音源分離における音響モデリング(Acoustic modeling in audio source separation)
北村大地, "音源分離における音響モデリング," 日本音響学会 サマーセミナー 招待講演, September 11th, 2017.
Daichi Kitamura, "Acoustic modeling in audio source separation," The Acoustical Society of Japan, Summer Seminar Invited Talk, September 11th, 2017.
#8 You are drinking at the party. Of cause many people are simultaneously talking, BUT you can listen only one voice if you pay attention to that person, and if the person is very cute, right?
Anyway, we all can separate many voices and make a chatting with one person even if the other people is talking in the same room. This is a special ability of a human being, which is called “Cocktail party effect.”
But the question is, how can we do the same thing by a computer? How do we know the process of the audio source separation in brain?
This is a deep question, and many researchers around the world are working to reveal the process of audio source separation, and simulate that by the computer.
#9 Before we dive into the details, I show some demonstrations of audio source separation.
This is a video for real-time speech source separation, which is developed by Prof. Saruwatari, the boss of our laboratory.
I’m sorry but the video is only in Japanese, but I think you can understand what’s going on.
After Prof. Saruwatari got a patent of this device, Japanese police employed this device as their equipment.
I heard that he was complaining because his wife monopolized much money.
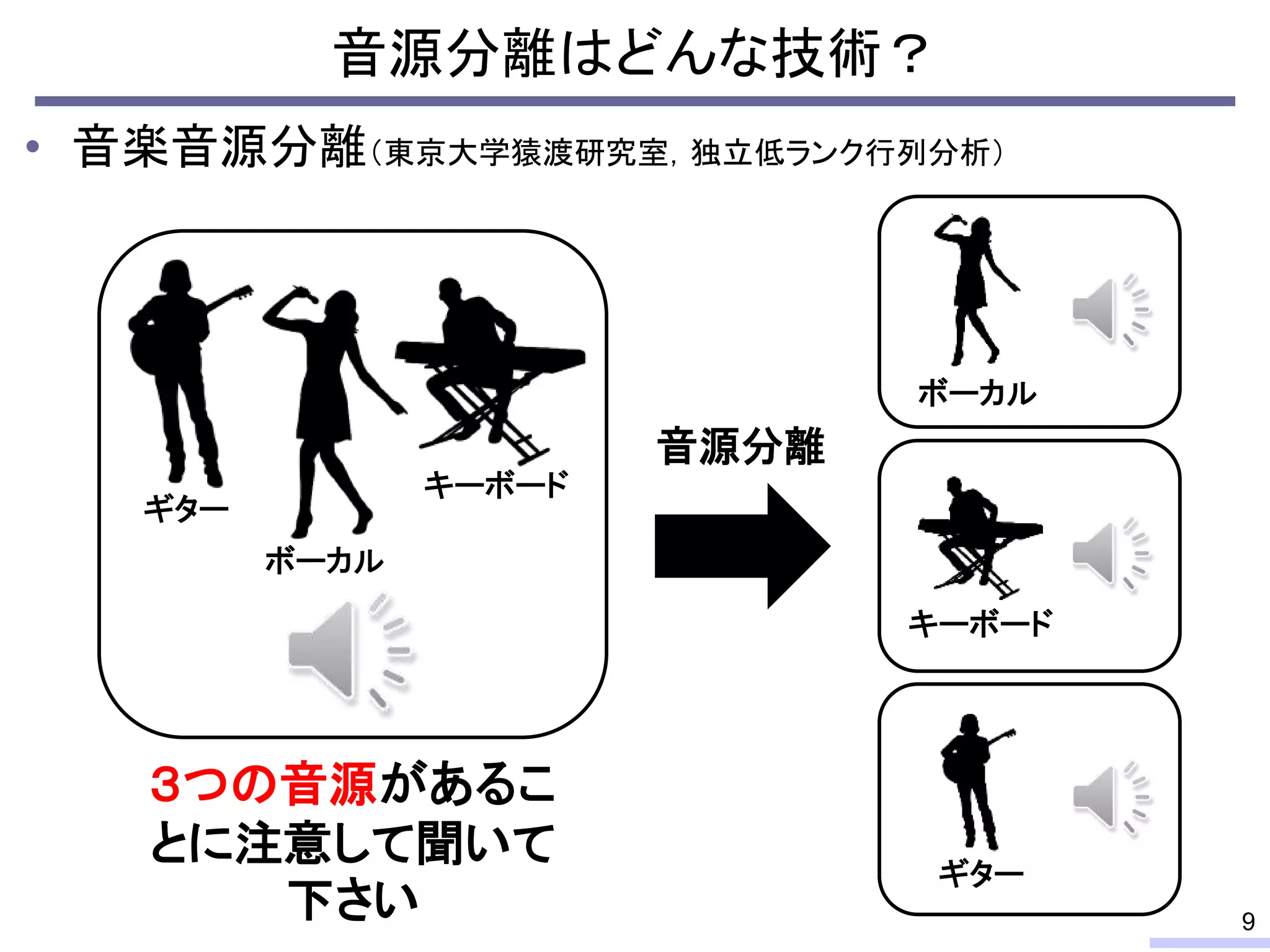
#10 Anyway, the next one is a music source separation.
Here we have a mixture signal of three parts. It’s just like a typical music.
Please pay attention to listen three parts, guitar, vocal, and keyboard, OK? Let’s listen.
Then, if we apply source separation, we can obtain this kind of signals.
So, we can remix them, re-edit them, or anything we want. This is a source separation.
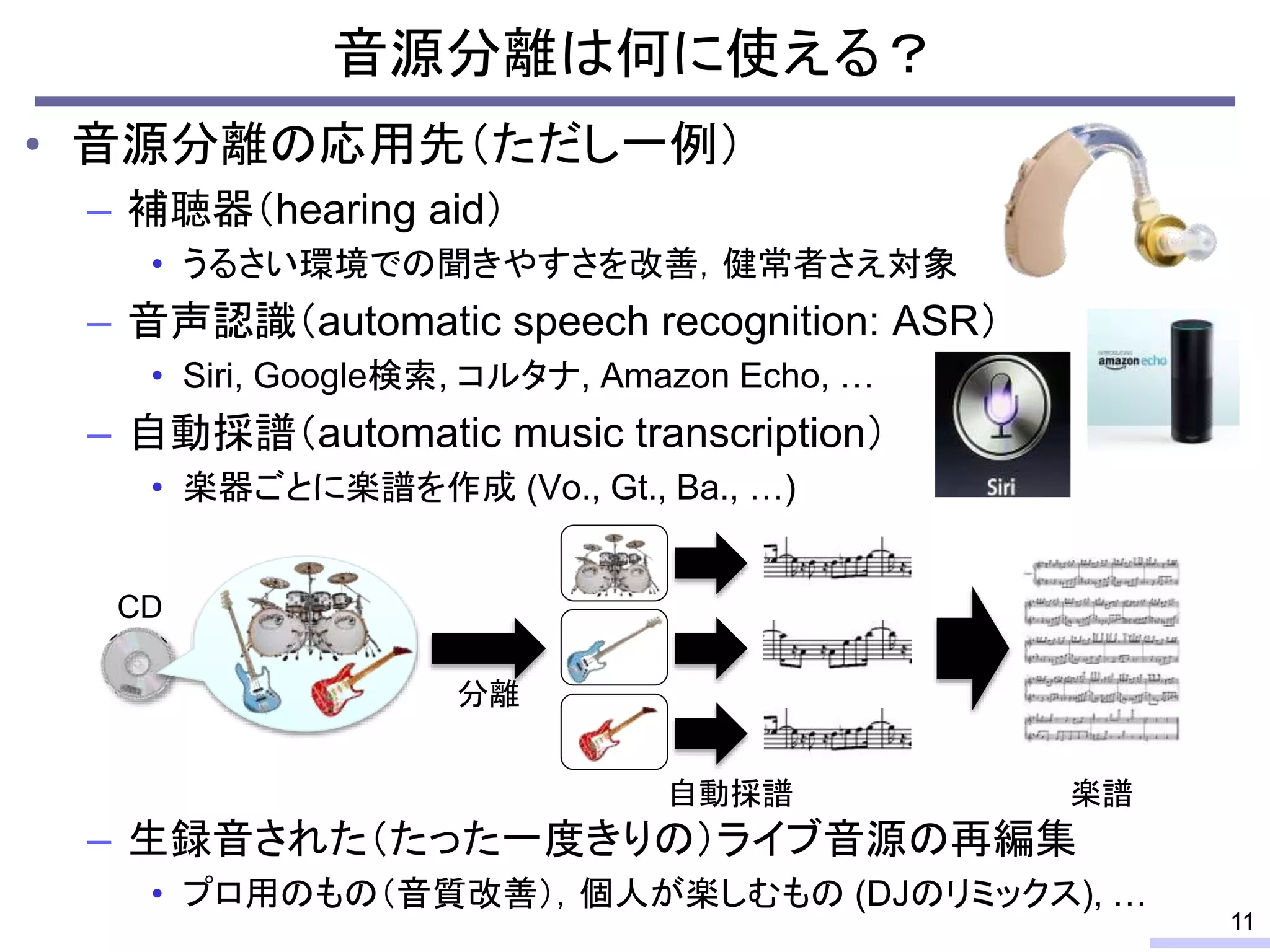
#12 If we could achieve such a thing, many applications could be realized.
For example,
So, the audio source separation can be used any of audio systems, as a front-end. Before we do something to the audio signal, it should be separated in each sound source.
#13 If we could achieve such a thing, many applications could be realized.
For example,
So, the audio source separation can be used any of audio systems, as a front-end. Before we do something to the audio signal, it should be separated in each sound source.
#14 If we could achieve such a thing, many applications could be realized.
For example,
So, the audio source separation can be used any of audio systems, as a front-end. Before we do something to the audio signal, it should be separated in each sound source.
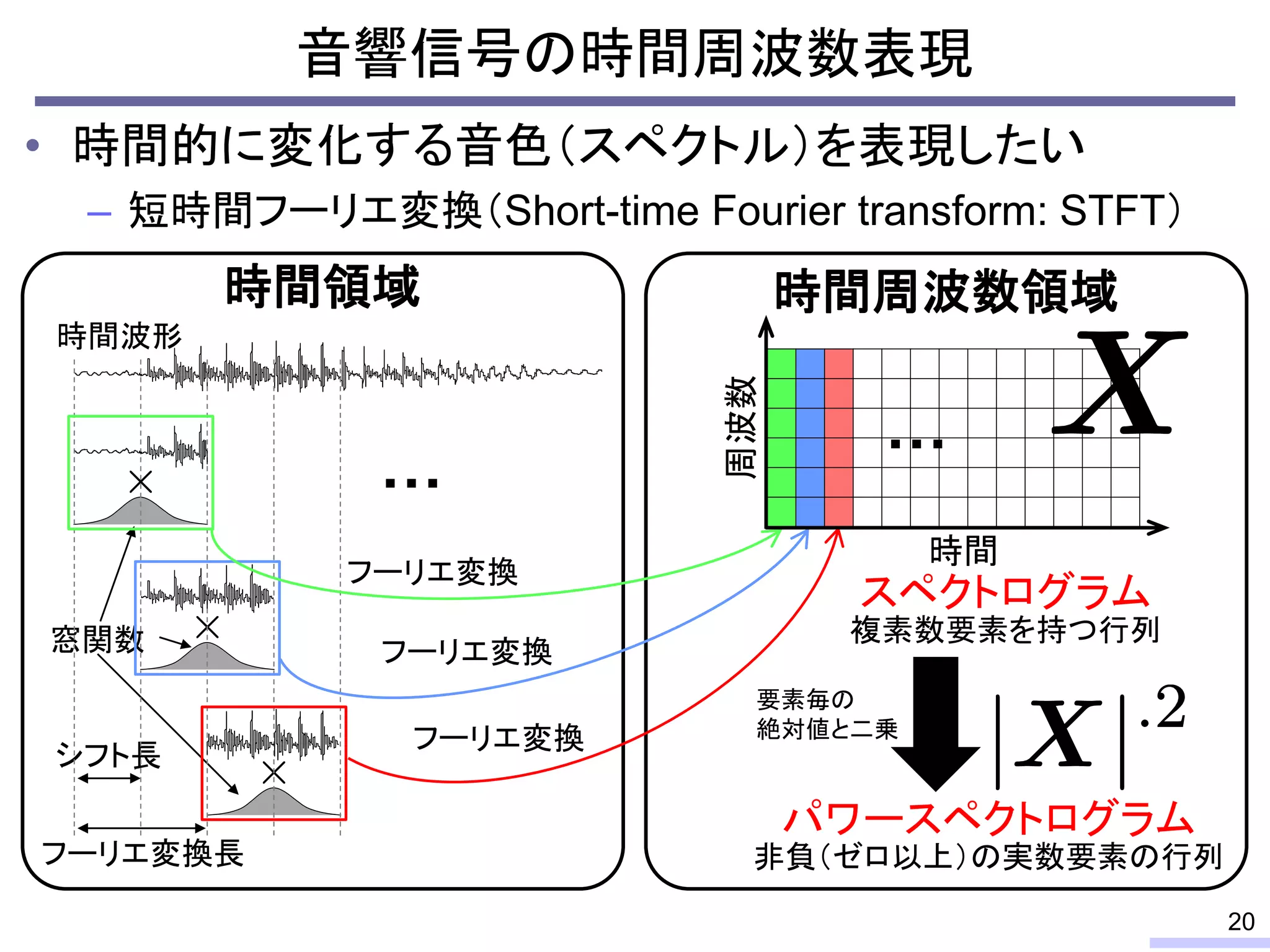
#21 But in the audio signal processing, we apply a short-time Fourier transform, STFT, to see the time-varying frequency structure of audio signals.
This is an audio waveform. In STFT, first, we split the waveform in a bunch of pieces with some overlaps like this.
We call these length as shift length and FFT length.
This is a very basic approach for audio signal processing.
Almost all techniques for audio signals, we apply STFT first, then do something to the spectrogram.
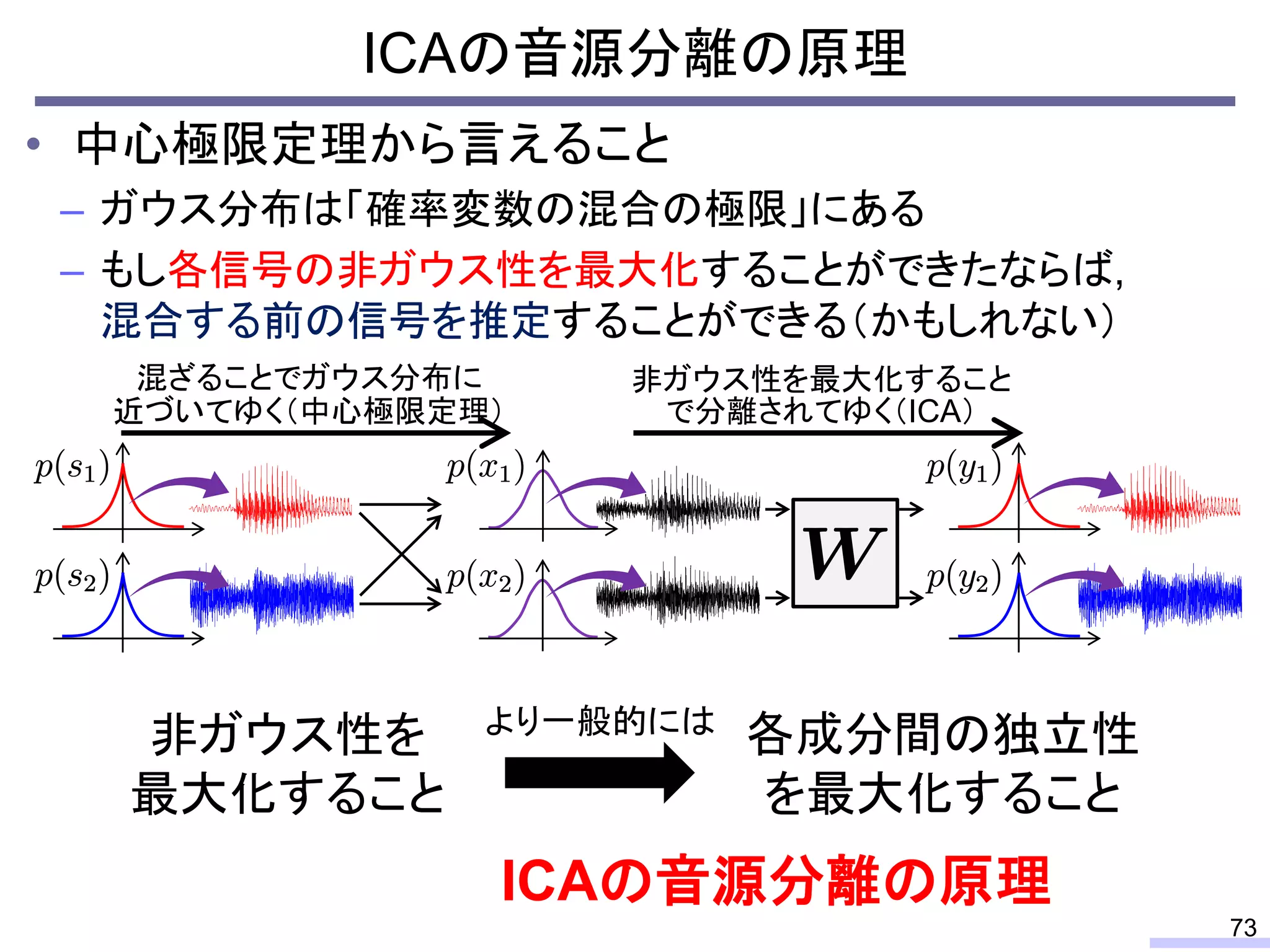
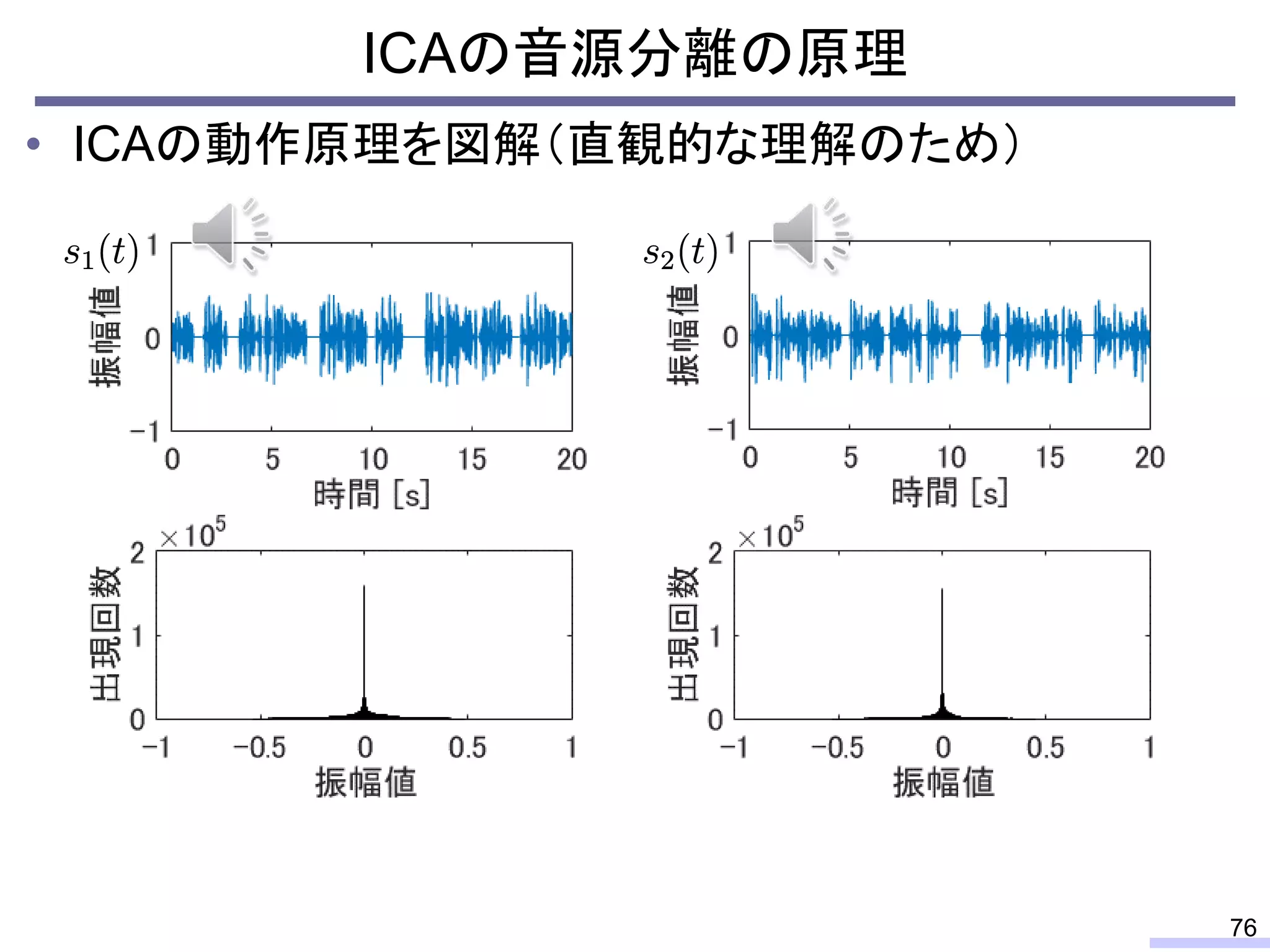
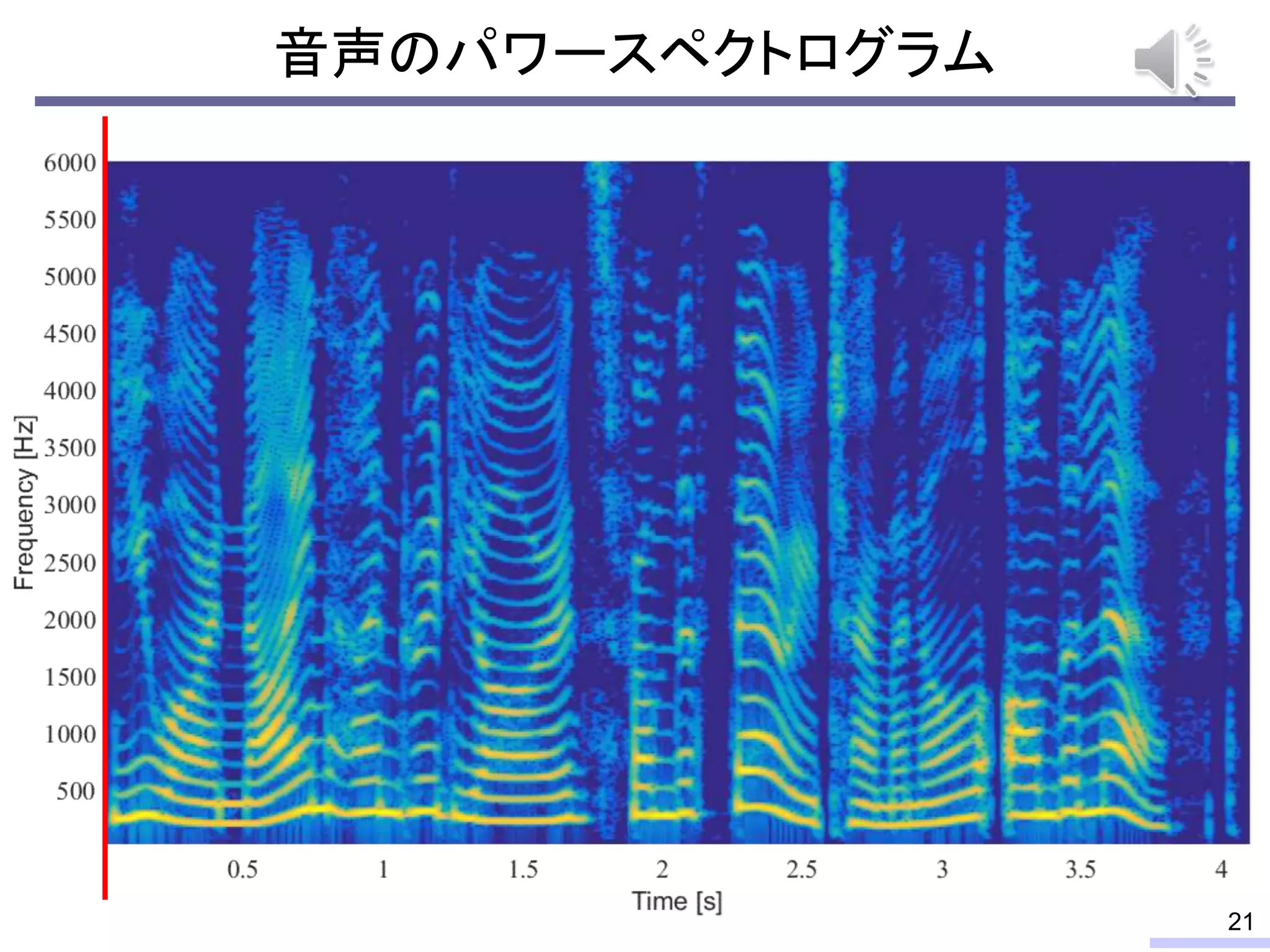
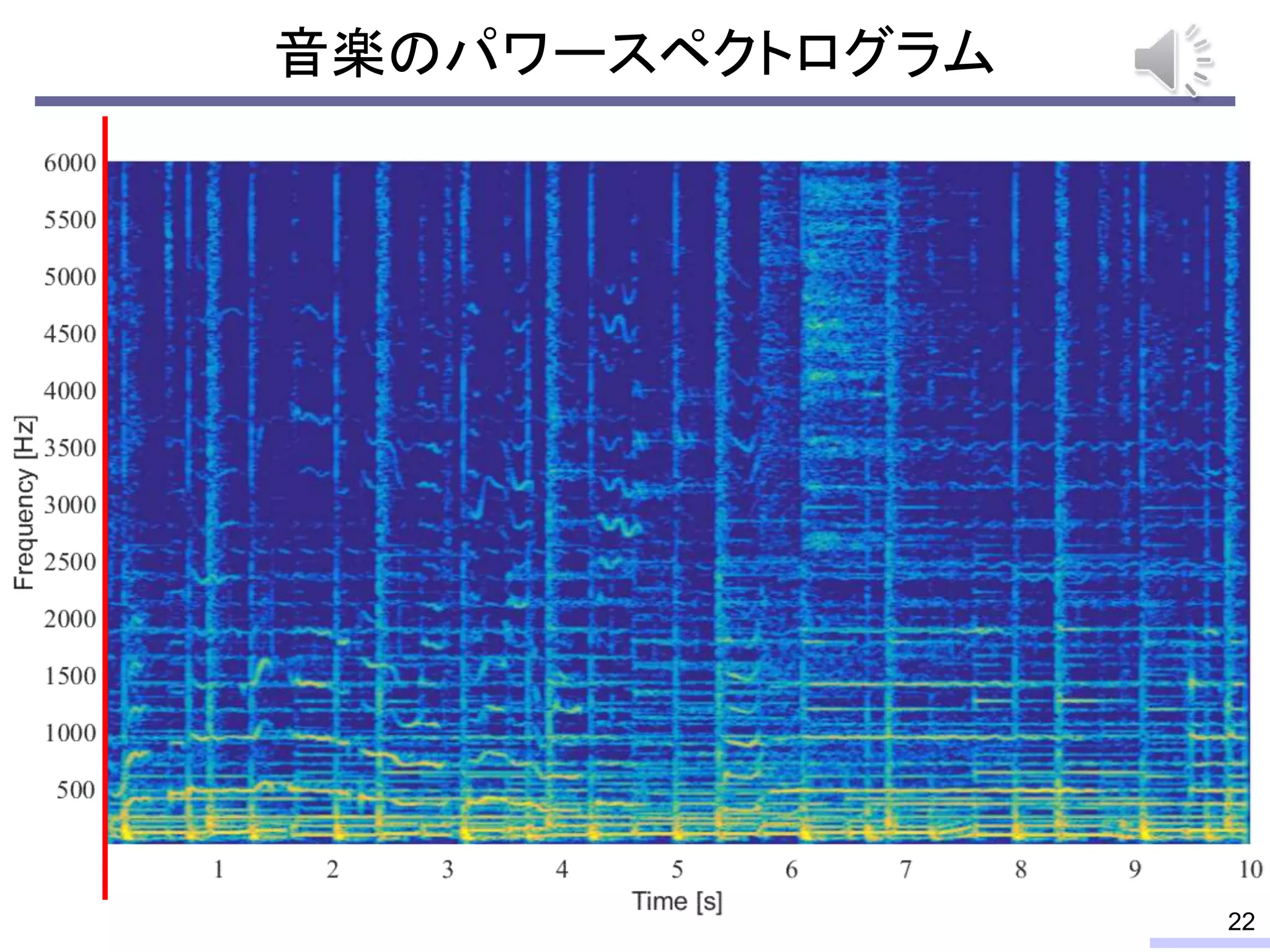
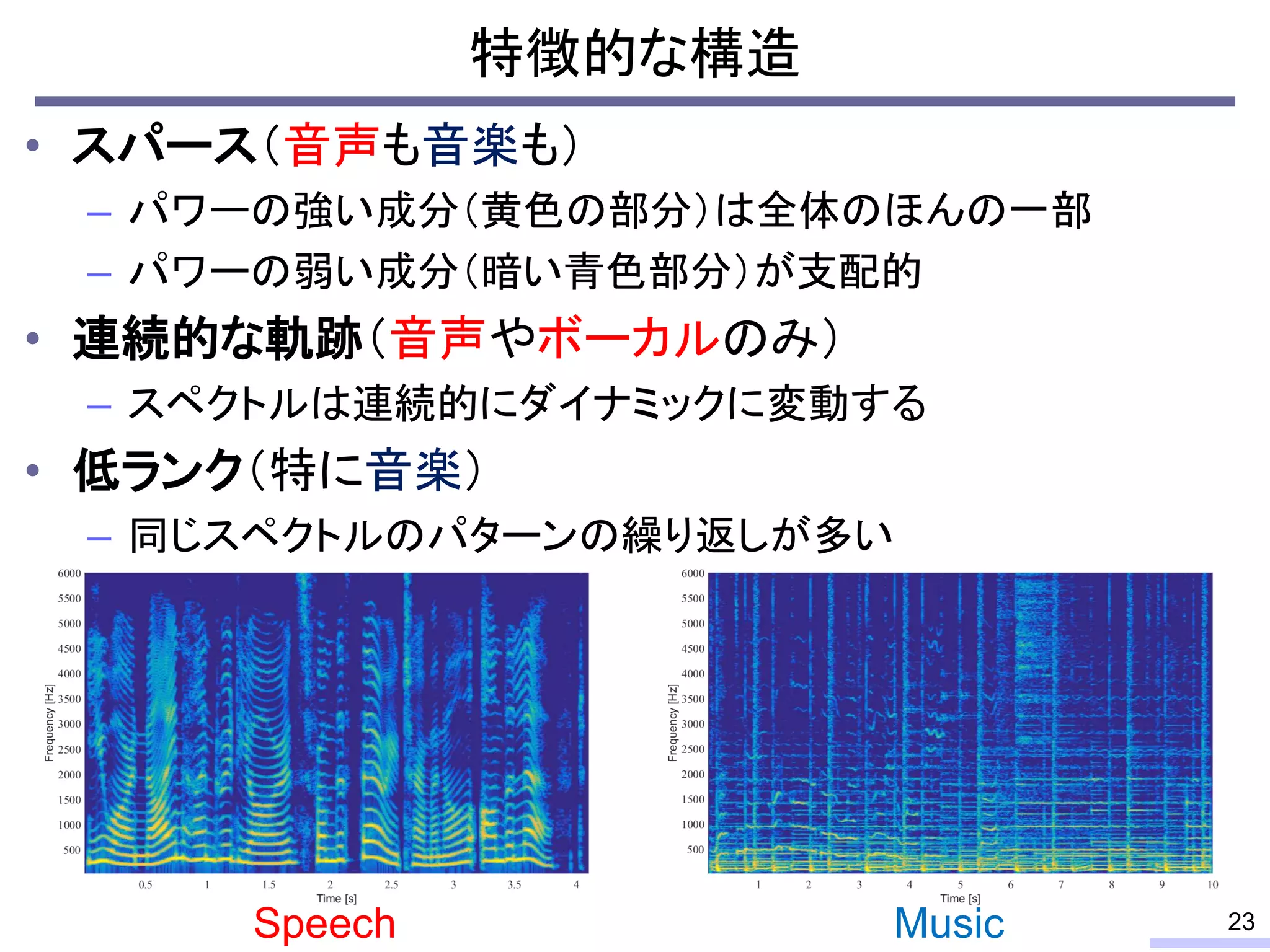
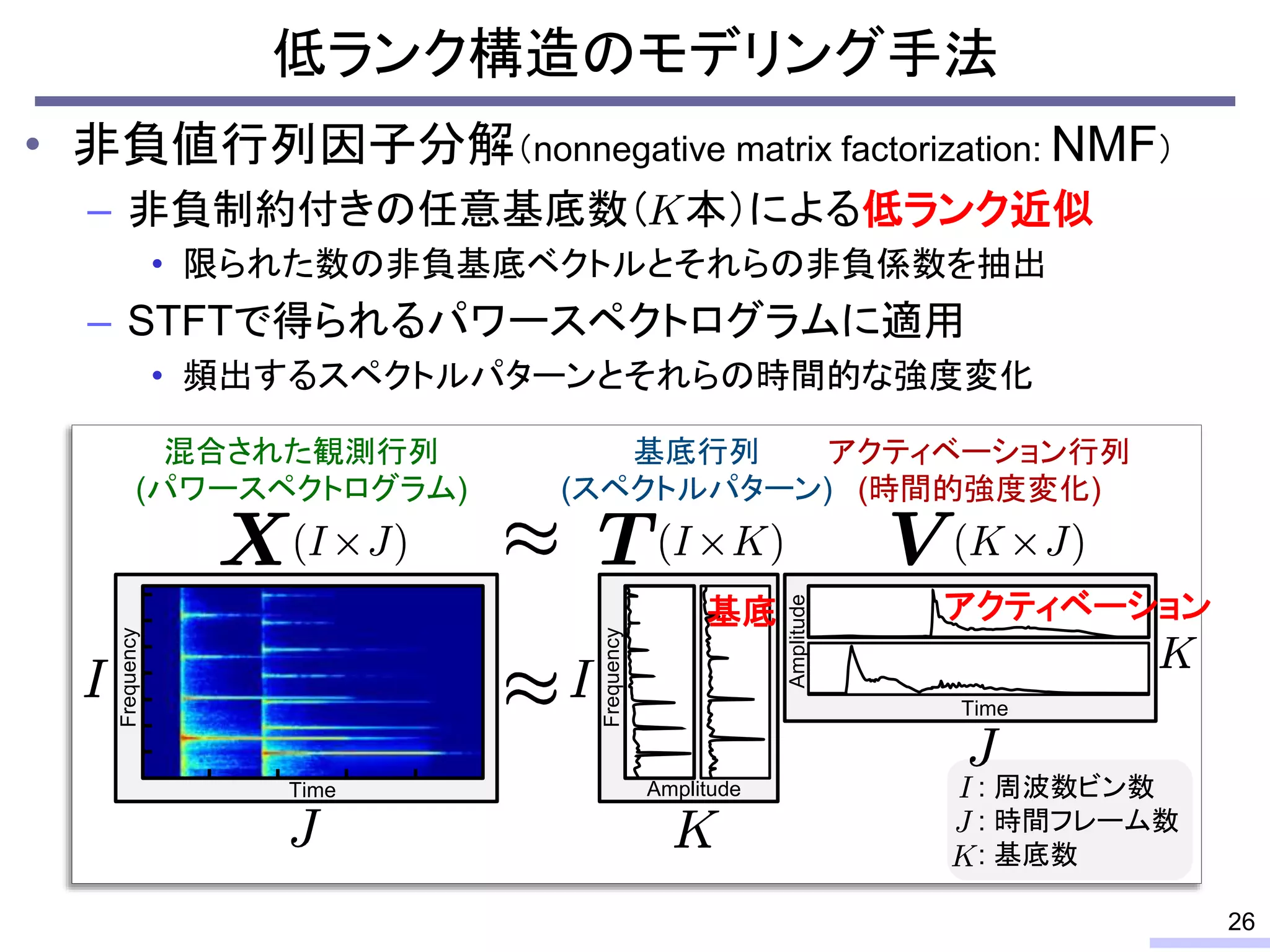
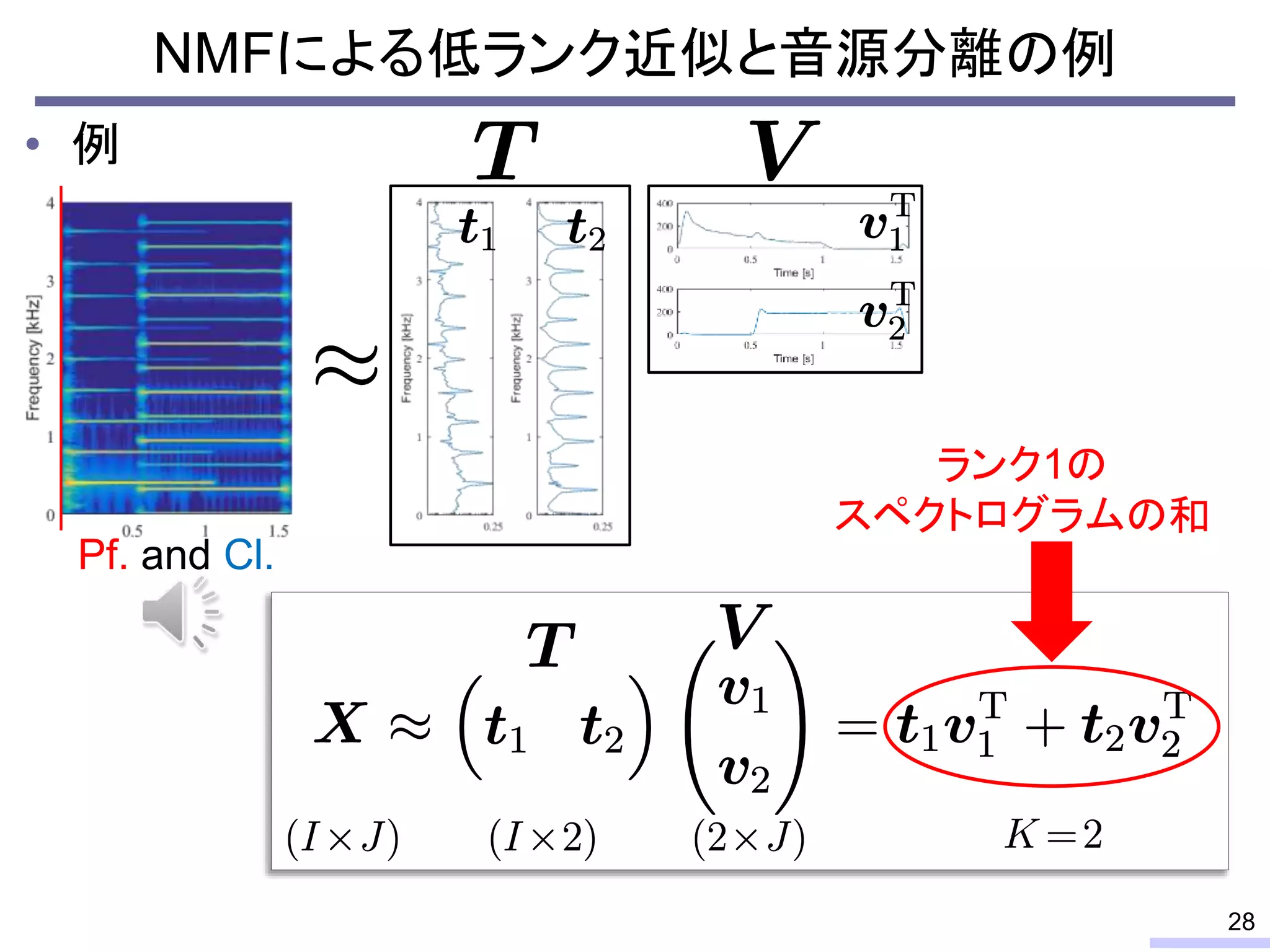
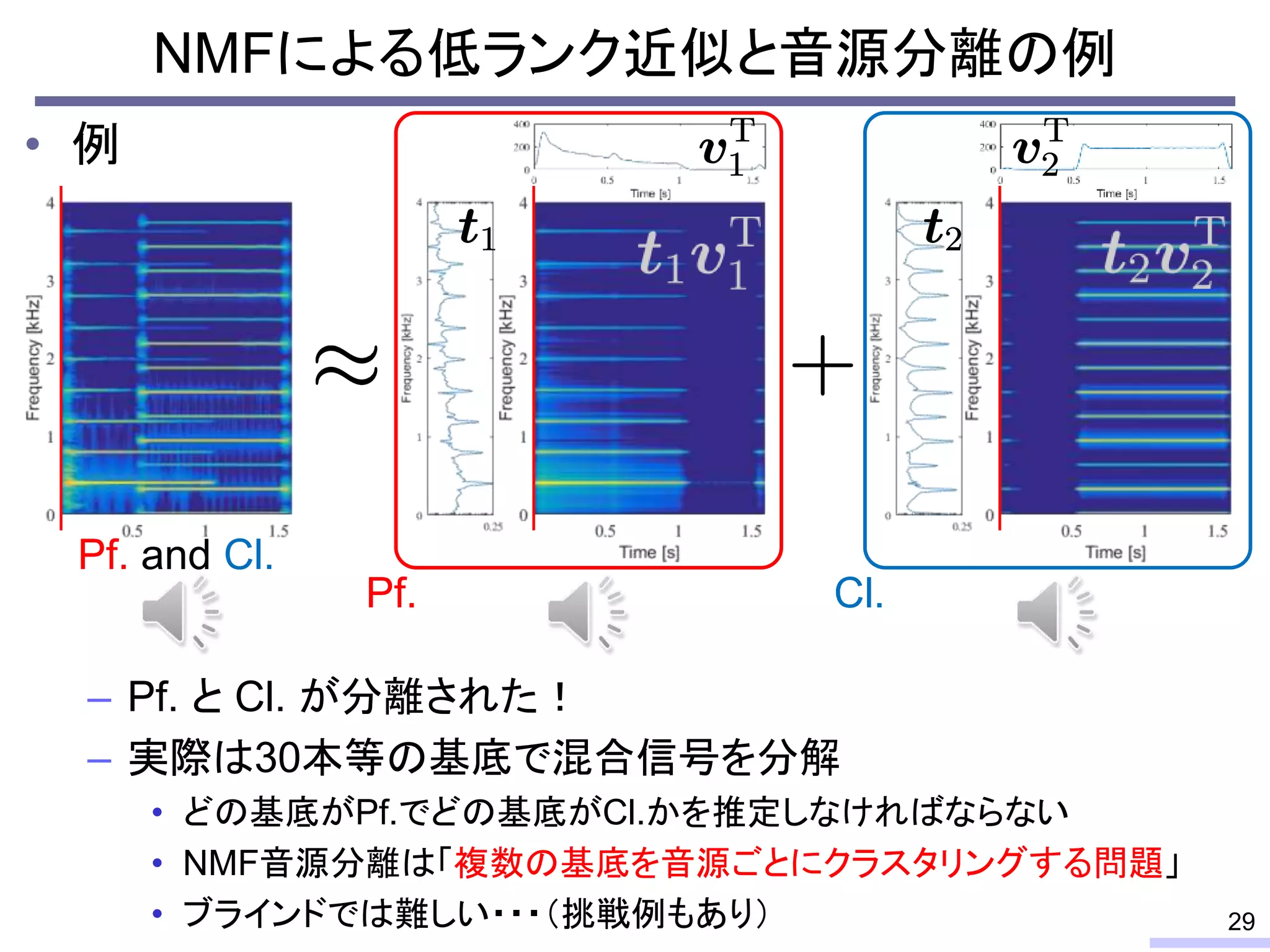
#24 These properties can be used for modeling the power spectrogram, and such modeling enables us to do some processing, such as a source separation.
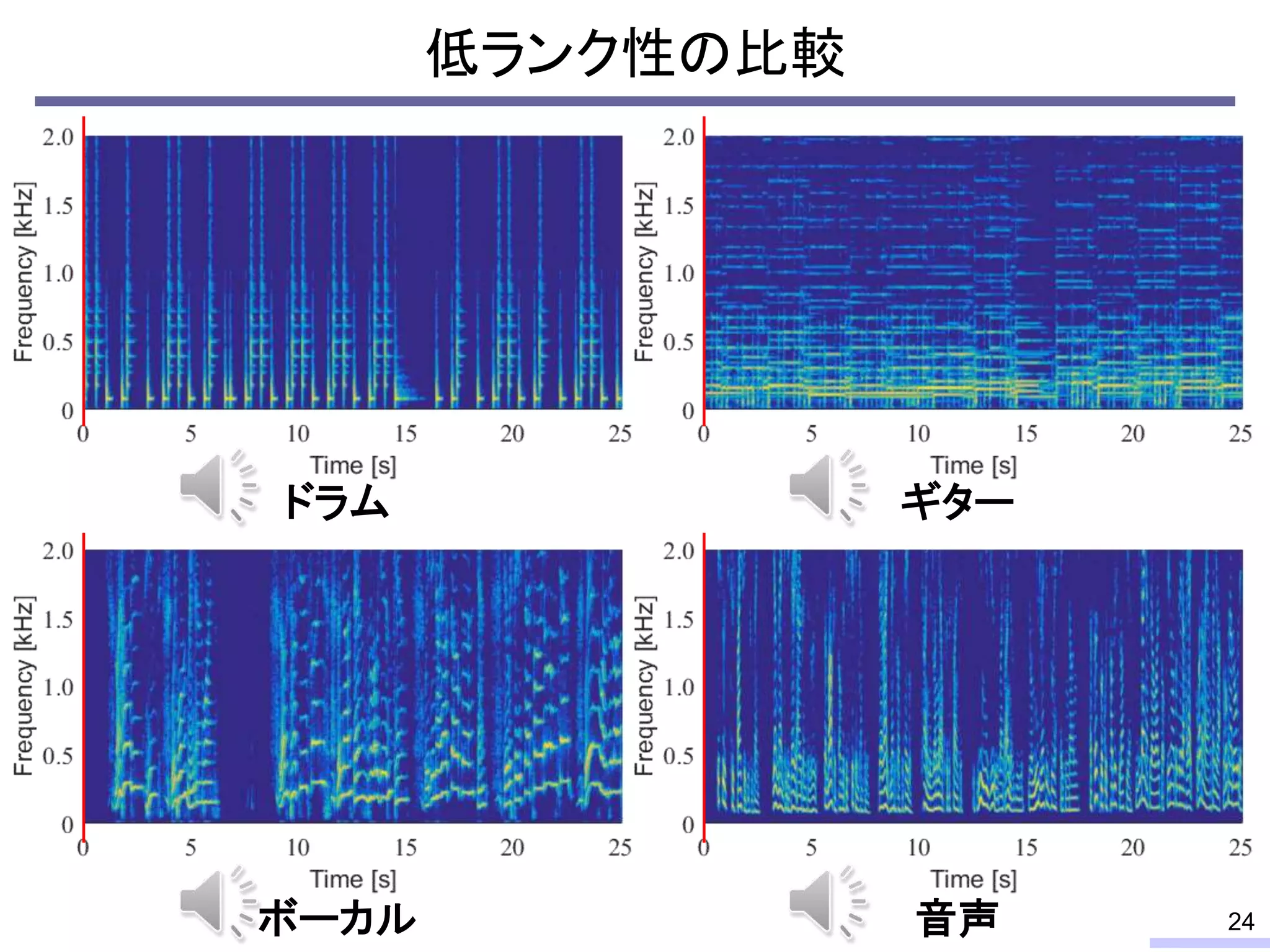
Especially, the low-rankness is really useful for audio source separation. I will tell about that issue later, but let’s confirm the low-rank property from an objective view.
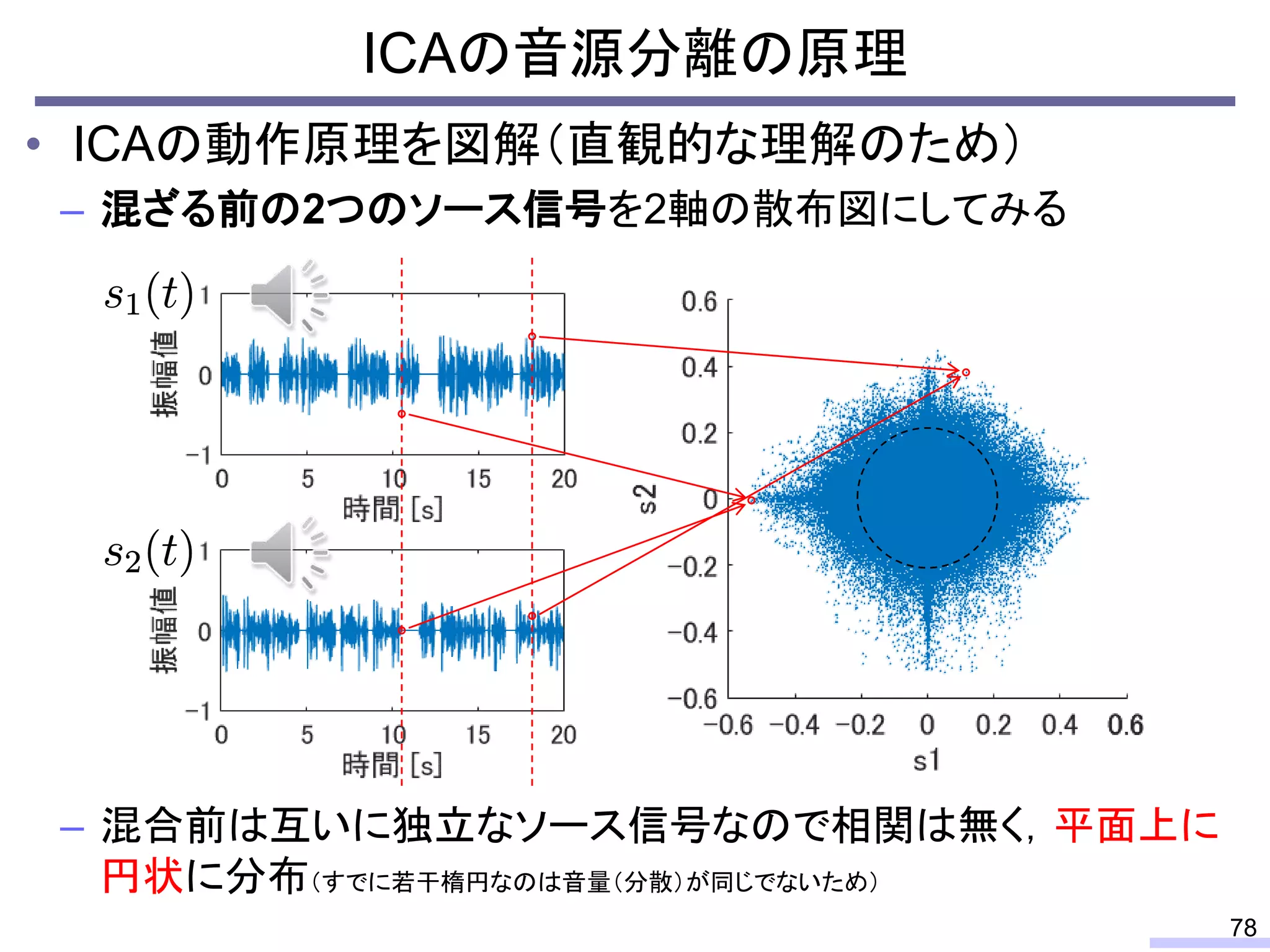
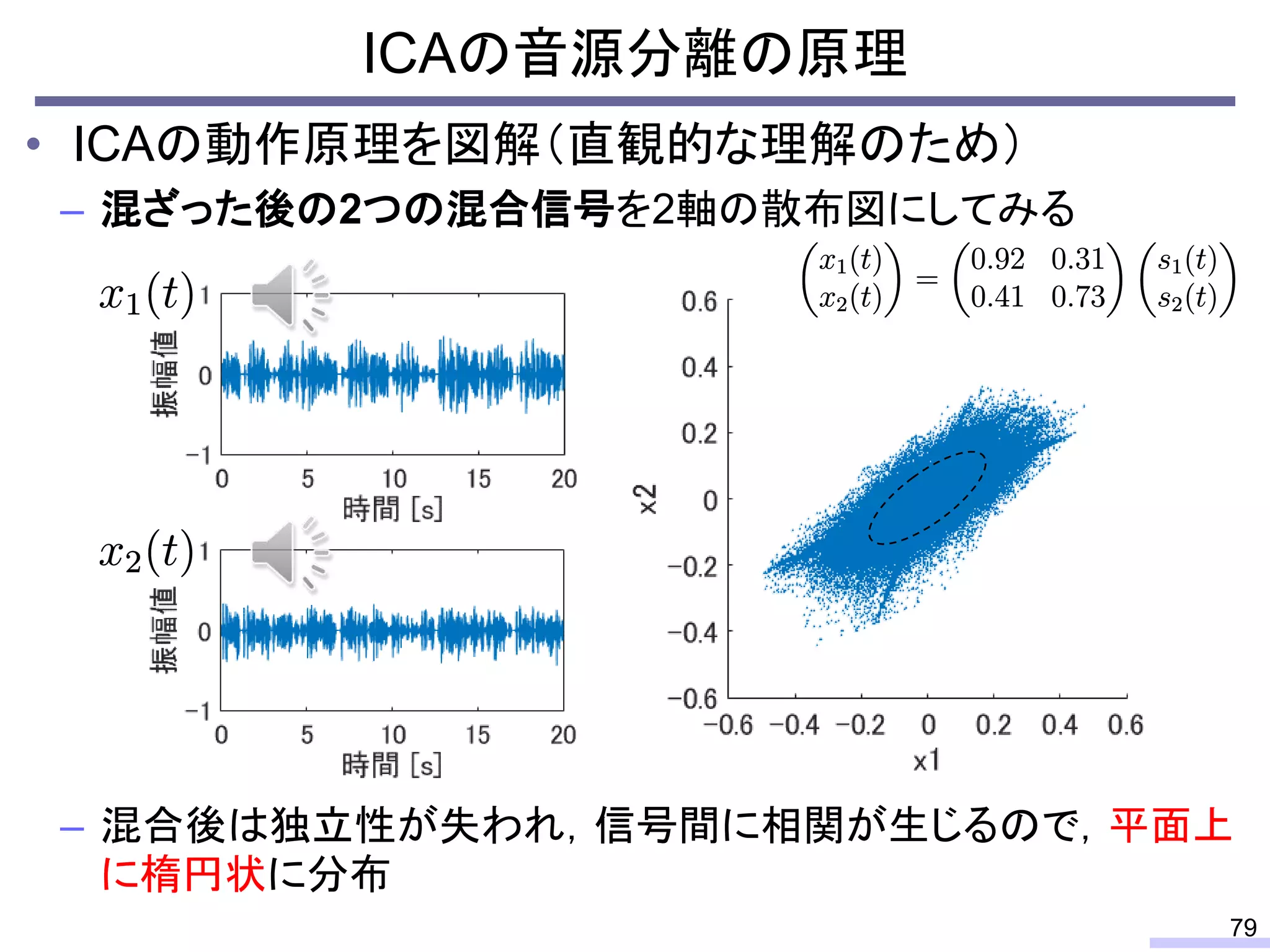
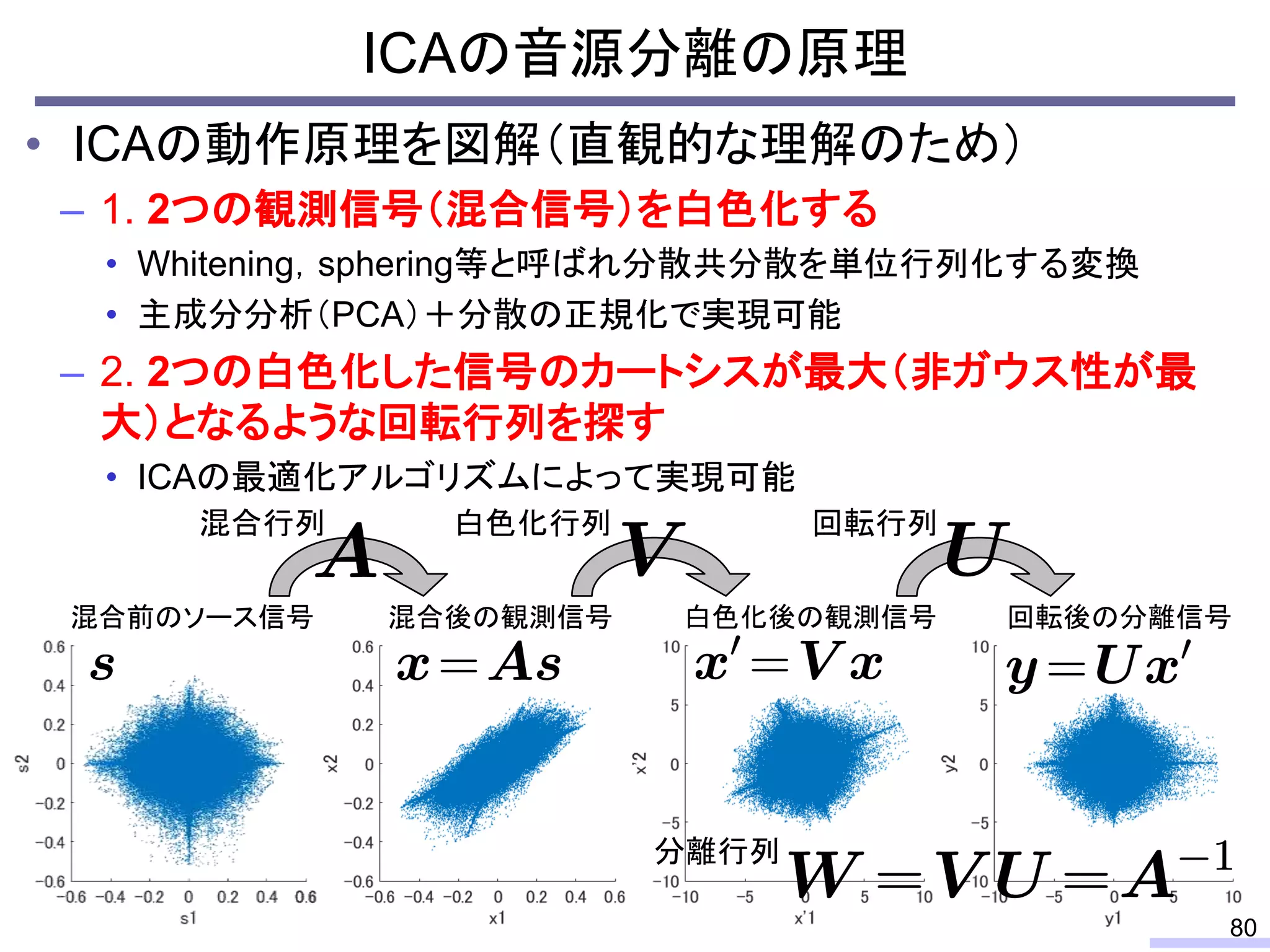
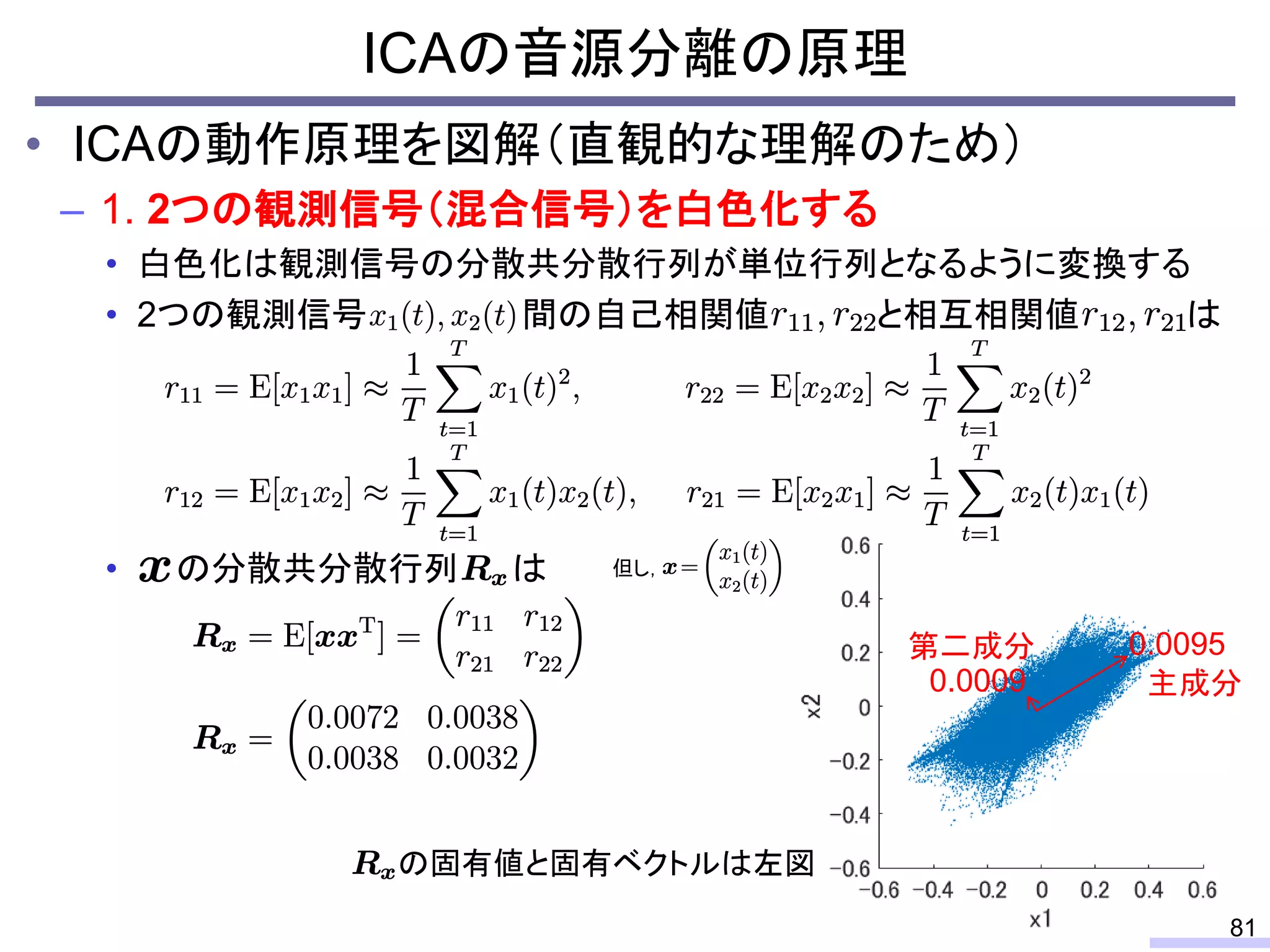
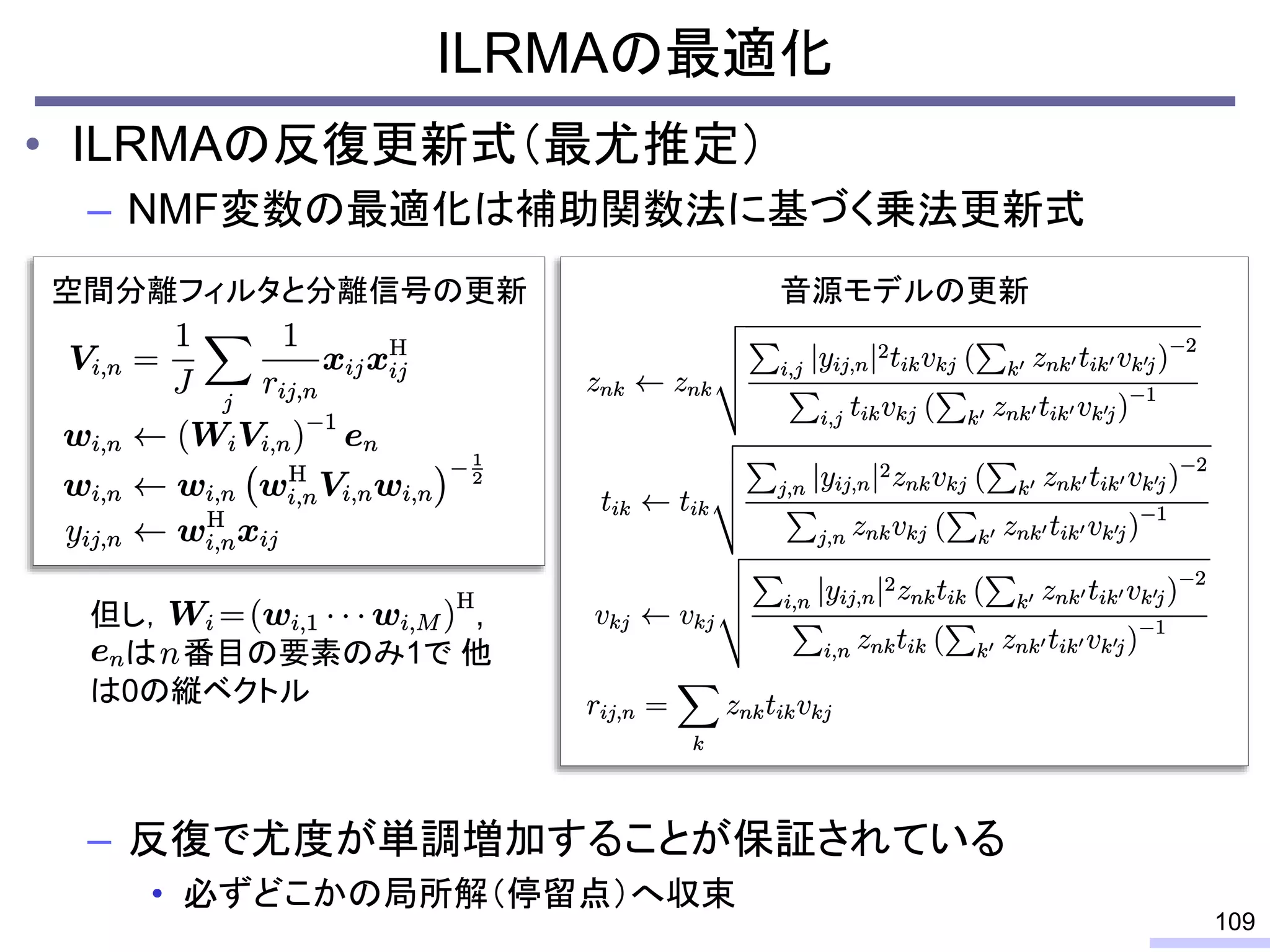
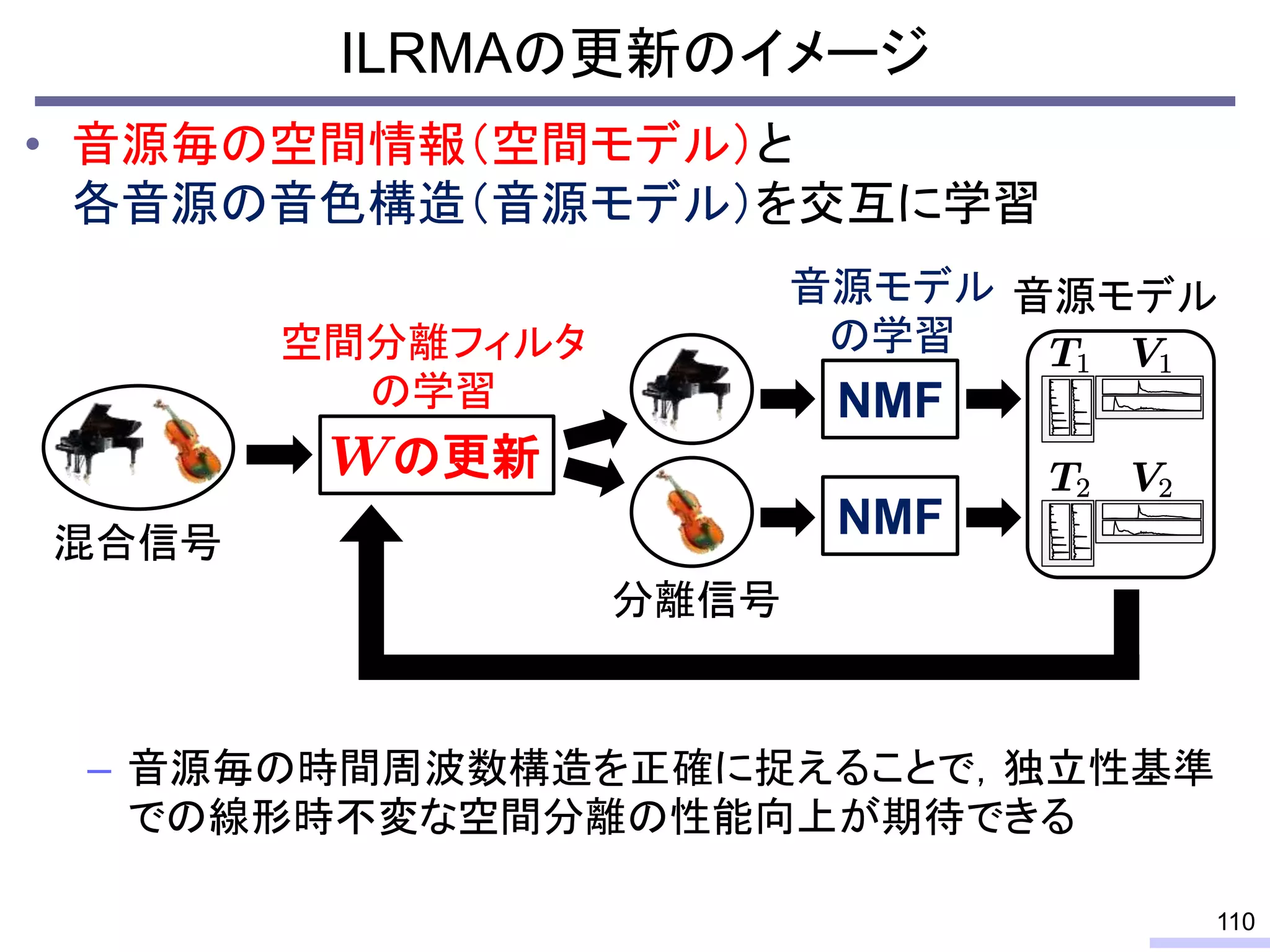
#58 先に上から
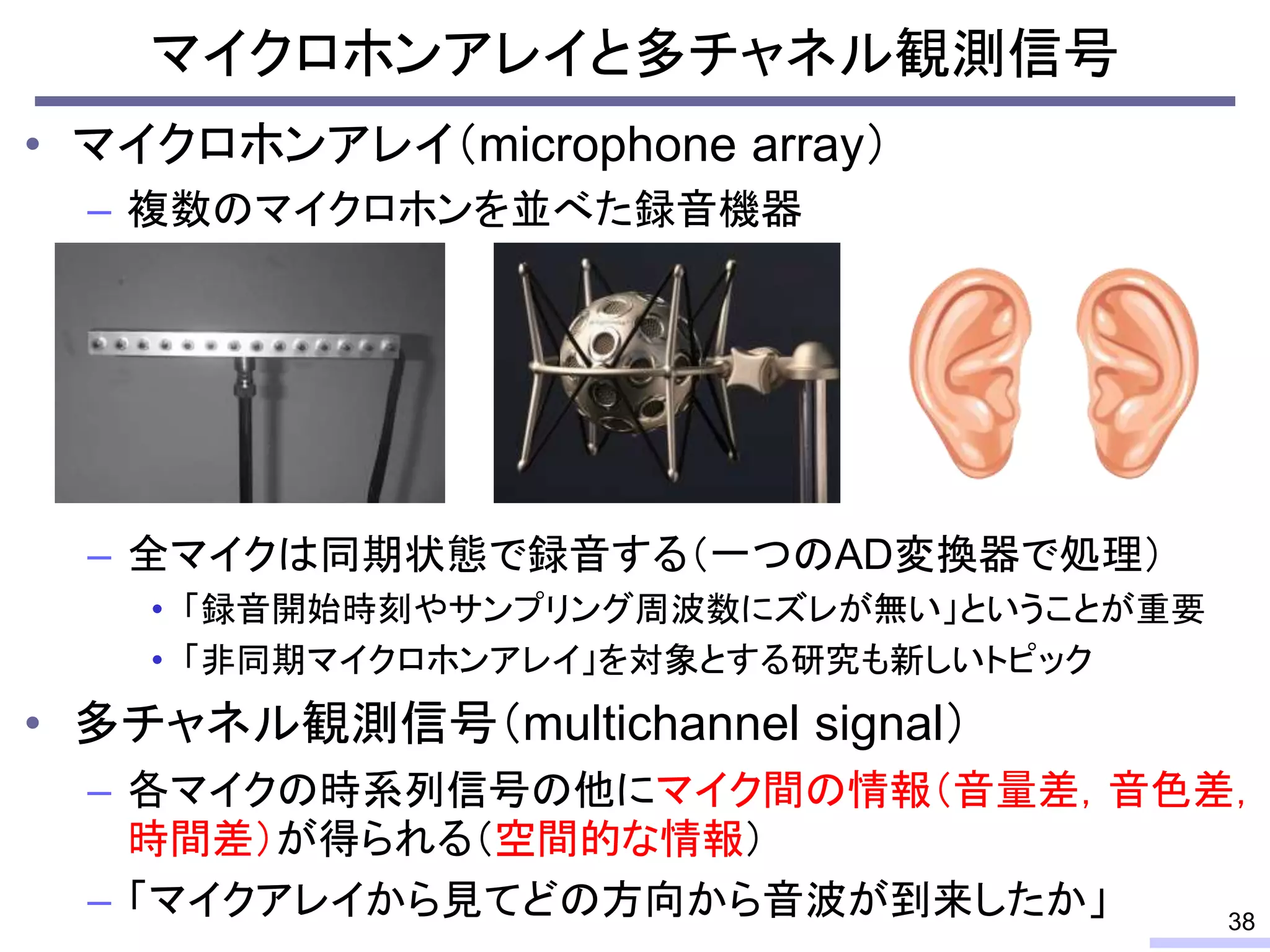
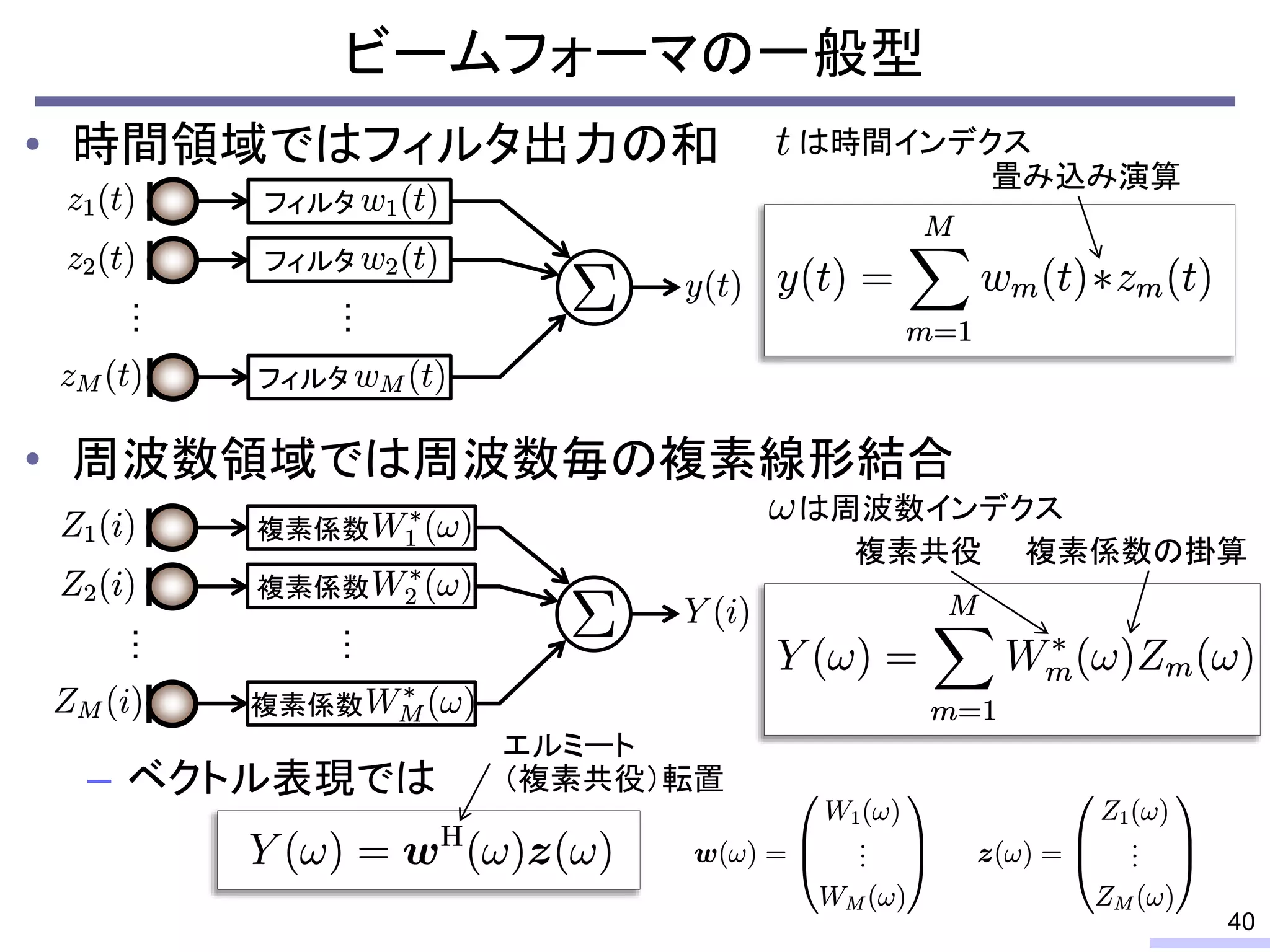
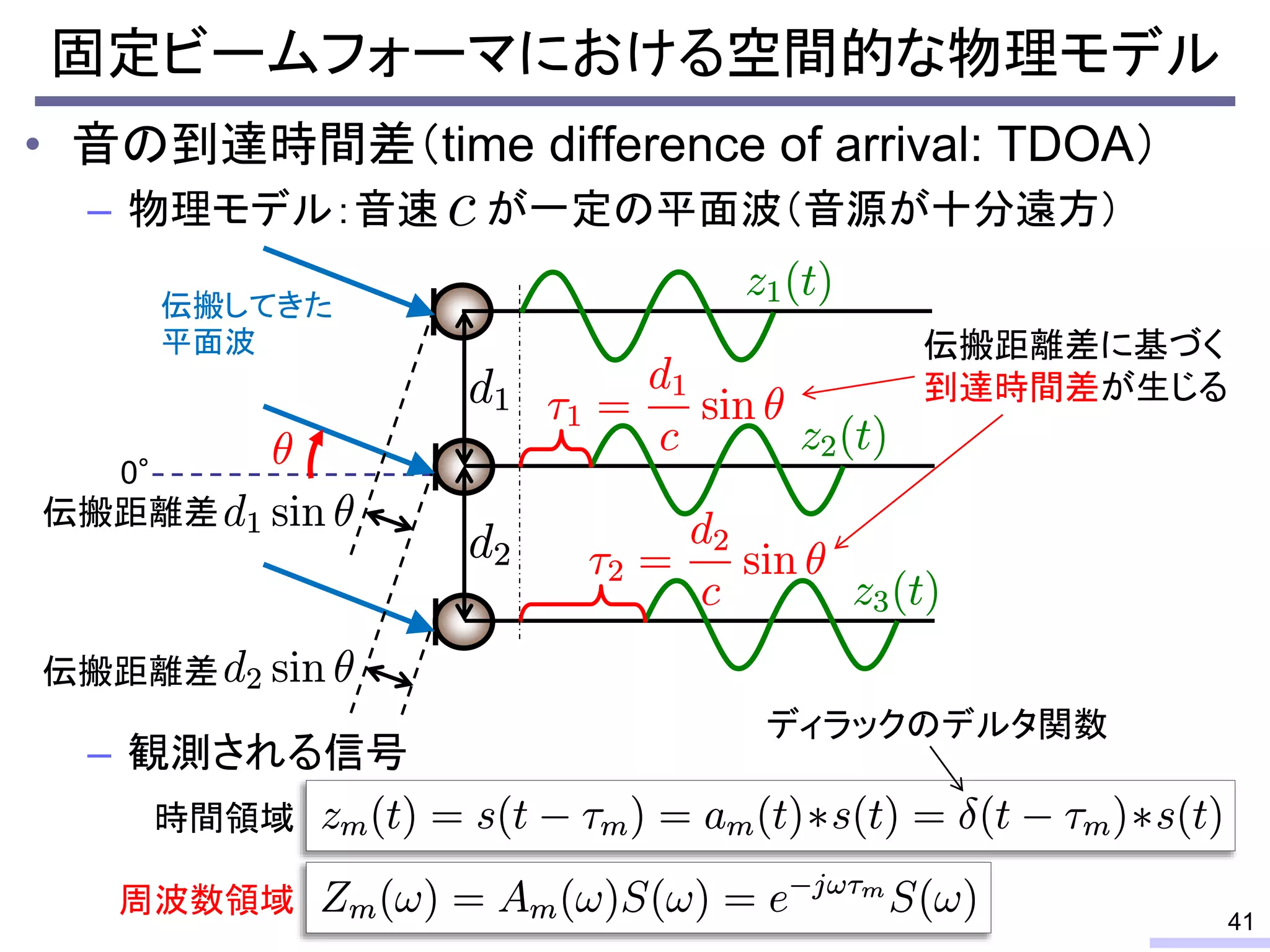
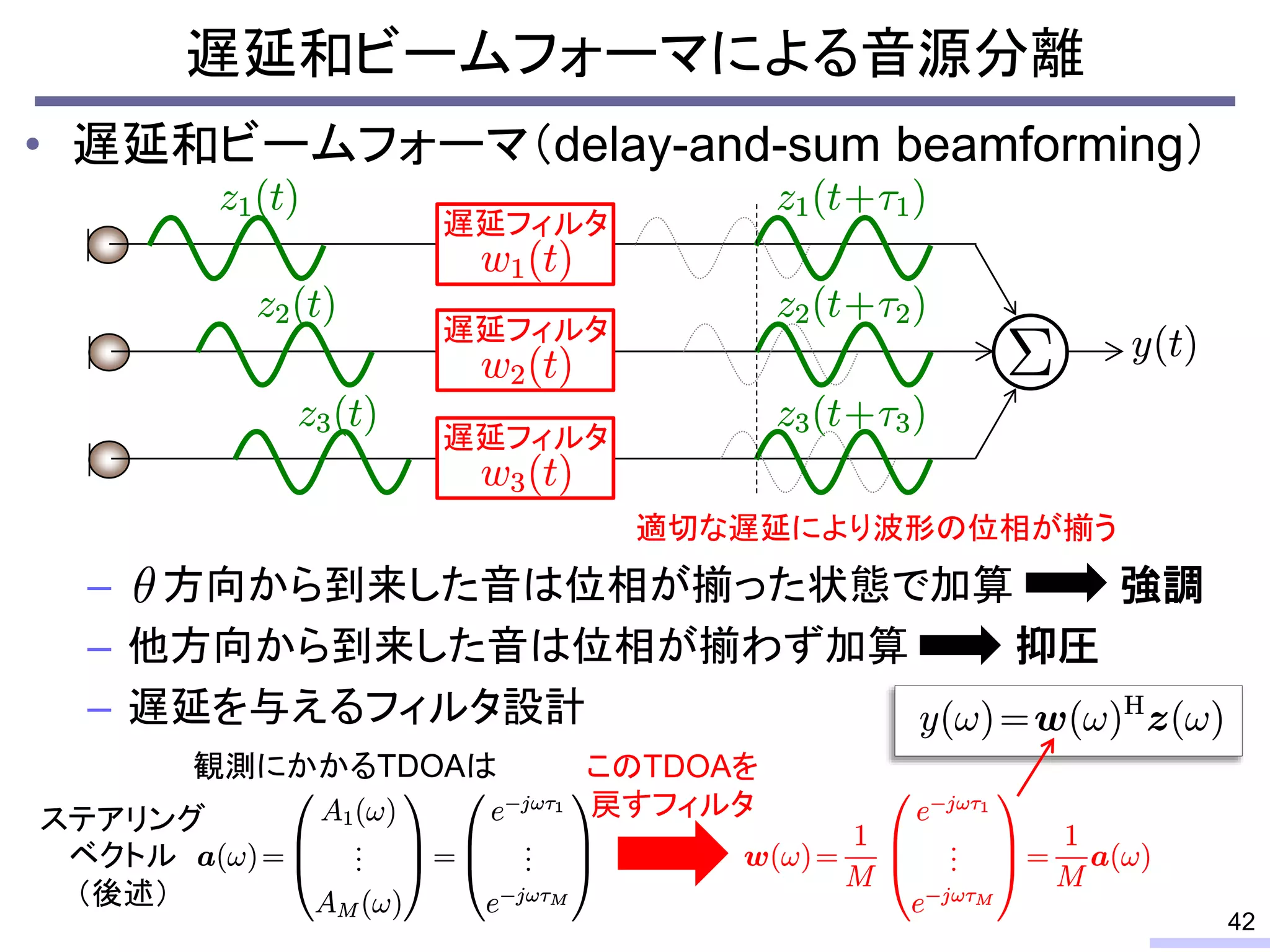
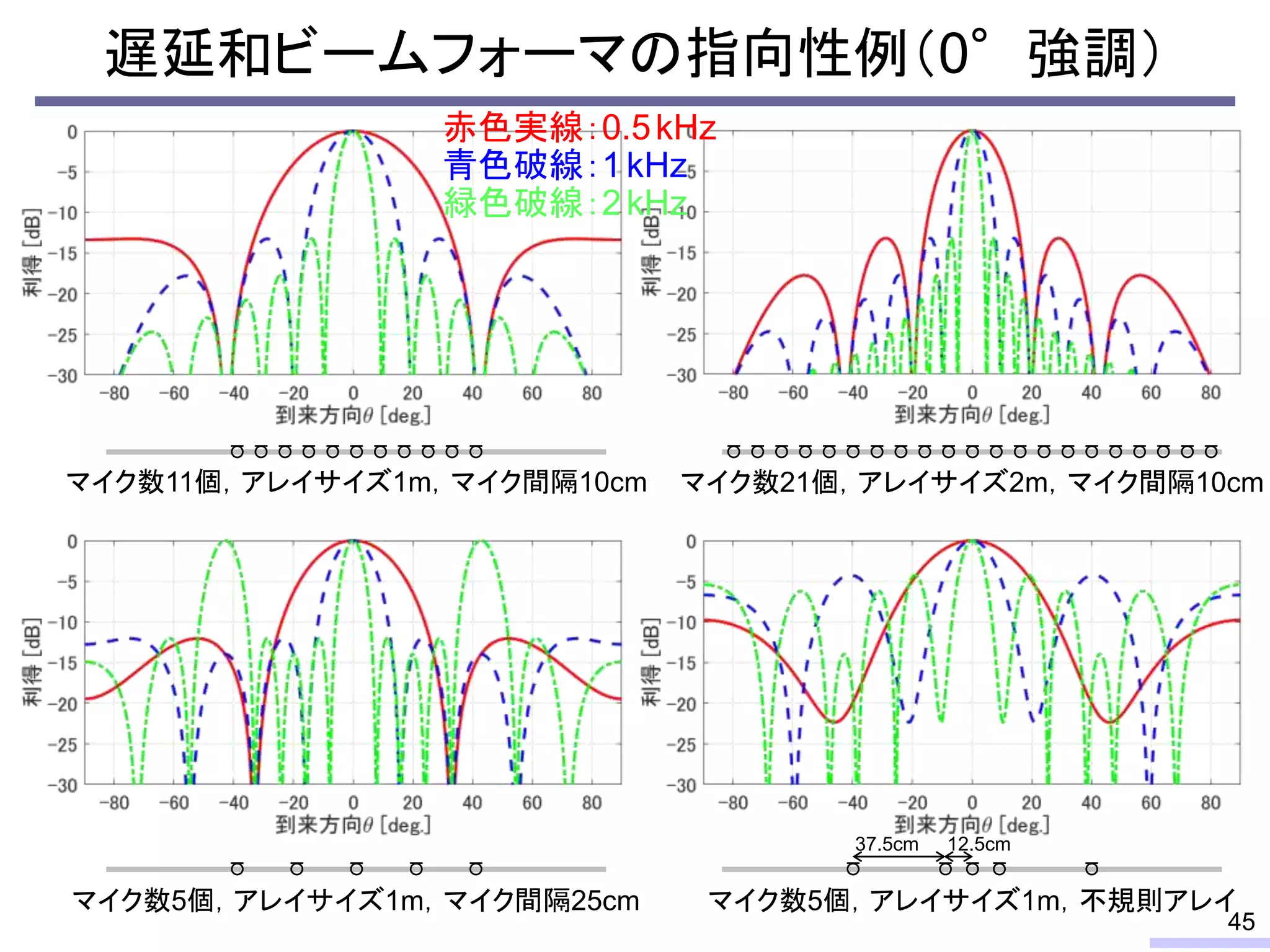
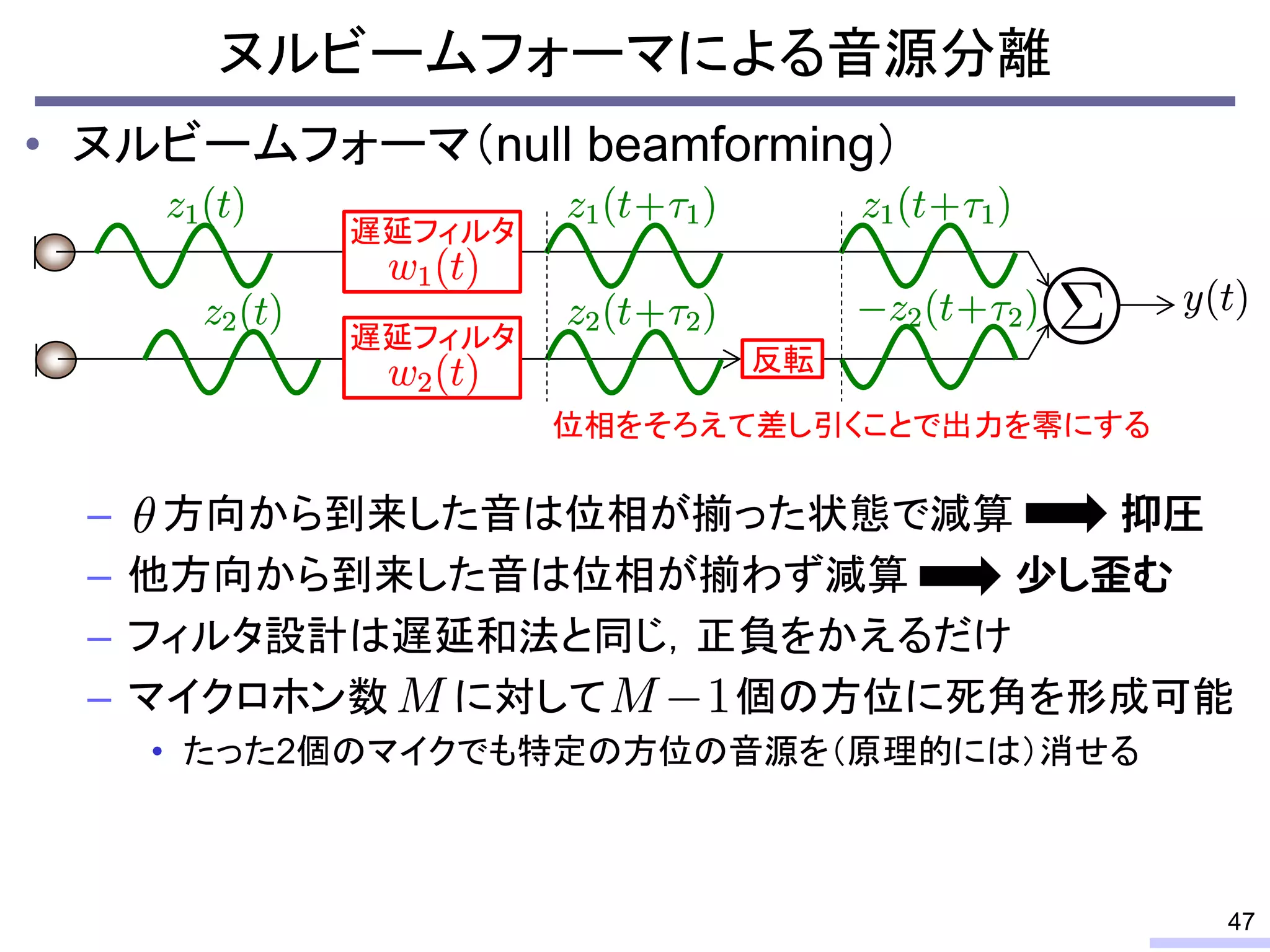
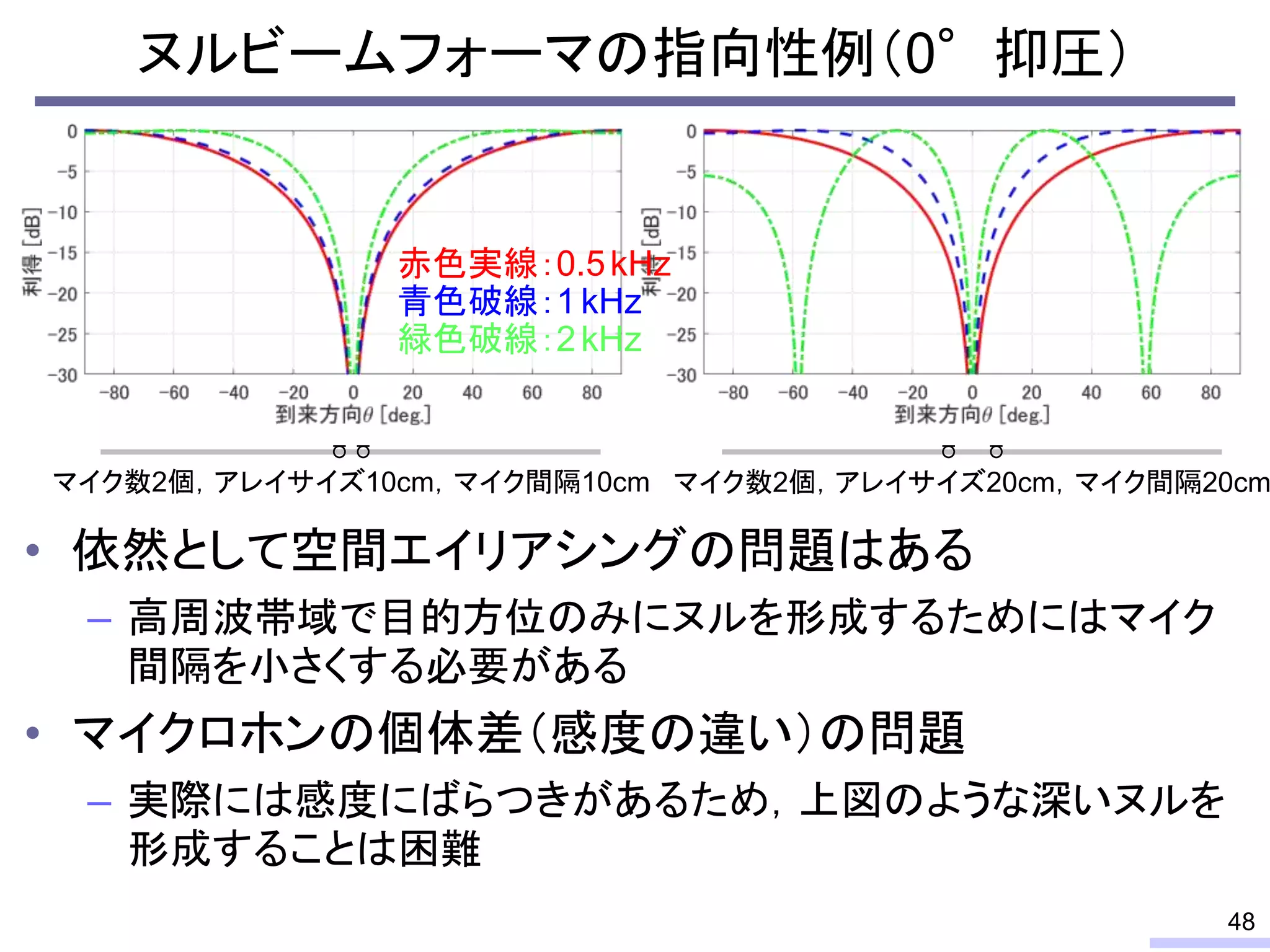
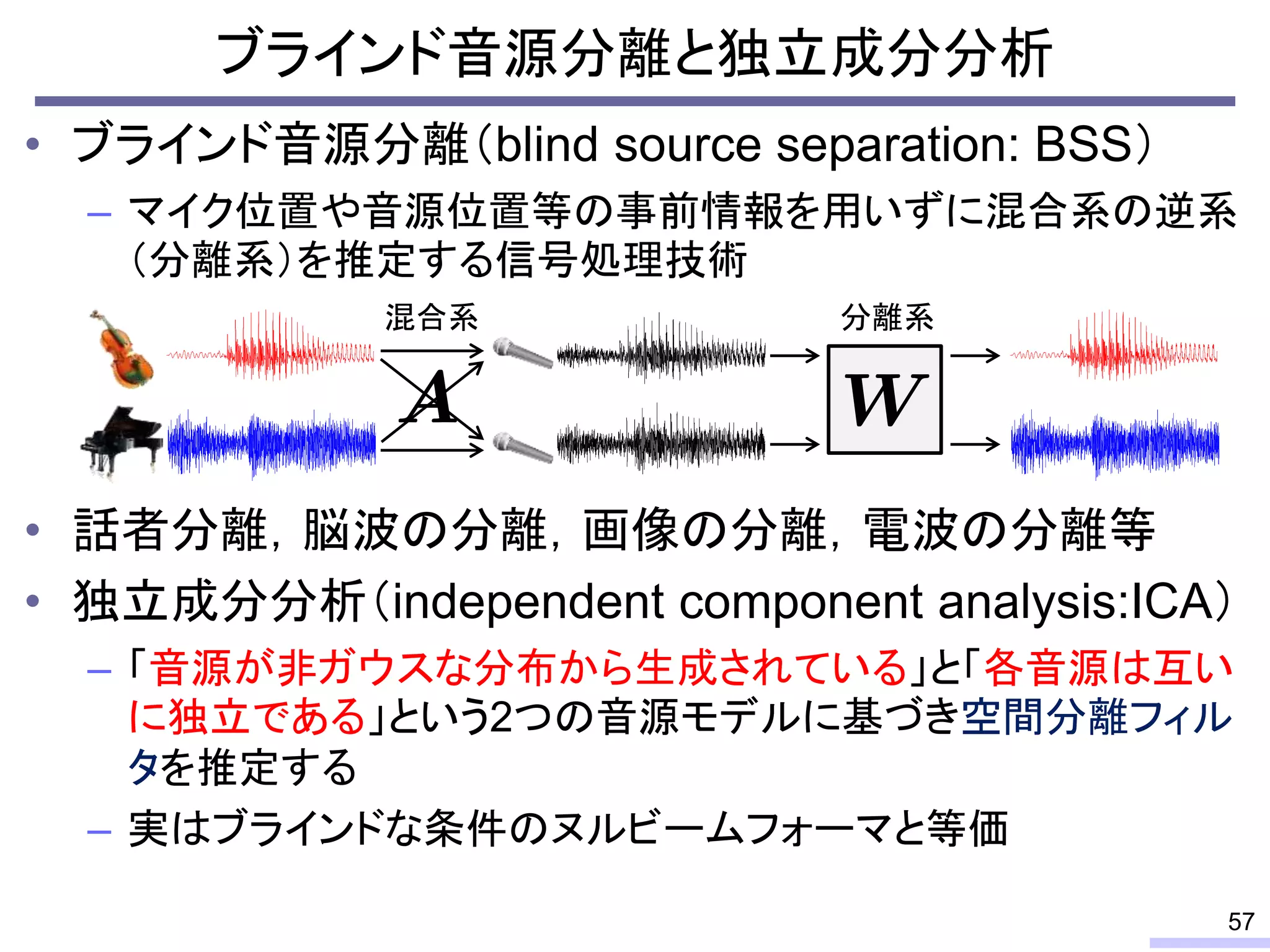
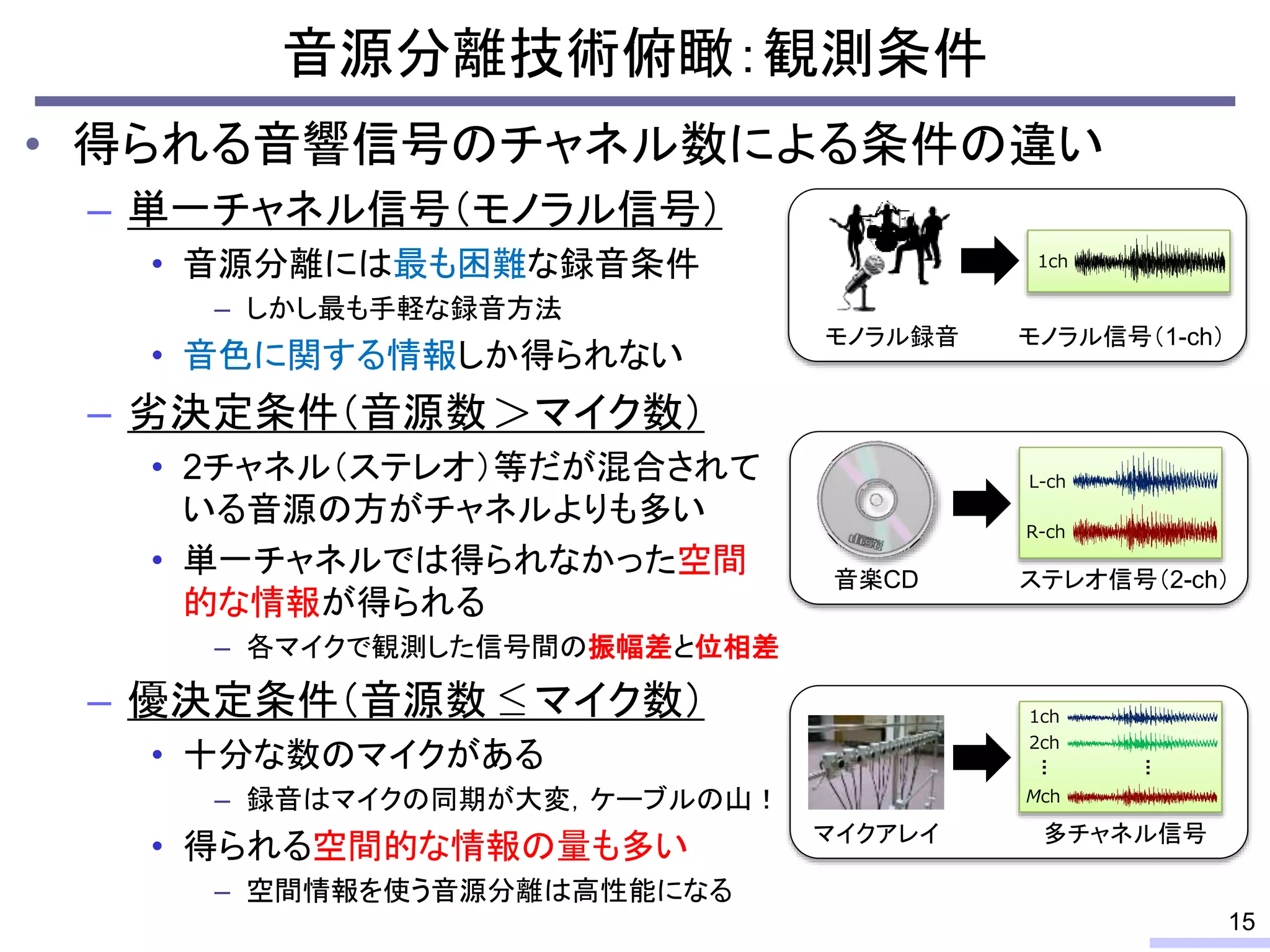
So, we don’t require an information of positions of each microphone, position of sources, or recording environment.
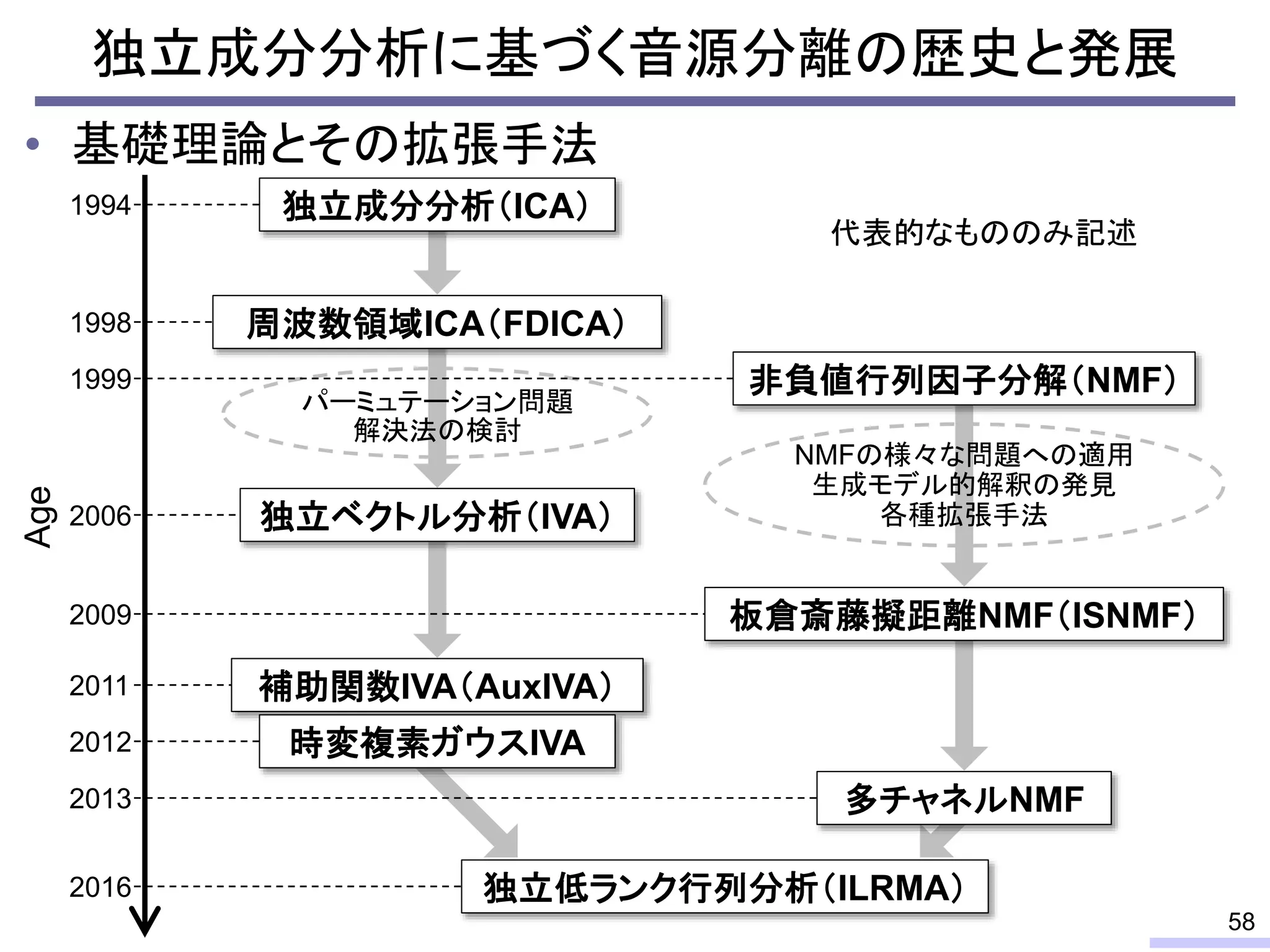
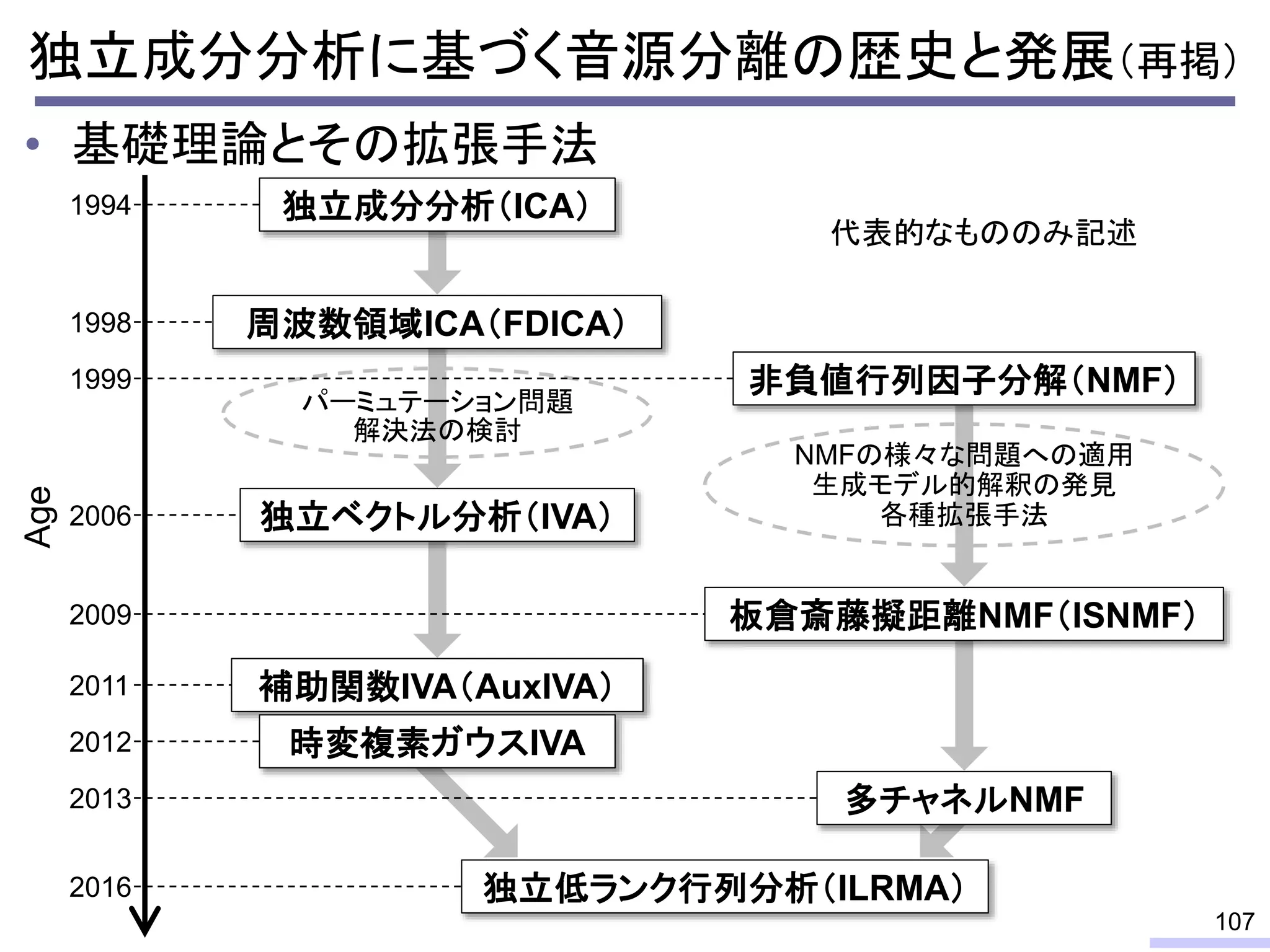
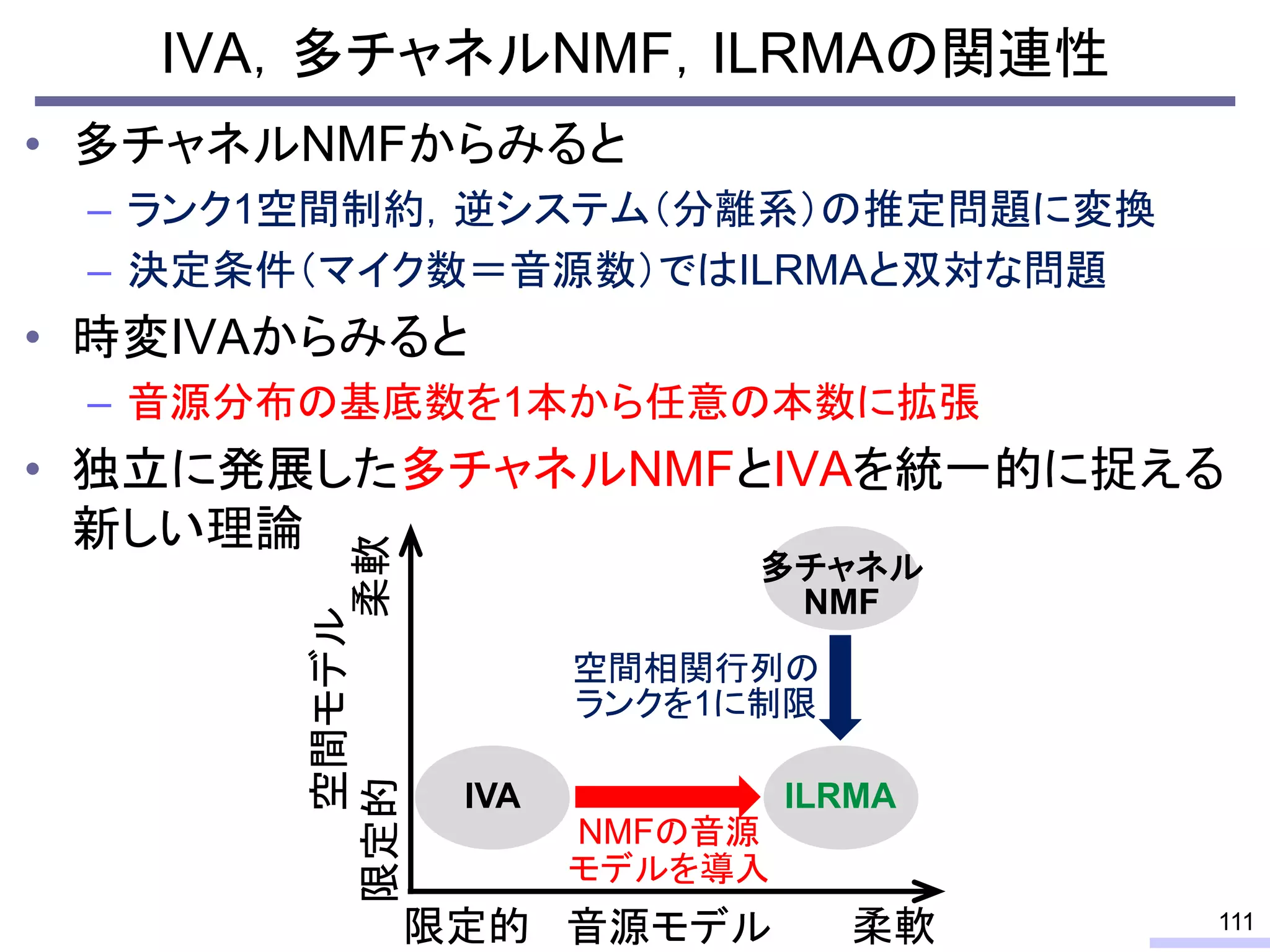
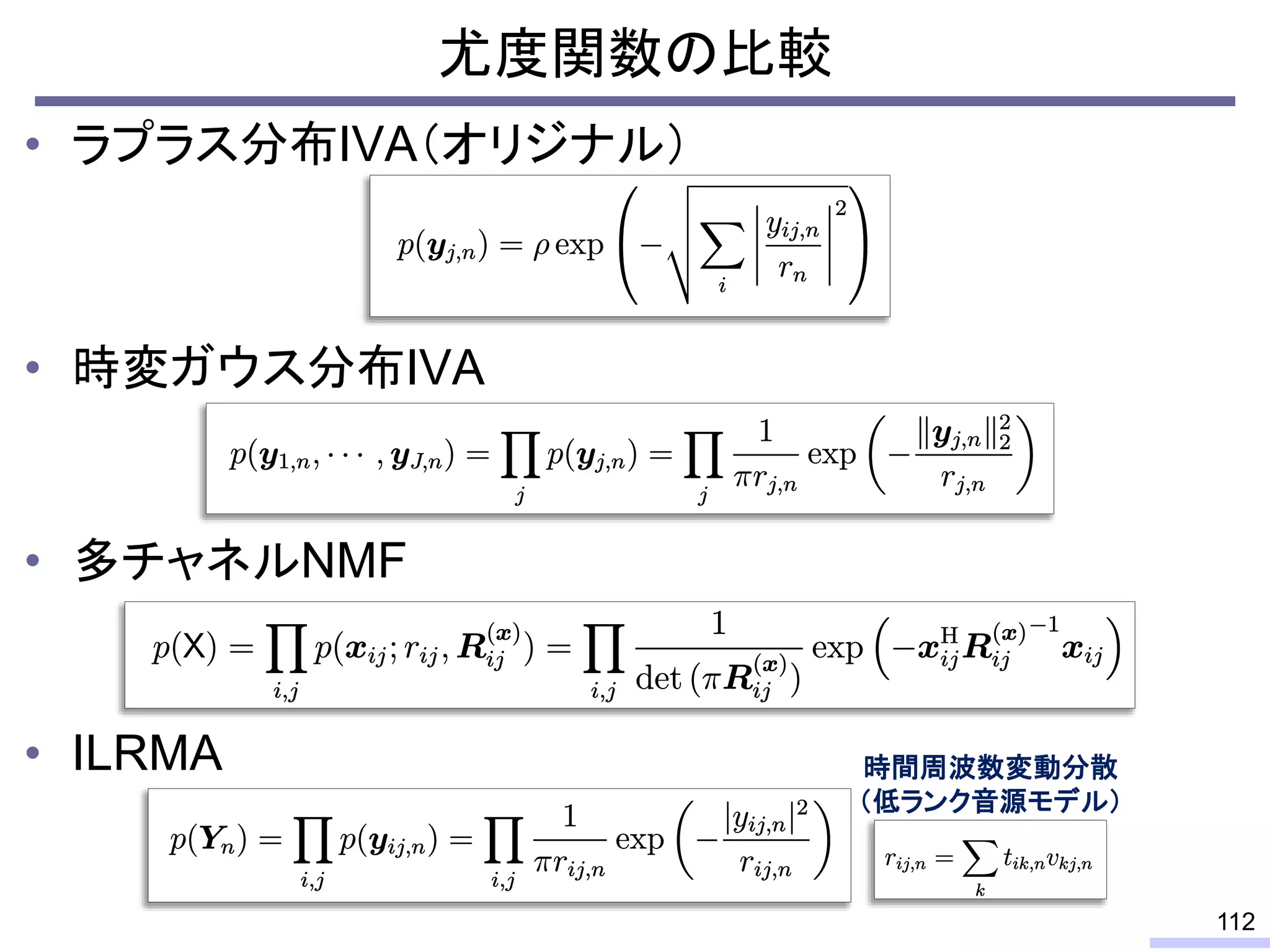
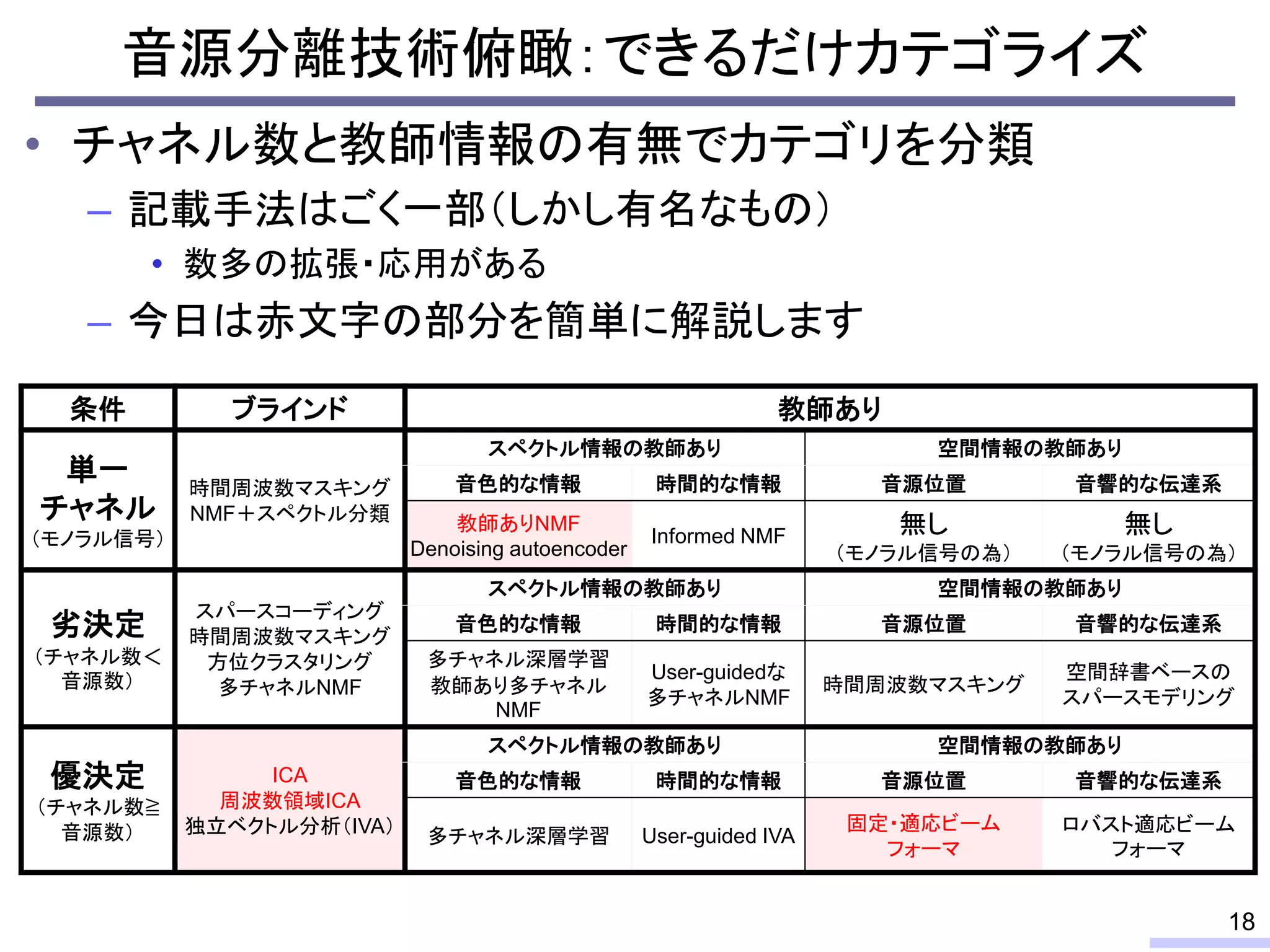
#59 This is a history of basic theories in audio BSS field.
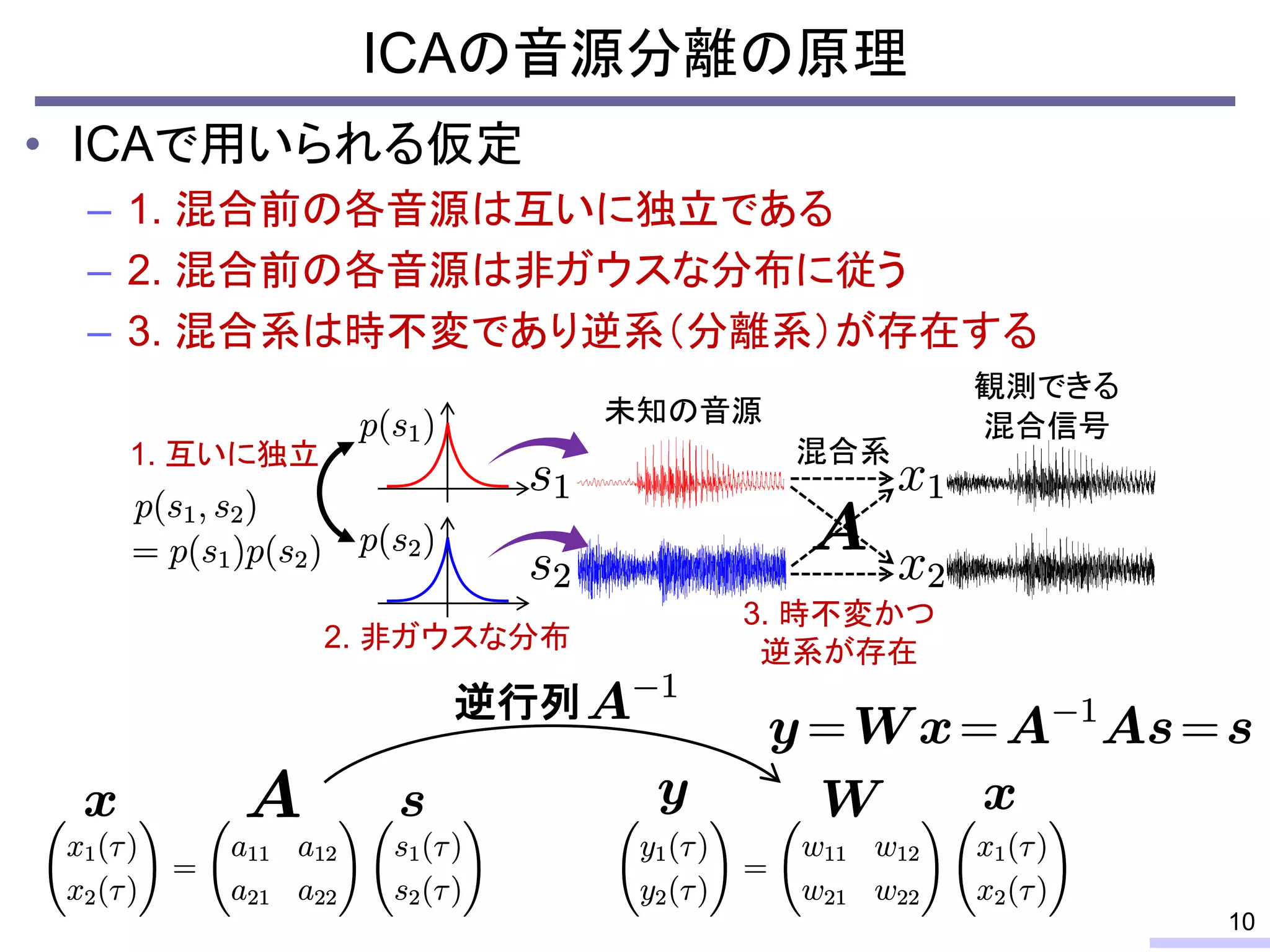
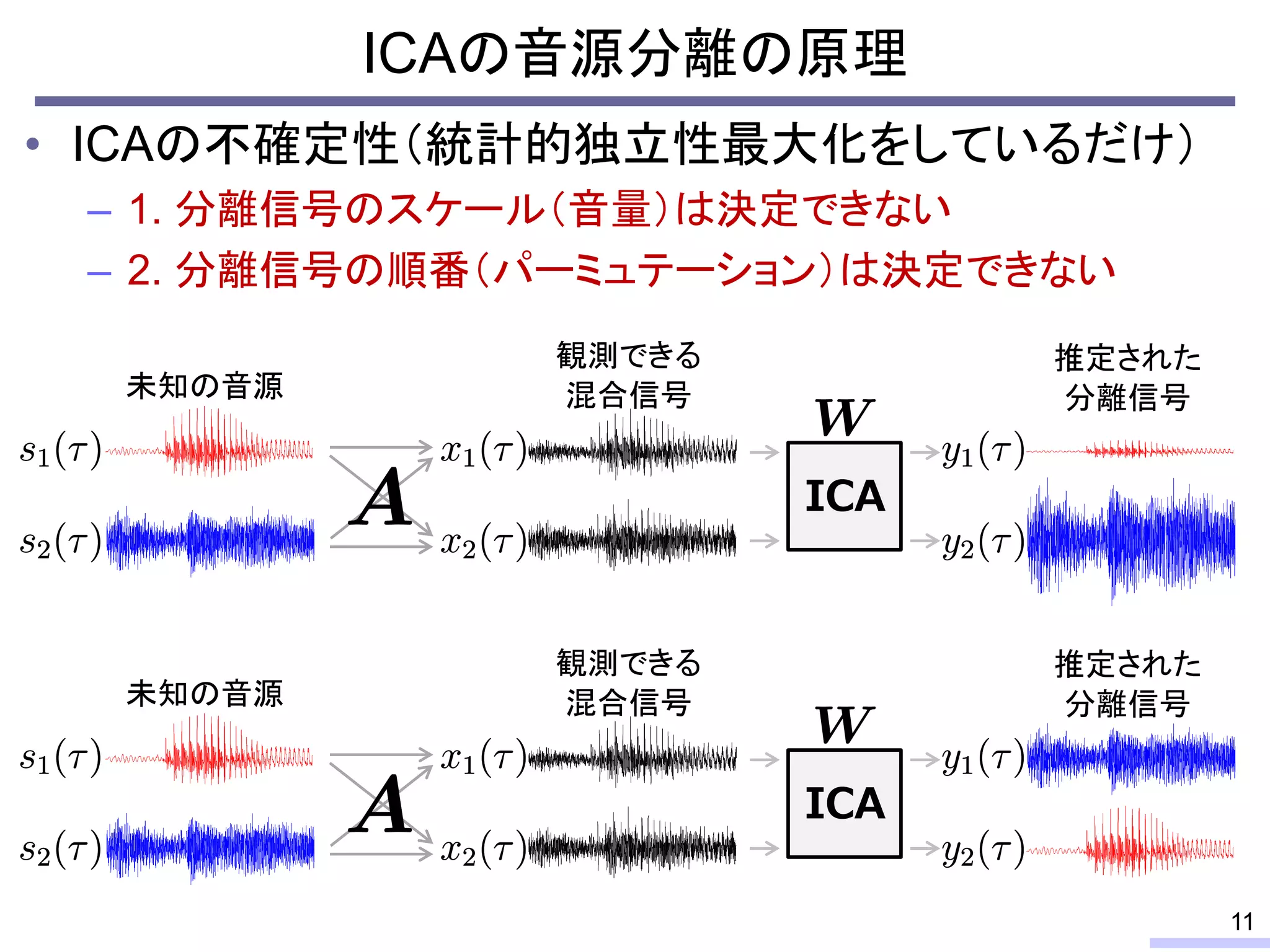
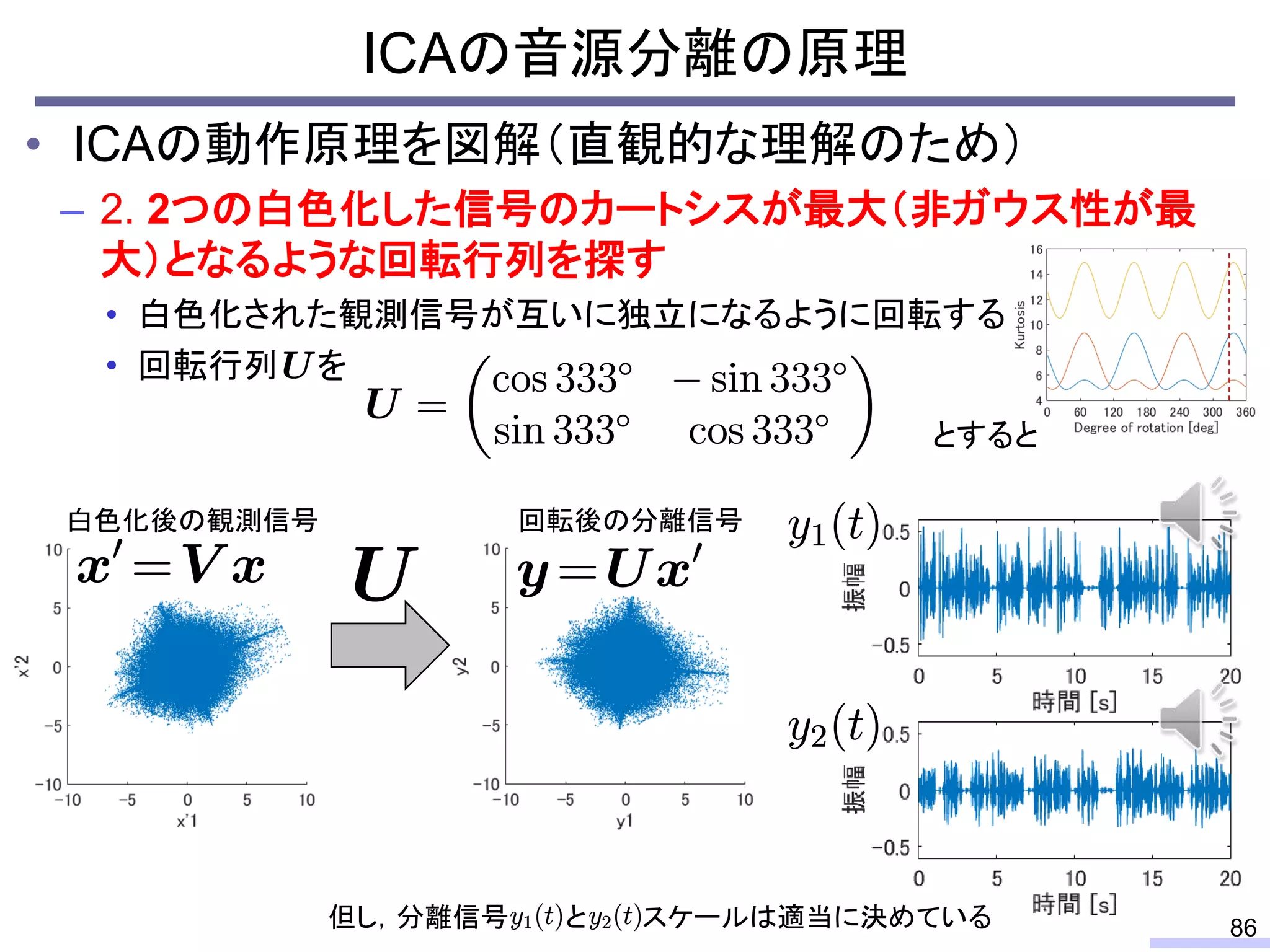
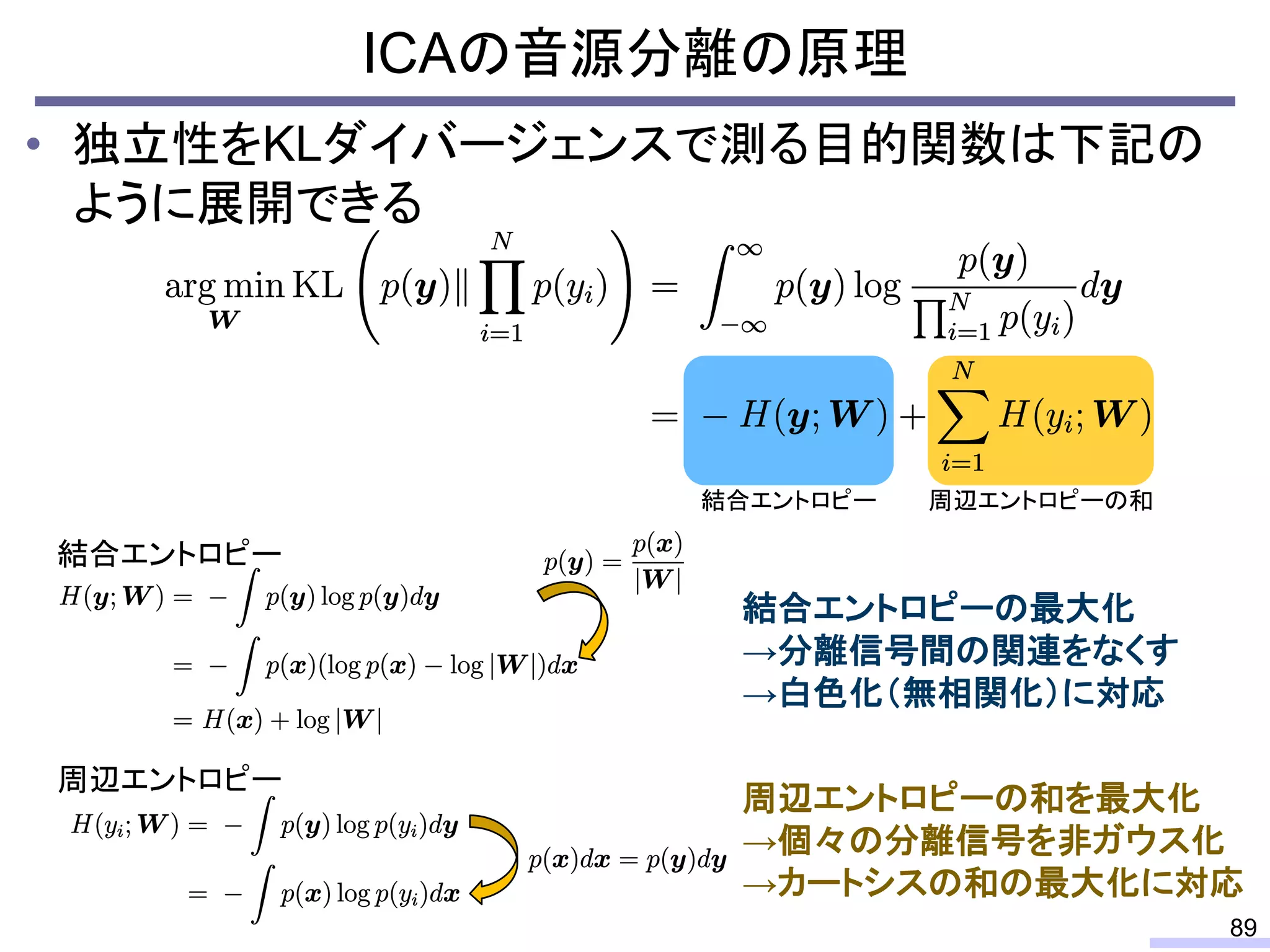
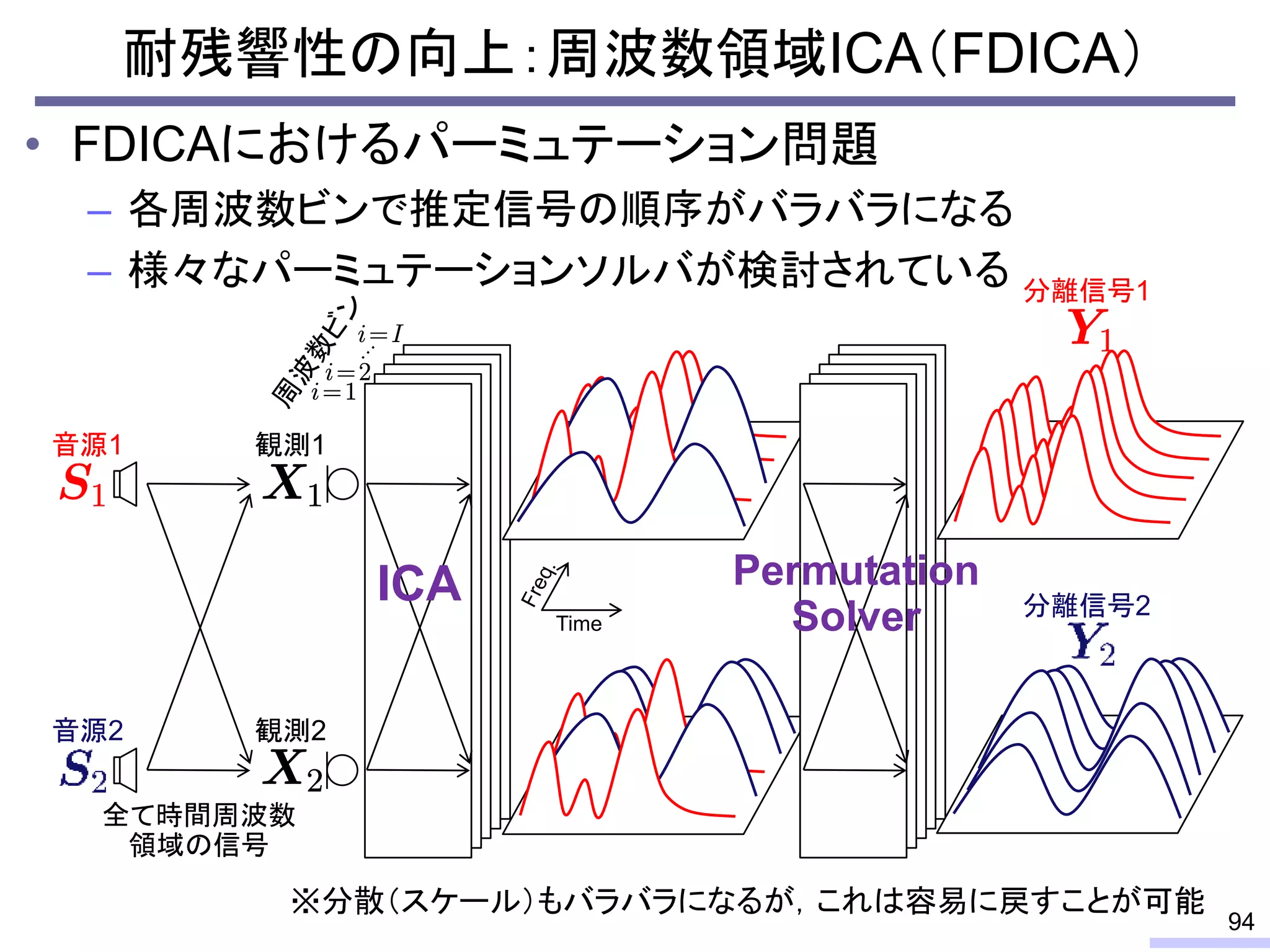
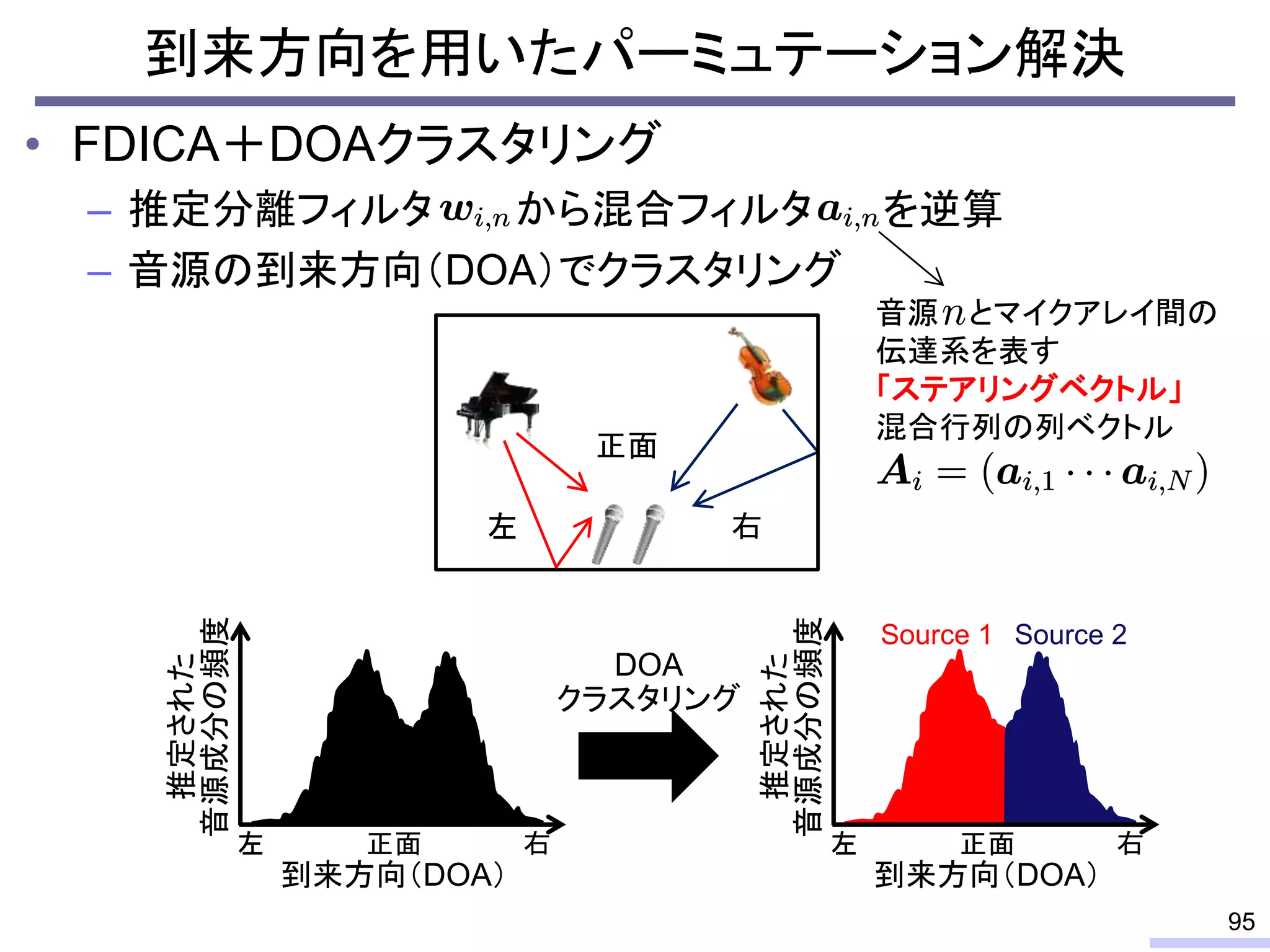
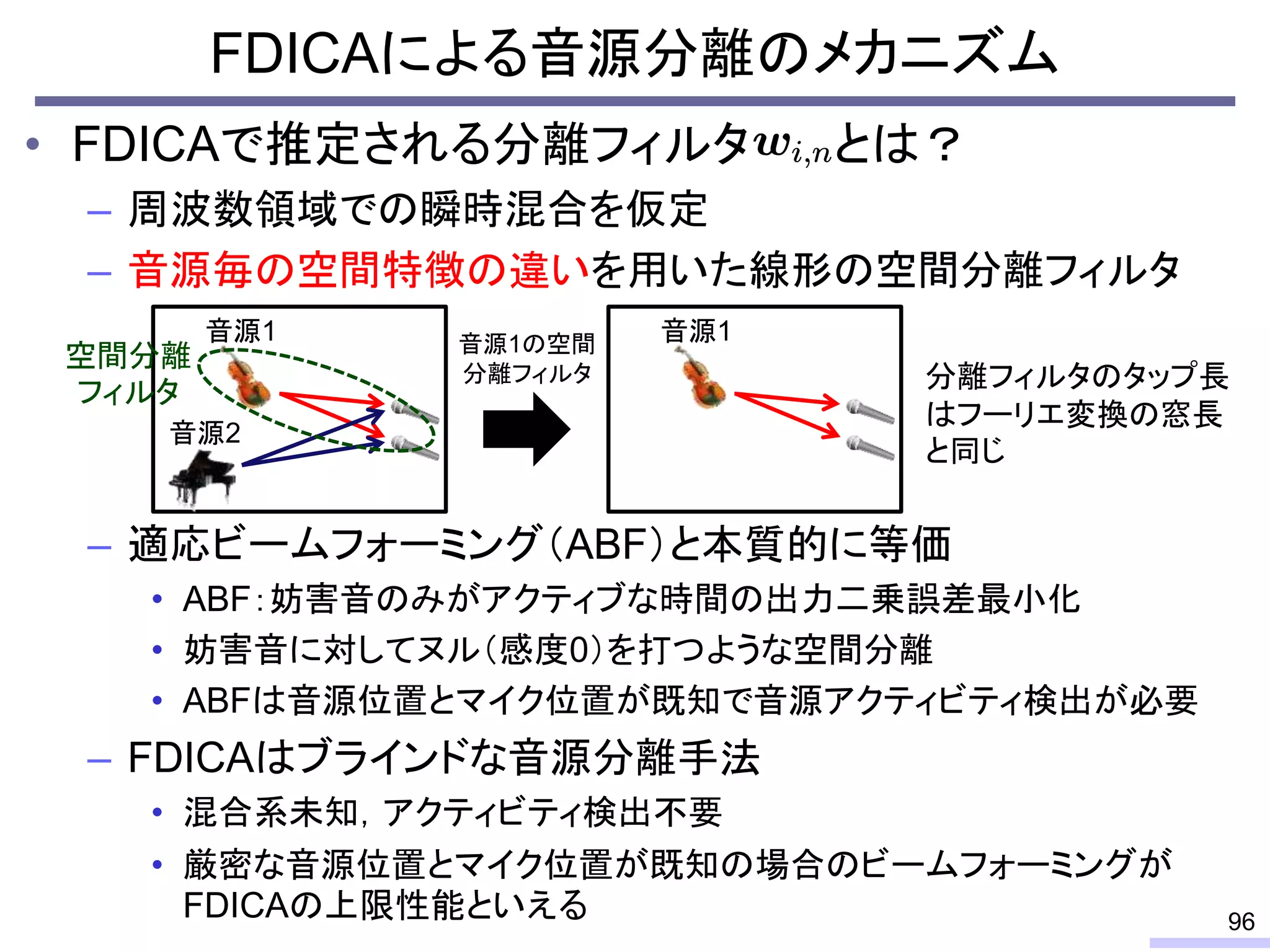
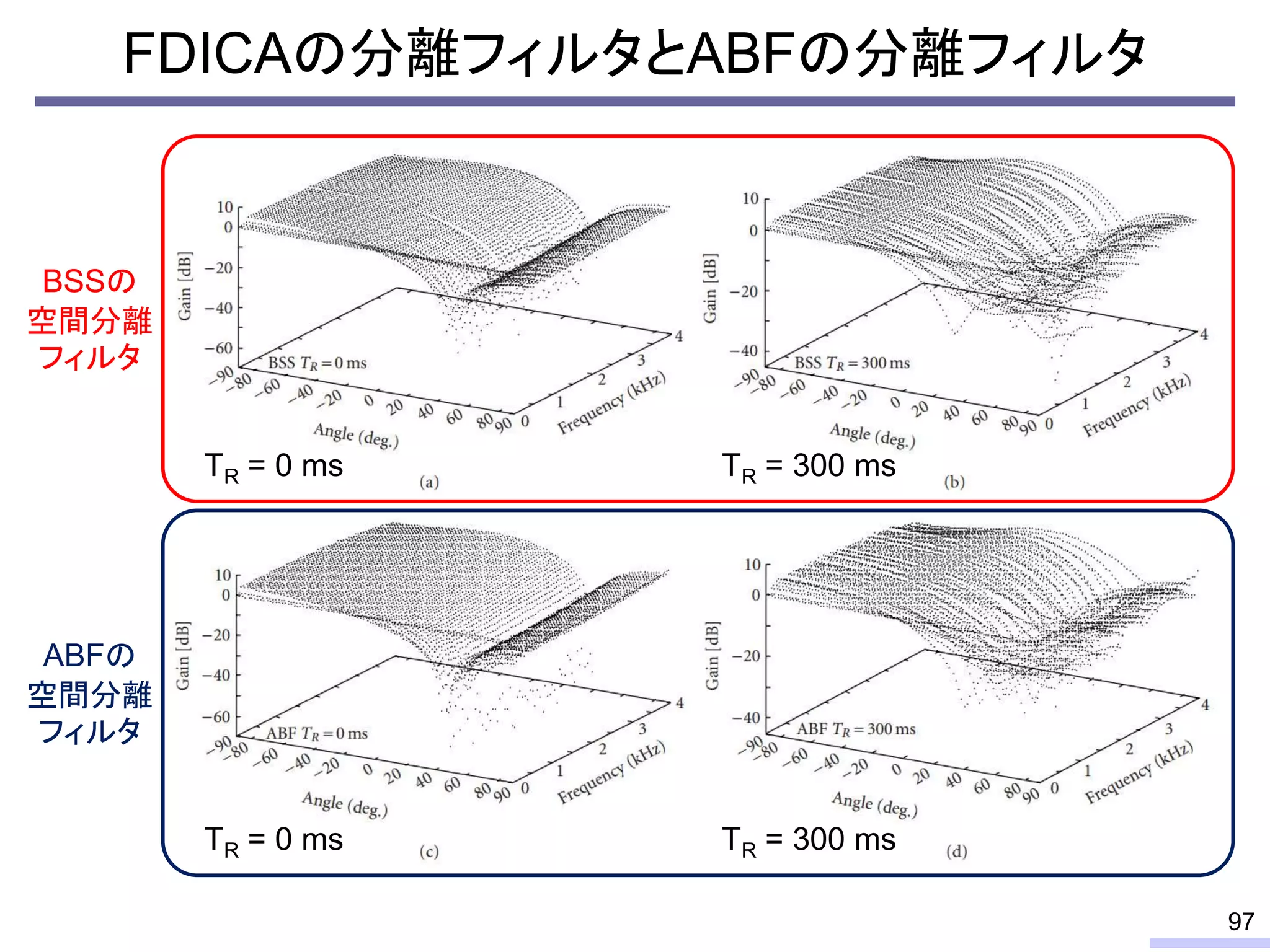
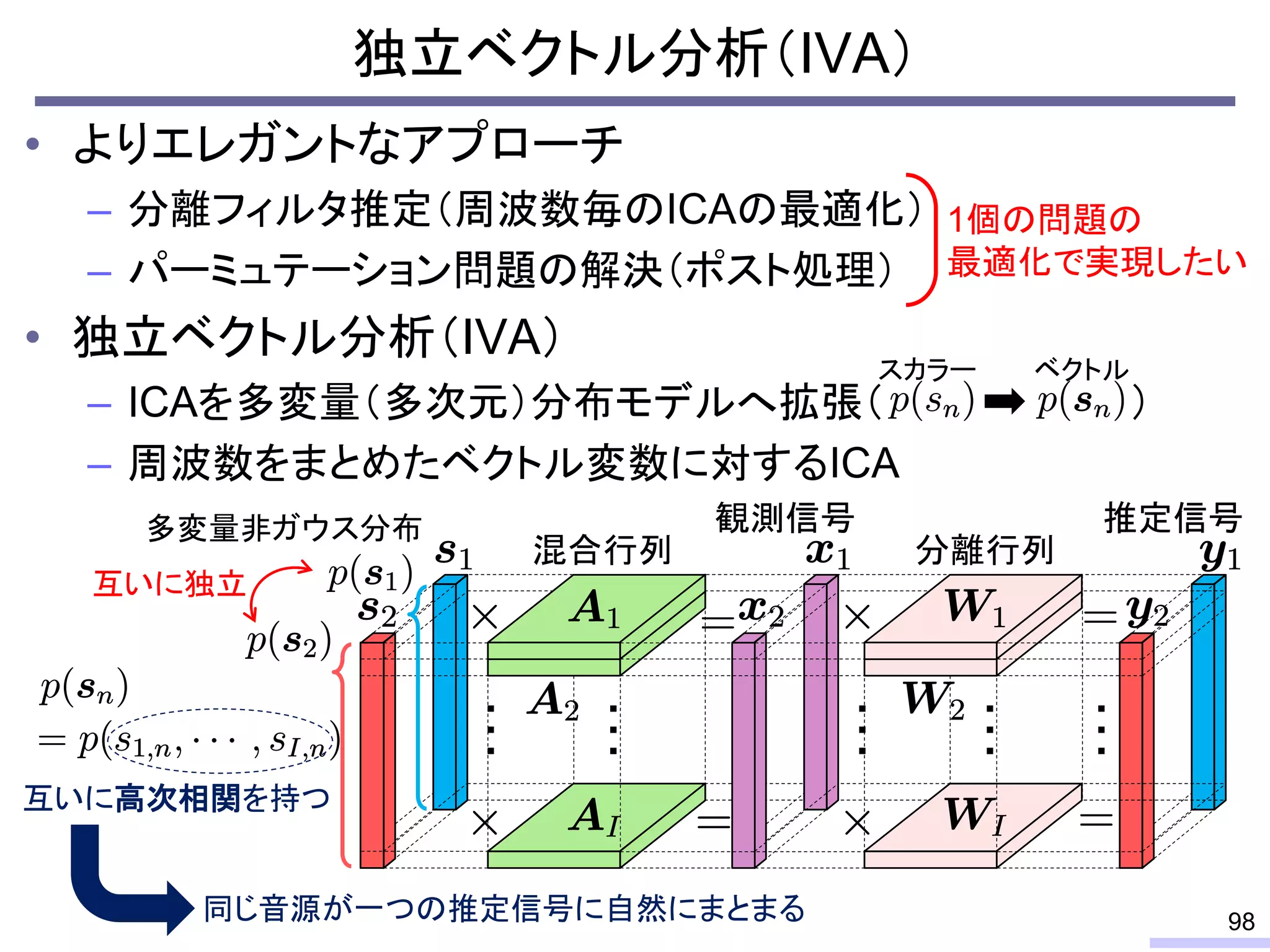
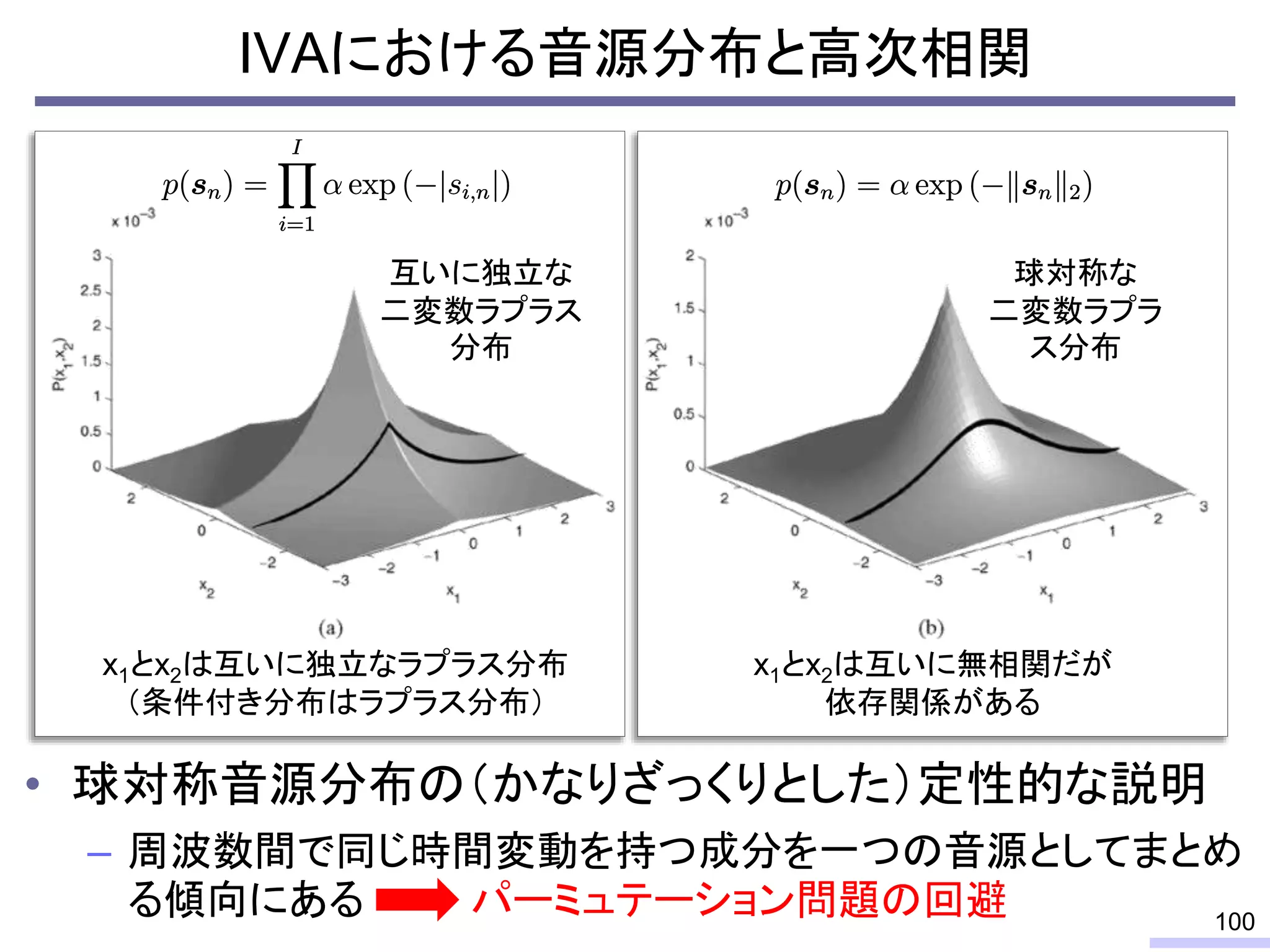
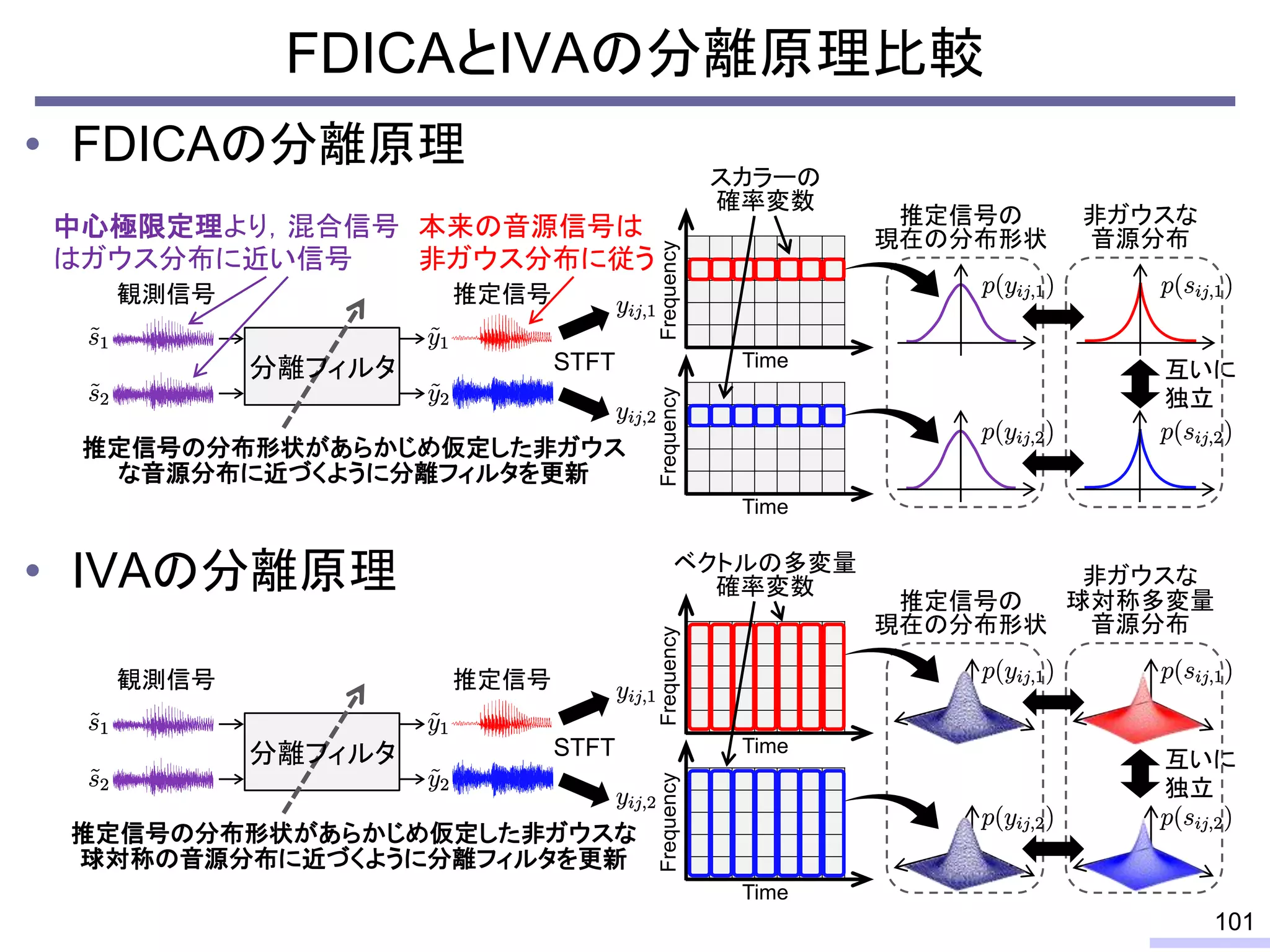
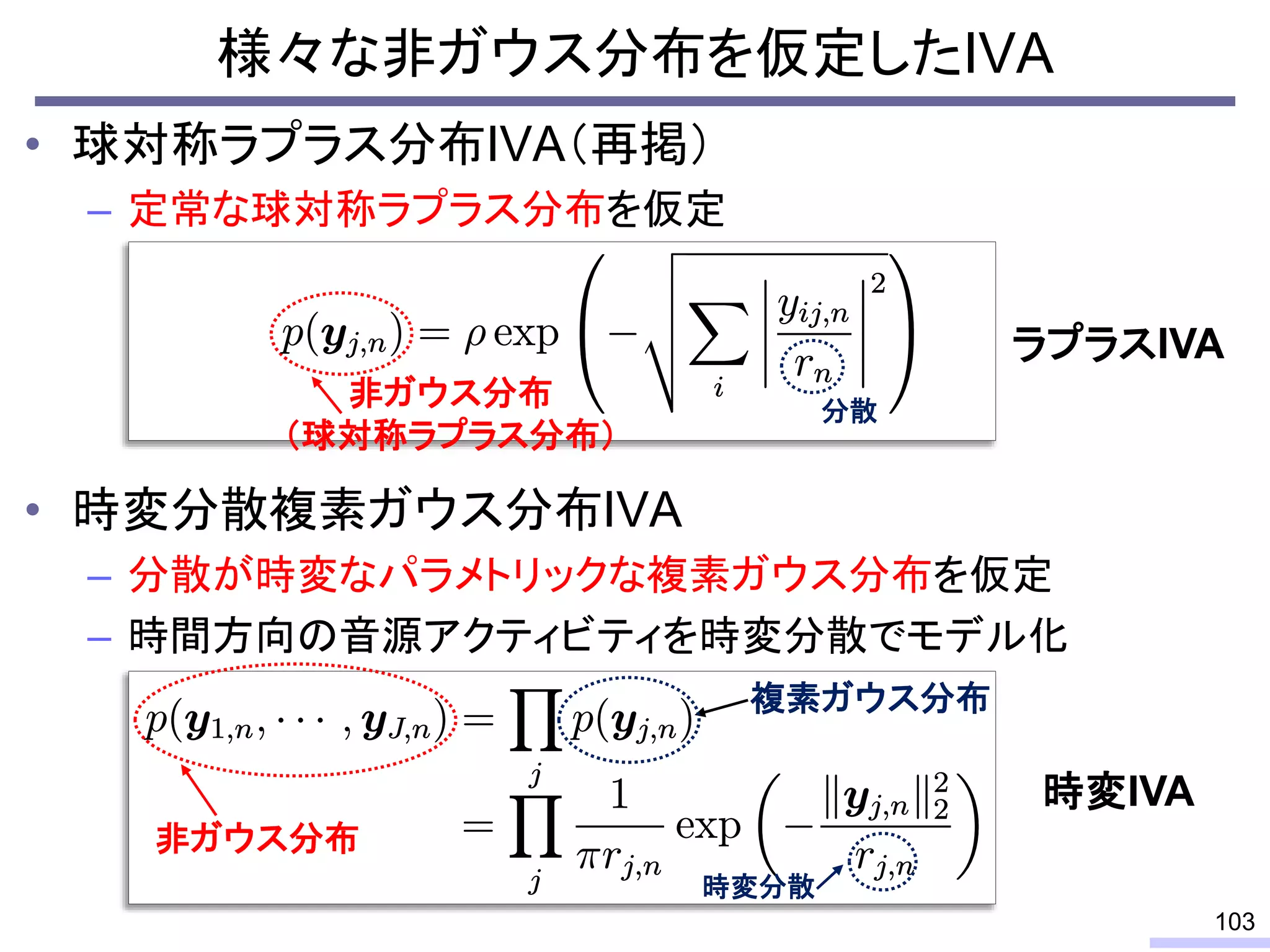
For acoustic signals, independent component analysis, ICA, was applied to the frequency domain signals as FDICA. After that, many permutation solvers for FDICA have been proposed, but eventually, an elegant solution, independent vector analysis, IVA was proposed. It is still extended to more flexible models.
On the other hand, nonnegative matrix factorization, NMF, is also developed and extended to a multichannel signals for source separation problems.
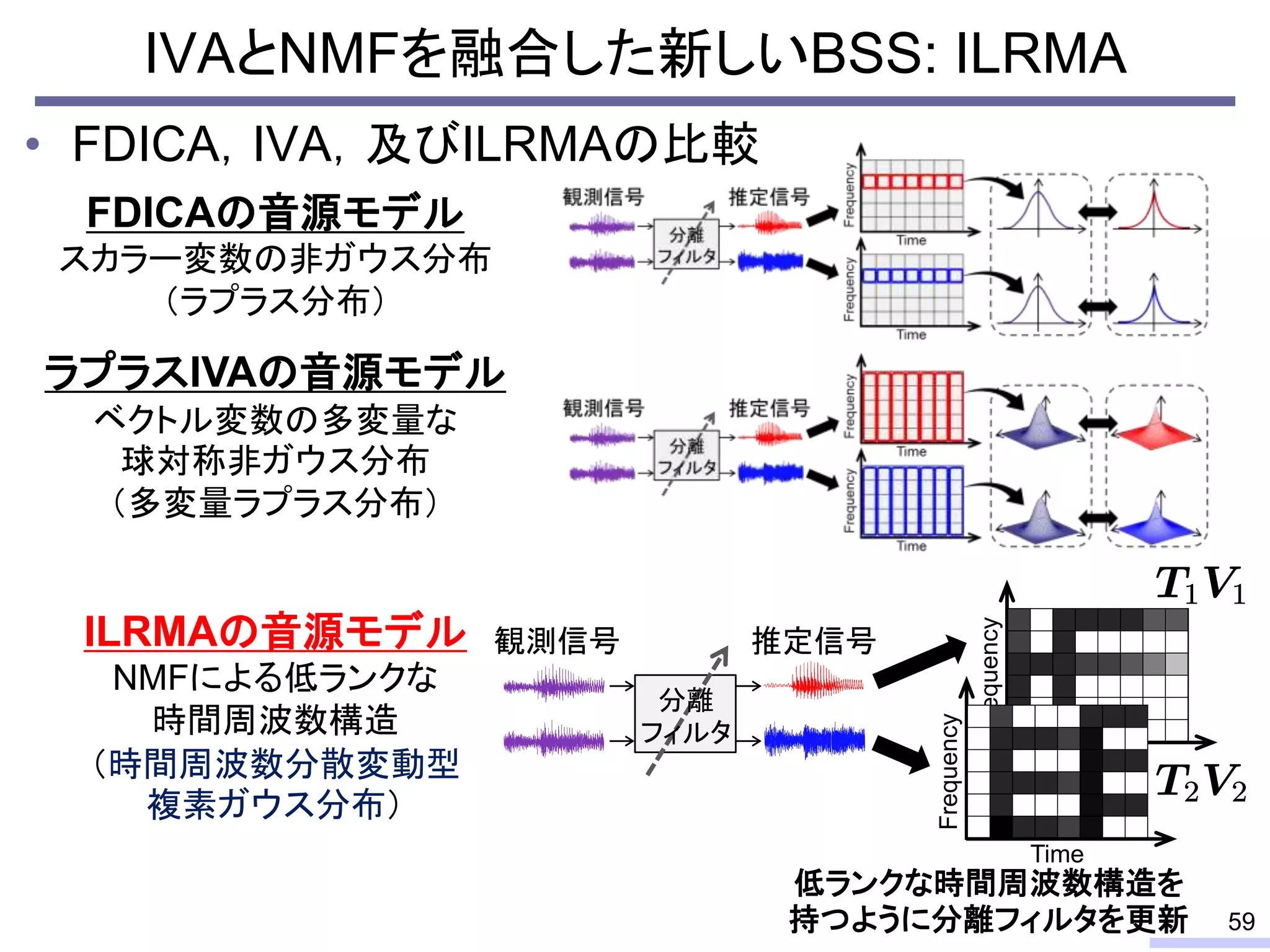
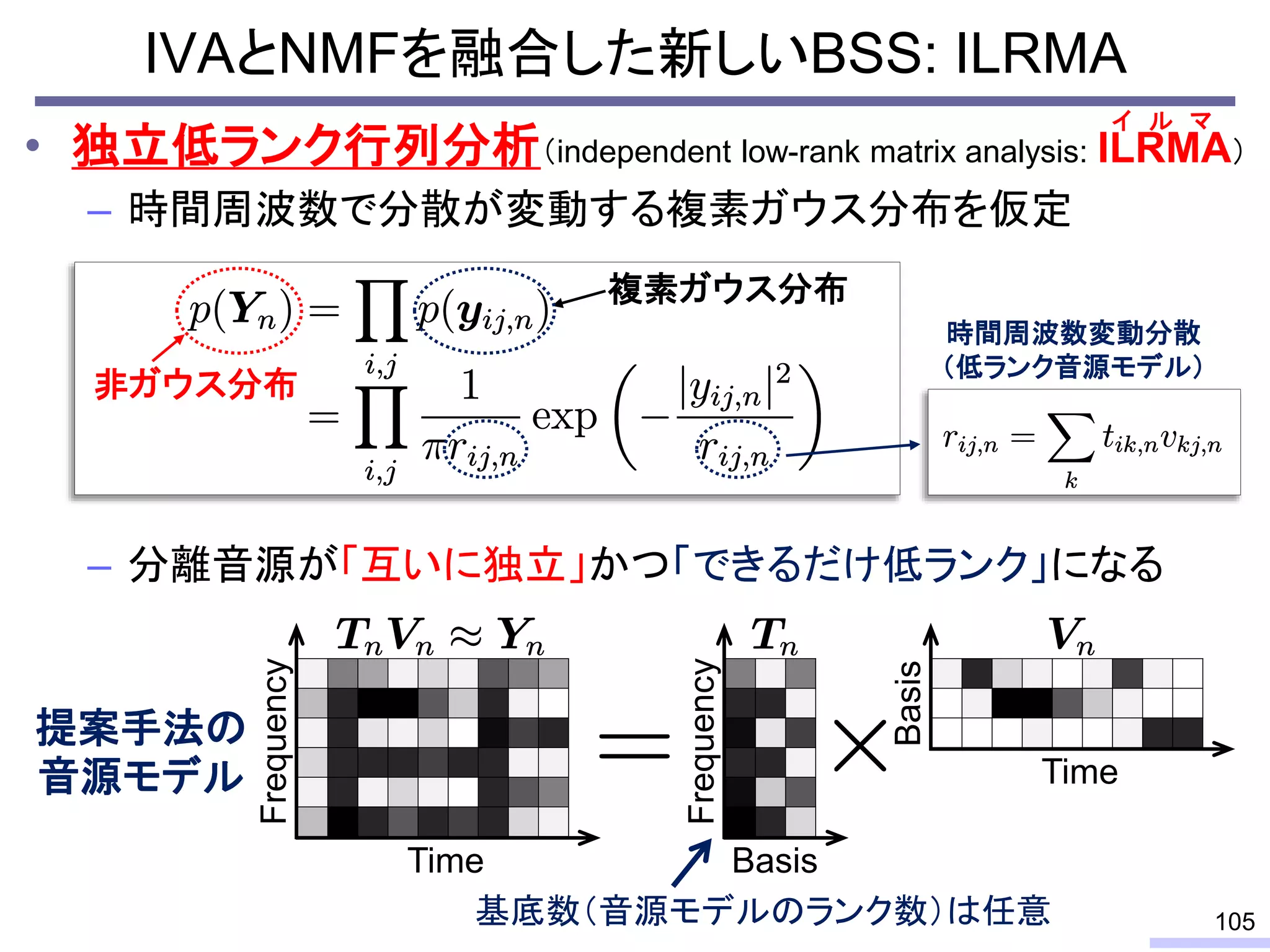
Recently, we have developed a new framework, which unifies these two powerful theories, called independent low-rank matrix analysis, ILRMA.
I will explain about the detail.
#108 This is a history of basic theories in audio BSS field.
For acoustic signals, independent component analysis, ICA, was applied to the frequency domain signals as FDICA. After that, many permutation solvers for FDICA have been proposed, but eventually, an elegant solution, independent vector analysis, IVA was proposed. It is still extended to more flexible models.
On the other hand, nonnegative matrix factorization, NMF, is also developed and extended to a multichannel signals for source separation problems.
Recently, we have developed a new framework, which unifies these two powerful theories, called independent low-rank matrix analysis, ILRMA.
I will explain about the detail.

















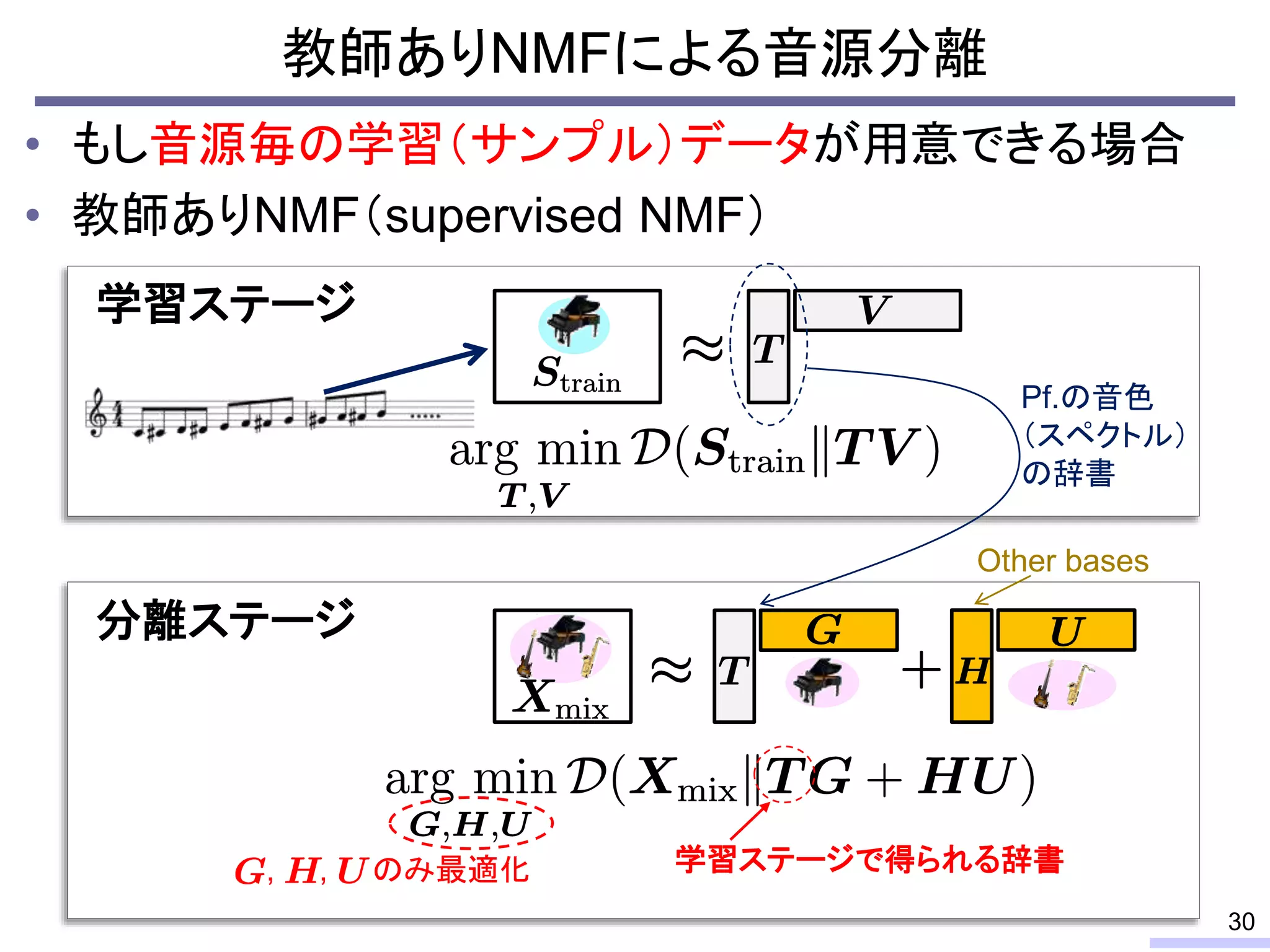

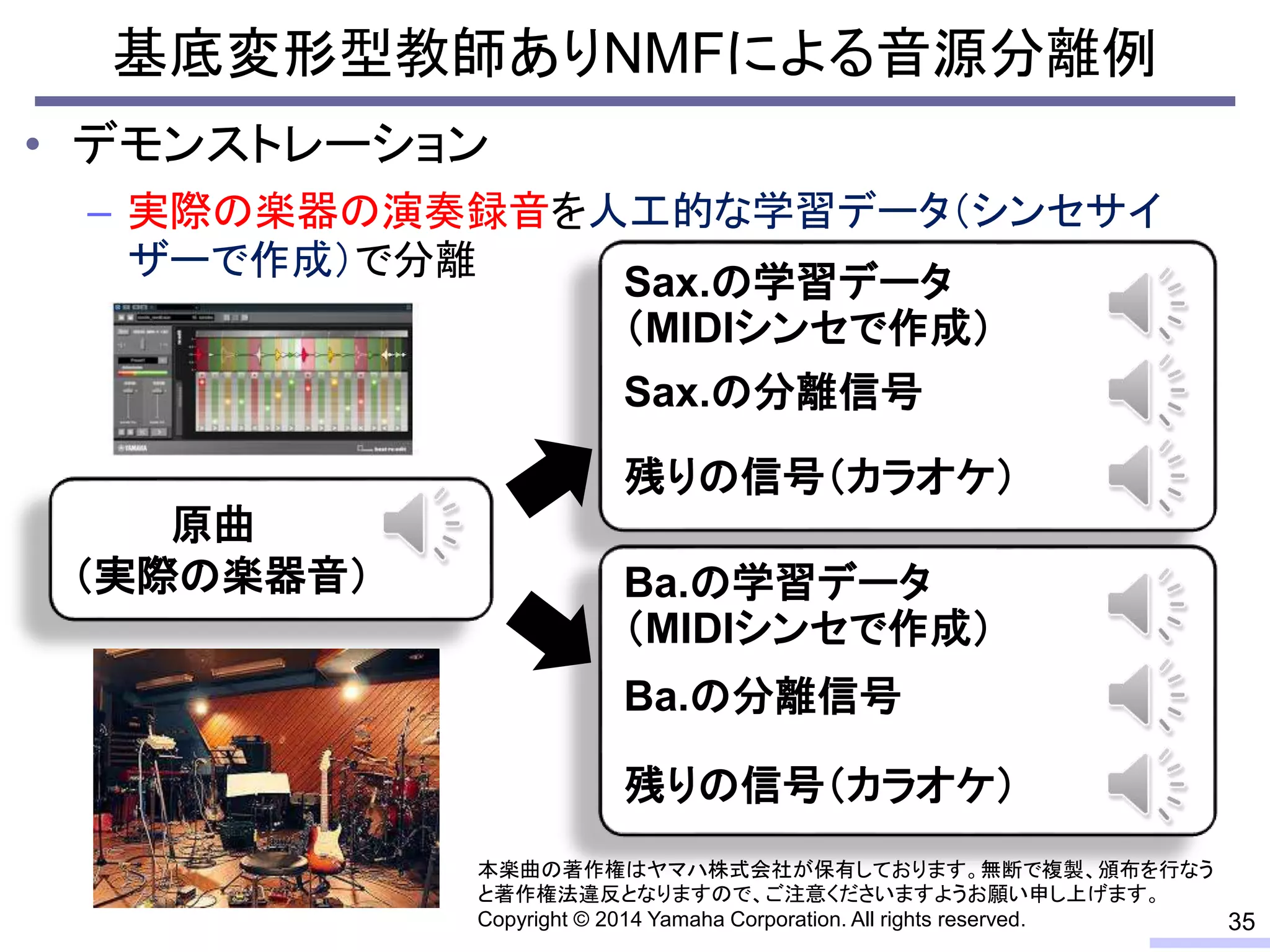
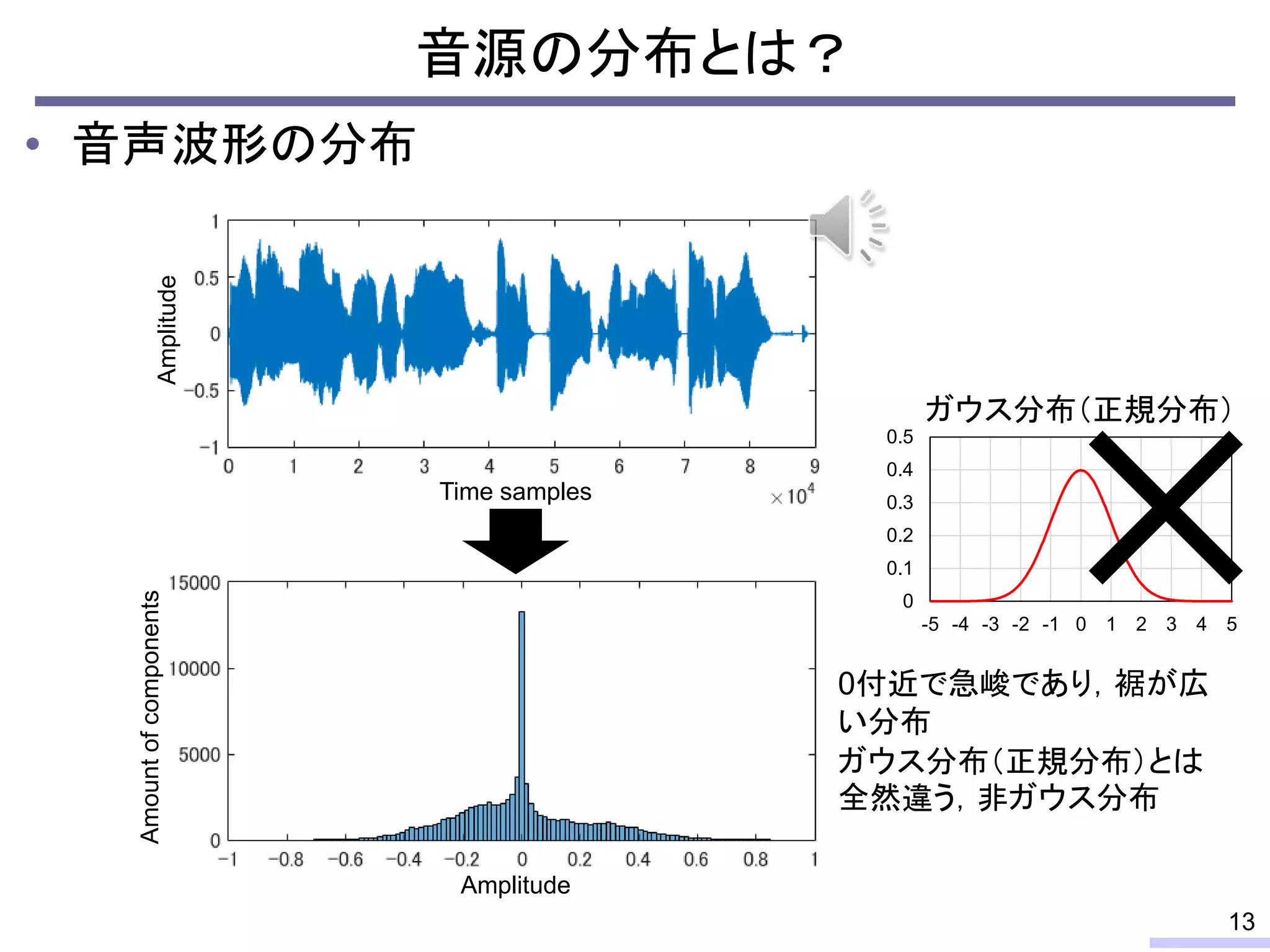
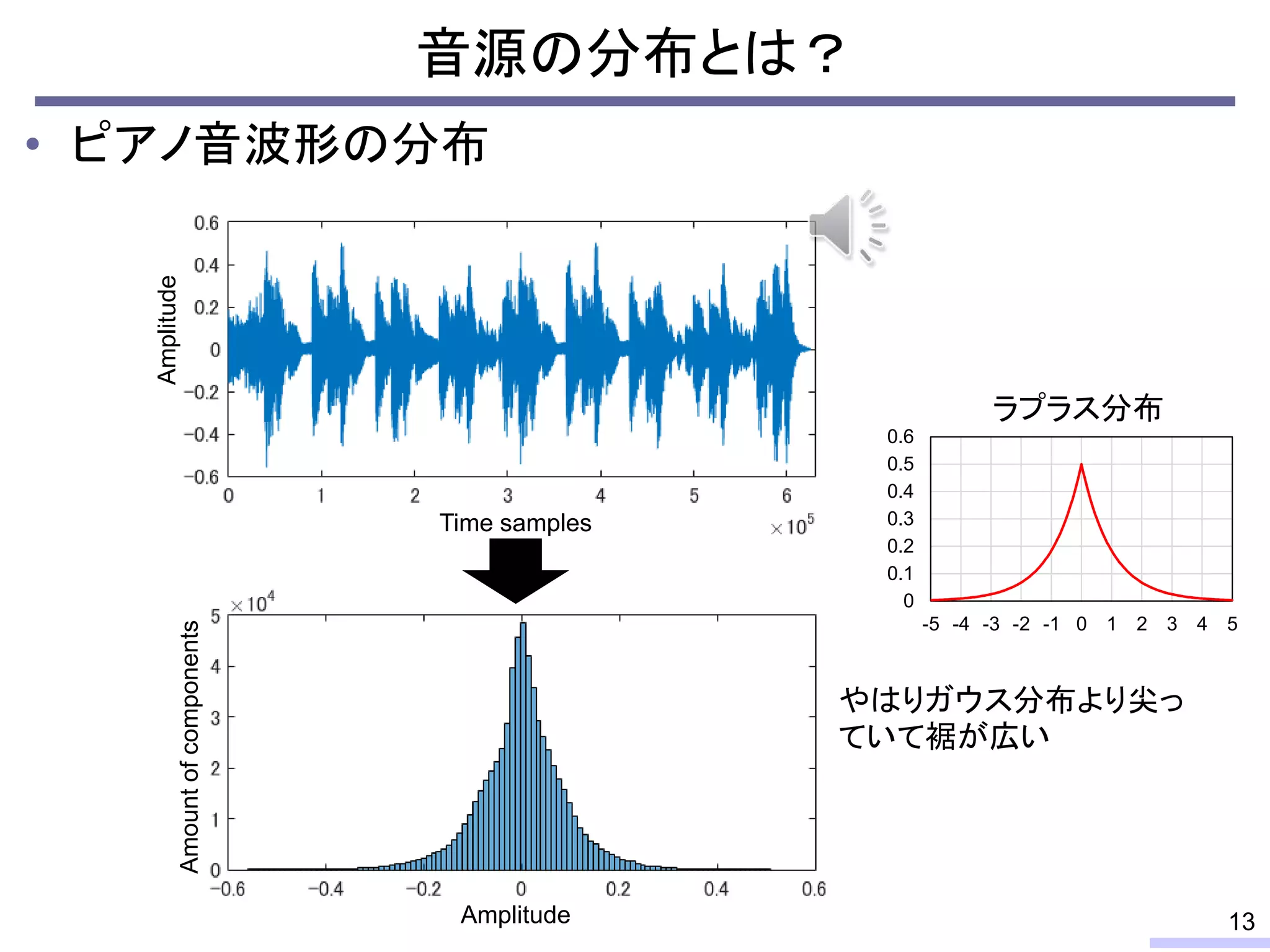
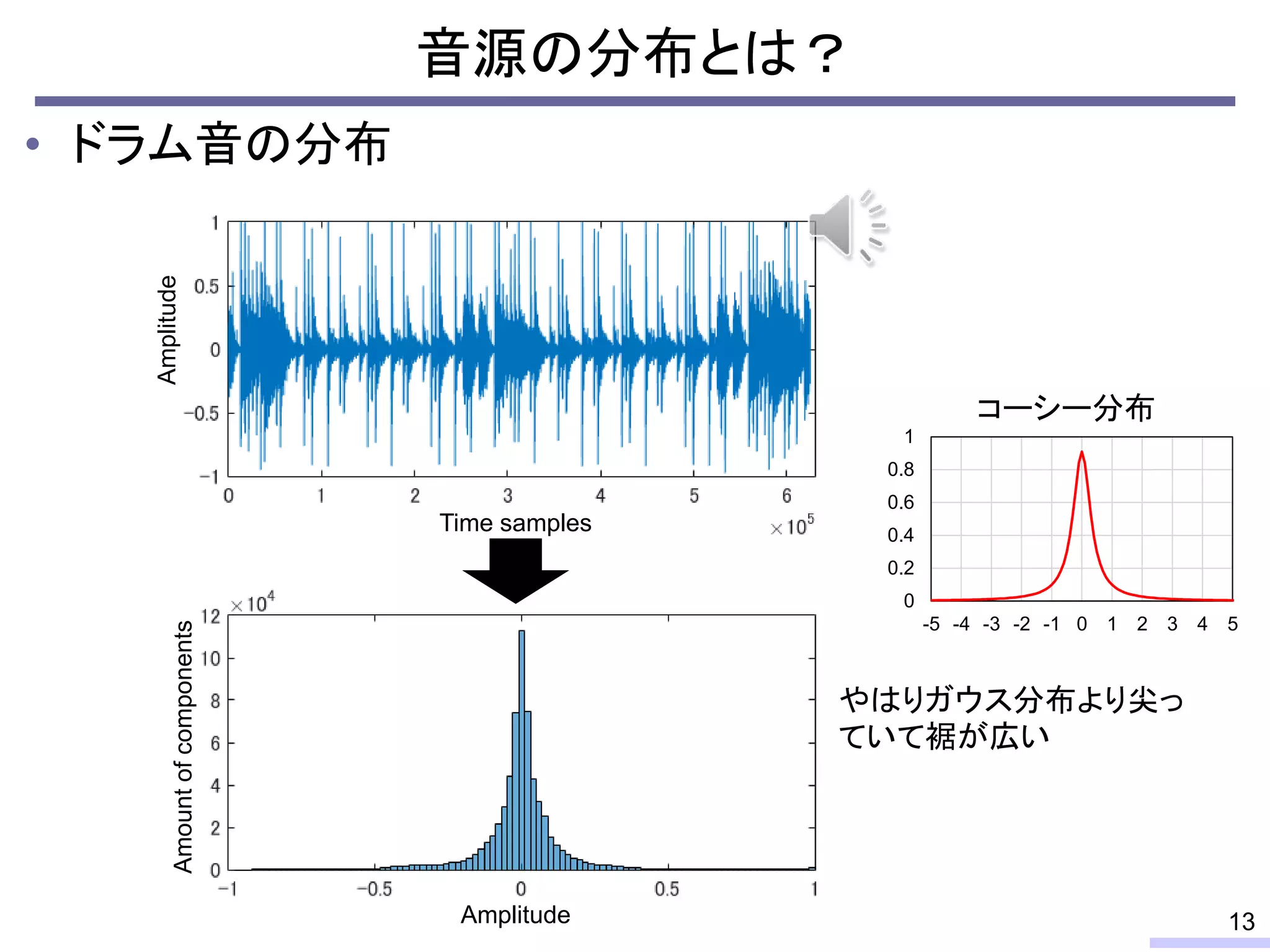
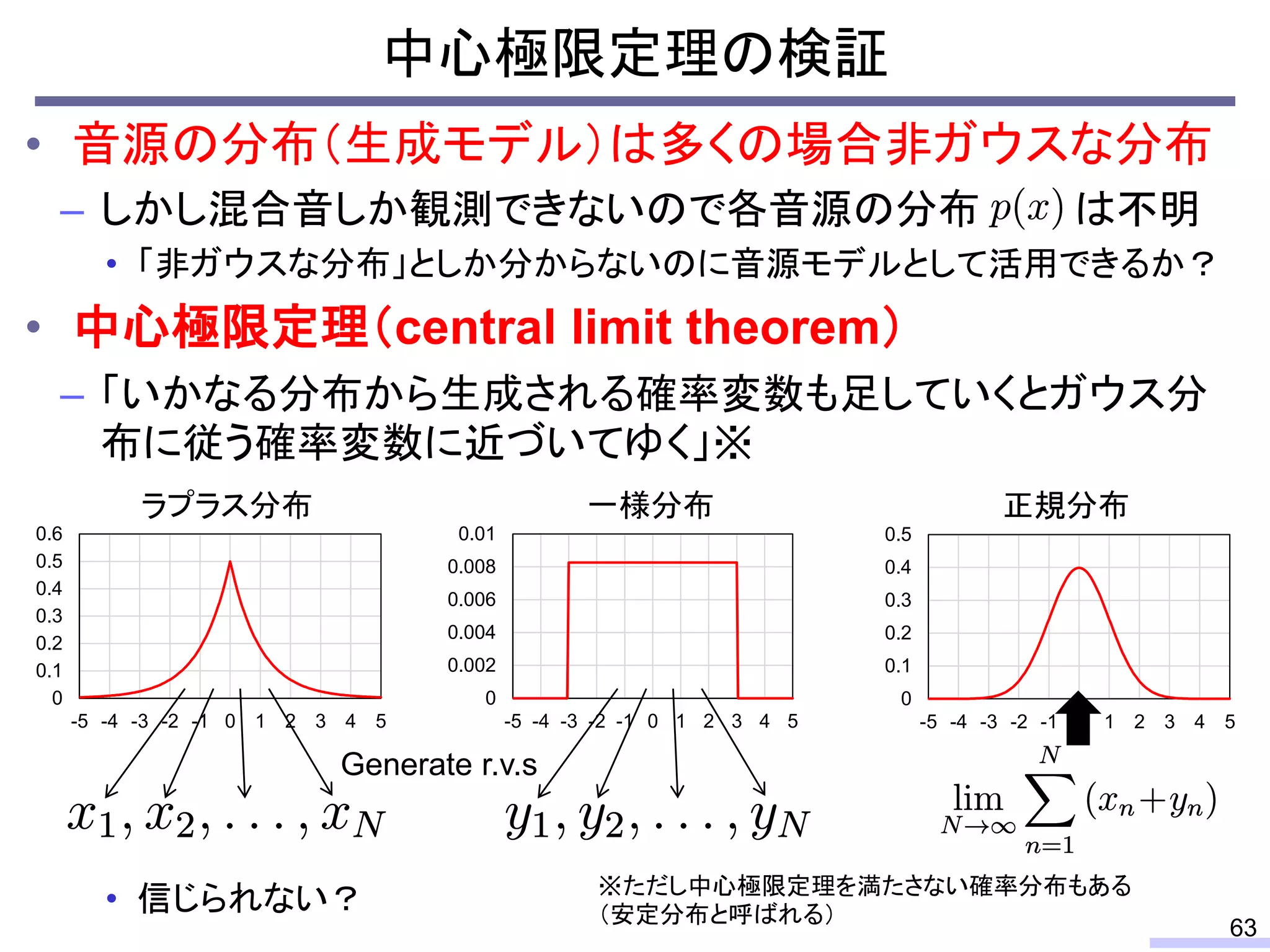
![• 学習データの音色が分離したい音源の音色と異なる場合
– スペクトルが異なるため音源分離の性能は大きく劣化
– 完璧な学習データを用意することは通常不可能
教師ありNMFによる音源分離の問題
32
混合信号
目的音源 別のピアノ
若干異なる
学習データ
60
40
20
0
-20
Amplitude[dB]
3.02.52.01.51.00.50.0
Frequency [kHz]
Real sound
Artificial sound by MIDI
音色の違いの例(人工ピアノと実ピアノ)
混合信号
(本物のPf.とTb.)
人工Pf.を学習データ
に用いた教師あり
NMFの結果
教師あり
NMF](https://image.slidesharecdn.com/asjsummerseminer20170911kitamuraver2-170909092404/75/Acoustic-modeling-in-audio-source-separation-32-2048.jpg)