Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Shinnosuke Takamichi
1,950 views
分布あるいはモーメント間距離最小化に基づく統計的音声合成
ステアラボ人工知能セミナー招待講演 (2018/10/12)
Technology
◦
Read more
7
Save
Share
Embed
Embed presentation
Download
Downloaded 31 times
1
/ 47
2
/ 47
3
/ 47
4
/ 47
5
/ 47
6
/ 47
7
/ 47
8
/ 47
9
/ 47
10
/ 47
11
/ 47
12
/ 47
13
/ 47
14
/ 47
15
/ 47
16
/ 47
17
/ 47
18
/ 47
19
/ 47
20
/ 47
21
/ 47
22
/ 47
23
/ 47
24
/ 47
25
/ 47
26
/ 47
27
/ 47
28
/ 47
29
/ 47
30
/ 47
31
/ 47
32
/ 47
33
/ 47
34
/ 47
35
/ 47
36
/ 47
37
/ 47
38
/ 47
39
/ 47
40
/ 47
41
/ 47
42
/ 47
43
/ 47
44
/ 47
45
/ 47
46
/ 47
47
/ 47
More Related Content
PDF
【DL輪読会】Patches Are All You Need? (ConvMixer)
by
Deep Learning JP
PDF
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法
by
Shinnosuke Takamichi
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PPTX
畳み込みLstm
by
tak9029
PPTX
【解説】 一般逆行列
by
Kenjiro Sugimoto
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
【DL輪読会】Patches Are All You Need? (ConvMixer)
by
Deep Learning JP
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法
by
Shinnosuke Takamichi
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
畳み込みLstm
by
tak9029
【解説】 一般逆行列
by
Kenjiro Sugimoto
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
What's hot
PDF
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
PDF
Action Recognitionの歴史と最新動向
by
Ohnishi Katsunori
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PDF
強化学習その1
by
nishio
PDF
最適化超入門
by
Takami Sato
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PPTX
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
PDF
【DL輪読会】NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics vi...
by
Deep Learning JP
PPTX
論文紹介 wav2vec: Unsupervised Pre-training for Speech Recognition
by
YosukeKashiwagi1
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
多様な強化学習の概念と課題認識
by
佑 甲野
PPTX
勾配降下法の 最適化アルゴリズム
by
nishio
PDF
LSTM (Long short-term memory) 概要
by
Kenji Urai
PDF
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
Fisher Vectorによる画像認識
by
Takao Yamanaka
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
Action Recognitionの歴史と最新動向
by
Ohnishi Katsunori
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
強化学習その1
by
nishio
最適化超入門
by
Takami Sato
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
【DL輪読会】NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics vi...
by
Deep Learning JP
論文紹介 wav2vec: Unsupervised Pre-training for Speech Recognition
by
YosukeKashiwagi1
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
多様な強化学習の概念と課題認識
by
佑 甲野
勾配降下法の 最適化アルゴリズム
by
nishio
LSTM (Long short-term memory) 概要
by
Kenji Urai
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
Fisher Vectorによる画像認識
by
Takao Yamanaka
Similar to 分布あるいはモーメント間距離最小化に基づく統計的音声合成
PDF
Neural text-to-speech and voice conversion
by
Yuki Saito
PDF
深層生成モデルに基づく音声合成技術
by
NU_I_TODALAB
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PDF
音学シンポジウム2025「ニューラルボコーダ概説:生成モデルと実用性の観点から」
by
NU_I_TODALAB
PDF
[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...
by
Deep Learning JP
PDF
ICASSP読み会2020
by
Yuki Saito
PDF
音学シンポジウム2025「音声研究の知見がニューラルボコーダの発展にもたらす効果」
by
NU_I_TODALAB
PDF
深層生成モデルによるメディア生成
by
kame_hirokazu
PDF
DNN音声合成のための Anti-spoofing を考慮した学習アルゴリズム
by
Yuki Saito
PDF
方向統計DNNに基づく振幅スペクトログラムからの位相復元
by
Shinnosuke Takamichi
PDF
差分スペクトル法に基づくDNN声質変換のためのリフタ学習およびサブバンド処理
by
Takaaki Saeki
PDF
SLP研究会201902 正弦関数摂動 von Mises 分布 DNN の モード近似を用いた位相復元
by
Shinnosuke Takamichi
PDF
Saito17asjA
by
Yuki Saito
PDF
Slp201702
by
Yuki Saito
PDF
DNNテキスト音声合成のためのAnti-spoofingに敵対する学習アルゴリズム
by
Shinnosuke Takamichi
PDF
saito2017asj_vc
by
Yuki Saito
PDF
Kameoka2012 talk07 1
by
kame_hirokazu
PDF
Ieice中国地区
by
nozomuhamada
PDF
Deep learning for acoustic modeling in parametric speech generation
by
Yuki Saito
PDF
【文献紹介】Predictive regression modeling with MEG
by
佑友輔 仲井
Neural text-to-speech and voice conversion
by
Yuki Saito
深層生成モデルに基づく音声合成技術
by
NU_I_TODALAB
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
音学シンポジウム2025「ニューラルボコーダ概説:生成モデルと実用性の観点から」
by
NU_I_TODALAB
[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...
by
Deep Learning JP
ICASSP読み会2020
by
Yuki Saito
音学シンポジウム2025「音声研究の知見がニューラルボコーダの発展にもたらす効果」
by
NU_I_TODALAB
深層生成モデルによるメディア生成
by
kame_hirokazu
DNN音声合成のための Anti-spoofing を考慮した学習アルゴリズム
by
Yuki Saito
方向統計DNNに基づく振幅スペクトログラムからの位相復元
by
Shinnosuke Takamichi
差分スペクトル法に基づくDNN声質変換のためのリフタ学習およびサブバンド処理
by
Takaaki Saeki
SLP研究会201902 正弦関数摂動 von Mises 分布 DNN の モード近似を用いた位相復元
by
Shinnosuke Takamichi
Saito17asjA
by
Yuki Saito
Slp201702
by
Yuki Saito
DNNテキスト音声合成のためのAnti-spoofingに敵対する学習アルゴリズム
by
Shinnosuke Takamichi
saito2017asj_vc
by
Yuki Saito
Kameoka2012 talk07 1
by
kame_hirokazu
Ieice中国地区
by
nozomuhamada
Deep learning for acoustic modeling in parametric speech generation
by
Yuki Saito
【文献紹介】Predictive regression modeling with MEG
by
佑友輔 仲井
More from Shinnosuke Takamichi
PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
PDF
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
PDF
JVS:フリーの日本語多数話者音声コーパス
by
Shinnosuke Takamichi
PDF
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
by
Shinnosuke Takamichi
PDF
論文紹介 Unsupervised training of neural mask-based beamforming
by
Shinnosuke Takamichi
PDF
国際会議 interspeech 2020 報告
by
Shinnosuke Takamichi
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討
by
Shinnosuke Takamichi
PDF
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価
by
Shinnosuke Takamichi
PDF
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス
by
Shinnosuke Takamichi
PDF
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定
by
Shinnosuke Takamichi
PDF
P J S: 音素バランスを考慮した日本語歌声コーパス
by
Shinnosuke Takamichi
PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ...
by
Shinnosuke Takamichi
PDF
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価
by
Shinnosuke Takamichi
PDF
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
PDF
音響モデル尤度に基づくsubword分割の韻律推定精度における評価
by
Shinnosuke Takamichi
PDF
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking
by
Shinnosuke Takamichi
PDF
音声合成研究を加速させるためのコーパスデザイン
by
Shinnosuke Takamichi
PDF
音声合成・変換の国際コンペティションへの 参加を振り返って
by
Shinnosuke Takamichi
PDF
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages
by
Shinnosuke Takamichi
PDF
論文紹介 Building the Singapore English National Speech Corpus
by
Shinnosuke Takamichi
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
JVS:フリーの日本語多数話者音声コーパス
by
Shinnosuke Takamichi
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
by
Shinnosuke Takamichi
論文紹介 Unsupervised training of neural mask-based beamforming
by
Shinnosuke Takamichi
国際会議 interspeech 2020 報告
by
Shinnosuke Takamichi
短時間発話を用いた話者照合のための音声加工の効果に関する検討
by
Shinnosuke Takamichi
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価
by
Shinnosuke Takamichi
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス
by
Shinnosuke Takamichi
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定
by
Shinnosuke Takamichi
P J S: 音素バランスを考慮した日本語歌声コーパス
by
Shinnosuke Takamichi
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ...
by
Shinnosuke Takamichi
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価
by
Shinnosuke Takamichi
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
音響モデル尤度に基づくsubword分割の韻律推定精度における評価
by
Shinnosuke Takamichi
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking
by
Shinnosuke Takamichi
音声合成研究を加速させるためのコーパスデザイン
by
Shinnosuke Takamichi
音声合成・変換の国際コンペティションへの 参加を振り返って
by
Shinnosuke Takamichi
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages
by
Shinnosuke Takamichi
論文紹介 Building the Singapore English National Speech Corpus
by
Shinnosuke Takamichi
Recently uploaded
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
Drupal Recipes 解説 .
by
iPride Co., Ltd.
PPTX
ddevについて .
by
iPride Co., Ltd.
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
Drupal Recipes 解説 .
by
iPride Co., Ltd.
ddevについて .
by
iPride Co., Ltd.
分布あるいはモーメント間距離最小化に基づく統計的音声合成
1.
06/12/2018©Shinnosuke Takamichi, The University
of Tokyo 分布あるいはモーメント間距離最小化に基づく 統計的音声合成 東京大学 助教 高道 慎之介 (@forthshinji) ステアラボ人工知能セミナー招待講演 (2018/10/12)
2.
/47 自己紹介 経歴 – 奈良先端大
博士後期課程 修了 (2016) – 東京大学 助教 (兼担:同大学 DMMラボ連携講座 特任助教) 研究テーマ – 音声合成変換 / speech synthesis, voice conversion – 音声信号処理 / speech signal processing – 音声なりすまし検出 / anti-spoofing – 深層学習 / deep learning – 音声コミュニケーション拡張 / augmented speech communication 2
3.
/47 猿渡・小山研究室 3 猿渡 洋 (教授) ・音メディアシステム ・教師無し最適化 ・統計・機械学習論的 信号処理 特任研究員 高宗さん 秘書
丹治さん 博士課程学生2名 ・音響信号処理 ・音場再生・伝送 (音響ホログラフ) ・スパース信号処理 小山翔一 (講師) 高道慎之介 (助教) ・音声信号処理 ・統計的音声合成 ・声質変換 ・深層学習(DNN) ・音メディア信号処理 ・統計・機械学習論的 信号処理 ・音楽信号処理 修士課程学生4+5名 柏野研学生1名 北村大地 (客員研究員) 香川高専
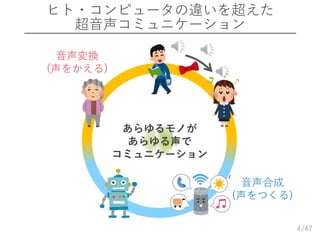
4.
/47 ヒト・コンピュータの違いを超えた 超音声コミュニケーション 4 音声変換 (声をかえる) 音声合成 (声をつくる) あらゆるモノが あらゆる声で コミュニケーション
5.
/47 テキスト音声合成と音声変換 テキスト音声合成 (Text-To-Speech:
TTS) – テキストなどから音声を合成 – 人以外のモノのコミュニケーションのため 音声変換 (Voice Conversion: VC) – 言語情報を保持したままパラ言語・非言語情報を変換 – 人の発声制約を超えたコミュニケーションのため 5 Text TTS VC 統計モデルに基づく手法を統計的音声合成・変換と呼ぶ
6.
/47 本日のテーマ 6 分布あるいはモーメント間距離最小化に基づく 統計的音声合成・変換 音声合成から見た 敵対的学習 (GAN) 非対称分布な周期変数に 対応する深層生成モデル “シンプルだけど強力”・“普遍的な技術に新たに解釈する”がキーワード
7.
デモ 7
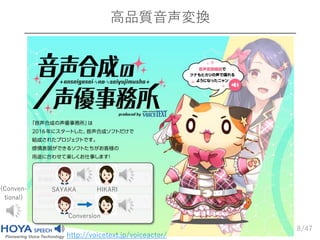
8.
/47 高品質音声変換 8 http://voicetext.jp/voiceactor/ SAYAKA HIKARI Conversion (Conven- tional)
9.
/47 日本人英語音声合成 9 [Oshima16] 従来法で生成 提案法で生成 学習に使用した音声 (大学生、ERJデータベースに含まれる男性話者のうち、 評定スコアが最低) “I can see
that knife now.”
10.
/47 英会話アプリによる実証実験 ~音声合成はどこまで役立つか~ 10 https://www.joyz.co.jp/press_research
11.
/47 多方言音声合成 11 [Akiyama18] Dialect text Multi-dialect speech synthesis Dialect speech Miyazaki-ben 韻律と単語の教師なし獲得により地域性・話者性を分離した音声合成へ
12.
音声のもつ情報とDNN音声合成 12
13.
/47 音声の持つ情報 13 言語情報 パラ言語情報 非言語情報 狭義の音声認識 (speech-to-text) 話者認識など (speaker recognition) 感情認識など (emotion recognition) テキスト化できる情報 話し手が意図的に付与する, テキスト化できない情報
(例:感情) 話し手の意図とは無関係に付与される, テキスト化できない情報(例:話者性)
14.
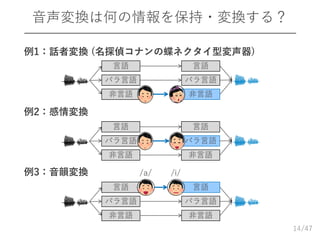
/47 音声変換は何の情報を保持・変換する? 例1:話者変換 (名探偵コナンの蝶ネクタイ型変声器)
例2:感情変換 例3:音韻変換 14 言語 パラ言語 非言語 言語 パラ言語 非言語 言語 パラ言語 非言語 言語 パラ言語 非言語 言語 パラ言語 非言語 言語 パラ言語 非言語 /a/ /i/
15.
/47 音声合成は何の情報を保持・変換する? 例:究極の音声翻訳 (ドラえもんのホンヤクこんにゃく) 15 言語 パラ言語 非言語 言語 パラ言語 非言語 翻訳 音声認識 など 感情認識など 話者認識 など テキスト翻訳 音声合成
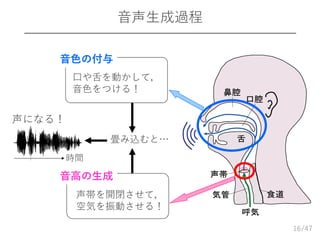
16.
/47 音声生成過程 16 音色の付与 口や舌を動かして, 音色をつける! 音高の生成 声帯を開閉させて, 空気を振動させる! 声になる! 畳み込むと… 時間
17.
/47 フレーム分析と音声特徴量 音声の準定常性を仮定してフレーム分析 – 20~30ms程度であれば,音声は定常信号 17 Time Freq. F0
[Hz] Time有声 無声 声帯が 周期的に振動 Speech スペクトルとF0が 1フレームの特徴量
18.
/47 Text-to-speechでの利用 18 テキスト特徴量 音声特徴量 t=1 t=2 t=T 当該音素 アクセント モーラ位置 時間位置 などなど a i u … 1 2 3 … 0 1 0 1 0 スペクトル (声色) F0
(音高) 有声・無声 テキスト DNN DNNは自然音声特徴量との二乗誤差を最小化するように学習
19.
音声合成から見た敵対的学習 (GAN) 19
20.
/47 生成パラメータの過剰な平滑化: 音質劣化の要因 統計モデリングにおける平均化により,自然音声パラメータに含 まれていた微細構造が消失すること.音質劣化の主要因 20 Time Natural speech
parameters Time Synthetic speech parameters Speech parameter generation Acoustic modeling Training Synthesis 何が 違う?
21.
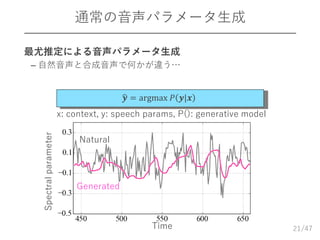
/47 通常の音声パラメータ生成 21 Natural 𝒚 = argmax
𝑃 𝒚|𝒙 Generated x: context, y: speech params, P(): generative model 最尤推定による音声パラメータ生成 – 自然音声と合成音声で何かが違う… Time Spectralparameter
22.
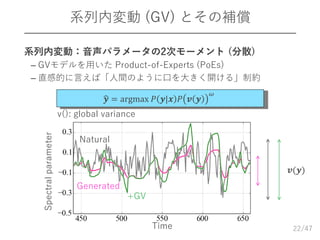
/47 系列内変動 (GV) とその補償 22Time Natural +GV Spectralparameter 𝒗(𝒚) Generated 𝒚
= argmax 𝑃 𝒚|𝒙 𝑃 𝒗 𝒚 𝜔 v(): global variance 系列内変動:音声パラメータの2次モーメント (分散) – GVモデルを用いた Product-of-Experts (PoEs) – 直感的に言えば「人間のように口を大きく開ける」制約
23.
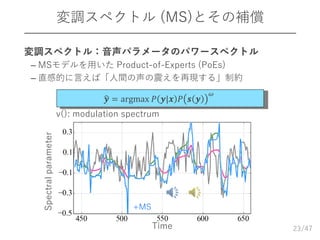
/47 変調スペクトル (MS)とその補償 23 𝒚 =
argmax 𝑃 𝒚|𝒙 𝑃 𝒔 𝒚 𝜔 v(): modulation spectrum 変調スペクトル:音声パラメータのパワースペクトル – MSモデルを用いた Product-of-Experts (PoEs) – 直感的に言えば「人間の声の震えを再現する」制約 +MS Time Spectralparameter
24.
/47 変調スペクトルを用いた高品質音声合成 24 Telugu Tamil Marathi Malayalam Japanese Bengali Hindi Conventional Ours 2015音声合成コンペ・2016音声変換コンペで世界最高品質と評価
25.
まだまだ音が悪い→GANの登場 25
26.
/47 Generative Adversarial Network
(GAN): 分布間距離の最小化 Generative adversarial network – 分布間の近似 Jensen-Shannon divergence を最小化 – 合成器と,自然/合成音声を識別する識別器を敵対 26 𝒚 1: 自然 0: 生成 [Goodfellow et al., 2014.] ⋯ ⋯ ⋯ ⋯ Text +noise Anti-spoofing Text-to-speech
27.
/47 DNN音声合成のための敵対学習 27 ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ Linguistic feats. Parameter generation 𝐿G 𝒚, 𝒚 𝐿D,1
𝒚Feature function 1: natural ⋯ 𝒚 𝒚 Generated speech params. Natural speech params. 𝐿 𝒚, 𝒚 = 𝐿G 𝒚, 𝒚 + 𝜔D 𝐿D,1 𝒚 を最小化 敵対的損失生成誤差 Text-to-speech Anti-spoofing [Saito et al., 2018.]
28.
/47 GANによる分布補償の効果 28 20th mel-cepstral coefficient 23rdmel-cepstral coefficient Natural
MGE GAN モーメントや分布を明示的に定義せずに分布を近づける [Saito et al., 2018.]
29.
/47 GANs as various
divergence minimization 29 KL-GAN [Nowozin16] JS-GAN [Nowozin16] RKL-GAN [Nowozin16] GAN [Goodfellow14] W-GAN [Arjovsky17] LS-GAN [Mao17] Kullback Leibler (KL) div. Jensen-Shannon (JS) div. Reversed KL div. Approx. JS div. Wasserstein div. 1 2 3 4 5 Mean opinion score on synthetic speech quality [Saito et al., 2018.]
30.
/47 別の観点から見たGAN 音声なりすまし検出セキュリティ(anti-spoofing) を騙す –
Anti-spoofing: 音声合成・変換による「声のなりすまし」を検出 する識別器 – 「セキュリティを騙せば高品質化できるんじゃない?」 様々な音声特徴量に適用可能 – Vocoder features (spectral envelope, F0) – DFT features – Waveform 30 Anti-spoofing “I’m Chun-Li!” “I’m Chun-Li!” OK! NG!
31.
非対称分布な周期変数を モデル化するDNN 31
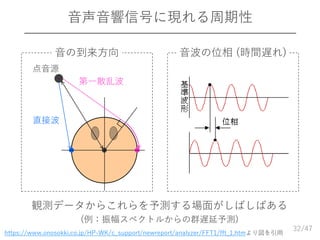
32.
/47 音声音響信号に現れる周期性 32 音の到来方向 音波の位相 (時間遅れ) 観測データからこれらを予測する場面がしばしばある (例:振幅スペクトルからの群遅延予測) 点音源 直接波 第一散乱波 https://www.onosokki.co.jp/HP-WK/c_support/newreport/analyzer/FFT1/fft_1.htmより図を引用
33.
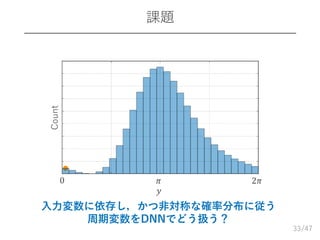
/47 課題 33 入力変数に依存し,かつ非対称な確率分布に従う 周期変数をDNNでどう扱う? 𝑦 0 𝜋 2𝜋 Count
34.
/47 パラメトリック確率分布DNNとは 定義:パラメトリックな条件付き確率分布 𝑃
𝑦|𝑥 を持つDNN – 負の対数尤度を最小化する,DNN学習時の損失関数 𝐿 ⋅ – 例) 𝑦 − 𝑦 2 → 分散 given の(等方性)ガウス分布DNN − cos 𝑦 − 𝑦 → 集中度パラメータ given の von Mises分布DNN 本発表:正弦関数摂動一般化ハート分布 – 円周上の確率分布 (位相のような周期変数に対応) – 一般化ハート分布 [Jones05] … von Mises 分布を一般化した対称分布 – 正弦関数摂動 [Abe11] … 円周上の分布の非対称化 34 𝑥 𝑦 𝑦𝐿 ⋅ [Takamichi18] 以降では,分布を導入してDNN学習時の損失関数を定義
35.
/47 正弦関数摂動一般化ハート分布 (sine-skewed generalized cardioid
dist.) 35 𝑃 𝑦; 𝜇, 𝜅, 𝜓 = cosh1/𝜓 𝜅𝜓 1 + tanh 𝜅𝜓 cos 𝑦 − 𝜇 1/𝜓 2𝜋𝑃1/𝜓 cosh 𝜅𝜓 平均 (mean) 集中度パラメータ (concentration param.) [Jones05] * 本稿では 𝜓をgiven (一定値) とした特殊形のみを扱う von Mises (𝜓 = 0) Cardioid (𝜓 = 1)Wrapped Cauchy (𝜓 = −1) 𝑦 0 𝜋 2𝜋 𝜇 𝜅
36.
/47 正弦関数摂動一般化ハート分布 (sine-skewed generalized cardioid
dist.) 36 𝑃 𝑦; 𝜇, 𝜆 = 𝑃circ 𝑦 ⋅ 1 + 𝜆 sin 𝑦 − 𝜇 摂動パラメータ (skewness param.)円周上の確率分布 [Abe11] sine-skewed von Mises (𝜓 = 0, 𝜓 = [−1,1]) 𝑦 0 𝜋 2𝜋
37.
/47 正弦関数摂動一般化ハート分布 (sine-skewed generalized cardioid
dist.) 37 𝜓∞−∞ −1 10 von Mises Cardioid Wrapped CauchyUniform Uniform Generalized cardioid Sine-skewed cardioid 1 −1 Sine-skewed wrapped Cauchy Sine-skewed von Mises Sine-skewed generalized cardioid 𝜆 𝑃 𝑦; 𝜇, 𝜅, 𝜓, 𝜆 = cosh1/𝜓 𝜅𝜓 1 + tanh 𝜅𝜓 cos 𝑦 − 𝜇 1/𝜓 1 + 𝜆 sin 𝑦 − 𝜇 2𝜋𝑃1/𝜓 cosh 𝜅𝜓 [Abe11]
38.
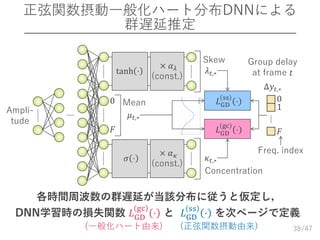
/47 正弦関数摂動一般化ハート分布DNNによる 群遅延推定 38 0 1 𝐹 Δ𝑦𝑡,∗ Group delay at frame
𝑡 𝐿GD gc ⋅ 𝜎 ⋅ × 𝛼 𝜅 (const.) 0 𝐹 𝜇 𝑡,∗ 𝜅 𝑡,∗ tanh ⋅ × 𝛼 𝜆 (const.) 𝜆 𝑡,∗ 𝐿GD ss ⋅Mean Concentration Skew Freq. index 各時間周波数の群遅延が当該分布に従うと仮定し, DNN学習時の損失関数 𝐿GD gc ⋅ と 𝐿GD ss ⋅ を次ページで定義 (一般化ハート由来) (正弦関数摂動由来) Ampli- tude
39.
/47 DNN学習時の損失関数 正弦関数摂動巻込み Cauchy (sine-skewed
wrapped Cauchy) 分布 DNN 正弦関数摂動 von Mises (sine-skewed von Mises) 分布 DNN 正弦関数摂動ハート (sine-skewed cardioid) 分布 DNN 39 𝐿 = − log 1 + 2𝜅 𝑡,𝑓 cos Δ𝑦𝑡,𝑓 − 𝜇 𝑡,𝑓 − log 1 + 𝜆 𝑡,𝑓 sin Δ𝑦𝑡,𝑓 − 𝜇 𝑡,𝑓 𝑓 𝐿 = log 1 + 𝜅 𝑡,𝑓 2 − 2𝜅 𝑡,𝑓 cos Δ𝑦𝑡,𝑓 − 𝜇 𝑡,𝑓 1 − 𝜅 𝑡,𝑓 2 − log 1 + 𝜆 𝑡,𝑓 sin Δ𝑦𝑡,𝑓 − 𝜇 𝑡,𝑓 𝑓 𝐿 = log 𝐼0 𝜅 𝑡,𝑓 − 𝜅 𝑡,𝑓 cos Δ𝑦𝑡,𝑓 − 𝜇 𝑡,𝑓 − log 1 + 𝜆 𝑡,𝑓 sin Δ𝑦𝑡,𝑓 − 𝜇 𝑡,𝑓 𝑓 (一般化ハート由来) (正弦関数摂動由来) 𝐿GD gc ⋅ 𝐿GD ss ⋅ * * * ここでの𝜅 𝑡,𝑓は一般化ハート分布の𝜅 𝑡,𝑓と異なることに注意.論文を参照.
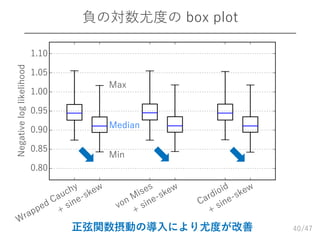
40.
/47 負の対数尤度の box plot 40 0.80 0.85 0.90 0.95 1.00 1.05 1.10 Negativeloglikelihood Min Max Median 正弦関数摂動の導入により尤度が改善
41.
今後の音声合成はどこに向かう? (超個人的な意見) 41
42.
/47 “Text”-to-speechを超える音声合成と そのためのコーパス 42 音声による抽象化・具体化を利用した多元的情報の融合へ JSUT JSUT-songJSUT-vi Singing voice (0.5
hrs)Vocal imitation (0.4 hrs) Reading-style speech (10 hrs) Single Japanese speaker’s voice [new!] JSUT-book Audiobook [new!] JSUT-??? ??? [Release in this winter] [Takamichi18] Jpn. E2E TTS [Ueno18] 日本語End-to-end音声合成のサンプル音声は,京都大学 河原先生・上乃さまに提供して頂いた
43.
/47 一期一会音声合成 43 [Takamichi17] 「正しく喋る」から「正しく間違えて喋る」音声合成へ Human Noise Current TTS Noise Our approach
今の音声合成は間違えてくれない… – いつも同じ声・セリフ… → 人間はそうじゃない – Moment matching network に基づく音声サンプリング [Takamichi17]
44.
/47 感情音声合成から扇情音声合成へ 感情音声合成 – 計算機の所望した感情を合成音声に付与する技術 –
聞き手 (人間側)のことを何も考えていない 扇情音声合成 – 計算機の所望した「ユーザの感情」を起こす技術 – 人間の挙動を計算機ループに組み込んだ学習 – 計算機に気持ちよく操られたい – (名前募集中) 44 人間の音声の挙動を計算機ループに組み込んだ Human-in-the-loop 音声合成へ
45.
/47 これからの音声合成まとめ 音声合成の役目は,音声を正確に出すこと? – 答えはNo.
(もちろん,正確に出すことも大事) 音声合成の役目は,音声コミュニケーションを拡張すること – 音声の芸術性を満たすには?(感性工学?) – 音声生成・聴取との関連?(物理学?) – セキュリティとの関連?(セキュリティ工学?) • 声の肖像権はどうあるべき? – 人間を組み込んだ音声合成? (ヒューマンコンピュテーション?) – IoA (Internet of Ability)としての音声合成? • 身体・時空間・文化の多様性を認めつつ,それらを拡張できる? 45
46.
まとめ 46
47.
/47 まとめ 統計的音声合成 敵対的学習の利用
方向統計DNN 今後の音声合成 47
Download







![/47
日本人英語音声合成
9
[Oshima16]
従来法で生成
提案法で生成
学習に使用した音声
(大学生、ERJデータベースに含まれる男性話者のうち、
評定スコアが最低)
“I can see that knife now.”](https://image.slidesharecdn.com/slide-181013074646/85/slide-9-320.jpg)

![/47
多方言音声合成
11
[Akiyama18]
Dialect
text
Multi-dialect
speech
synthesis
Dialect speech
Miyazaki-ben
韻律と単語の教師なし獲得により地域性・話者性を分離した音声合成へ](https://image.slidesharecdn.com/slide-181013074646/85/slide-11-320.jpg)



![/47
フレーム分析と音声特徴量
音声の準定常性を仮定してフレーム分析
– 20~30ms程度であれば,音声は定常信号
17
Time
Freq.
F0 [Hz]
Time有声 無声
声帯が
周期的に振動
Speech
スペクトルとF0が
1フレームの特徴量](https://image.slidesharecdn.com/slide-181013074646/85/slide-17-320.jpg)





![/47
Generative Adversarial Network (GAN):
分布間距離の最小化
Generative adversarial network
– 分布間の近似 Jensen-Shannon divergence を最小化
– 合成器と,自然/合成音声を識別する識別器を敵対
26
𝒚
1: 自然
0: 生成
[Goodfellow et al., 2014.]
⋯
⋯
⋯
⋯
Text
+noise
Anti-spoofing
Text-to-speech](https://image.slidesharecdn.com/slide-181013074646/85/slide-26-320.jpg)
![/47
DNN音声合成のための敵対学習
27
⋯
⋯
⋯
⋯
⋯
⋯
⋯
⋯
⋯
⋯
Linguistic
feats.
Parameter
generation
𝐿G 𝒚, 𝒚
𝐿D,1 𝒚Feature
function 1: natural
⋯
𝒚 𝒚
Generated
speech
params.
Natural
speech
params.
𝐿 𝒚, 𝒚 = 𝐿G 𝒚, 𝒚 + 𝜔D 𝐿D,1 𝒚 を最小化
敵対的損失生成誤差
Text-to-speech
Anti-spoofing
[Saito et al., 2018.]](https://image.slidesharecdn.com/slide-181013074646/85/slide-27-320.jpg)
![/47
GANによる分布補償の効果
28
20th mel-cepstral coefficient
23rdmel-cepstral
coefficient
Natural MGE GAN
モーメントや分布を明示的に定義せずに分布を近づける
[Saito et al., 2018.]](https://image.slidesharecdn.com/slide-181013074646/85/slide-28-320.jpg)
![/47
GANs as various divergence minimization
29
KL-GAN [Nowozin16]
JS-GAN [Nowozin16]
RKL-GAN [Nowozin16]
GAN [Goodfellow14]
W-GAN [Arjovsky17]
LS-GAN [Mao17]
Kullback Leibler (KL) div.
Jensen-Shannon (JS) div.
Reversed KL div.
Approx. JS div.
Wasserstein div.
1 2 3 4 5
Mean opinion score on synthetic speech quality
[Saito et al., 2018.]](https://image.slidesharecdn.com/slide-181013074646/85/slide-29-320.jpg)


![/47
パラメトリック確率分布DNNとは
定義:パラメトリックな条件付き確率分布 𝑃 𝑦|𝑥 を持つDNN
– 負の対数尤度を最小化する,DNN学習時の損失関数 𝐿 ⋅
– 例)
𝑦 − 𝑦 2 → 分散 given の(等方性)ガウス分布DNN
− cos 𝑦 − 𝑦 → 集中度パラメータ given の von Mises分布DNN
本発表:正弦関数摂動一般化ハート分布
– 円周上の確率分布 (位相のような周期変数に対応)
– 一般化ハート分布 [Jones05] … von Mises 分布を一般化した対称分布
– 正弦関数摂動 [Abe11] … 円周上の分布の非対称化
34
𝑥 𝑦 𝑦𝐿 ⋅
[Takamichi18]
以降では,分布を導入してDNN学習時の損失関数を定義](https://image.slidesharecdn.com/slide-181013074646/85/slide-34-320.jpg)
![/47
正弦関数摂動一般化ハート分布
(sine-skewed generalized cardioid dist.)
35
𝑃 𝑦; 𝜇, 𝜅, 𝜓 =
cosh1/𝜓 𝜅𝜓 1 + tanh 𝜅𝜓 cos 𝑦 − 𝜇 1/𝜓
2𝜋𝑃1/𝜓 cosh 𝜅𝜓
平均 (mean) 集中度パラメータ (concentration param.)
[Jones05]
* 本稿では 𝜓をgiven (一定値) とした特殊形のみを扱う
von Mises (𝜓 = 0) Cardioid (𝜓 = 1)Wrapped Cauchy (𝜓 = −1)
𝑦
0 𝜋 2𝜋
𝜇
𝜅](https://image.slidesharecdn.com/slide-181013074646/85/slide-35-320.jpg)
![/47
正弦関数摂動一般化ハート分布
(sine-skewed generalized cardioid dist.)
36
𝑃 𝑦; 𝜇, 𝜆 = 𝑃circ 𝑦 ⋅ 1 + 𝜆 sin 𝑦 − 𝜇
摂動パラメータ (skewness param.)円周上の確率分布
[Abe11]
sine-skewed von Mises (𝜓 = 0, 𝜓 = [−1,1])
𝑦
0 𝜋 2𝜋](https://image.slidesharecdn.com/slide-181013074646/85/slide-36-320.jpg)
![/47
正弦関数摂動一般化ハート分布
(sine-skewed generalized cardioid dist.)
37
𝜓∞−∞ −1 10
von
Mises Cardioid
Wrapped
CauchyUniform Uniform
Generalized
cardioid
Sine-skewed
cardioid
1
−1
Sine-skewed
wrapped Cauchy
Sine-skewed
von Mises
Sine-skewed generalized cardioid
𝜆
𝑃 𝑦; 𝜇, 𝜅, 𝜓, 𝜆 =
cosh1/𝜓 𝜅𝜓 1 + tanh 𝜅𝜓 cos 𝑦 − 𝜇 1/𝜓 1 + 𝜆 sin 𝑦 − 𝜇
2𝜋𝑃1/𝜓 cosh 𝜅𝜓
[Abe11]](https://image.slidesharecdn.com/slide-181013074646/85/slide-37-320.jpg)


![/47
“Text”-to-speechを超える音声合成と
そのためのコーパス
42
音声による抽象化・具体化を利用した多元的情報の融合へ
JSUT
JSUT-songJSUT-vi
Singing voice (0.5 hrs)Vocal imitation (0.4 hrs)
Reading-style speech (10 hrs)
Single Japanese speaker’s voice
[new!] JSUT-book
Audiobook
[new!] JSUT-???
???
[Release in this winter]
[Takamichi18]
Jpn. E2E TTS
[Ueno18]
日本語End-to-end音声合成のサンプル音声は,京都大学 河原先生・上乃さまに提供して頂いた](https://image.slidesharecdn.com/slide-181013074646/85/slide-42-320.jpg)
![/47
一期一会音声合成
43
[Takamichi17]
「正しく喋る」から「正しく間違えて喋る」音声合成へ
Human
Noise
Current TTS
Noise
Our approach
今の音声合成は間違えてくれない…
– いつも同じ声・セリフ… → 人間はそうじゃない
– Moment matching network に基づく音声サンプリング [Takamichi17]](https://image.slidesharecdn.com/slide-181013074646/85/slide-43-320.jpg)











![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)











































