Downloaded 36 times
![��
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
�������������������������������������������
Hirono Okamoto, Kato・Nakamura Lab](https://image.slidesharecdn.com/dl0216okamoto2162-180323031830/75/DL-Deep-Neural-Networks-as-Gaussian-Processes-1-2048.jpg)


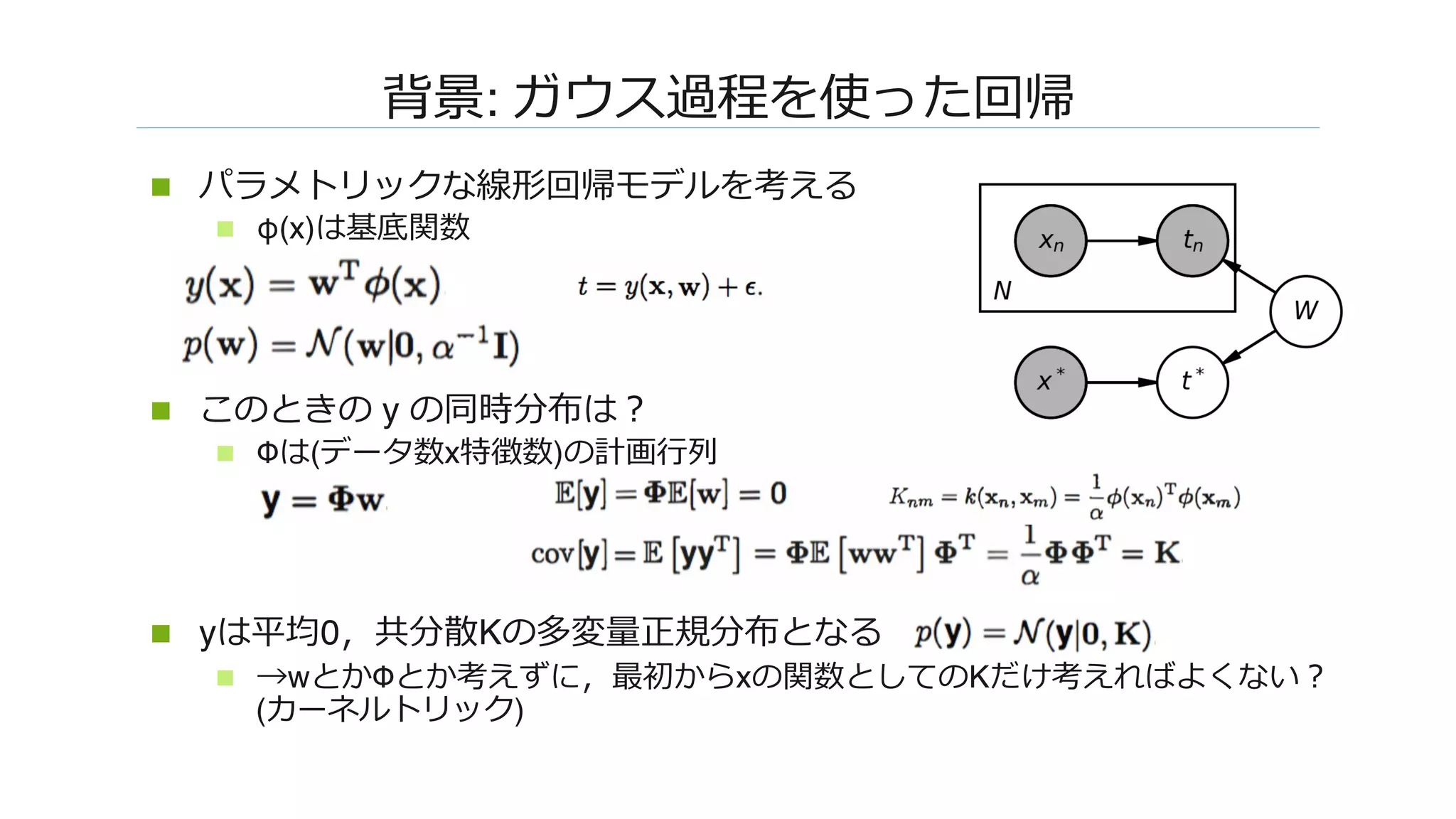
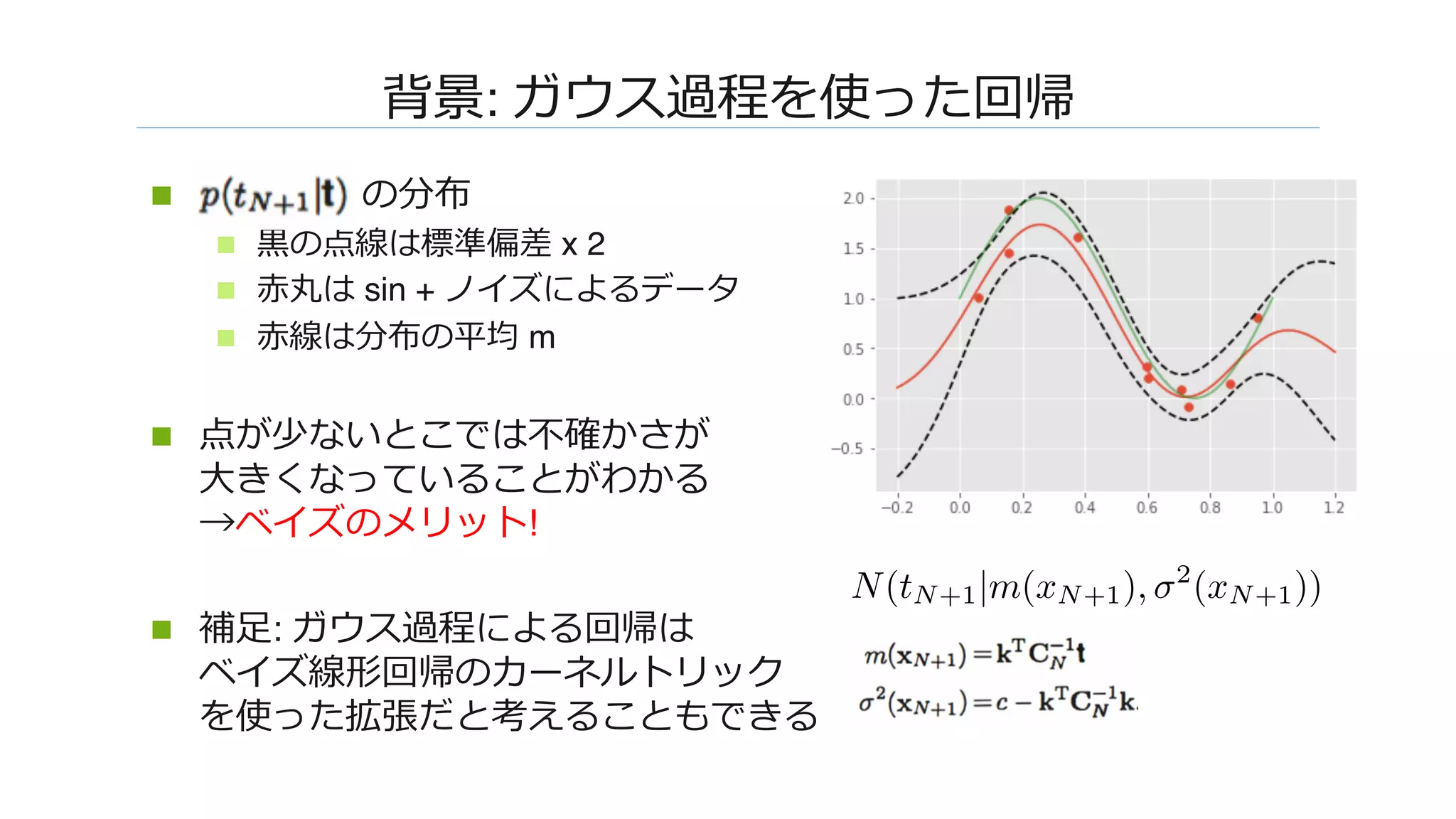
![��: �����������W����������
n �������(��)��������������������
n x: ���Φ: �����
n w, b�iid����W���������������iid�
���W���������G���� ∞
W��W����������� [Neal, 1994]
n �����������������������
���������
������������������
N1
φ
W0
W1
x1
j z1
ix1
j0
z1
i
z1
i](https://image.slidesharecdn.com/dl0216okamoto2162-180323031830/75/DL-Deep-Neural-Networks-as-Gaussian-Processes-9-2048.jpg)

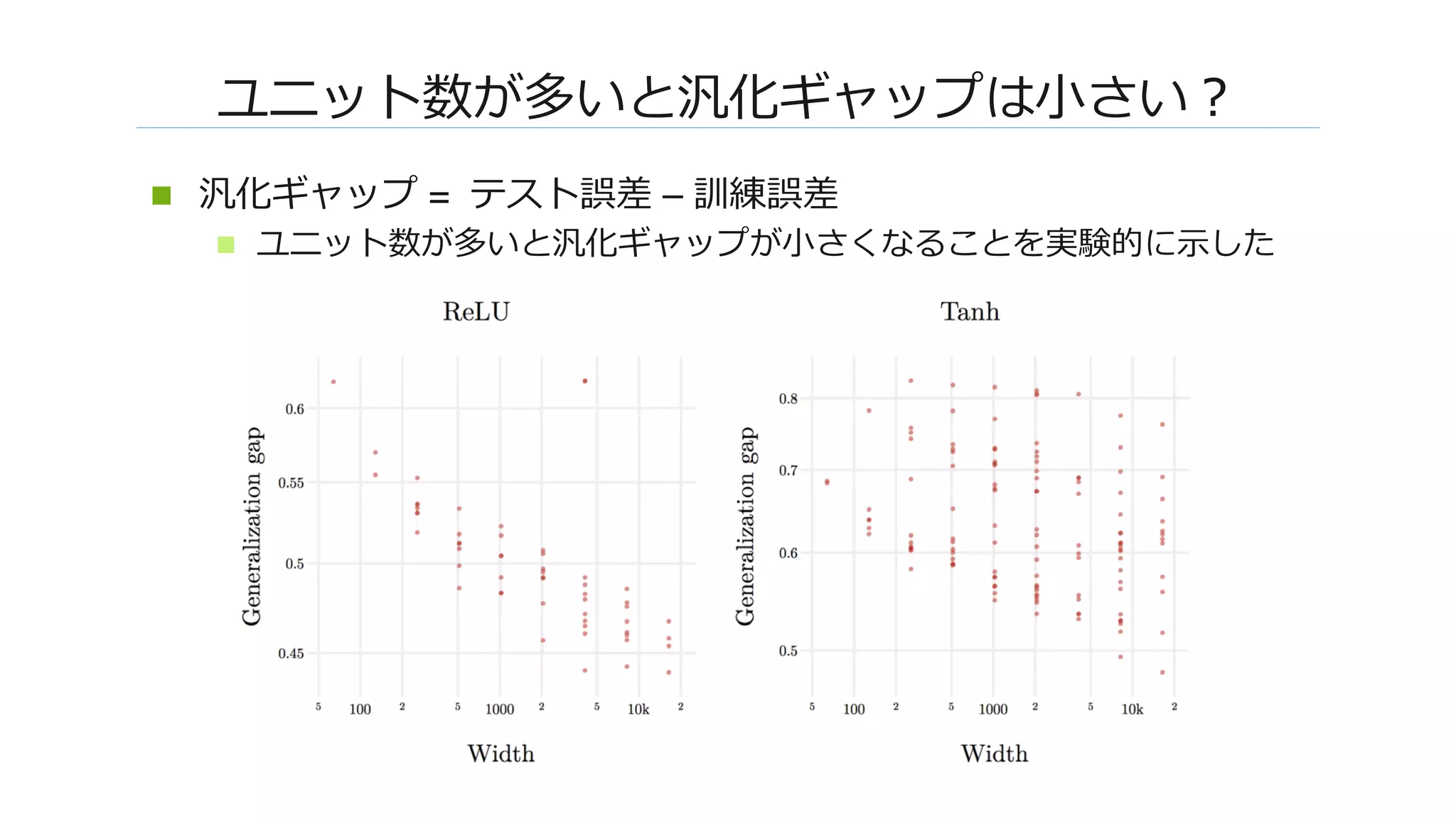


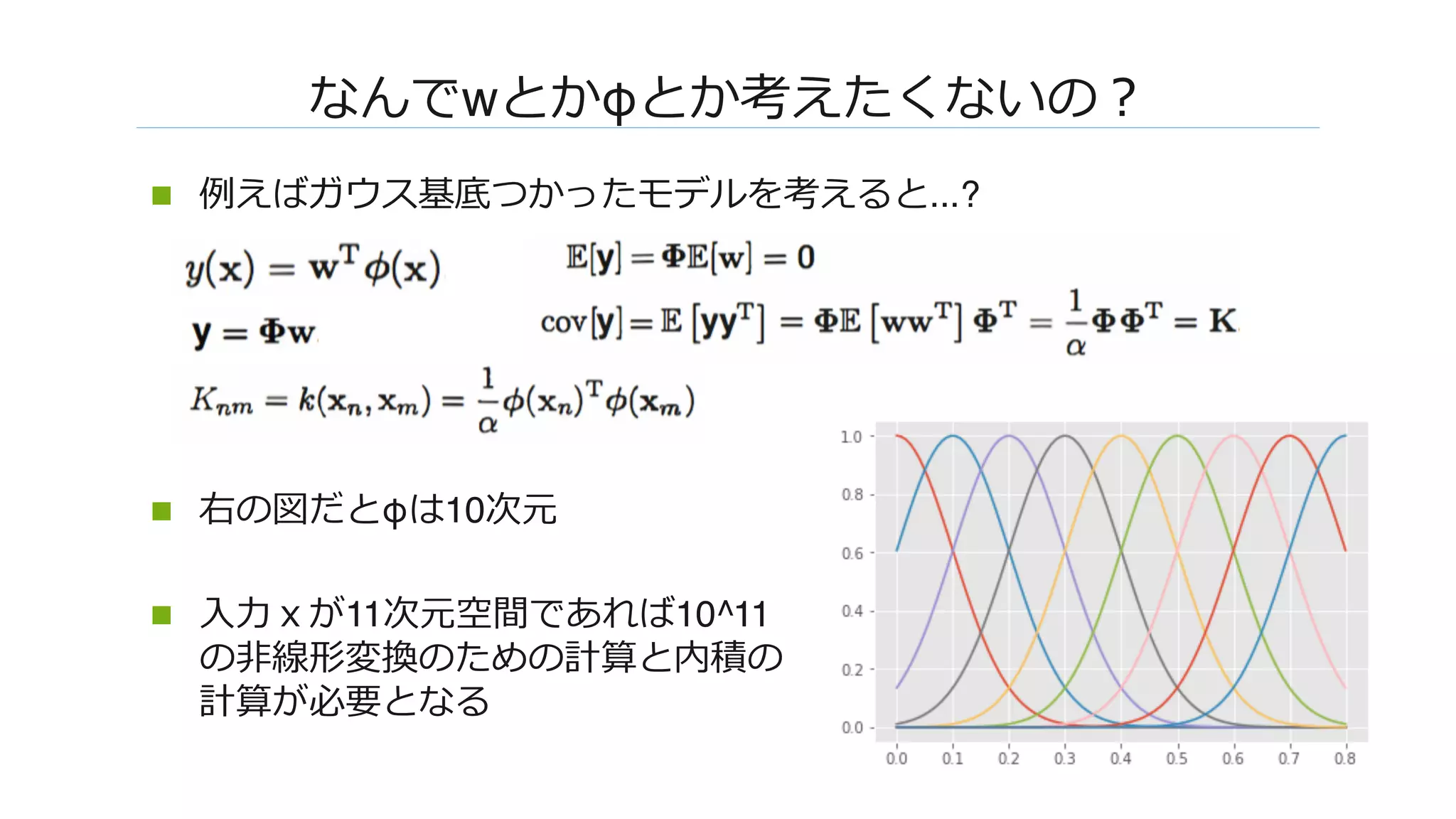
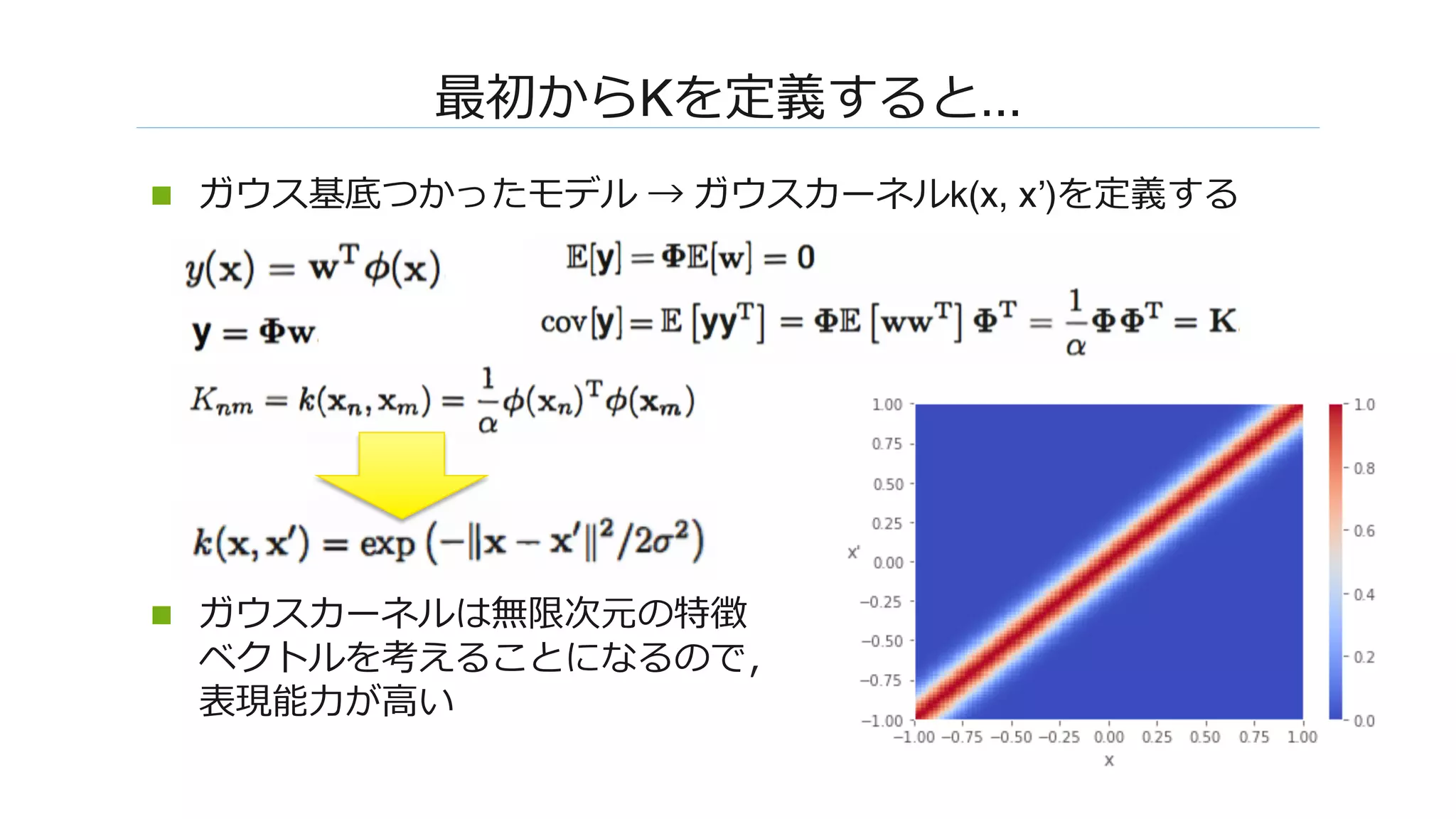
![����: MLP�������
n F_φ������������
n ReLU�W��������� [Cho & Saul, 2009]
n ��������W����������W���� (��������)
n F�sWc���, s�K(x, x)�c�K(x, x’)/K(x, x)����](https://image.slidesharecdn.com/dl0216okamoto2162-180323031830/75/DL-Deep-Neural-Networks-as-Gaussian-Processes-14-2048.jpg)
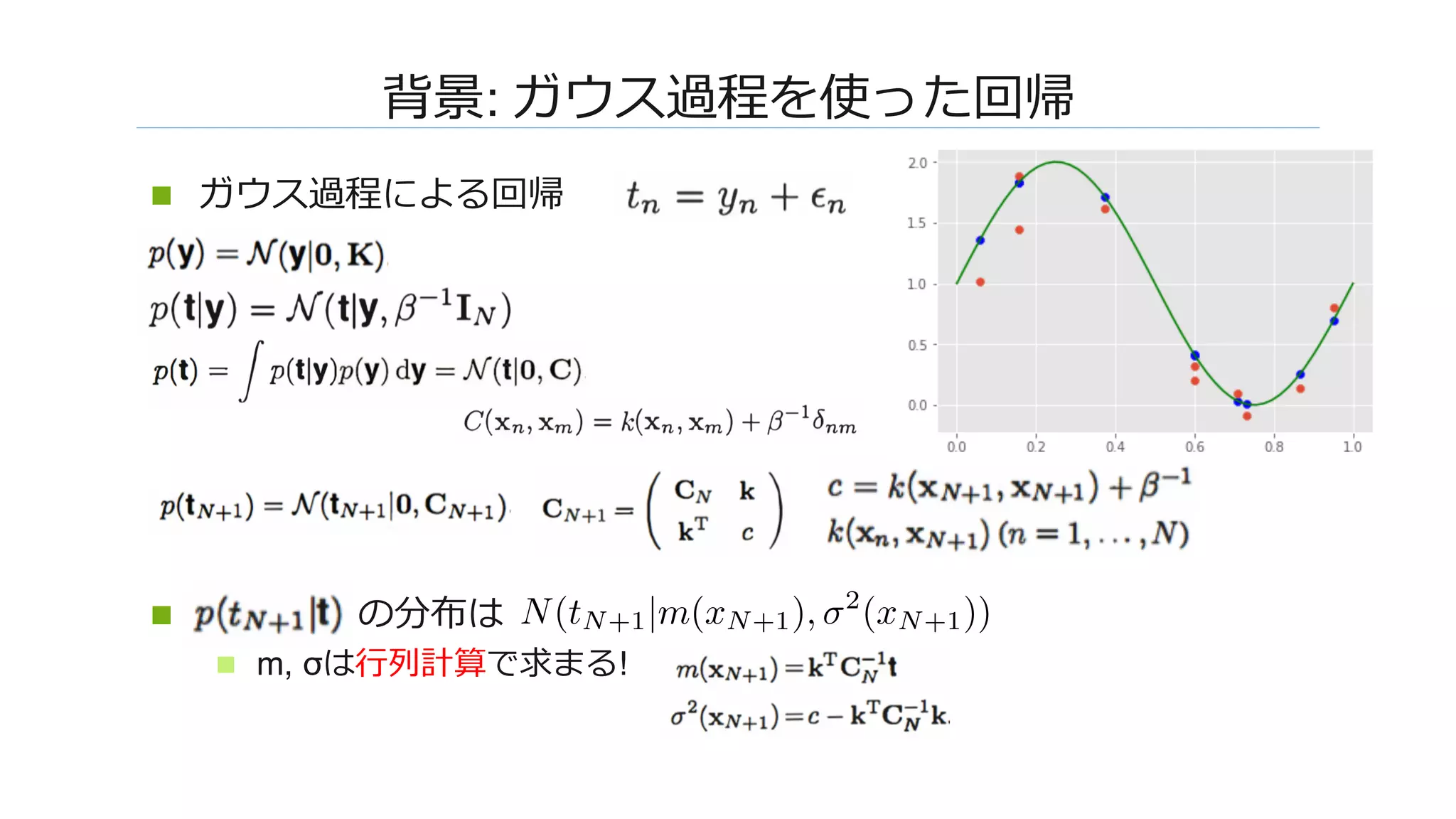
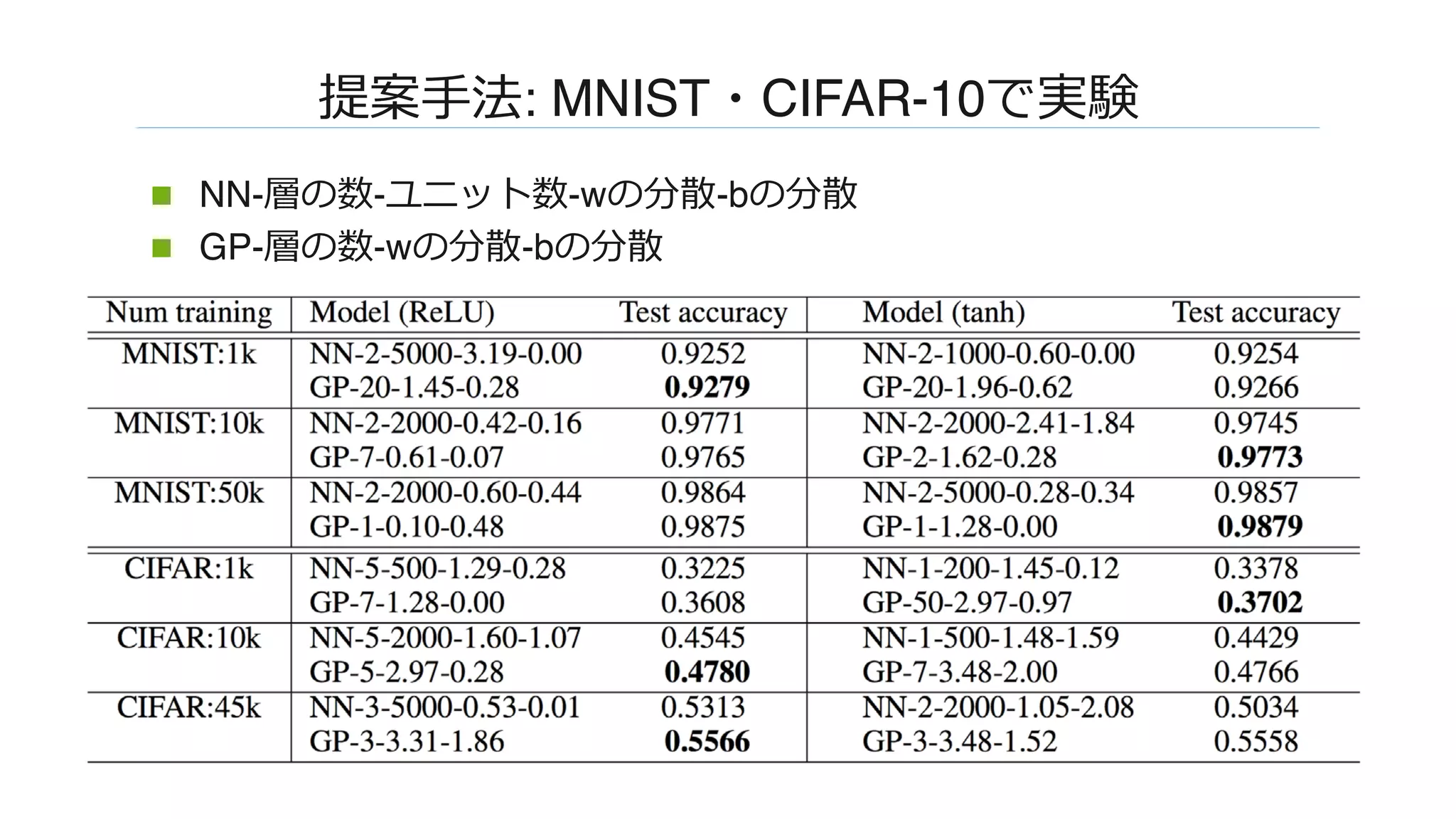
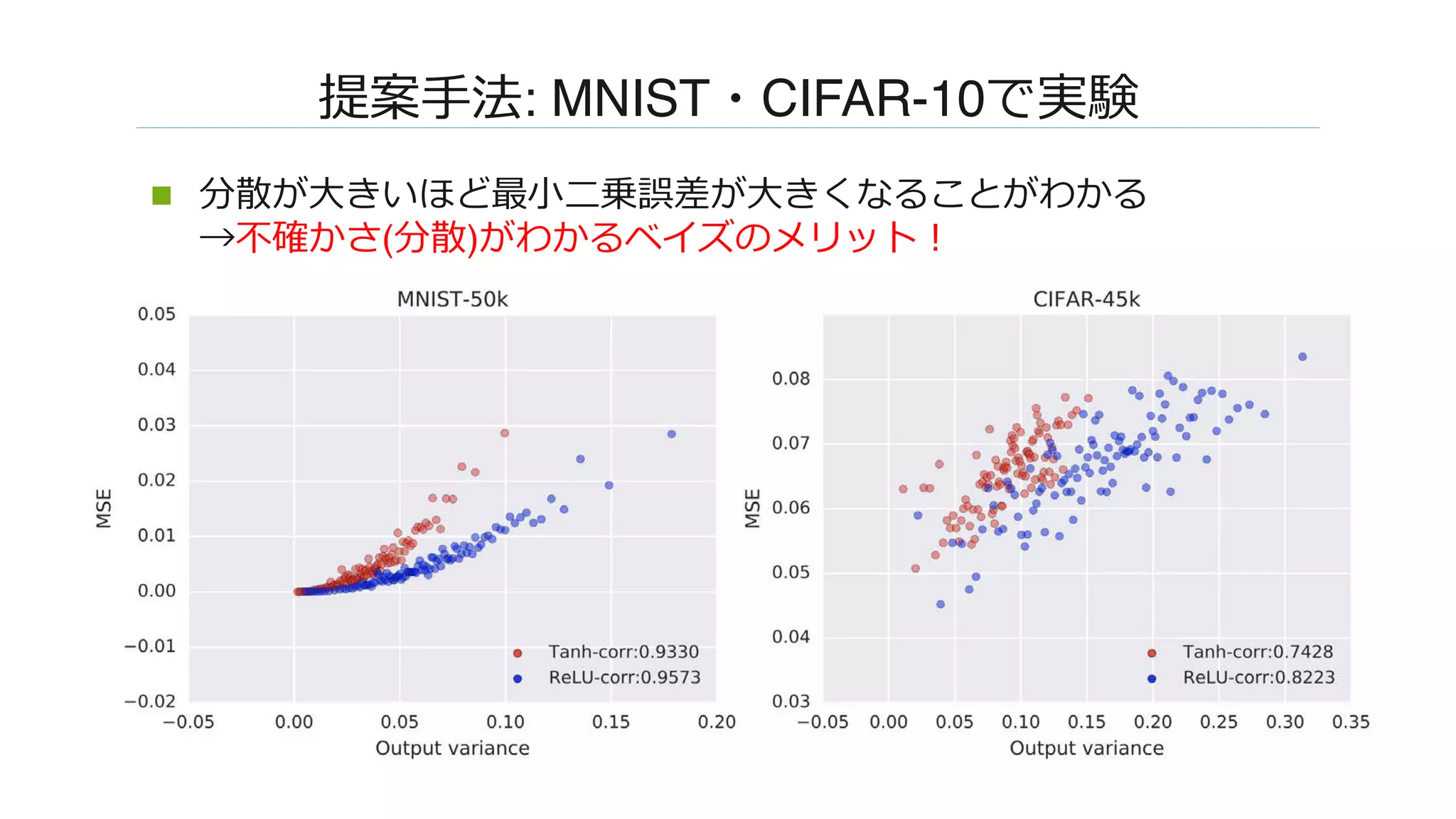
![����: MNIST�CIFAR-10����
n �����N�����W��� [Rifkin & Klautau, 2004] ����
�����
n �����:
n onehot : [-0.1, -0.1, ..., 0.9, ..., -0.1]
n �� 0
n ������0.9
n ��������-0.1
n ��: �������
n ��: �����
n L��MLP���������������������
N(tN+1|m(xN+1), σ2
(xN+1))=�](https://image.slidesharecdn.com/dl0216okamoto2162-180323031830/75/DL-Deep-Neural-Networks-as-Gaussian-Processes-15-2048.jpg)
![�����
n [Neal, 1994] Priors for infinite networks
n [Cho & Saul, 2009] Kernel methods for deep learning
n [Rifkin & Klautau, 2004] Regularized least-squares classification
n [Bishop] Pattern recognition and machine learning
n [Murphy] Machine learning a probabilistic perspective�](https://image.slidesharecdn.com/dl0216okamoto2162-180323031830/75/DL-Deep-Neural-Networks-as-Gaussian-Processes-18-2048.jpg)

Документ обсуждает использование глубоких нейронных сетей в качестве гауссовых процессов и анализирует алгоритмы для работы с набором данных MNIST и CIFAR-10. Рассматриваются различные методы, стандарты и математические модели, включая многослойные перцептроны (MLP) и их применение. Авторы сосредотачиваются на теоретических основах и практических аспектах реализации этих алгоритмов.
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)



























