュアンスとしては、depthのbiasとvarianceを表現している ● このように生成したDとMを掛け合わせて統合
12.
Depth Loss ● logarithmic
errorとRSEの組み合わせ ● Pixel LevelのLossとInstance LevelのLossを組み合わせる
13.
実装上の工夫 ● Adaptive Kernel
Fusion (AKS) ○ Kernel Fusionのタイミングにおける Average Clusterの改良 ● Full Scale Fine Tuning (FSFT) ○ 距離が離れたインスタンス同士が融合してしまうことを発見 ■ image cloppingによっておこる ○ 類似の問題が怒っている他の研究では、 original imageで訓練することで対応するが、 GPUメモリ をめちゃめちゃに使ってしまう ○ Fine tuningの時のみFull Imageを使ったfine-tuningを小さなbatch sizeで行うことで、この問題に対 応
14.
評価指標 Panoptic Quality Depth-awareなPanoptic Quality λはしきい値、Pλはλよりerrorが小さいピクセルのみを考慮する λの値を{0.1,
0.25, 0.5}でそれぞれ計算した時の平均を取る
16.
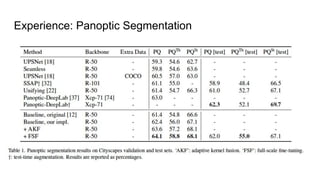
Experience: Panoptic Segmentation
17.
● ViP-DeepLabは現在公開されている唯一のDepth-awareなPanoptic Segmentationなモデル ● 精度は及ばなかったが、Vip-DeepLabは大規模な追加データセット、半教師、 AutoAug,
Test-time segmentationというテクニックが採用されている ○ こういうのを採用すれば伸びるのでは?
18.
Monocular Depth Estimation ●
シンプルな単眼画像による深さ 推定では、提案手法が最も良い 結果となった ● 深さを推定するのにinstan ●
19.
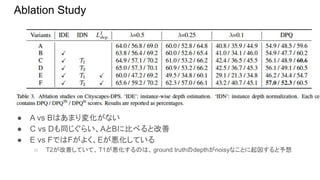
Ablation Study ● A
vs Bはあまり変化がない ● C vs Dも同じぐらい、AとBに比べると改善 ● E vs FではFがよく、Eが悪化している ○ T2が改善していて、T1が悪化するのは、ground truthのdepthがnoisyなことに起因すると予想
21.
まとめ ● おそらく単眼深度における精度向上が工夫されての採択? ● 数式が省略されているところが多くて追い辛い ○
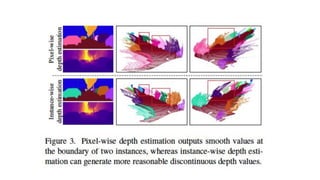
特にkernelの部分、これで通すのかぁというカルチャーショック ○ 実装は公開されている ○ arxivにappendixとかあるのかな、と思ったけどなかった ● 精度の改善ポイントとしては局所的なnormalizedが一番効いているのは面白い ● Boundaryがなめらかになってるでしょ?と言われてもよくわからなかった ○ 画像処理に精通するとわかるようになるのか
Download
![DEEP LEARNING JP
[DL Papers]
“PanopticDepth: A Unified Framework for Depth-aware
Panoptic Segmentation
(CVPR 2022)” Yoshifumi Seki
http://deeplearning.jp/](https://image.slidesharecdn.com/20220805dl-220809035005-f38b1c5d/85/DL-PanopticDepth-A-Unified-Framework-for-Depth-aware-Panoptic-Segmentation-CVPR-2022-1-320.jpg)
![DEEP LEARNING JP
[DL Papers]
“PanopticDepth: A Unified Framework for Depth-aware
Panoptic Segmentation
(CVPR 2022)” Yoshifumi Seki
http://deeplearning.jp/](https://image.slidesharecdn.com/20220805dl-220809035005-f38b1c5d/75/DL-PanopticDepth-A-Unified-Framework-for-Depth-aware-Panoptic-Segmentation-CVPR-2022-1-2048.jpg)










![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)



![[論文解説]Unsupervised monocular depth estimation with Left-Right Consistency](https://cdn.slidesharecdn.com/ss_thumbnails/unsupervisedmonoculardepthestimation-170809092538-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning](https://cdn.slidesharecdn.com/ss_thumbnails/slidev2reduced-190422065109-thumbnail.jpg?width=640&height=640&fit=bounds)




















