参考⽂献:1
[van den Oord+2016] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N.
Kalchbrenner, A. W. Senior, K. Kavukcuoglu, “WaveNet: a generative model for raw audio,” arXiv preprint,
arXiv:1609.03499, 15 pages, 2016.
[Tamamori+ 2017] A. Tamamori, T. Hayashi, K. Kobayashi, K. Takeda, T. Toda, “Speaker-dependent
WaveNet vocoder,” Proc. INTERSPEECH, pp. 1118‒1122, 2017.
[Itakura+ 1968] F. Itakura, S. Saito, “Analysis synthesis telephony based upon the maximum likelihood
method,” Proc. ICA, C-5-5, pp. C17‒20, 1968.
[van den Oord+ 2017] A. van den Oord, Y. Li, I. Babuschkin, K. Simonyan, O. Vinyals, K. Kavukcuoglu, G. van
den Driessche, E. Lockhart, L.C. Cobo, F. Stimberg, N. Casagrande, D. Grewe, S. Noury, S. Dieleman, E. Elsen,
N. Kalchbrenner, H. Zen, A. Graves, H. King, T. Walters, D. Belov, D. Hassabis, “Parallel WaveNet: fast high-
fidelity speech synthesis,” arXiv preprint, arXiv:1711.10433, 11 pages, 2017.
[Yamamoto+ 2020] R. Yamamoto, E. Song, J.-M. Kim, “Parallel WaveGAN: A fast waveform generation
model based on generative adversarial networks with multi-resolution spectrogram,” Proc. IEEE ICASSP, pp.
6199‒6203, 2020.
[Wang+ 2019] X. Wang, S. Takaki J. Yamagishi, “Neural source-filter waveform models for statistical
parametric speech synthesis,” IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 28, pp. 402‒415, 2019.
[Schroeder+ 1985] M. Schroeder, B. Atal, “Code-excited linear prediction (CELP): high-quality speech at
very low bit rates,” Proc. IEEE ICASSP, pp. 937‒940, 1985.
[Wu+ 2021a] Y.-C. Wu, T. Hayashi, T. Okamoto, H. Kawai, T. Toda, “Quasi-periodic parallel WaveGAN: a
non-autoregressive raw waveform generative model with pitch-dependent dilated convolution neural
network,” IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 29, pp. 792‒806, 2021.
[Wu+ 2021b] Y.-C. Wu, T. Hayashi, T. Okamoto, H. Kawai, T. Toda, “Quasi-periodic WaveNet: an
autoregressive raw waveform generative model with pitch-dependent dilated convolution neural network,”
IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 29, pp. 1134‒1148, 2021.
参考⽂献
42.
参考⽂献:2
[Yoneyama+ 2023a] R.Yoneyama, Y.-C. Wu, T. Toda, “High-fidelity and pitch-controllable neural vocoder
based on unified source-filter networks,” IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 31, pp.
3717‒3729, 2023.
[Yoneyama+ 2023b] R. Yoneyama, Y.-C. Wu, T. Toda, “Source-Filter HiFiGAN: fast and pitch controllable
high-fidelity neural vocoder,” Proc. IEEE ICASSP, 5 pages, 2023.
[Yamagishi+ 2019] J. Yamagishi, C. Veaux, K. MacDonald, “CSTR VCTK Corpus: English multi-speaker
corpus for CSTR voice cloning toolkit (version 0.92),” https://doi.org/10.7488/ds/2645, University of
Edinburgh. The Centre for Speech Technology Research (CSTR), 2019.
[Kong+ 2020] J. Kong, J. Kim, J. Bae, “HiFi-GAN: generative adversarial networks for efficient and high
fidelity speech synthesis,” Proc. NeurIPS, pp. 17022‒17033, 2020.
[Matsubara+ 2023] K. Matsubara, T. Okamoto, R. Takashima, T. Takiguchi, T. Toda, H. Kawai, “Harmonic-
Net: fundamental frequency and speech rate controllable fast neural vocoder,” IEEE/ACM Trans. Audio,
Speech & Lang. Process., Vol. 31, pp. 1902‒1915, 2023.
[Ogita+ 2025] K. Ogita, R. Yoneyama, W.-C. Huang, T. Toda, “VAE-SiFiGAN: source-filter HiFi-GAN based
on variational autoencoder representations with enhanced pitch controllability,” Proc. EUSIPCO, 5 pages,
2025 (in press).
[Canon 2021] Canon, “NamineRitsu Singing DB Ver.2,”
https://drive.google.com/drive/folders/1XA2cm3UyRpAk_BJb1LTytOWrhjsZKbSN, 2021.
[Kaneko+ 2022] T. Kaneko, K. Tanaka, H. Kameoka, S. Seki, “iSTFTNet: Fast and lightweight mel-
spectrogram vocoder incorporating inverse short-time Fourier transform,” Proc. IEEE ICASSP, pp. 6207‒6211,
2022.
[Yoneyama+ 2024] R. Yoneyama, A. Miyashita, R. Yamamoto, T. Toda, “Wavehax: aliasing-free neural
waveform synthesis based on 2D convolution and harmonic prior for reliable complex spectrogram
estimation,” arXiv preprint, arXiv:2411.06807, 13 pages, 2024.
[Pantazis+ 2011] Y. Pantazis, O. Rosec, and Y. Stylianou, “Adaptive AM-FM signal decomposition with
application to speech analysis,” IEEE Trans. Audio, Speech & Lang. Process., Vol. 19, No. 2, pp. 290‒300,
2011.
43.
参考⽂献:3
[Chen+ 2025a] S.Chen, T. Toda, “Sequence-wise speech waveform modeling via gradient descent
optimization of quasi-harmonic parameters,” IEEE Trans. Audio, Speech & Lang. Process., Vol. 33, pp. 319‒
332, 2025.
[Chen+ 2025b] S. Chen, T. Toda, “QHARMA-GAN: Quasi-harmonic neural vocoder based on autoregressive
moving average model,” arXiv preprint, arXiv: 2507.01611, 16 pages, 2025.
[Takamichi+ 2019] S. Takamichi, K. Mitsui, Y. Saito, T. Koriyama, N. Tanji, H. Saruwatari, “JVS corpus: free
Japanese multi-speaker voice corpus,” arXiv preprint, arXiv: 1908.06248, 4 pages, 2019.
[Huang+ 2021] R. Huang, F. Chen, Y. Ren, J. Liu, C. Cui, Z. Zhao, “Multi-Singer: fast multi-singer singing
voice vocoder with a large-scale corpus,” Proc. ACM Multimedia, pp. 3945‒3954, 2021.

![ふと思い返してみると・・・
• 2016年9⽉にWaveNet [van den Oord+ 2016] が登場
• 衝撃を受けてすぐにニューラルボコーダの研究を開始
• INTERSPEECH 2017にてWaveNetボコーダを発表 [Tamamori+ 2017]
• 2018年1⽉に⾳声研究会にて招待講演を実施
専⾨知識を活かして改善できる
可能性はあると思います!
あれから7〜8年
経ったがはたして?
はじめに](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-2-320.jpg)

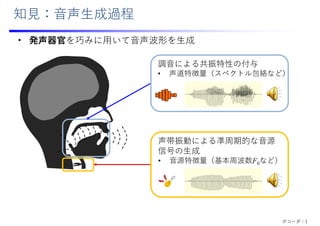
![知⾒:信号処理に基づくボコーダ
• ソースフィルタモデル:⾳声⽣成過程を信号処理で数理的に表現
• ⾳声特徴量の操作による合成⾳声波形の加⼯が容易
⾳源波形
𝑒 𝑛
パルス列信号 雑⾳信号
合成⾳声波形
𝑥 𝑛 ℎ 𝑛 ∗ 𝑒 𝑛
合成フィルタ
𝐻 𝑧
𝐺
1 ∑ 𝑎 𝑧
⾳源⽣成部
調⾳部
スペクトル包絡系列
(共振特性)
F0パターン
(声の⾼さ,有声/無声)
時間
周波数
周波数
パワー
時間
[Itakura+ 1968]
ボコーダ:2](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-5-320.jpg)
![𝑥 ~ 𝑝 𝑥 |𝑥 , … , 𝑥
深層学習に基づくボコーダ
• ニューラルボコーダ:⾳声特徴量から⾳声波形への変換を学習
• 深層ネットワークによる⾳声波形サンプルの同時分布モデリング
• ソースフィルタモデルの近似を避けることで⾼品質化
深層
ネットワーク
⾳声データ
合成⾳声波形
𝑥
𝑥
⼊⼒層
𝑥
第1隠れ層
𝑥
𝑥
𝑥
𝑥
第2隠れ層
Dilation幅 1
Dilation幅 2
𝑥
第3隠れ層
Dilation幅 4
WaveNet [van den Oord+ 2016]
• 拡張畳み込みによる⾃⼰回帰モデリング
⾳声特徴量
系列
[van den Oord+ 2016]
ボコーダ:3](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-6-320.jpg)
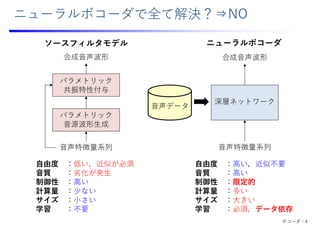
![ニューラルボコーダの発展(⼀部のみ)
HN-uSFGAN
[Yoneyama+ 2023a]
SiFiGAN
[Yoneyama+ 2023b]
Parallel
WaveGAN (PWG)
[Yamamoto+ 2020]
QPPWG
[Wu+ 2021a]
HiFiGAN
[Kong+ 2020]
HarmonicNet+
[Matsubara+ 2023]
Parallel WaveNet
[van den Oord+ 2017]
F0依存畳み込み
Neural Source
Filter (NSF)
[Wang 2019]
F0制御
⾳源
敵対的学習
アップサンプ
リング
• F0制御⾳源
• F0依存畳み込み
⾳源正則化 ⾳源正則化
⾼速化
⾼制御化
時間周波数
表現
iSTFTNet
[Kaneko+ 2022]
Wavehax
[Yoneyama+ 2024]
• F0制御⾳源
• 2D畳み込み
QH-ARMAGAN
[Chen+ 2025b]
BP-QHM
[Chen+ 2025a]
QHM
[Pantazis+ 2011]
分析機能
系列最適化 • 敵対的学習
• 特徴抽出ネット
• 包絡モデル
⾮⾃⼰回帰型
敵対的学習
ニューラルボコーダの発展](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-8-320.jpg)
![SiFiGAN
[Yoneyama+ 2023b]
HarmonicNet+
[Matsubara+ 2023]
アップサンプ
リング
ニューラルボコーダの発展(⼀部のみ)
HN-uSFGAN
[Yoneyama+ 2023a]
Parallel
WaveGAN (PWG)
[Yamamoto+ 2020]
QPPWG
[Wu+ 2021a]
HiFiGAN
[Kong+ 2020]
Parallel WaveNet
[van den Oord+ 2017]
F0依存畳み込み
Neural Source
Filter (NSF)
[Wang 2019]
F0制御
⾳源
敵対的学習
• F0制御⾳源
• F0依存畳み込み
⾳源正則化 ⾳源正則化
⾼速化
⾼制御化
時間周波数
表現
iSTFTNet
[Kaneko+ 2022]
Wavehax
[Yoneyama+ 2024]
• F0制御⾳源
• 2D畳み込み
QH-ARMAGAN
[Chen+ 2025b]
BP-QHM
[Chen+ 2025a]
QHM
[Pantazis+ 2011]
分析機能
系列最適化 • 敵対的学習
• 特徴抽出ネット
• 包絡モデル
⾮⾃⼰回帰型
敵対的学習
時間領域処理型](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-9-320.jpg)
![時間領域⾮⾃⼰回帰型ニューラルボコーダ
• Parallel WaveGAN (PWG) [Yamamoto+ 2020]
• 敵対的学習の導⼊で⾮⾃⼰回帰型ネットワークの学習を実現
• 同時サンプリングによる⾼速な合成処理を達成
拡張畳み込み
雑⾳信号
合成⾳声波形
識別器
⾳声特徴量
系列
敵対的損失と誤差損失を利⽤
誤差損失
時間領域⾮線形処理により
雑⾳信号を加⼯: 𝒙 𝑓 𝒛
雑⾳信号をサンプリング:𝒛 ~ 𝒩 𝟎, 𝑰
時間領域処理型:1](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-10-320.jpg)
![ソースフィルタモデルの導⼊
• Neural Source Filter (NSF) [Wang+ 2019]
• 𝐹 に応じた正弦波も⼊⼒
• 𝐹 制御性能を改善
拡張畳み込み
合成⾳声波形
⾳声特徴量
系列
誤差損失
正弦波 雑⾳信号
所望の𝐹 パターンを持つ
パラメトリック⾳源信号を⽣成
時間領域⾮線形処理により
⾳源信号を加⼯
𝐹 パターンが保持される傾向あり!
(その理由については後述)
時間領域処理型:2](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-11-320.jpg)
![𝜔
知⾒:⾳声符号化における⾳源モデリング
• CELPの⻑期予測(ピッチフィルタ)[Schroeder+ 1985]
• ⾳源波形を⽣成するための⾃⼰回帰モデル
• 調波構造を付与
n
𝑦 𝑛
𝑦 𝑛 𝑝
𝑝点離れた値から予測
𝐻 𝑧
1
ピッチフィルタ
𝐻 𝑧
1
1 𝑎𝑧
合成フィルタ
𝐻 𝑧
𝑔
1 ∑ 𝑎 𝑧
⾳源信号
誤差信号
n
𝑦 𝑛
𝑦 𝑛 𝐷
過去𝐷点の値から予測
調波構造(微細構造)を付与
共振特性(包絡)を付与
𝜔
時間領域処理型:3](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-12-320.jpg)
![依存畳み込み層の導⼊
• F0依存拡張畳み込み層 [Wu+ 2021b]
• F0パターンに基づきDilation幅を動的に制御
• QPPWG (Quasi-Periodic PWG) [Wu+ 2021a]
• 拡張畳み込みネットワークを⾳源波形⽣成部と共振特性付与部に分解
• F0依存拡張畳み込み層による⾳源波形⽣成
• 固定拡張畳み込み層による共振特性付与
𝑇
3
𝑇
2
𝑇
2
𝑇
2
𝑇
1
𝑇
3
𝑇
1
𝑇
1
𝑇 1/𝐹 ,
基本周期:
𝑥
𝑥
⼊⼒層
𝑥
第1隠れ層
𝑥
𝑥 𝑥
𝑥
𝑥
第2隠れ層
Dilation幅 𝑇
Dilation幅 2𝑇
基本周期に応じて
受容野が時々刻々と
動的に変化
時間領域処理型:4](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-13-320.jpg)
![拡張畳み込みネットワークの挙動分析
F0依存拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
F0依存拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
雑⾳信号
⾳声波形 ⾳声波形
雑⾳信号
⾳声波形
雑⾳信号
共振特性
付与
⾳源波形
⽣成
[Wu+ 2021a]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
出⼒層から
⽣成された
波形信号の
周波数特性
時間領域処理型:5](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-14-320.jpg)
![拡張畳み込みネットワークの挙動分析
F0依存拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
F0依存拡張畳み込み
ネットワーク
雑⾳源
⾳声波形 ⾳声波形
雑⾳源
⾳声波形
雑⾳源
共振特性
付与
⾳源波形
⽣成
[Wu+ 2021a]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
固定拡張畳み込み
ネットワーク
第5隠れ層
からの出⼒
波形信号の
周波数特性
時間領域処理型:5](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-15-320.jpg)
![拡張畳み込みネットワークの挙動分析
F0依存拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
F0依存拡張畳み込み
ネットワーク
雑⾳源
⾳声波形 ⾳声波形
雑⾳源
⾳声波形
雑⾳源
共振特性
付与
⾳源波形
⽣成
[Wu+ 2021a]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
固定拡張畳み込み
ネットワーク
第10隠れ層
からの出⼒
波形信号の
周波数特性
時間領域処理型:5](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-16-320.jpg)
![拡張畳み込みネットワークの挙動分析
F0依存拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
F0依存拡張畳み込み
ネットワーク
雑⾳源
⾳声波形 ⾳声波形
雑⾳源
⾳声波形
雑⾳源
共振特性
付与
⾳源波形
⽣成
第15隠れ層
からの出⼒
波形信号の
周波数特性
[Wu+ 2021a]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
固定拡張畳み込み
ネットワーク
時間領域処理型:5](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-17-320.jpg)
![拡張畳み込みネットワークの挙動分析
F0依存拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
固定拡張畳み込み
ネットワーク
F0依存拡張畳み込み
ネットワーク
雑⾳源
⾳声波形 ⾳声波形
雑⾳源
⾳声波形
雑⾳源
共振特性
付与
⾳源波形
⽣成
[Wu+ 2021a]
• ⾳源波形⽣成部と共振特性付与部にネットワークを分解可能
• F0制御性能(特に外挿精度)を改善
固定拡張畳み込み
ネットワーク
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
10
8
6
4
2
0
0 0.5 1.0 1.5 2.0 2.5
Times [s]
Frequency
[kHz]
出⼒層から
⽣成された
波形信号の
周波数特性
時間領域処理型:5](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-18-320.jpg)
![×
• 単⼀の敵対的⽣成ネットワークを⾳源⽣成部と共振付与部に分解
• ⾳源正則化損失により分解を促進
畳み込み
⾳源正則化損失
識別器
調⾳ネット
合成⾳声波形
⾳源⽣成部
正弦波
𝑭
周期⾳源
𝑭𝟎依存層
×
雑⾳信号
⾮周期⾳源
固定層
⾳声特徴量系列
周期成分
固定層
+
[Yoneyama+ 2023a]
共振
付与部
統合:HN-uSFGAN
⾳源波形
時間領域処理型:6](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-19-320.jpg)
![HN-uSFGANによるF0変換のデモ⾳声
1倍
2倍
4倍
8倍
16倍
1倍
1/2倍
1/4倍
収録⾳声
変換再合成⾳声
変換再合成⾳声
収録⾳声
学習に⽤いた通常発話のF0 範囲
30 Hz 4 kHz
70 Hz 340 Hz
• 約100名の英語話者の⾳声(VCTKコーパス [Yamagishi+ 2019])を⽤いて
学習されたHN-uSFGANを使⽤
時間領域処理型:7](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-20-320.jpg)
![Parallel WaveNet
[van den Oord+ 2017]
時間周波数
表現
QPPWG
[Wu+ 2021a]
iSTFTNet
[Kaneko+ 2022]
Wavehax
[Yoneyama+ 2024]
HN-uSFGAN
[Yoneyama+ 2023b]
F0依存畳み込み
⾳源正則化
アップサンプ
リング
ニューラルボコーダの発展(⼀部のみ)
SiFiGAN
[Yoneyama+ 2023b]
Parallel
WaveGAN (PWG)
[Yamamoto+ 2020]
HiFiGAN
[Kong+ 2020]
HarmonicNet+
[Matsubara+ 2023]
Neural Source
Filter (NSF)
[Wang 2019]
F0制御
⾳源
敵対的学習
• F0制御⾳源
• F0依存畳み込み
⾳源正則化
⾼速化
⾼制御化
• F0制御⾳源
• 2D畳み込み
QH-ARMAGAN
[Chen+ 2025b]
BP-QHM
[Chen+ 2025a]
QHM
[Pantazis+ 2011]
分析機能
系列最適化 • 敵対的学習
• 特徴抽出ネット
• 包絡モデル
⾮⾃⼰回帰型
敵対的学習
アップサンプリング型](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-21-320.jpg)
![アップサンプリング型ニューラルボコーダ
⾳声特徴量系列
合成⾳声波形
識別器
アップサンプリング
拡張畳み込み
• HiFiGAN [Kong+ 2020]
• 時間フレーム特徴量系列に対するアップサンプリングを通して
⾳声波形を⽣成
• 短い⻑さの系列を導⼊することで⾼速化を達成
誤差損失
アップサンプリング型:1](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-22-320.jpg)
![パラメトリック⾳源と 依存畳み込み層の導⼊
• HarmonicNet+ [Matsubara+ 2022]
• パラメトリック⾳源信号を導⼊するためにダウンサンプリングを活⽤
識別器
合成⾳声波形
パラメトリック⾳源信号
⾳声特徴量系列
アップ
サンプリング
𝐹 依存拡張
畳み込み層
Conv
Conv
Conv
Conv
Conv
𝐹 依存Conv
𝐹 依存Conv
𝐹 依存Conv
𝐹 依存Conv
Conv
Conv
ダウンサンプリング層
アップサンプリング型:2](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-23-320.jpg)
![• アップサンプリング型でF0制御と⾼速合成処理を実現
識別器
合成⾳声波形
パラメトリック⾳源信号
⾳声特徴量系列
𝐹
⾳源⽣成𝐹 依存
アップサンプリング
畳み込み
畳み込み
ダウン
サンプリング
共振付与
アップサンプリング
ダウン
サンプリング
畳み込み
畳み込み
⾳源波形
⾳源正則化損失
共振
付与部
⾳源⽣成部
統合:SiFiGAN (Source-filter HiFi GAN)
[Yoneyama+ 2023b]
アップサンプリング型:3](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-24-320.jpg)
![SiFiGANの改善:確率的潜在特徴抽出の導⼊
• VAE-SiFiGAN [Ogita+ 2025]
• メルスペクトログラムから確率的潜在特徴抽出
• 学習時にボコーダパラメータからの⾼精度な確率的潜在特徴を
事前知識として活⽤することで𝐹 分離を促進
確率的潜在特徴抽出部
揺らぎ成分を表現
共振特性に特化
学習処理
アップサンプリング型:4](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-25-320.jpg)
![VAE-SiFiGANによるF0変換⾳声
• 歌声データ(波⾳リツデータセット [Canon+ 2021])を⽤いて学習された
VAE-SiFiGANを利⽤
• 合成時にF0を変換
• 主観評価結果
• 被験者22⼈
確率的潜在特徴は
𝐹 変換精度を改善!
合成処理
合成歌声品質
⾼い
[Ogita+ 2025]
アップサンプリング型:5](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-26-320.jpg)
![アップサンプ
リング
SiFiGAN
[Yoneyama+ 2023a]
HarmonicNet+
[Matsubara+ 2022]
• F0制御⾳源
• F0依存畳み込み
⾳源正則化
時間周波数
表現
QPPWG
[Wu+ 2021a]
iSTFTNet
[Kaneko+ 2022]
Wavehax
[Yoneyama+ 2024]
HN-uSFGAN
[Yoneyama+ 2023a]
F0依存畳み込み
⾳源正則化
ニューラルボコーダの発展(⼀部のみ)
Parallel
WaveGAN (PWG)
[Yamamoto+ 2020]
HiFiGAN
[Kong+ 2020]
Parallel WaveNet
[van den Oord+ 2017]
Neural Source
Filter (NSF)
[Wang 2019]
F0制御
⾳源
敵対的学習
⾼速化
⾼制御化
• F0制御⾳源
• 2D畳み込み
QH-ARMAGAN
[Chen+ 2025b]
BP-QHM
[Chen+ 2025a]
QHM
[Pantazis+ 2011]
分析機能
系列最適化 • 敵対的学習
• 特徴抽出ネット
• 包絡モデル
⾮⾃⼰回帰型
敵対的学習
時間周波数領域処理型](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-27-320.jpg)
![時間周波数領域型ニューラルボコーダ
• iSTFTNet [Kaneko+ 2022]
• 深層ネットワークにより時間周波数表現(複素スペクトログラム)を
推定し,短時間フーリエ逆変換により⾳声波形を⽣成
iSTFT
⾳声特徴量系列
合成⾳声波形
識別器
アップサンプリング
1D畳み込み層
誤差損失
複素スペクトログラム
• 時間波形の線形変換
• 時間領域推定との
違いは?同じ?
時間周波数領域処理型:1](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-28-320.jpg)
![知⾒:時間領域⾮線形処理とエイリアシング
• 時間領域における⾮線形処理 が周波数特性に与える影響
• 利点:⾼調波⽣成バイアス
• 周期信号⼊⼒に対して調波成分を⽣成(NSF [Wang+ 2019] の妥当性)
• ⽋点:エイリアシングによる歪み
• 𝐹 が学習データの範囲内:エイリアシングは低減される傾向あり
• 𝐹 が学習データの範囲外:エイリアシングは顕著に発⽣
𝑓 𝑥 𝑡
𝑓 0
𝑛!
𝑥 𝑡 𝑥 𝑡 は周波数領域では畳み込みに相当
𝑥 𝑡 sin 𝜔𝑡 の例
[Yoneyama+ 2024]
時間周波数領域処理型:2](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-29-320.jpg)
![エイリアシングフリーにするには?
調波信号⼊⼒(⾳源スペクトログラムの⽣成)と
2D畳み込み(局所的な演算)の併⽤が有効
調波モデリング
畳み込み
次元
エイリアシング
フリー
処理領域 調波信号
⼊⼒
正弦波信号
⼊⼒
雑⾳信号
⼊⼒
○
○
No
1D
No
時間
(波形)
×
×
×
1D
Yes
時間周波数
(スペクトロ
グラム)
〇
×
×
2D
[Yoneyama+ 2024]
時間周波数領域処理型:3](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-30-320.jpg)
![エイリアシングフリーボコーダ
• Wavehax [Yoneyama+ 2024]
• 時間周波数領域処理 + 2D 畳み込み + 調波信号モデル
調波信号の解析的⽣成および
⾳源複素スペクトログラム抽出
時間周波数領域2D畳み込みによる
複素スペクトログラム加⼯
時間周波数領域処理型:4](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-31-320.jpg)
![時間周波数
表現
QPPWG
[Wu+ 2021a]
iSTFTNet
[Kaneko+ 2022]
Wavehax
[Yoneyama+ 2024]
HN-uSFGAN
[Yoneyama+ 2023a]
F0依存畳み込み
⾳源正則化
アップサンプ
リング
ニューラルボコーダの発展(⼀部のみ)
SiFiGAN
[Yoneyama+ 2023b]
Parallel
WaveGAN (PWG)
[Yamamoto+ 2020]
HiFiGAN
[Kong+ 2020]
HarmonicNet+
[Matsubara+ 2023]
Parallel WaveNet
[van den Oord+ 2017]
Neural Source
Filter (NSF)
[Wang 2019]
F0制御
⾳源
敵対的学習
• F0制御⾳源
• F0依存畳み込み
⾳源正則化
⾼速化
⾼制御化
• F0制御⾳源
• 2D畳み込み
QH-ARMAGAN
[Chen+ 2025b]
BP-QHM
[Chen+ 2025a]
QHM
[Pantazis+ 2011]
分析機能
系列最適化 • 敵対的学習
• 特徴抽出ネット
• 包絡モデル
⾮⾃⼰回帰型
敵対的学習
正弦波モデル](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-32-320.jpg)
![知⾒:⾳声波形のスパースモデリング
• Quasi Harmonic Model (QHM) [Pantazis+ 2008]
• ⾳声波形を調波成分に相当する正弦波の重畳でモデル化
• 準調波性を正確にモデル化することで無声⾳も表現
• 分析:複素正弦波の振幅と位相を短時間フレーム分析で推定
• 合成:時間フレームパラメータ時系列𝑎
:
, 𝑓
:
を補間して
サンプル毎の振幅𝐴 𝑡 と位相𝜑 𝑡 を求め,⾳声波形を⽣成
𝑥 𝑡 𝑎 𝑡𝑏 exp 𝑗2𝜋𝑓 𝑡 𝑤 𝑡 𝑡 ∈ 𝑇 , 𝑇
𝑥 𝑡 𝐴 𝑡 exp 𝑗𝜑 𝑡
時間フレーム 𝑙 に
おける分析窓
𝑘 番⽬成分の
周波数 𝑘𝐹
𝑘 番⽬成分の
複素振幅
𝑘 番⽬成分の
複素振幅変化量
𝐴 𝑡 𝑆 𝑎
:
𝜑 𝑡 𝑆 𝑎
:
, 𝑓
:
補正
正弦波モデル:1](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-33-320.jpg)
![勾配法によるパラメータ時系列同時最適化
• BP-QHM [Chen+ 2025a]
• 合成波形の誤差が最⼩となるように誤差逆伝搬法により
時間フレームパラメータ時系列 𝑎 :
:
, 𝑓 :
:
を同時推定
• 合成⾳声 の例
𝑎 :
:
, 𝑓 :
:
arg min ℒ 𝑥 𝑡 , 𝐴 𝑡 exp 𝑗𝜑 𝑡
subject to 𝐴 𝑡 𝑆 𝑎
:
, 𝜑 𝑡 𝑆 𝑎
:
, 𝑓
:
𝐾 2
𝐾 4
𝐾 16
𝐾 64
正弦波モデル:2](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-34-320.jpg)
![分析合成ニューラルボコーダ
• QH-ARMAGAN [Chen+ 2025b]
• 複素スペクトル包絡をARMAモデルで表現
• 分析:時間フレームモデルパラメータ時系列𝐺 :
, 𝑎 :
:
, 𝑏 :
:
を
メルスペクトログラムから深層ネットワークにより推定
• 合成:所望の𝐹 に対する調波振幅・位相をARMAモデルから
サンプリングして⾳声波形を合成
𝜑 𝜋𝑘 𝐹 𝐹 𝑡 𝑡 arg 𝐻 2𝜋𝑘 𝐹 𝑓
𝐻 𝜔 𝐺
1 ∑ 𝑏 exp 𝑗𝑞𝜔
1 ∑ 𝑎 exp 𝑗𝑝𝜔
𝐴 𝐻 2𝜋𝑘 𝐹 𝑓
ARMAモデル:
𝒌番⽬調波振幅:
𝒌番⽬調波位相:
𝑥 𝑡 𝐴 𝑡 exp 𝑗𝜑 𝑡
𝐴 𝑡 𝑆 𝐴
:
𝜑 𝑡 𝑆 𝜑
:
合成⾳声波形:
正弦波モデル:3](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-35-320.jpg)
![QH-ARMAGAN分析例:複素スペクトル包絡推定
0 0.5 1.0 1.5
12
0
4
8
12
0
4
8
12
0
4
8
12
0
4
8
Frequency
[kHz]
Frequency
[kHz]
Frequency
[kHz]
Frequency
[kHz]
0 0.5 1.0 1.5 0 0.5 1.0 1.5
Time [s] Time [s]
0
2π
観測振幅・位相スペクトログラム 推定振幅・位相スペクトログラム
⾳源成分を除去して1ピッチ波形に
相当する周波数応答を抽出
[Chen+ 2025b]
正弦波モデル:4](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-36-320.jpg)
![QH-ARMAGAN分析・変換・合成例
• ⽇本語⾳声(JVS DB [Takamichi+ 2019])で学習したモデルを⽤いて
中国語歌声(OpenSinger DB [Huang+ 2021])を分析・変換・合成
収録歌声
分析再合成歌声
𝐹 倍率 2
𝐹 倍率 2 .
𝐹 倍率 2 .
𝐹 倍率 0.5
[Chen+ 2025b]
正弦波モデル:5](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-37-320.jpg)
![時間周波数
表現
QPPWG
[Wu+ 2021a]
iSTFTNet
[Kaneko+ 2022]
Wavehax
[Yoneyama+ 2024]
HN-uSFGAN
[Yoneyama+ 2023a]
F0依存畳み込み
⾳源正則化
アップサンプ
リング
ニューラルボコーダの発展(⼀部のみ)
SiFiGAN
[Yoneyama+ 2023b]
Parallel
WaveGAN (PWG)
[Yamamoto+ 2020]
HiFiGAN
[Kong+ 2020]
HarmonicNet+
[Matsubara+ 2023]
Parallel WaveNet
[van den Oord+ 2017]
Neural Source
Filter (NSF)
[Wang 2019]
F0制御
⾳源
敵対的学習
• F0制御⾳源
• F0依存畳み込み
⾳源正則化
⾼速化
⾼制御化
• F0制御⾳源
• 2D畳み込み
QH-ARMAGAN
[Chen+ 2025b]
BP-QHM
[Chen+ 2025a]
QHM
[Pantazis+ 2011]
分析機能
系列最適化 • 敵対的学習
• 特徴抽出ネット
• 包絡モデル
⾮⾃⼰回帰型
敵対的学習
ニューラルボコーダの発展](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-38-320.jpg)


![参考⽂献:1
[van den Oord+ 2016] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N.
Kalchbrenner, A. W. Senior, K. Kavukcuoglu, “WaveNet: a generative model for raw audio,” arXiv preprint,
arXiv:1609.03499, 15 pages, 2016.
[Tamamori+ 2017] A. Tamamori, T. Hayashi, K. Kobayashi, K. Takeda, T. Toda, “Speaker-dependent
WaveNet vocoder,” Proc. INTERSPEECH, pp. 1118‒1122, 2017.
[Itakura+ 1968] F. Itakura, S. Saito, “Analysis synthesis telephony based upon the maximum likelihood
method,” Proc. ICA, C-5-5, pp. C17‒20, 1968.
[van den Oord+ 2017] A. van den Oord, Y. Li, I. Babuschkin, K. Simonyan, O. Vinyals, K. Kavukcuoglu, G. van
den Driessche, E. Lockhart, L.C. Cobo, F. Stimberg, N. Casagrande, D. Grewe, S. Noury, S. Dieleman, E. Elsen,
N. Kalchbrenner, H. Zen, A. Graves, H. King, T. Walters, D. Belov, D. Hassabis, “Parallel WaveNet: fast high-
fidelity speech synthesis,” arXiv preprint, arXiv:1711.10433, 11 pages, 2017.
[Yamamoto+ 2020] R. Yamamoto, E. Song, J.-M. Kim, “Parallel WaveGAN: A fast waveform generation
model based on generative adversarial networks with multi-resolution spectrogram,” Proc. IEEE ICASSP, pp.
6199‒6203, 2020.
[Wang+ 2019] X. Wang, S. Takaki J. Yamagishi, “Neural source-filter waveform models for statistical
parametric speech synthesis,” IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 28, pp. 402‒415, 2019.
[Schroeder+ 1985] M. Schroeder, B. Atal, “Code-excited linear prediction (CELP): high-quality speech at
very low bit rates,” Proc. IEEE ICASSP, pp. 937‒940, 1985.
[Wu+ 2021a] Y.-C. Wu, T. Hayashi, T. Okamoto, H. Kawai, T. Toda, “Quasi-periodic parallel WaveGAN: a
non-autoregressive raw waveform generative model with pitch-dependent dilated convolution neural
network,” IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 29, pp. 792‒806, 2021.
[Wu+ 2021b] Y.-C. Wu, T. Hayashi, T. Okamoto, H. Kawai, T. Toda, “Quasi-periodic WaveNet: an
autoregressive raw waveform generative model with pitch-dependent dilated convolution neural network,”
IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 29, pp. 1134‒1148, 2021.
参考⽂献](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-41-320.jpg)
![参考⽂献:2
[Yoneyama+ 2023a] R. Yoneyama, Y.-C. Wu, T. Toda, “High-fidelity and pitch-controllable neural vocoder
based on unified source-filter networks,” IEEE/ACM Trans. Audio, Speech & Lang. Process., Vol. 31, pp.
3717‒3729, 2023.
[Yoneyama+ 2023b] R. Yoneyama, Y.-C. Wu, T. Toda, “Source-Filter HiFiGAN: fast and pitch controllable
high-fidelity neural vocoder,” Proc. IEEE ICASSP, 5 pages, 2023.
[Yamagishi+ 2019] J. Yamagishi, C. Veaux, K. MacDonald, “CSTR VCTK Corpus: English multi-speaker
corpus for CSTR voice cloning toolkit (version 0.92),” https://doi.org/10.7488/ds/2645, University of
Edinburgh. The Centre for Speech Technology Research (CSTR), 2019.
[Kong+ 2020] J. Kong, J. Kim, J. Bae, “HiFi-GAN: generative adversarial networks for efficient and high
fidelity speech synthesis,” Proc. NeurIPS, pp. 17022‒17033, 2020.
[Matsubara+ 2023] K. Matsubara, T. Okamoto, R. Takashima, T. Takiguchi, T. Toda, H. Kawai, “Harmonic-
Net: fundamental frequency and speech rate controllable fast neural vocoder,” IEEE/ACM Trans. Audio,
Speech & Lang. Process., Vol. 31, pp. 1902‒1915, 2023.
[Ogita+ 2025] K. Ogita, R. Yoneyama, W.-C. Huang, T. Toda, “VAE-SiFiGAN: source-filter HiFi-GAN based
on variational autoencoder representations with enhanced pitch controllability,” Proc. EUSIPCO, 5 pages,
2025 (in press).
[Canon 2021] Canon, “NamineRitsu Singing DB Ver.2,”
https://drive.google.com/drive/folders/1XA2cm3UyRpAk_BJb1LTytOWrhjsZKbSN, 2021.
[Kaneko+ 2022] T. Kaneko, K. Tanaka, H. Kameoka, S. Seki, “iSTFTNet: Fast and lightweight mel-
spectrogram vocoder incorporating inverse short-time Fourier transform,” Proc. IEEE ICASSP, pp. 6207‒6211,
2022.
[Yoneyama+ 2024] R. Yoneyama, A. Miyashita, R. Yamamoto, T. Toda, “Wavehax: aliasing-free neural
waveform synthesis based on 2D convolution and harmonic prior for reliable complex spectrogram
estimation,” arXiv preprint, arXiv:2411.06807, 13 pages, 2024.
[Pantazis+ 2011] Y. Pantazis, O. Rosec, and Y. Stylianou, “Adaptive AM-FM signal decomposition with
application to speech analysis,” IEEE Trans. Audio, Speech & Lang. Process., Vol. 19, No. 2, pp. 290‒300,
2011.](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-42-320.jpg)
![参考⽂献:3
[Chen+ 2025a] S. Chen, T. Toda, “Sequence-wise speech waveform modeling via gradient descent
optimization of quasi-harmonic parameters,” IEEE Trans. Audio, Speech & Lang. Process., Vol. 33, pp. 319‒
332, 2025.
[Chen+ 2025b] S. Chen, T. Toda, “QHARMA-GAN: Quasi-harmonic neural vocoder based on autoregressive
moving average model,” arXiv preprint, arXiv: 2507.01611, 16 pages, 2025.
[Takamichi+ 2019] S. Takamichi, K. Mitsui, Y. Saito, T. Koriyama, N. Tanji, H. Saruwatari, “JVS corpus: free
Japanese multi-speaker voice corpus,” arXiv preprint, arXiv: 1908.06248, 4 pages, 2019.
[Huang+ 2021] R. Huang, F. Chen, Y. Ren, J. Liu, C. Cui, Z. Zhao, “Multi-Singer: fast multi-singer singing
voice vocoder with a large-scale corpus,” Proc. ACM Multimedia, pp. 3945‒3954, 2021.](https://image.slidesharecdn.com/slides20250613-250705112908-f679775a/85/2025-43-320.jpg)
















![音声分析合成[3].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/random-220616064407-3408f742-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]GANSynth: Adversarial Neural Audio Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/20180315gansynthmizuta-190315003922-thumbnail.jpg?width=640&height=640&fit=bounds)



















