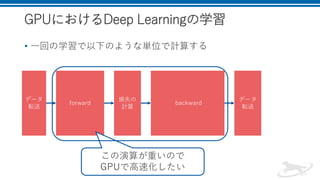
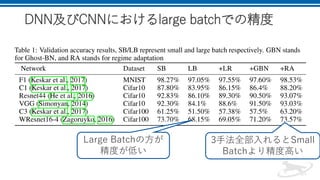
その2: Ghost BatchNormalization(GBN)
• 小さいバッチに分けてそれぞれのバッチごとにBNを行う
Small Batch
Small Batch
Small Batch
Small Batch
BN
BN
BN
BN
Large Batch
Ghost Batch Normalization(BN)
分割
出力
結合
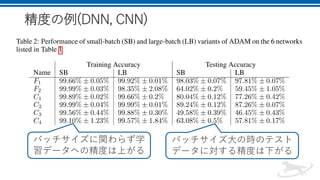
19.
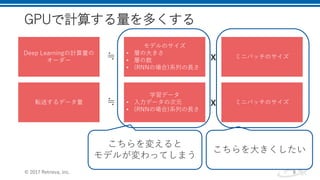
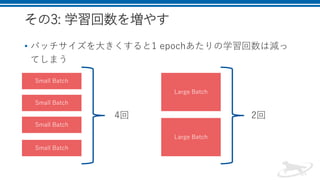
その3: 学習回数を増やす
• バッチサイズを大きくすると1epochあたりの学習回数は減っ
てしまう
Small Batch
Small Batch
Small Batch
Small Batch
Large Batch
Large Batch
4回 2回
参考文献
• (Hoffer etal., 2017): Train longer, generalize better: closing the
generalization gap in large batch training of neural networks.
• (Wilson et al., 2017): The Value of Adaptive Gradient Methods in
Machine Learning.
• (Dinh et al., 2017): Sharp Minima Can generalize For Deep Nets.
• (Kesker et al., 2017): On Large-Batch Training For Deep Learning:
Generalization Gap and Sharp Minima.
• (Chaudhari et al., 2017): Entropy-sgd: Biasing gradient descent
into wide valleys.
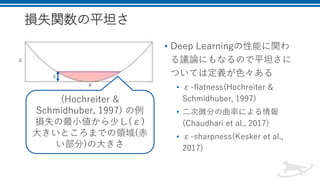
• (Hochreiter & Schmidhuber, 1997): Flat minima.

















![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]モデルベース強化学習とEnergy Based Model](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-191129002008-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)

































