Recommended
PDF
DNN音声合成のための Anti-spoofing を考慮した学習アルゴリズム
PDF
PDF
Saito21asj Autumn Meeting
PDF
Moment matching networkを用いた音声パラメータのランダム生成の検討
PDF
PDF
日本音響学会2017秋 ”Moment-matching networkに基づく一期一会音声合成における発話間変動の評価”
PDF
PDF
雑音環境下音声を用いた音声合成のための雑音生成モデルの敵対的学習
PDF
SLP201805: 日本語韻律構造を考慮した prosody-aware subword embedding とDNN多方言音声合成への適用
PDF
PDF
PDF
PDF
PDF
日本音響学会2018春 ”雑音環境下音声を用いたDNN音声合成のための雑音生成モデルの敵対的学習” (宇根)
PDF
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討
PDF
PPTX
Divergence optimization based on trade-off between separation and extrapolati...
PPTX
半教師あり非負値行列因子分解における音源分離性能向上のための効果的な基底学習法
PDF
PPTX
Study on optimal divergence for superresolution-based supervised nonnegative ...
PDF
分布あるいはモーメント間距離最小化に基づく統計的音声合成
PDF
PPTX
Evaluation of separation accuracy for various real instruments based on super...
PDF
日本語音声合成のためのsubword内モーラを考慮したProsody-aware subword embedding
PDF
Onoma-to-wave: オノマトペを利用した環境音合成手法の提案
PDF
日本音響学会2017秋 ”クラウドソーシングを利用した対訳方言音声コーパスの構築”
PPTX
論文紹介: Direct-Path Signal Cross-Correlation Estimation for Sound Source Locali...
PDF
HMMに基づく日本人英語音声合成における中学生徒の英語音声を用いた評価
PDF
More Related Content
PDF
DNN音声合成のための Anti-spoofing を考慮した学習アルゴリズム
PDF
PDF
Saito21asj Autumn Meeting
PDF
Moment matching networkを用いた音声パラメータのランダム生成の検討
PDF
PDF
日本音響学会2017秋 ”Moment-matching networkに基づく一期一会音声合成における発話間変動の評価”
PDF
PDF
雑音環境下音声を用いた音声合成のための雑音生成モデルの敵対的学習
What's hot
PDF
SLP201805: 日本語韻律構造を考慮した prosody-aware subword embedding とDNN多方言音声合成への適用
PDF
PDF
PDF
PDF
PDF
日本音響学会2018春 ”雑音環境下音声を用いたDNN音声合成のための雑音生成モデルの敵対的学習” (宇根)
PDF
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討
PDF
PPTX
Divergence optimization based on trade-off between separation and extrapolati...
PPTX
半教師あり非負値行列因子分解における音源分離性能向上のための効果的な基底学習法
PDF
PPTX
Study on optimal divergence for superresolution-based supervised nonnegative ...
PDF
分布あるいはモーメント間距離最小化に基づく統計的音声合成
PDF
PPTX
Evaluation of separation accuracy for various real instruments based on super...
PDF
日本語音声合成のためのsubword内モーラを考慮したProsody-aware subword embedding
PDF
Onoma-to-wave: オノマトペを利用した環境音合成手法の提案
PDF
日本音響学会2017秋 ”クラウドソーシングを利用した対訳方言音声コーパスの構築”
PPTX
論文紹介: Direct-Path Signal Cross-Correlation Estimation for Sound Source Locali...
Viewers also liked
PDF
HMMに基づく日本人英語音声合成における中学生徒の英語音声を用いた評価
PDF
PDF
私がビギナーの頃を振り返って�~20代の代表として~
PDF
PDF
PDF
z変換をやさしく教えて下さい (音響学入門ペディア)
PDF
PDF
GMMに基づく固有声変換のための変調スペクトル制約付きトラジェクトリ学習・適応
PDF
Prosody-Controllable HMM-Based Speech Synthesis Using Speech Input
PDF
The NAIST Text-to-Speech System for Blizzard Challenge 2015
ODP
PDF
やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析
ODP
PDF
ODP
PPTX
独立性に基づくブラインド音源分離の発展と独立低ランク行列分析 History of independence-based blind source sep...
PPTX
非負値行列分解の確率的生成モデルと�多チャネル音源分離への応用 (Generative model in nonnegative matrix facto...
PDF
PDF
PDF
深層リカレントニューラルネットワークを用いた日本語述語項構造解析
Similar to DNNテキスト音声合成のためのAnti-spoofingに敵対する学習アルゴリズム
PDF
Neural text-to-speech and voice conversion
PDF
[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...
PDF
微分可能な信号処理に基づく音声合成器を用いた DNN 音声パラメータ推定の検討
PDF
差分スペクトル法に基づくDNN声質変換のためのリフタ学習およびサブバンド処理
PPTX
深層ガウス過程音声合成におけるsequence-to-sequence学習の初期検討
PDF
[DL輪読会]音声言語病理学における機械学習とDNN
PDF
PDF
Deep learning for acoustic modeling in parametric speech generation
PPTX
[DL輪読会]Monaural Audio Source Separationusing Variational Autoencoders
PDF
PDF
音学シンポジウム2025「ニューラルボコーダ概説:生成モデルと実用性の観点から」
PDF
深層学習に基づくテキスト音声合成の技術動向_言語音声ナイト
PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ...
PDF
音学シンポジウム2025「音声研究の知見がニューラルボコーダの発展にもたらす効果」
PPTX
[DL輪読会]GANSynth: Adversarial Neural Audio Synthesis
PDF
ICASSP2019 音声&音響読み会 テーマ発表音声生成
PDF
テキスト音声合成技術と多様性への挑戦 (名古屋大学 知能システム特論)
PDF
深層ニューラルネットワークによる聴覚系のモデリング
PDF
[DL輪読会]An Iterative Framework for Self-supervised Deep Speaker Representatio...
PDF
More from Shinnosuke Takamichi
PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
PDF
PDF
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス
PDF
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法
PDF
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
PDF
PDF
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価
PDF
P J S: 音素バランスを考慮した日本語歌声コーパス
PDF
音響モデル尤度に基づくsubword分割の韻律推定精度における評価
PDF
PDF
論文紹介 Unsupervised training of neural mask-based beamforming
PDF
論文紹介 Building the Singapore English National Speech Corpus
PDF
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages
PDF
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価
PDF
PDF
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定
PDF
音声合成・変換の国際コンペティションへの 参加を振り返って
PDF
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking
PDF
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
PDF
DNNテキスト音声合成のためのAnti-spoofingに敵対する学習アルゴリズム 1. 2. /21
音声合成:
– 入力情報から音声を人工的に合成する技術
統計的パラメトリック音声合成:
– 音声特徴量を統計モデルによりモデル化 & 生成
• Deep Neural Network (DNN) 音声合成 [Zen et al., 2013.]
– 利点: 高い汎用性 & 容易な応用
• アミューズメント応用 [Doi et al., 2013.] や 言語教育 [高道 他, 2015.] など
– 欠点: 合成音声の音質劣化
• 生成される特徴量系列の過剰な平滑化が一因
1
研究分野: 統計的パラメトリック音声合成
テキスト音声合成:
Text-To-Speech (TTS)
Text Speech
3. /21
改善策: 自然 / 合成音声特徴量の分布の違いを補償
– 分布の2次モーメント (系列内変動など) [Toda et al., 2007.]
– ヒストグラム [Ohtani et al., 2012.]
本発表: Anti-spoofing に敵対するDNNテキスト音声合成
– 声のなりすましを防ぐ anti-spoofing を詐称するように学習
– 自然 / 合成音声特徴量の分布の違いを敵対的学習で補償
• 従来の補償手法の拡張に相当 [Goodfellow et al., 2014.]
結果:
– 従来のDNN音響モデル学習と比較して音質が改善
– 提案手法におけるハイパーパラメータ設定の頑健性を確認
2
本発表の概要
4. 5. 6. /21
従来のDNN音響モデル学習:
Minimum Generation Error (MGE) 学習
5
Generation
error
𝐿G 𝒚, ෝ𝒚
Linguistic
feats.
[Wu et al., 2016.]
Natural
speech
feats.
𝐿G 𝒚, ෝ𝒚 =
1
𝑇
ෝ𝒚 − 𝒚 ⊤ ෝ𝒚 − 𝒚 → Minimize
𝒚
ML-based
parameter
generation
Generated
speech
feats.
ෝ𝒚
Acoustic models
𝒙
⋯
𝒀
⋯
⋯
𝒙1
𝒙 𝑇
7. 8. 9. /21
Anti-spoofing:
合成音声による声のなりすましを防ぐ識別器
8
[Wu et al., 2016.] [Chen et al., 2015.]
𝐿D,1 𝒚 𝐿D,0 ෝ𝒚
𝐿D 𝒚, ෝ𝒚 = → Minimize−
1
𝑇
𝑡=1
𝑇
log 𝐷 𝒚 𝑡 −
1
𝑇
𝑡=1
𝑇
log 1 − 𝐷 ෝ𝒚 𝑡
合成音声を
合成音声と識別させる
自然音声を
自然音声と識別させる
ෝ𝒚
Cross entropy
𝐿D 𝒚, ෝ𝒚
1: natural
0: generated
Generated
speech feats.
𝒚Natural
speech feats.
Feature
function
𝝓 ⋅
本発表では
𝝓 𝒚 𝑡 = 𝒚 𝑡
Anti-spoofing
𝐷 ⋅
or
10. /21
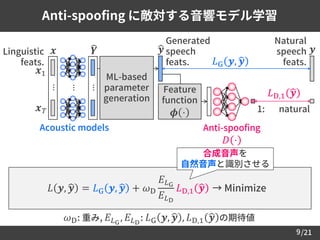
Anti-spoofing に敵対する音響モデル学習
9
𝜔D: 重み, 𝐸 𝐿G
, 𝐸 𝐿D
: 𝐿G 𝒚, ෝ𝒚 , 𝐿D,1 ෝ𝒚 の期待値
合成音声を
自然音声と識別させる
𝐿 𝒚, ෝ𝒚 = 𝐿G 𝒚, ෝ𝒚 + 𝜔D
𝐸 𝐿G
𝐸 𝐿D
𝐿D,1 ෝ𝒚 → Minimize
𝐿G 𝒚, ෝ𝒚
Linguistic
feats.
Natural
speech
feats.
𝒚
ML-based
parameter
generation
Generated
speech
feats.
ෝ𝒚
Acoustic models
𝒙
⋯
𝒀
⋯
⋯
𝒙1
𝒙 𝑇
𝐿D,1 ෝ𝒚
1: natural
Feature
function
𝝓 ⋅
Anti-spoofing
𝐷 ⋅
11. /21
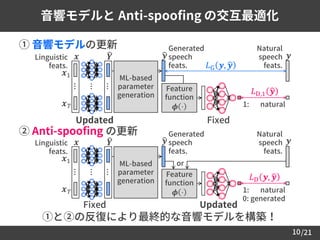
① 音響モデルの更新
② Anti-spoofing の更新
音響モデルと Anti-spoofing の交互最適化
10
①と②の反復により最終的な音響モデルを構築!
FixedUpdated
UpdatedFixed
𝐿G 𝒚, ෝ𝒚
Linguistic
feats.
Natural
speech
feats.
𝒚
ML-based
parameter
generation
Generated
speech
feats.
ෝ𝒚𝒙
⋯
𝒀
⋯
⋯𝒙1
𝒙 𝑇
𝐿D,1 ෝ𝒚
1: natural
Feature
function
𝝓 ⋅
Linguistic
feats.
Natural
speech
feats.
𝒚
ML-based
parameter
generation
Generated
speech
feats.
ෝ𝒚𝒙
⋯
𝒀
⋯
⋯
𝒙1
𝒙 𝑇
𝐿D 𝒚, ෝ𝒚
1: natural
0: generated
Feature
function
𝝓 ⋅
or
12. /21
音響モデル学習の損失関数:
– 敵対的学習 [Goodfellow et al., 2014.] と生成誤差最小化の組合せ
• 所望の入出力間対応関係を持った敵対的学習 [Reed et al., 2016.]
– 敵対的学習 = 真のデータ分布と生成分布間の距離最小化
• 分布間の距離 = Jensen-Shannon ダイバージェンス
• 自然 / 合成音声特徴量の分布の違いを補償
11
提案手法に関する考察: 敵対的学習に基づく分布補償
⋯
𝒚
𝒙
𝒚 の分布𝐷 𝒚
ෝ𝒚 の分布
学習の進行
13. 14. /21
系列内変動 (global variance): [Toda et al., 2007.]
– 特徴量分布の2次モーメント = 分布の広がり
13
系列内変動の補償
明示的に使用していないにもかかわらず,
anti-spoofing が系列内変動を自動的に補償!
Feature index
0 5 10 15 20
10-3
10-1
101
Globalvariance
Proposed
Natural
MGE
10-2
100
10-4
大
小
15. /21
Maximal Information Coefficient (MIC): [Reshef et al., 2011.]
– 2変量間の非線形な相関を定量化する指標
– 自然音声の特徴量間の相関は弱まる傾向 [Ijima et al., 2016.]
14
提案手法による副次的効果: 不自然な相関の緩和
Natural MGE
0
6
12
18
24
0 6 12 18 24
0.0
0.2
0.4
0.6
0.8
1.0
強
弱
Proposed
特徴量の分布や系列内変動のみならず,
特徴量間の相関も補償!
0 6 12 18 24 0 6 12 18 24
16. 17. /21
実験条件
データセット ATR 音素バランス503文 (16 kHz サンプリング)
学習 / 評価データ A-I セット 450文 / Jセット 53文
音声パラメータ 25次元のメルケプストラム, 𝐹0, 5帯域の非周期成分
コンテキストラベル 274次元 (音素, モーラ位置, アクセント型など)
前処理 Trajectory smoothing [Takamichi et al., 2015.]
予測パラメータ
メルケプストラム
(𝐹0, 非周期成分, 継続長は自然音声の特徴量を利用)
最適化アルゴリズム AdaGrad [Duchi et al., 2011.] (学習率 0.01)
音響モデル Feed-Forward 274 – 3x400 (ReLU) – 75 (linear)
Anti-spoofing Feed-Forward 25 – 2x200 (ReLU) – 1 (sigmoid)
16
18. /21
提案手法の初期化・学習および客観評価
17
初期化:
– 音響モデル: MGE学習
– Anti-spoofing: 自然音声とMGE学習後の合成音声を識別
学習時:
– 音響モデル: Anti-spoofing に敵対する学習
– Anti-spoofing: 自然音声と当該学習時点での合成音声を識別
客観評価指標:
– 特徴量の生成誤差 𝐿G 𝒚, ෝ𝒚
– Anti-spoofing における詐称率
• 詐称率: 合成音声を自然音声と誤識別した割合
• ここでの anti-spoofing はMGE学習後の合成音声を用いて構築
提案手法の重み 𝜔D の変化に伴う客観評価指標の変化を調査
19. /21
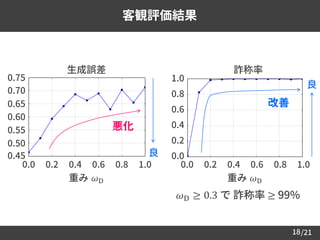
客観評価結果
18
生成誤差 詐称率
0.0 0.2 0.4 0.6 0.8 1.0
重み 𝜔D
0.45
0.50
0.55
0.60
0.65
0.70
0.75
1.0
0.8
0.6
0.4
0.2
0.0
0.8
1.0
良
良
0.0 0.2 0.4 0.6 0.8 1.0
重み 𝜔D
悪化
改善
𝜔D ≥ 0.3 で 詐称率 ≥ 99%
20. 21. 22. /21
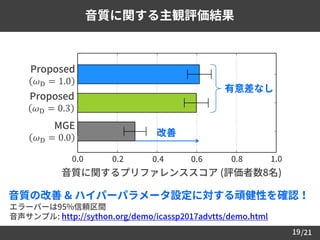
まとめ
目的: 統計的パラメトリック音声合成の音質改善
提案手法: Anti-spoofing に敵対するDNNテキスト音声合成
• 自然 / 合成音声特徴量の分布の違いを敵対的学習で補償
• 系列内変動だけでなく, 特徴量間の相関も補償
結果:
– 従来のDNN音響モデル学習と比較して音質が改善
– 提案手法におけるハイパーパラメータ設定の頑健性を確認
今後の検討事項:
– 時間・言語依存の anti-spoofing の導入
– 提案手法の 𝐹0・継続長生成への拡張
• → 2017年春季ASJ (3/16(木) 16:15 ~) で発表予定
21



![/21
音声合成:
– 入力情報から音声を人工的に合成する技術
統計的パラメトリック音声合成:
– 音声特徴量を統計モデルによりモデル化 & 生成
• Deep Neural Network (DNN) 音声合成 [Zen et al., 2013.]
– 利点: 高い汎用性 & 容易な応用
• アミューズメント応用 [Doi et al., 2013.] や 言語教育 [高道 他, 2015.] など
– 欠点: 合成音声の音質劣化
• 生成される特徴量系列の過剰な平滑化が一因
1
研究分野: 統計的パラメトリック音声合成
テキスト音声合成:
Text-To-Speech (TTS)
Text Speech](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-2-320.jpg)
![/21
改善策: 自然 / 合成音声特徴量の分布の違いを補償
– 分布の2次モーメント (系列内変動など) [Toda et al., 2007.]
– ヒストグラム [Ohtani et al., 2012.]
本発表: Anti-spoofing に敵対するDNNテキスト音声合成
– 声のなりすましを防ぐ anti-spoofing を詐称するように学習
– 自然 / 合成音声特徴量の分布の違いを敵対的学習で補償
• 従来の補償手法の拡張に相当 [Goodfellow et al., 2014.]
結果:
– 従来のDNN音響モデル学習と比較して音質が改善
– 提案手法におけるハイパーパラメータ設定の頑健性を確認
2
本発表の概要](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-3-320.jpg)

![/214
DNNを音響モデルとして用いたTTSの枠組み
𝒙
⋯
𝒀
Acoustic models
⋯
⋯
𝒙1
𝒙 𝑇
𝒀1
𝒀 𝑇
Spectrum
Continuous F0
Voiced / unvoiced
Band
aperiodicity
Linguistic
feats.
Static-dynamic
mean vectors
(generated speech feats.)
[Zen et al., 2013.]
⋯⋯
0
0
1
1
a
i
u
1
2
3
Phoneme
Accent
Mora
position
Frame
position
etc.
0](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-5-320.jpg)
![/21
従来のDNN音響モデル学習:
Minimum Generation Error (MGE) 学習
5
Generation
error
𝐿G 𝒚, ෝ𝒚
Linguistic
feats.
[Wu et al., 2016.]
Natural
speech
feats.
𝐿G 𝒚, ෝ𝒚 =
1
𝑇
ෝ𝒚 − 𝒚 ⊤ ෝ𝒚 − 𝒚 → Minimize
𝒚
ML-based
parameter
generation
Generated
speech
feats.
ෝ𝒚
Acoustic models
𝒙
⋯
𝒀
⋯
⋯
𝒙1
𝒙 𝑇](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-6-320.jpg)
![/216
MGE学習の問題点: 自然音声と異なる特徴量の分布
Natural MGE
21st mel-cepstral coefficient
23rdmel-cepstral
coefficient
自然音声と比較して特徴量の分布が縮小...
(系列内変動[Toda et al., 2007.] は分布の2次モーメントを明示的に補償)](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-7-320.jpg)

![/21
Anti-spoofing:
合成音声による声のなりすましを防ぐ識別器
8
[Wu et al., 2016.] [Chen et al., 2015.]
𝐿D,1 𝒚 𝐿D,0 ෝ𝒚
𝐿D 𝒚, ෝ𝒚 = → Minimize−
1
𝑇
𝑡=1
𝑇
log 𝐷 𝒚 𝑡 −
1
𝑇
𝑡=1
𝑇
log 1 − 𝐷 ෝ𝒚 𝑡
合成音声を
合成音声と識別させる
自然音声を
自然音声と識別させる
ෝ𝒚
Cross entropy
𝐿D 𝒚, ෝ𝒚
1: natural
0: generated
Generated
speech feats.
𝒚Natural
speech feats.
Feature
function
𝝓 ⋅
本発表では
𝝓 𝒚 𝑡 = 𝒚 𝑡
Anti-spoofing
𝐷 ⋅
or](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-9-320.jpg)
![/21
音響モデル学習の損失関数:
– 敵対的学習 [Goodfellow et al., 2014.] と生成誤差最小化の組合せ
• 所望の入出力間対応関係を持った敵対的学習 [Reed et al., 2016.]
– 敵対的学習 = 真のデータ分布と生成分布間の距離最小化
• 分布間の距離 = Jensen-Shannon ダイバージェンス
• 自然 / 合成音声特徴量の分布の違いを補償
11
提案手法に関する考察: 敵対的学習に基づく分布補償
⋯
𝒚
𝒙
𝒚 の分布𝐷 𝒚
ෝ𝒚 の分布
学習の進行](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-12-320.jpg)

![/21
系列内変動 (global variance): [Toda et al., 2007.]
– 特徴量分布の2次モーメント = 分布の広がり
13
系列内変動の補償
明示的に使用していないにもかかわらず,
anti-spoofing が系列内変動を自動的に補償!
Feature index
0 5 10 15 20
10-3
10-1
101
Globalvariance
Proposed
Natural
MGE
10-2
100
10-4
大
小](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-14-320.jpg)
![/21
Maximal Information Coefficient (MIC): [Reshef et al., 2011.]
– 2変量間の非線形な相関を定量化する指標
– 自然音声の特徴量間の相関は弱まる傾向 [Ijima et al., 2016.]
14
提案手法による副次的効果: 不自然な相関の緩和
Natural MGE
0
6
12
18
24
0 6 12 18 24
0.0
0.2
0.4
0.6
0.8
1.0
強
弱
Proposed
特徴量の分布や系列内変動のみならず,
特徴量間の相関も補償!
0 6 12 18 24 0 6 12 18 24](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-15-320.jpg)

![/21
実験条件
データセット ATR 音素バランス503文 (16 kHz サンプリング)
学習 / 評価データ A-I セット 450文 / Jセット 53文
音声パラメータ 25次元のメルケプストラム, 𝐹0, 5帯域の非周期成分
コンテキストラベル 274次元 (音素, モーラ位置, アクセント型など)
前処理 Trajectory smoothing [Takamichi et al., 2015.]
予測パラメータ
メルケプストラム
(𝐹0, 非周期成分, 継続長は自然音声の特徴量を利用)
最適化アルゴリズム AdaGrad [Duchi et al., 2011.] (学習率 0.01)
音響モデル Feed-Forward 274 – 3x400 (ReLU) – 75 (linear)
Anti-spoofing Feed-Forward 25 – 2x200 (ReLU) – 1 (sigmoid)
16](https://image.slidesharecdn.com/saito17slpslide-170217041823/85/DNN-Anti-spoofing-17-320.jpg)



















































![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]音声言語病理学における機械学習とDNN](https://cdn.slidesharecdn.com/ss_thumbnails/201016dltext-to-speech-201016023355-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Monaural Audio Source Separationusing Variational Autoencoders](https://cdn.slidesharecdn.com/ss_thumbnails/20190717dlmonauralaudiosourceseparationusingvariationalautoencodersver2-190719035345-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]GANSynth: Adversarial Neural Audio Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/20180315gansynthmizuta-190315003922-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]An Iterative Framework for Self-supervised Deep Speaker Representatio...](https://cdn.slidesharecdn.com/ss_thumbnails/20220216dlaniterativeframeworkforself-superviseddeepspeakerrepresentationlearning-220218040109-thumbnail.jpg?width=640&height=640&fit=bounds)




















